【CV】计算机视觉领域的 GAN 模型综述论文笔记
论文名称:Generative Adversarial Networks in Computer Vision:
A Survey and Taxonomy
论文下载:https://dl.acm.org/doi/abs/10.1145/3439723
论文年份:ACM Computing Surveys 2021
论文被引:173(2022/04/12)
论文代码:https://github.com/sheqi/GAN_Review
Abstract
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably their most significant impact has been in the area of computer vision where great advances have been made in challenges such as plausible image generation, image-to-image translation, facial attribute manipulation, and similar domains. Despite the significant successes achieved to date, applying GANs to real-world problems still poses significant challenges, three of which we focus on here. These are as follows: (1) the generation of high quality images, (2) diversity of image generation, and (3) stabilizing training. Focusing on the degree to which popular GAN technologies have made progress against these challenges, we provide a detailed review of the state-of-the-art in GAN-related research in the published scientific literature. We further structure this review through a convenient taxonomy we have adopted based on variations in GAN architectures and loss functions. While several reviews for GANs have been presented to date, none have considered the status of this field based on their progress toward addressing practical challenges relevant to computer vision. Accordingly, we review and critically discuss the most popular architecture-variant, and loss-variant GANs, for tackling these challenges. Our objective is to provide an overview as well as a critical analysis of the status of GAN research in terms of relevant progress toward critical computer vision application requirements. As we do this we also discuss the most compelling applications in computer vision in which GANs have demonstrated considerable success along with some suggestions for future research directions.
生成对抗网络(GAN)在过去几年中得到了广泛的研究。可以说,它们最显着的影响是在计算机视觉领域,在诸如可信图像生成(plausible image generation)、图像到图像转换(image-to-image translation)、面部属性操作(facial attribute manipulation)和类似领域等挑战方面取得了巨大进步。尽管迄今为止取得了重大成功,但将 GAN 应用于现实世界的问题仍然存在重大挑战,我们在这里重点关注其中三个。它们如下:(1)高质量图像的生成,(2)图像生成的多样性,以及(3)稳定训练。着眼于流行的 GAN 技术在应对这些挑战方面取得的进展程度,我们在已发表的科学文献中对 GAN 相关研究的最新技术进行了详细回顾。我们根据 GAN 架构和损失函数的变化采用了一种方便的分类法,进一步构建了这篇综述。虽然迄今为止已经提出了一些关于 GAN 的综述,但没有人在解决与计算机视觉相关的实际挑战方面取得的进展来考虑该领域的现状。因此,我们回顾并批判性地讨论了最流行的架构变体和损失变体 GAN,以应对这些挑战。我们的目标是根据关键计算机视觉应用需求的相关进展,对 GAN 研究的现状进行概述和批判性分析。在此过程中,我们还讨论了计算机视觉中最引人注目的应用,在这些应用中 GAN 取得了相当大的成功,并对未来的研究方向提出了一些建议。
