Detectron2 Beginner's Tutorial(colabNotebook搬运,包括ipynb文件)
文章目录
- 项目地址和colab文件下载
- Detectron2 Beginner's Tutorial(这里有的代码得改改才能用)
- Install detectron2
- Run a pre-trained detectron2 model
- Train on a custom dataset
-
- Prepare the dataset
- Train!
- Inference & evaluation using the trained model
- Other types of builtin models
- Run panoptic segmentation on a video
项目地址和colab文件下载
国内上不去colab,其实是一个ipynb文件
DOC
Detectron2github项目
colab网址
ipynb文件下载
Detectron2 Beginner’s Tutorial(这里有的代码得改改才能用)
Welcome to detectron2! In this tutorial, we will go through some basics usage of detectron2, including the following:

Run inference on images or videos, with an existing detectron2 model
Train a detectron2 model on a new dataset
You can make a copy of this tutorial or use “File -> Open in playground mode” to play with it yourself.
Install detectron2
# install dependencies:
# (use +cu100 because colab is on CUDA 10.0)
!pip install -U torch==1.4+cu100 torchvision==0.5+cu100 -f https://download.pytorch.org/whl/torch_stable.html
!pip install cython pyyaml==5.1
!pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
import torch, torchvision
torch.__version__
!gcc --version
# opencv is pre-installed on colab
# install detectron2:
!git clone https://github.com/facebookresearch/detectron2 detectron2_repo
!pip install -e detectron2_repo
out:
Cloning into 'detectron2_repo'...
remote: Enumerating objects: 11, done.
remote: Counting objects: 100% (11/11), done.
remote: Compressing objects: 100% (10/10), done.
remote: Total 2443 (delta 1), reused 3 (delta 1), pack-reused 2432
Receiving objects: 100% (2443/2443), 1.86 MiB | 11.43 MiB/s, done.
Resolving deltas: 100% (1624/1624), done.
Obtaining file:///content/detectron2_repo
Requirement already satisfied: termcolor>=1.1 in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (1.1.0)
Requirement already satisfied: Pillow==6.2.2 in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (6.2.2)
Collecting yacs>=0.1.6
Downloading https://files.pythonhosted.org/packages/2f/51/9d613d67a8561a0cdf696c3909870f157ed85617fea3cff769bb7de09ef7/yacs-0.1.6-py3-none-any.whl
Requirement already satisfied: tabulate in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (0.8.6)
Requirement already satisfied: cloudpickle in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (1.2.2)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (3.1.2)
Collecting tqdm>4.29.0
Downloading https://files.pythonhosted.org/packages/72/c9/7fc20feac72e79032a7c8138fd0d395dc6d8812b5b9edf53c3afd0b31017/tqdm-4.41.1-py2.py3-none-any.whl (56kB)
|████████████████████████████████| 61kB 3.6MB/s
Requirement already satisfied: tensorboard in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (1.15.0)
Collecting fvcore
Downloading https://files.pythonhosted.org/packages/b1/f7/6c63a2ea9aa495ff34e79189f3267ba585c5f8cb9798eeaff8ef5796c7e6/fvcore-0.1.dev200114.tar.gz
Requirement already satisfied: future in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (0.16.0)
Requirement already satisfied: pydot in /usr/local/lib/python3.6/dist-packages (from detectron2==0.1) (1.3.0)
Requirement already satisfied: PyYAML in /usr/local/lib/python3.6/dist-packages (from yacs>=0.1.6->detectron2==0.1) (5.1)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->detectron2==0.1) (2.6.1)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->detectron2==0.1) (1.1.0)
Requirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.6/dist-packages (from matplotlib->detectron2==0.1) (1.17.5)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->detectron2==0.1) (0.10.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->detectron2==0.1) (2.4.6)
Requirement already satisfied: grpcio>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (1.15.0)
Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (3.1.1)
Requirement already satisfied: protobuf>=3.6.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (3.10.0)
Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (0.16.0)
Requirement already satisfied: absl-py>=0.4 in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (0.9.0)
Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (42.0.2)
Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (1.12.0)
Requirement already satisfied: wheel>=0.26; python_version >= "3" in /usr/local/lib/python3.6/dist-packages (from tensorboard->detectron2==0.1) (0.33.6)
Collecting portalocker
Downloading https://files.pythonhosted.org/packages/91/db/7bc703c0760df726839e0699b7f78a4d8217fdc9c7fcb1b51b39c5a22a4e/portalocker-1.5.2-py2.py3-none-any.whl
Building wheels for collected packages: fvcore
Building wheel for fvcore (setup.py) ... done
Created wheel for fvcore: filename=fvcore-0.1.dev200114-cp36-none-any.whl size=30376 sha256=75265123013d6d39d8903303ad9e6a1e0d0e0ed0730a83431d42719216056dfb
Stored in directory: /root/.cache/pip/wheels/31/52/ce/158c59c47690d60a76878c7b09d3e660fbfb091acbc02e6da3
Successfully built fvcore
Installing collected packages: yacs, tqdm, portalocker, fvcore, detectron2
Found existing installation: tqdm 4.28.1
Uninstalling tqdm-4.28.1:
Successfully uninstalled tqdm-4.28.1
Running setup.py develop for detectron2
Successfully installed detectron2 fvcore-0.1.dev200114 portalocker-1.5.2 tqdm-4.41.1 yacs-0.1.6
# You may need to restart your runtime prior to this, to let your installation take effect
# Some basic setup:
# Setup detectron2 logger
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# import some common libraries
import numpy as np
import cv2
import random
from google.colab.patches import cv2_imshow
# import some common detectron2 utilities
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog
Run a pre-trained detectron2 model
!wget http://images.cocodataset.org/val2017/000000439715.jpg -O input.jpg
im = cv2.imread("./input.jpg")
cv2_imshow(im)
--2019-12-26 06:45:01-- http://images.cocodataset.org/val2017/000000439715.jpg
Resolving images.cocodataset.org (images.cocodataset.org)... 52.217.42.132
Connecting to images.cocodataset.org (images.cocodataset.org)|52.217.42.132|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 209222 (204K) [image/jpeg]
Saving to: ‘input.jpg’
input.jpg 100%[===================>] 204.32K 1.08MB/s in 0.2s
2019-12-26 06:45:01 (1.08 MB/s) - ‘input.jpg’ saved [209222/209222]

Then, we create a detectron2 config and a detectron2 DefaultPredictor to run inference on this image.
cfg = get_cfg()
# add project-specific config (e.g., TensorMask) here if you're not running a model in detectron2's core library
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set threshold for this model
# Find a model from detectron2's model zoo. You can use the https://dl.fbaipublicfiles... url as well
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
WARNING [12/26 06:45:43 d2.config.compat]: Config '/content/detectron2_repo/detectron2/model_zoo/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml' has no VERSION. Assuming it to be compatible with latest v2.
model_final_f10217.pkl: 178MB [00:02, 63.7MB/s]
# look at the outputs. See https://detectron2.readthedocs.io/tutorials/models.html#model-output-format for specification
outputs["instances"].pred_classes
outputs["instances"].pred_boxes
out:
Boxes(tensor([[126.6035, 244.8977, 459.8291, 480.0000],
[251.1083, 157.8127, 338.9731, 413.6379],
[114.8496, 268.6864, 148.2352, 398.8111],
[ 0.8217, 281.0327, 78.6072, 478.4210],
[ 49.3954, 274.1229, 80.1545, 342.9808],
[561.2248, 271.5816, 596.2755, 385.2552],
[385.9072, 270.3125, 413.7130, 304.0397],
[515.9295, 278.3744, 562.2792, 389.3802],
[335.2409, 251.9167, 414.7491, 275.9375],
[350.9300, 269.2060, 386.0984, 297.9081],
[331.6292, 230.9996, 393.2759, 257.2009],
[510.7349, 263.2656, 570.9865, 295.9194],
[409.0841, 271.8646, 460.5582, 356.8722],
[506.8767, 283.3257, 529.9403, 324.0392],
[594.5663, 283.4820, 609.0577, 311.4124]], device='cuda:0'))
# We can use `Visualizer` to draw the predictions on the image.
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])
Train on a custom dataset
In this section, we show how to train an existing detectron2 model on a custom dataset in a new format.
We use the balloon segmentation dataset which only has one class: balloon. We’ll train a balloon segmentation model from an existing model pre-trained on COCO dataset, available in detectron2’s model zoo.