1 INTRODUCTION
生成对抗网络 (Generative adversarial networks,GAN) 在深度学习社区中引起了越来越多的兴趣。
-
【GAN的应用领域】:计算机视觉、自然语言处理、时间序列合成,语义分割等。
-
【GAN的优势】:GAN 属于机器学习中的生成模型家族。与其他生成模型(例如变分自编码器)相比,GAN 具有处理尖锐估计密度函数的能力、有效生成所需样本的能力、消除确定性偏差以及与内部神经架构的良好兼容性等优势 [44]。
-
【GAN在CV中应用】:以上特性使 GAN 获得了巨大的成功,特别是在CV领域,例如,可信图像生成(plausible image generation)、图像到图像的转换(image-to-image translation),图像超分辨率(image super-resolution)和图像补全(image completion)。
-
【GAN 的问题】:最重要的两个是 **难以训练 **和 难以评估。就难以训练而言,判别器和生成器在训练过程中实现纳什均衡(Nash Equilibrium)并非易事,生成器无法很好地学习数据集的完整分布是很常见的。这是众所周知的模式崩溃问题(Mode Collapse)。在这一领域已经开展了大量工作 [27, 68, 69, 78]。在评估方面,主要问题是如何最好地衡量目标 pr 的真实分布与生成的分布 pg 之间的差异。不幸的是,无法准确估计 pr。因此,对 pr 和 pg 之间的对应关系进行良好的估计是具有挑战性的。以前的工作已经为 GAN [10、12、46、47、49、124、134、135、138] 提出了各种评估指标,这是一个活跃的研究领域。对评估挑战感兴趣的读者可以参考 [12, 124]。
-
【GAN 研究热点】:当前的大部分 GAN 研究可以根据以下两个目标来考虑:(1)改进训练和(2)将 GAN 部署到实际应用中。前者旨在提高 GAN 的性能,因此是后者(即应用程序)的基础。训练过程的改进在 GAN 的性能方面提供了如下好处:(1) 生成图像多样性(也称为模式多样性)的改进,(2) 生成图像质量的提高,以及 (3) 稳定训练,例如解决生成器的梯度消失问题。为了提高上述性能,可以从架构方面或损失角度对 GAN 进行修改。
图 1 说明了我们为 2014 年至 2020 年文献中提出的代表性 GAN 提出的分类法。文献中已经提出了许多 GAN 变体来提高性能。这些可以分为两种类型,即 架构变体 和 损失变体。
- 架构变体:第一个提出的 GAN 使用完全连接的神经网络 [45],因此特定类型的架构可能有利于特定应用,例如用于图像的卷积神经网络 (CNN) 和用于时间序列数据的循环神经网络 (RNN);
- 损失变体:这里探索了损失函数(等式(1))的不同变化,以实现对 G 的更稳定的学习。
在架构变体中,我们总结了三个类别:
- 网络架构:指对整个 GAN 架构进行的改进或修改,例如,在 Progressive GAN (PROGAN) [64] 中部署的渐进式机制。
- 潜在空间:表明架构修改是基于潜在空间的不同表示进行的,例如,条件 GAN(CGAN)[99] 涉及向生成器和鉴别器提供标签信息。
- 以应用为中心:指根据不同应用进行的修改,例如,CycleGAN [153] 具有处理图像风格迁移的特定架构。
在损失变体方面,我们将其分为两类:
- 损失类型:指可以针对 GAN 优化的不同损失函数。
- 基于积分概率度量 (integral probability metric,IPM) :判别器受限于特定类别的函数 [60],例如,Wasserstein GAN (WGAN) 中的判别器受限于 1-Lipschitz。
- 非基于 IPM:鉴别器没有这样的约束。
- 正则化:指设计到损失函数中的额外惩罚或对网络进行的任何类型的归一化操作。
文章的其余部分组织如下:
- 1)介绍了 GAN 的相关综述工作,并说明了这些综述与本工作之间的区别,
- 2)简要介绍了 GAN,
- 3)回顾了文献中 GAN 的架构变体,
- 4)回顾了文献中 GAN 的损失变体,
- 5)介绍了一些主要在计算机视觉领域的基于 GAN 的应用,
- 6)总结了本研究中的 GAN 变体并说明他们的差异和关系,讨论了 GAN 未来研究的几种途径,
- 7)总结了这篇综述并预览了该领域未来可能的研究工作。
2 RELATED REVIEWS
以前有过 GAN 的综述论文,例如,在研究 GAN 的性能方面[71]。这项工作的重点是在大规模场景理解 (LSUN)-BEDROOM [145]、CELEBA-HQ128 [84] 和 CIFAR10 [70] 图像数据集上对不同类型的 GAN 进行基准测试的实验验证。结果表明,在将 GAN 应用于新数据集时,具有光谱归一化 [144] 的原始 GAN [45] 是一个很好的开始选择。该综述的一个限制是基准数据集没有以重要的方式考虑多样性。因此,基准结果倾向于更多地关注图像质量的评估,这可能会忽略 GAN 在生成不同图像方面的特性。其他工作 [51] 研究了不同的 GAN 架构及其评估指标。需要进一步比较不同架构变体的性能、应用、复杂性等。其他论文 [26, 52, 131] 侧重于研究最新的发展轨迹和 GAN 的应用。他们通过不同应用目标来比较 GAN 变体。
将我们的综述与其他现有综述文章进行比较,我们强调基于 GAN 变体的性能介绍,包括它们产生高质量和多样化图像的能力、训练的稳定性以及它们处理梯度消失问题的能力。我们通过基于架构和损失函数考虑的观点来处理这个阐述。这个观点很重要,因为它涵盖了 GAN 的基本挑战,它将帮助研究人员了解如何最好地为他们的 GAN 要求和特定应用选择架构和损失函数。
本综述的贡献有三方面:
- 通过解决三个重要问题来关注 GAN:(1) 高质量图像生成; (2) 多样化的图像生成;(3) 稳定训练。
- 提出了一种有用的 GAN 分类法,并通过 (1) 生成器和判别器的架构,例如网络架构、潜在空间和应用驱动设计,以及 (2) 训练的目标函数,包括损失设计的变体和正则化方法。
- GAN 变体的优缺点的比较和分析。
3 GENERATIVE ADVERSARIAL NETWORKS
典型的 GAN 包含两个组件,其中一个是区分真实图像和生成图像的鉴别器 (discriminator,D),而另一个是生成器 (generator,G) 创建图像以欺骗鉴别器。给定分布 z∼pz,G 将概率分布 pg 定义为样本 G(z) 的分布。GAN 的目标是学习生成器的分布 pg,该分布近似于真实数据分布 pr。针对 D 和 G 的联合损失函数执行 GAN 的优化:
m i n G m a x D E x ∼ p r l o g [ D ( x ) ] + E z ∼ p z l o g [ 1 − D ( G ( x ) ) ] (1) \mathcal min_G max_D \mathbb{E}_{x \sim p_r}log[D(x)] + \mathbb{E}_{z \sim p_z}log[1-D(G(x))] \tag{1} minGmaxDEx∼prlog[D(x)]+Ez∼pzlog[1−D(G(x))](1)
GAN 作为深度生成模型(DGM)家族的一员,由于与传统 DGM 相比的一些优势:
- GAN 能够产生比其他 DGM 更好的输出。与最著名的 DGM——变分自动编码器 (VAE) 相比,GAN 能够产生任何类型的概率密度,而 VAE 无法生成清晰的图像 [44]。
- GAN 框架可以训练任何类型的生成器网络。其他 DGM 可能对生成器有预先要求,例如,生成器的输出层是高斯[32,44,67]。
- 潜变量的大小没有限制。
这些优势使 GAN 在生成合成数据(尤其是图像数据)方面取得了最先进的性能。
4 ARCHITECTURE-VARIANT GANS
在本节中,我们回顾了有助于在前面提到的三个方面提高 GAN 性能的架构变体,即提高图像多样性、提高图像质量和稳定训练。可以在 [26, 51] 找到根据不同应用程序对架构变体的回顾。

4.1 Fully connected GAN
最初的基于能量的 GAN (EBGAN) 论文 [45] 使用全连接的神经网络作为生成器和判别器。这种架构变体适用于一些简单的图像数据集,即 MNIST [73]、CIFAR-10 [70] 和多伦多人脸数据集。如果在训练的内部循环中完成优化 D,由于判别器 D 的过拟合,作者建议优化 D 的 k 步和优化 G 的一步。在实践中,等式 (1) 可能会引发梯度消失问题以优化生成器,作者改为最大化 log D(G(z)) 以训练 G。这种修改等效地优化了 G 的 pg 和 pr 之间的反向 Kullback-Leibler (KL) 散度,这也导致了不对称问题(asymmetry issue)。我们将在第 5 节中详细讨论这一点。对于架构设置,maxout [41] 被用于鉴别器,而 ReLU 和 sigmoid 的混合用于生成器。对于更复杂的图像类型,它没有表现出良好的泛化性能。
4.2 Semi-supervised GAN
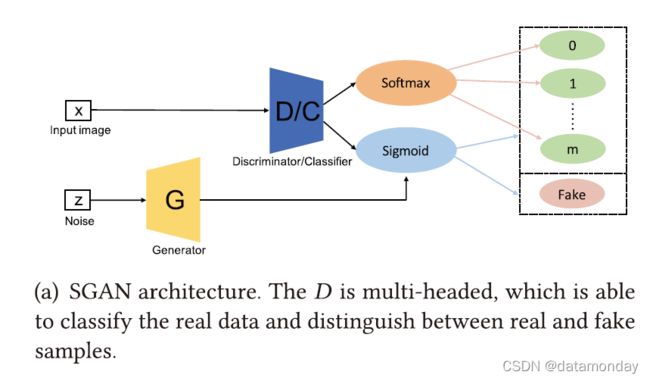
半监督GAN(Semi-supervised GAN,SGAN)是在半监督学习的背景下提出的[105]。半监督学习是介于监督学习和无监督学习之间的一个很有前途的研究领域。与监督学习(我们需要为每个样本标记)和无监督学习(不提供标记)不同,半监督学习具有用于一小部分示例的标记。与全连接 GAN(FCGAN)相比,SGAN 的判别器是多头的,即它具有 softmax 和 sigmoid,分别用于对真实数据进行分类并区分真假样本。作者在 MNIST 数据集上训练了 SGAN。结果表明,与原始 GAN 相比,SGAN 中的判别器和生成器都得到了改进。我们认为多头判别器的架构相对简单,限制了模型的多样性,即实验只在 MNIST 数据集上进行。判别器的更复杂架构可能会提高模型的性能。
4.3 Bidirectional GAN

传统的 GAN 无法学习逆映射,即将数据投射回潜在空间。双向 GAN (BiGAN) 就是为此目的而设计的 [35]。如图 3© 所示,整体架构由编码器 (E)、生成器 (G) 和鉴别器 (D) 组成。 E 将真实样本数据编码为 E(x),而 G 将 z 解码为 G(z)。 D 旨在评估每对 (E(x), x) 和 (G(z), z) 之间的差异。 由于 E 和 G 不直接通信,即 E 永远不会看到 G(z) 而 G 永远不会看到 E(x)。作者证明了编码器和解码器必须学会相互反转以欺骗原始论文中的鉴别器。看看这样的模型是否能够在未来的工作中处理对抗样本将会很有趣。 BiGAN 在 MNIST 和 ImageNet 数据集上进行了训练。使用参数为 β1 = 0.5 和 β2 = 0.999 的 Adam 优化器。批量大小为 128,权重衰减为 2.5 × 10−5,适用于所有参数。还应用了BN层。