Note that COCO dataset does not have the “balloon” category. We’ll be able to recognize this new class in a few minutes.
Prepare the dataset
# download, decompress the data
!wget https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
!unzip balloon_dataset.zip > /dev/null
Register the balloon dataset to detectron2, following the detectron2 custom dataset tutorial.
Here, the dataset is in its custom format, therefore we write a function to parse it and prepare it into detectron2’s standard format. See the tutorial for more details.
import os
import numpy as np
import json
from detectron2.structures import BoxMode
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
"iscrowd": 0
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
from detectron2.data import DatasetCatalog, MetadataCatalog
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
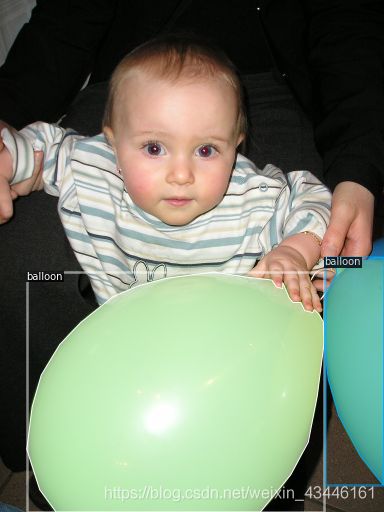
To verify the data loading is correct, let’s visualize the annotations of randomly selected samples in the training set:
dataset_dicts = get_balloon_dicts("balloon/train")
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=balloon_metadata, scale=0.5)
vis = visualizer.draw_dataset_dict(d)
cv2_imshow(vis.get_image()[:, :, ::-1])

Train!
Now, let’s fine-tune a coco-pretrained R50-FPN Mask R-CNN model on the balloon dataset. It takes ~6 minutes to train 300 iterations on Colab’s K80 GPU, or ~2 minutes on a P100 GPU.
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.DATASETS.TRAIN = ("balloon_train",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") # Let training initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 300 # 300 iterations seems good enough for this toy dataset; you may need to train longer for a practical dataset
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon)
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
out:
WARNING [11/15 04:10:08 d2.config.compat]: Config './detectron2_repo/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml' has no VERSION. Assuming it to be compatible with latest v2.
[11/15 04:10:08 d2.engine.defaults]: Model:
GeneralizedRCNN(
(backbone): FPN(
(fpn_lateral2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_block): LastLevelMaxPool()
(bottom_up): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)
)
(proposal_generator): RPN(
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
(rpn_head): StandardRPNHead(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(objectness_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
(roi_heads): StandardROIHeads(
(box_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(box_head): FastRCNNConvFCHead(
(fc1): Linear(in_features=12544, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNOutputLayers(
(cls_score): Linear(in_features=1024, out_features=2, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=4, bias=True)
)
(mask_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(14, 14), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(14, 14), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(mask_head): MaskRCNNConvUpsampleHead(
(mask_fcn1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(mask_fcn2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(mask_fcn3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(mask_fcn4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(deconv): ConvTranspose2d(256, 256, kernel_size=(2, 2), stride=(2, 2))
(predictor): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
)
[11/15 04:10:10 d2.data.build]: Removed 0 images with no usable annotations. 61 images left.
[11/15 04:10:10 d2.data.detection_utils]: TransformGens used in training: [ResizeShortestEdge(short_edge_length=(640, 672, 704, 736, 768, 800), max_size=1333, sample_style='choice'), RandomFlip()]
[11/15 04:10:10 d2.data.build]: Using training sampler TrainingSampler
# Look at training curves in tensorboard:
%load_ext tensorboard
%tensorboard --logdir output
Inference & evaluation using the trained model
Now, let’s run inference with the trained model on the balloon validation dataset. First, let’s create a predictor using the model we just trained:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set the testing threshold for this model
cfg.DATASETS.TEST = ("balloon_val", )
predictor = DefaultPredictor(cfg)
Then, we randomly select several samples to visualize the prediction results.
from detectron2.utils.visualizer import ColorMode
dataset_dicts = get_balloon_dicts("balloon/val")
for d in random.sample(dataset_dicts, 3):
im = cv2.imread(d["file_name"])
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1],
metadata=balloon_metadata,
scale=0.8,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels
)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])
We can also evaluate its performance using AP metric implemented in COCO API.
This gives an AP of ~70%. Not bad!