4.4 Conditional GAN
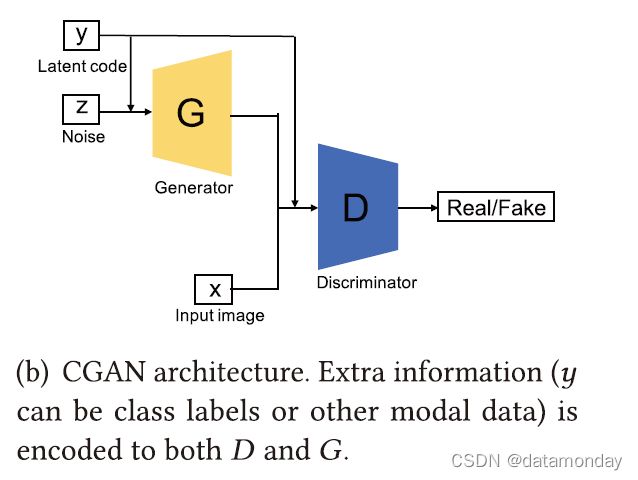
CGAN 的创新在于通过给每个判别器和生成器提供类标签 [99] 来调节判别器和生成器。如图 3(b) 所示,CGAN 将额外信息 y(y 可以是类标签或其他模态数据)提供给鉴别器和生成器。应该注意的是,在与编码的 z 和编码的 x 连接之前,y 通常在生成器和鉴别器内部进行编码。例如,在原始工作的 MNIST 实验中,在生成器中相互组合之前(组合层维数为 200 + 1000 = 1200),z 和 y 分别映射到层大小为 200 和 1,000 的隐藏层。通过这样做,CGAN 增强了判别器的判别能力。 CGAN 的损失函数与 FCGAN 略有不同,如等式 (2) 所示,其中 x 和 y 受 z 制约。受益于额外编码的 y 信息,CGAN 不仅能够处理单模态图像数据集,还能够处理多模态数据集,例如 Flickr,其中包含标记的图像数据及其相关的用户生成的元数据,即特别是用户标签,这使 GAN多模态数据生成领域。作者在 MNIST 和 Yahoo Flickr Creative Common 100M (YFCC 100M) 上试验了 CGAN。对于 MNIST 数据集,该模型使用随机梯度下降 (SGD) 进行训练,小批量大小为 100,初始学习率为 0.1,以指数方式下降到 1×10−6,衰减因子设置为 1.00004。生成器和判别器都以 0.5 的概率使用了 Dropout。 Momentum 的初始值为 0.5,最后增加到 0.7。类标签被编码为 one-hot 向量并馈送到 G 和 D。在 YFCC 100M 实验方面,训练超参数与 MNIST 实验中的设置相同。尽管 CGAN 通过引入编码标签增强了判别器的判别能力,但一些编码标签仍然与图像没有联系
![]()
4.5 InfoGAN
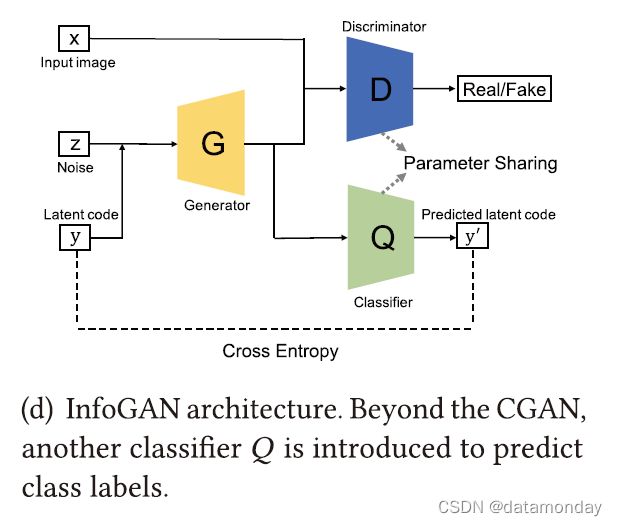
InfoGAN是在CGAN基础上提出的,它通过最大化条件变量和生成数据之间的互信息,以无监督的方式学习可解释的表示。为了实现这一点,InfoGAN引入了另一个分类器Q (图3(d)) 来预测 G(z|y) 给出的y。这里G和Q的组合可以理解为一个自动编码器,我们的目标是找到使y和y’之间的交叉熵最小化的嵌入(G(z|y))。然而,D执行与FCGAN相同的工作,区分从G或从真实数据生成的样本。为了降低计算成本,Q和D共享除了最后一个全连接层之外的所有卷积层,这使得鉴别器能够区分真假样本并恢复信息y。与原始GAN架构相比,这可以提高InfoGAN的鉴别能力。InfoGAN中使用的损失是CGAN损失的正则化
![]()
其中 V(D,G) 是CGAN的目标,只是鉴别器不将y作为输入,I(·)是互信息。作者使用MNIST、三维(3D)人脸图像[109]、3D椅子图像[6]、SVHN和CelebA对InfoGAN进行了实验。所有数据集共享相同的训练设置,其中使用了Adam优化器并应用了BN层。泄漏率为0.1的Leaky ReLU应用于鉴别器,而ReLU用于生成器。D的学习速率设置为2×10-4,而g的学习速率设置为1×10-3,λ设置为1。我们认为模型的多样性非常有限,因为除了最后一层,D和Q的参数是彼此共享的。可以有效地研究更复杂的Q设置。
4.6 Auxiliary Classifier GAN
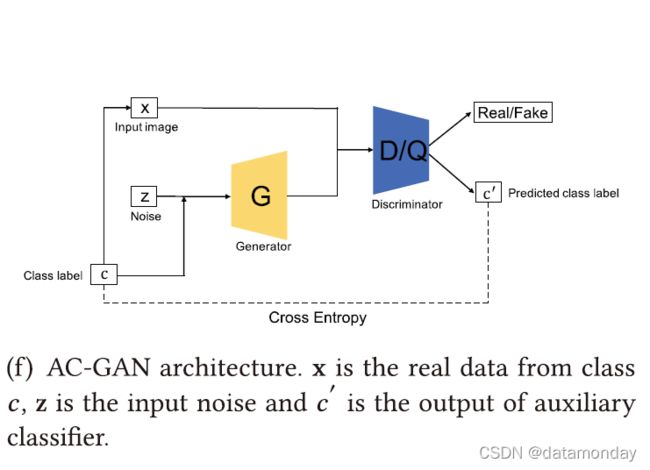
辅助分类器GAN (AC-GAN) [106]与CGAN和InfoGAN非常相似。它在结构中包含一个辅助分类器,如图3(f) 所示。在AC-GAN中,除了z之外,每个生成的样本都有相应的类标签c。应该注意的是,AC-GAN与前两个架构变体(CGAN和InfoGAN)之间的区别是这里的附加信息,它仅指类标签,而前两个可以是其他域数据。因此我们使用 c 和 c’ 在AC-GAN中明确标记与前两个变体的差异。AC-GAN中的鉴别器由鉴别器D(区分真假样本)和分类器Q(对真假样本进行分类)组成。与InfoGAN类似,鉴别器和分类器共享除最后一层之外的所有权重。AC-GAN的损失函数可以通过考虑鉴别器和分类器来构建,其可以表述为
![]()
其中,D通过最大化 LS + LC 进行训练,G通过最大化 LC - LS 进行训练。作者在CIFAR-10和ImageNet数据集上为所有1000个类训练了AC-GAN。对于CIFAR-10和ImageNet,使用Adam对模型进行训练,D、G、Q的α= 2×104,β1 = 0.5,β2 = 0.999,小批量设置为100。模型性能和相关实验的细节可在原始论文[106]中找到。AC-GAN提高了生成图像的视觉质量,并且具有高的模型多样性。然而,这些改进依赖于大规模的标记数据集,这可能在一些现实世界的应用中带来挑战。应该进一步研究AC-GAN和无监督或自监督方法的组合。在第4.13节中,我们还介绍了一种GAN,即标签噪声鲁棒性GAN(rGANs)。
4.7 Laplacian Pyramid of Adversarial Networks
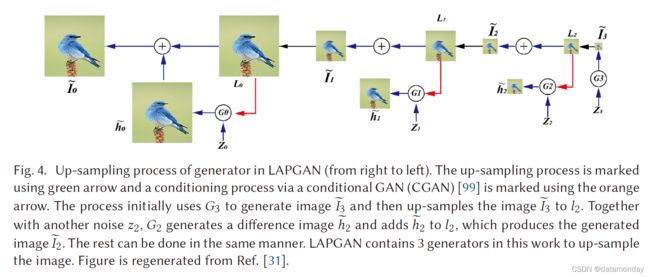
拉普拉斯金字塔对抗网络 (LAPGAN) 被提出用于从较低分辨率的输入GAN产生较高分辨率的图像[31]。拉普拉斯金字塔[16]是一种图像编码方法,它使用许多尺度但形状相同的局部算子作为基本函数。LAPGAN利用拉普拉斯金字塔框架[16]内的级联CNN产生高质量图像,如图4所示(从右到左)。LAPGAN使用拉普拉斯金字塔来对图像进行上采样,而不是使用反卷积过程 (在深度卷积GAN (DCGAN)中使用的) 来对前一层的内核输出进行上采样。
首先,LAPGAN 使用第一个生成器生成一个非常小的图像,这可以缓解生成器的不稳定性问题,然后通过使用拉普拉斯金字塔对该图像进行上采样。然后将上采样的图像馈送到下一个生成器,以产生图像差异和图像差异的总和。输入图像将是生成的图像。可以看出,只有图 4 中的 G3 用于生成图像,但维度非常小,有利于稳定训练。对于较大的图像,生成器用于生成图像差异,这比相同大小的原始图像要简单得多。这种结构有助于稳定训练和高分辨率建模。 CIFAR10(28 × 28 像素)、STL(96 × 96 像素)和 LSUN(64 × 64 像素)用于生成。每个数据集的拉普拉斯金字塔上采样过程为 8 → 14 → 28 (CIFAR10)、8 → 16 → 32 → 64 → 96 (STL) 和 4 → 8 → 16 → 32 → 64 (LSUN)。鉴别器使用三个隐藏层和一个 sigmoid 输出,而生成器使用带有 ReLU 和BN的五层 CNN。使用了线性输出层。在实验中部署了初始学习率为 0.02 的 SGD,在每个 epoch 降低了(4×10-5)倍。动量从 0.5 开始,每个时期增加 0.0008,最大为 0.8。当前结构包括用于生成图像的多个生成器,并且这些生成器之间的连接尚未建立。在 4.10 节中,我们介绍了一种更高级的策略,它以渐进的方式训练模型,即 PROGAN。
4.8 Deep Convolutional GAN
DCGAN [113] 是第一个为 G 应用反卷积神经网络架构的工作。提出了反卷积来可视化 CNN 的特征,并在 CNN 可视化方面显示出良好的性能 [148]。 DCGAN 为 G 部署了反卷积操作的空间上采样能力,这使得使用 GAN 生成更高分辨率的图像成为可能。与原始 FCGAN 相比,DCGAN 的架构有一些关键的修改,这有利于高分辨率建模和稳定训练。首先,DCGAN 将任何池化层替换为用于鉴别器的跨步卷积(strided convolutions)和用于生成器的分数跨步卷积(fractional-strided convolutions )。其次,判别器和生成器都使用BN,这有助于定位以零为中心的生成样本和真实样本,即生成样本和真实样本的相似统计量。第三,ReLU 激活用于除输出之外的所有层,输出使用 Tanh,而 Leaky ReLU 激活用于判别器的所有层。在这种情况下,当生成器从鉴别器接收梯度时,Leaky ReLU 激活将防止网络停滞在“死亡状态”情况(例如,ReLU 层中的输入小于 0)。 DCGAN 在 LSUN [145]、ImageNet [30] 和定制组装的人脸数据集上进行训练。所有模型都使用 SGD 进行训练,小批量大小为 128。所有权重均从标准偏差为 0.02 的零中心正态分布初始化。使用了一个 Adam 优化器,学习率为 0.0002,动量项为 0.5。所有模型的 Leaky ReLU 的斜率都设置为 0.2。使用 64 × 64 像素图像训练模型。 DCGAN 是 GAN 历史上一个非常重要的里程碑,反卷积思想成为 GAN 生成器中使用的主要架构的中流砥柱。由于模型容量的限制和 DCGAN 中使用的优化,它只在低分辨率和较少多样性的图像上成功。
4.9 Boundary Equilibrium GAN
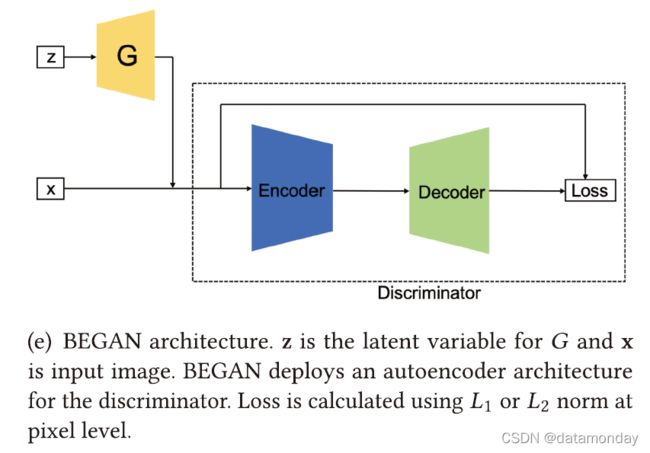
边界平衡 GAN (Boundary Equilibrium GAN,BEGAN) 使用自动编码器架构作为鉴别器,该架构首先在 EBGAN [151] 中提出。如图 3(e) 所示,可以分别为 G 和 D 生成自动编码器损失。在训练自动编码器 (D) 时,目标是最大化真实图像的重建损失并最大化生成图像的重建损失,即最小化 E [L(x)] - E [L(G(z))]。在训练 G 时,目标是最小化 E [L(G(z))]。通过引入自编码器,作者证明了上述重构损失的优化等效于 Wasserstein 距离。作者还提出使用超参数 γ = E[L(G (z))] E[L(x )] ,γ ∈ [0, 1] 来控制生成器和判别损失之间的平衡,这允许平衡分配给生成器和鉴别器的工作量,即控制各种生成的人脸。原始论文中的实验表明,较小的 γ 会使 G 生成看起来过于均匀的面。随着 γ 值的增加,人脸的多样性也会增加,但这也会引入伪影(artifacts)。整体损失函数总结在等式(5)中,

其中 L(·) 表示自动编码器重建损失 (L2),kt ∈ [0, 1] 是一个变量,用于控制 L(G(z)) 对损失的惩罚程度。 k 初始化为 0 并由 λk 控制(λk 可以解释为 k 的学习率,在原始论文中设置为1 × 10−3)。
4.10 PROGAN
PROGAN 涉及网络架构扩展的渐进步骤[64]。该架构使用了参考文献 [116] 中首次提出的**渐进式神经网络(progressive neural networks)**的思想。该技术不会遗忘,并且能够通过横向连接将先验知识部署到先前学习的特征。因此,它被广泛应用于学习复杂的任务序列。图 5 展示了 PROGAN 的训练过程。训练从低分辨率 4 × 4 像素图像开始。 G 和 D 随着训练的进展开始增长。