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
evaluator = COCOEvaluator("balloon_val", cfg, False, output_dir="./output/")
val_loader = build_detection_test_loader(cfg, "balloon_val")
inference_on_dataset(trainer.model, val_loader, evaluator)
# another equivalent way is to use trainer.test
out:
[11/15 04:10:32 d2.evaluation.evaluator]: Start inference on 13 images
[11/15 04:10:46 d2.evaluation.evaluator]: Total inference time: 0:00:05 (0.625000 s / img per device, on 1 devices)
[11/15 04:10:46 d2.evaluation.evaluator]: Total inference pure compute time: 0:00:03 (0.437190 s / img per device, on 1 devices)
[11/15 04:10:46 d2.evaluation.coco_evaluation]: Preparing results for COCO format ...
[11/15 04:10:46 d2.evaluation.coco_evaluation]: Saving results to ./output/coco_instances_results.json
[11/15 04:10:46 d2.evaluation.coco_evaluation]: Evaluating predictions ...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.13s).
Accumulating evaluation results...
DONE (t=0.02s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.849
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.828
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.011
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.572
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.816
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.228
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.714
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.750
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.133
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.671
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.857
[11/15 04:10:46 d2.evaluation.coco_evaluation]: Evaluation results for bbox:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:-----:|:------:|:------:|
| 68.133 | 84.928 | 82.807 | 1.106 | 57.231 | 81.589 |
Loading and preparing results...
DONE (t=0.02s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *segm*
DONE (t=0.15s).
Accumulating evaluation results...
DONE (t=0.02s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.770
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.846
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.840
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.008
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.589
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.936
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.248
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.780
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.820
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.233
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.682
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.957
[11/15 04:10:46 d2.evaluation.coco_evaluation]: Evaluation results for segm:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:-----:|:------:|:------:|
| 76.976 | 84.647 | 84.017 | 0.763 | 58.887 | 93.632 |
OrderedDict([('bbox',
{'AP': 68.13251528146942,
'AP50': 84.9277873853965,
'AP75': 82.8068039080166,
'APl': 81.58885128967246,
'APm': 57.23126698500541,
'APs': 1.1056105610561056}),
('segm',
{'AP': 76.97562111397131,
'AP50': 84.64734364022362,
'AP75': 84.01711775272273,
'APl': 93.63197968598362,
'APm': 58.887208805837645,
'APs': 0.763201320132013})])
Other types of builtin models
# Inference with a keypoint detection model
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set threshold for this model
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])
out:
WARNING [10/15 06:33:32 d2.config.compat]: Config './detectron2_repo/configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml' has no VERSION. Assuming it to be compatible with latest v2.
# Inference with a panoptic segmentation model
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml"))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml")
predictor = DefaultPredictor(cfg)
panoptic_seg, segments_info = predictor(im)["panoptic_seg"]
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_panoptic_seg_predictions(panoptic_seg.to("cpu"), segments_info)
cv2_imshow(v.get_image()[:, :, ::-1])
out:
WARNING [10/15 06:33:37 d2.config.compat]: Config './detectron2_repo/configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml' has no VERSION. Assuming it to be compatible with latest v2

Run panoptic segmentation on a video
# This is the video we're going to process
from IPython.display import YouTubeVideo, display
video = YouTubeVideo("ll8TgCZ0plk", width=500)
display(video)
# Install dependencies, download the video, and crop 5 seconds for processing
!pip install youtube-dl
!pip uninstall -y opencv-python opencv-contrib-python
!apt install python3-opencv # the one pre-installed have some issues
!youtube-dl https://www.youtube.com/watch?v=ll8TgCZ0plk -f 22 -o video.mp4
!ffmpeg -i video.mp4 -t 00:00:06 -c:v copy video-clip.mp4
# Run frame-by-frame inference demo on this video (takes 3-4 minutes)
# Using a model trained on COCO dataset
!cd detectron2_repo && python demo/demo.py --config-file configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml --video-input ../video-clip.mp4 --confidence-threshold 0.6 --output ../video-output.mkv \
--opts MODEL.WEIGHTS detectron2://COCO-PanopticSegmentation/panoptic_fpn_R_101_3x/139514519/model_final_cafdb1.pkl
# Download the results
from google.colab import files
files.download('video-output.mkv')