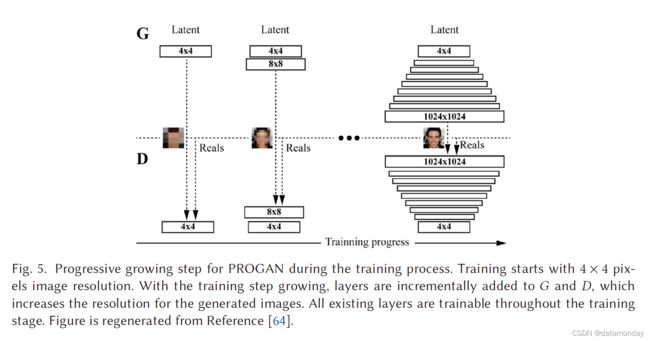
在整个增长过程中,所有变量都是可训练的。这种渐进式训练策略使两个网络的学习都更加稳定。通过一点一点地提高分辨率,与从潜在向量中发现映射的最终目标相比,网络不断被询问更简单得的问题。当前所有最先进的 GAN 都采用这种类型的训练策略,并产生了令人印象深刻、可信的图像 [13、64、65]。作者开始用 4 × 4 像素图像训练 PROGAN,并逐渐将两倍大小的层添加到 G 和 D,如图 5 所示,其中新层平滑地淡化。多尺度训练图像是通过使用拉普拉斯金字塔表示 [16] 生成的,即类似于 LAPGAN。模型在 CIFAR10(32 × 32 像素图像)、LSUN(256 × 256 像素图像)和 CelebA-HQ(1,024 × 1,024 像素图像)上进行了训练。除了最后一层(使用线性激活)之外,D 和 G 的所有层都使用了泄漏率为 0.2 的 Leaky ReLU。仅在生成器中的每个 Conv 3 × 3 层之后对特征向量进行像素归一化,即在任一网络中都没有批量归一化、层归一化或权重归一化。使用 α = 1 × 10−3、β1 = 0、β2 = 0.99 和 ϵ = 1 × 10−8 的 Adam 优化器来训练 D 和 G。随着图像像素的增加,mini-batch 大小逐渐减小以保存在内存上,即批量大小为 16,用于 4 × 4 到 8 × 8、256 × 256 → 14、512 × 512 → 6 和 1,024 × 1,024 → 3。WGAN-GP [136] 损失用于优化 D和 G。
4.11 Self-attention GAN
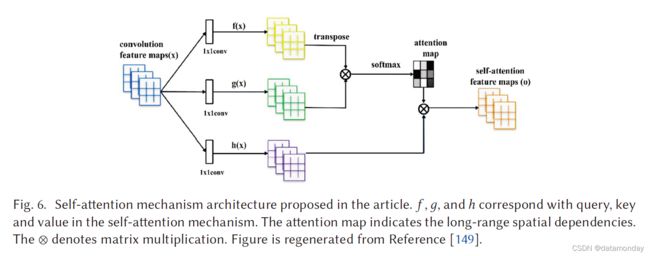
传统的 CNN 只能捕获局部空间信息,感受野可能无法覆盖足够的结构,这导致基于 CNN 的 GAN 难以学习多类图像数据集(例如 ImageNet),并且生成图像中的关键组件可能会发生偏移,例如,人脸生成图像中的鼻子可能不会出现在正确的位置。已经提出了自注意力机制,以确保在不牺牲 CNN [129] 的计算效率的情况下确保大的感受野。自注意力 GAN (SAGAN) 在 GAN [149] 的鉴别器和生成器架构的设计中部署了自注意力机制(见图 6)。得益于自注意力机制,SAGAN 能够学习生成图像的全局、长期依赖关系。它在基于 ImageNet 数据集的多类图像生成方面取得了出色的性能。作者在 ImageNet 数据集(128 × 128 像素图像)上训练了 SAGAN。 D 和 G 都应用了光谱归一化(Spectral normalization) [100]。
在生成器中使用 条件BN(Conditional batch normalization),而在鉴别器中使用 批量投影(batch projection)。使用了 β1 = 0 和 d β2 = 0.9 的 Adam 优化器,判别器的学习率为 4 × 10-4,生成器的学习率为 1 × 10-4。作者还证明了在大特征图上为判别器和生成器部署自注意力机制更有效,即使用 32 × 32 大小的特征图部署自注意力机制可以实现最佳的FID分数,具有 64 × 64 大小的特征图部署自注意力机制可以实现最佳的 Inception 分数,这表明自注意力机制是对大型特征图的卷积的补充。因此,我们建议将 self-attention 机制应用于大型特征图,以提高 GAN 的多样性。
4.12 BigGAN
BigGAN [13] 在 ImageNet 数据集上也取得了最先进的性能。它的设计基于 SAGAN,并且已经证明性能可以产生 GAN 训练的扩展,即增加每层的通道数量和增加批量大小。作者在 ImageNet 上以 128 × 128、256 × 256 和 512 × 512 的分辨率训练模型。这项工作的训练设置遵循 SAGAN,其中学习率减半,每 G 步训练两个 D 步。探索了潜在变量 z 的不同选择,作者指出 Bernoulli {0, 1} 和 Censored Normal max(N (0, I ), 0) 在不截断的情况下效果最佳。截断技巧包括在训练期间使用与在推理或图像合成期间不同的生成器分布作为潜在空间。在 BigGAN 中,训练时使用高斯分布,推理时使用截断高斯分布。这种截断技巧提供了图像质量和图像多样性之间的折衷。更窄的采样范围会导致更好的质量,而更大的采样范围会导致采样图像的多样性。我们总结了 BigGAN 上的以下操作,这些操作使 BigGAN 扩大了架构。
- 1)自注意力模块和折页损失:BigGAN 使用带有来自 SAGAN 的注意力模块的模型架构,并通过折页损失进行训练,其中自注意力有助于模型的多样性,而折页损失使训练更稳定。
- 2)类条件信息:类信息通过类条件BN层提供给生成器模型。
- 3)更新鉴别器多于生成器:BigGAN 对此稍作修改,并在每次训练迭代中更新生成器模型之前两次更新判别器模型。
- 4)模型权重的移动平均:在生成用于评估的图像之前,使用移动平均对先前训练迭代中的模型权重进行平均。
- 5)网络上的一些操作:正交权重初始化、更大的批大小、skip-z 连接(从潜在层跳过连接到多层)和共享嵌入,即作者证明这些操作都能够帮助改进表现。作者还描述了针对如此大规模的不稳定性分析。更多细节可以在原始论文中找到。
4.13 Label-noise rGANs
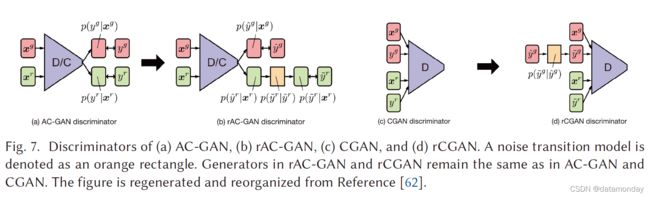
我们分别在 4.4 节讨论了 CGAN,在 4.6 节讨论了 AC-GAN,它们都具有学习解耦表示(disentangled representation)的能力并提高 GAN 的判别能力。然而,训练模型需要大规模的标记数据集,这在现实世界的场景中提出了一些挑战。 [62] 提出了一个名为 label-noise rGANs 的 GAN 家族,它结合了一个噪声转换模型,即使在提供有噪声的训练标签时也能够学习干净的标签条件生成分布。讨论了两种变体,它们是 AC-GAN (rAC-GAN) 的扩展和 CGAN (rCGAN) 的扩展,如图 7 所示。rGAN 的核心部分是噪声转换模块 p ( y ~ ∣ y ^ ) p(\tilde{y}| \hat{y}) p(y~∣y^) ( y ~ \tilde{y} y~ 是噪声标签, y ^ \hat{y} y^ 是干净标签) 引入判别器,其中 p ( y ~ = j ∣ y ^ = i ) = T ( i , j ) p(\tilde{y} = j| \hat{y} = i) = T(i, j) p(y~=j∣y^=i)=T(i,j) 因为 T T T 是噪声转移矩阵 T ( i , j ) ∈ [ 0 , 1 ] ( c × c ) T(i, j ) ∈ [0, 1]^{(c×c)} T(i,j)∈[0,1](c×c) ( ∑ i T i , j = 1 \sum_i T_{i, j} = 1 ∑iTi,j=1, c c c 是类数)。作者在 CIFAR-10 和 CIFAR-100 上训练了 rGAN。作者证明 rAC-GAN 和 rCGAN 在 CIFAR-10 上的性能优于原始架构,并且还表现出对标签噪声的鲁棒性。然而,在 CIFAR-100 中,当向标签引入高噪声时,它们的性能会下降。我们认为这样的框架在遇到更复杂的数据集时仍然有些局限性,例如 ImageNet,未来需要进一步研究。
4.14 Your Local GAN
这项工作 [29] 引入了一个新的局部稀疏注意力层(local sparse attention layer),它保留了二维几何和局部性。为了展示这个想法的适用性,他们用一种新的结构替换了 SAGAN [129] 的密集注意力层。关键创新是:
- 1)注意力模式得到了信息流图的信息理论框架的良好支持;
- 2)Your Local GAN (YLG)-SAGAN 被引入并实现了卓越的性能,将训练时间减少了大约40%;
- 3)他们使对损失执行梯度下降的自然反演过程适用于更大的模型,而不是以前在小型 GAN 上的工作。作者使用的一种特定技巧称为 Enumerate、Shift、Apply (ESA)。他们修改一维稀疏化以通过枚举图像的像素来了解二维局部性,方法是基于它们与位置 (0, 0) 像素的曼哈顿距离(使用行优先级打破绑定),移动任何给定的索引维稀疏化以匹配曼哈顿距离枚举而不是重塑枚举,并将这种基于二维局部性的一维稀疏化模式应用于图像的一维重塑版本。
然而,我们认为这项工作中存在着两个相互冲突的目标。该方法的目的一方面是为了提高计算和统计效率,使网络尽可能稀疏,另一方面仍然需要支持良好和完整的信息流。
4.15 AutoGAN
AutoGAN [43] 将神经架构搜索 (NAS) 算法引入生成对抗网络 (GAN)。生成器架构变化的搜索空间通过 RNN 与参数共享和动态重置一起引导,以加速该过程。他们使用 Inception 分数作为奖励,并引入多级搜索策略以渐进式的方式执行 NAS。作者使用折页损失来训练共享 GAN,遵循谱归一化 GAN (SN-GAN) 的训练设置。
整个管道很有见地,但也带来了结合 NAS 和 GAN 的新的挑战。 NAS 仍有待针对标准分类问题进行优化,更不用说 GAN 带来的不稳定训练问题。尽管在文章中 AutoGAN 展示了 NAS 用于 GAN 架构的有希望的结果,与上面介绍的手动设计 GAN 架构相比,这是非常独特的。我们认为它还有两个关键问题有待解决:
- 生成器的搜索空间有限,不讨论判别器的搜索策略。
- AutoGAN 尚未在高分辨率图像生成数据集上进行测试。因此,我们对这种方法的适用性没有直观的估计。当前的图像生成任务是初步的。
4.16 MSG-GAN
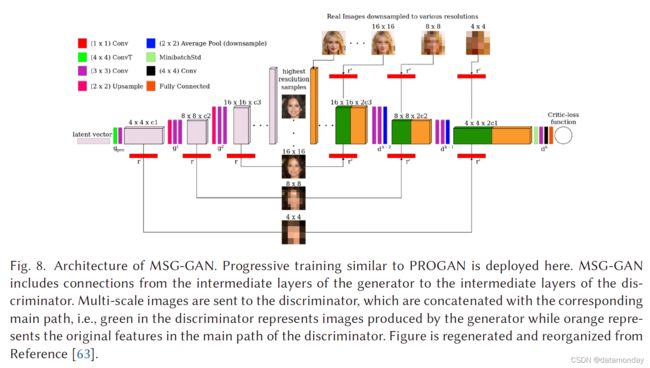
众所周知,GAN 很难适应不同的数据集。Karnewar等人认为造成这种情况的原因之一是当真实和虚假分布的支持没有足够的重叠时,从鉴别器传递到生成器的梯度变得无信息。他们提出 MSG-GAN [63] 作为处理此类问题的一种手段。如图 8 所示,生成器和判别器的潜在空间连接起来,以便在生成器和判别器之间共享更多信息。更具体地说,每个转置卷积步骤(图 8 中的三个步骤)中的激活通过操作 r 映射到不同尺度的图像,即在这种情况下为 1×1 卷积。类似地,映射的图像然后由 r’ 编码为激活,它与由真实图像编码的激活连接(concatenation)。这种连接使 D 和 G 之间可以共享更多信息,实验结果证明了这些好处。作者在多个数据集上训练了 MSG-GAN,即 CIFAR10、Oxford flowers、LSUN、Indian Celebs、CelebA-HQ (1,024 × 1,024) 和 FFHQ (1,024 × 1,024)。所有数据集的超参数设置几乎相同。具体来说, z ∈ R 512 × 1 z \in \mathbb{R}^{512×1} z∈R512×1 是从标准正态分布中得出的。学习率为 0.003 的 RMSprop 用于 D 和 G。 WGAN-GP 损失用于训练网络。虽然 MSG-GAN 在几个图像数据集上取得了非常好的结果,但 MSGGAN 生成多样化图像的能力尚未经过测试,我们发现 CIFAR10 上的结果不如其他数据集好。我们猜测这可能是由 G 和 D 之间的连接引起的,这可能将 G 上的多样性限制为来自 G 和 D 的激活。图像上的多样性可能导致不一致的匹配激活,这对训练产生负面影响。更多的开发可能会解决这个问题,例如通过添加自注意力模块。
4.17 Summary
我们提供了架构变体 GAN 的概述,重点是它们如何在图像质量、模式多样性和不稳定训练问题这三个关键挑战方面潜在地提高性能。图 9(a) 展示了本节讨论的 2014 年至 2020 年架构变体 GAN 的足迹。可以看出,在不同的 GAN 变体中存在大量互连。图 9(b) 说明了三个挑战的相对表现。我们建议感兴趣的读者查阅原始文章,以更深入地了解每个 GAN 变体的理论和性能。在这里,我们快速回顾一下 GAN架构变体是如何应对挑战的(定量结果总结在第 7 节的表 2 中)。

图像质量(Image Quality) GAN 的基本目标之一是生成具有高图像质量的逼真图像。
- 由于架构容量有限,原始 GAN(FCGAN)仅应用于 MNIST、Toronto face 和 CIFAR-10 数据集。
- DCGAN 和 LAPGAN 在设计中引入了反卷积和上采样过程。两者都使模型能够生成更高分辨率的图像。
- 其余的架构变体(即 BEGAN、PROGAN、SAGAN 和 BigGAN)都对损失函数进行了一些修改,我们将在本文后面部分讨论这些修改,这些也有利于产生更好的图像质量。
- 仅关于架构组件,BEGAN 使用自动编码器架构作为判别器,在像素级别比较生成的图像和真实图像。这有助于生成器生成易于重构的数据。
- PROGAN 利用更深层次的架构,模型随着训练的进行而扩展。这种渐进式训练策略提高了判别器和生成器的学习稳定性,因此模型更容易学习如何生成高分辨率图像。
- SAGAN 主要受益于谱归一化,我们将在下一节中讨论。
- BigGAN 证明了高分辨率图像的生成可以从具有更大批量的更深层模型中受益。
梯度消失(Vanishing Gradient) 改变损失函数是目前解决此类问题的唯一方法。这里的一些架构变体避免了梯度消失的问题,但这仅仅是因为它们使用了不同的损失函数。我们将在下一节探讨这一点。
模式多样性(Mode Diversity) 这是 GAN 最具挑战性的问题。GAN 很难生成逼真的多样化图像,例如自然图像。
- 在 GAN 的架构变体方面,只有 SAGAN 和 BigGAN 明确解决了这个问题。
- 得益于自注意力机制,SAGAN 和 BigGAN 中的 CNN 可以处理一个大的感受野,从而克服生成图像中的移动组件问题。这使得这种类型的 GAN 能够产生不同的图像。
5 LOSS-VARIANT GANS
GAN 中另一个显着影响性能的设计决策是等式 (1) 中损失函数的选择。虽然最初的 GAN 工作 [45] 已经证明了 GAN 训练的全局最优性和收敛性,但它仍然突出了训练 GAN 时可能出现的不稳定性问题。该问题是由参考文献 [45] 中所述的全局最优性标准引起的。当任何 G 达到最优 D 时,就实现了全局最优性。当方程 (1) 中的损失的 D 的导数等于 0 时,就实现了最优 D。所以我们有
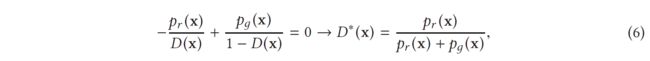
其中 x x x 代表真实数据和生成数据, D ∗ ( x ) D∗(x) D∗(x) 是最优判别器, p r ( x ) p_r(x) pr(x) 是真实数据分布, p g ( x ) p_g(x) pg(x) 是生成数据分布。到目前为止,我们有最优的鉴别器 D,当我们有最优的 D 时,G 的损失可以通过将 D∗(x) 代入等式 (1) 来可视化,
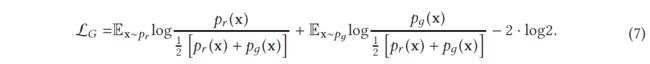
等式 (7) 展示了当鉴别器被优化时 GAN 的损失函数,它与两个重要的概率测量指标相关。一是KL散度,定义为
![]()
另一个是 Jensen-Shannon (JS) 散度,表示为
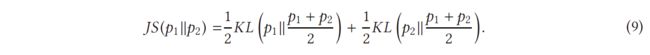
因此,方程(7)中关于最优 D 的 G 损失可以重新表述为
![]()
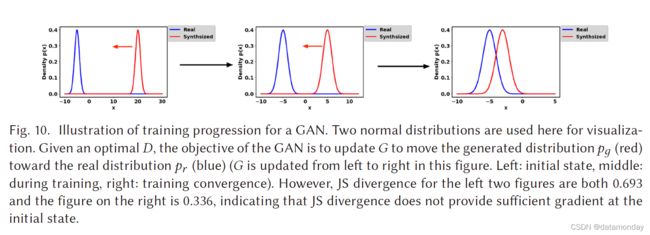
这表明 G 的损失现在同样成为 pr 和 pg 之间的 JS 散度的最小化。随着逐步训练D,G的优化将更接近于 pr 和 pg 之间的 JS 散度的最小化。我们现在可以开始描述训练中的不稳定问题,其中 D 往往很容易战胜 G。这种不稳定的训练问题实际上是由方程 (9) 中的 JS 散度引起的。 给定一个最优的 D,等式 (10) 的优化目标是使 pg 向 pr 移动(见图 10)。从左到右的三个图的 JS 散度分别为 0.693、0.693 和 0.336,这表明如果 pr 和 pg 之间没有重叠,则 JS 散度保持不变(log2 = 0.693)。图 11(a) 展示了 JS 散度的变化及其梯度对应于 pr 和 pg 之间的距离。可以看出,JS散度是恒定的,当距离大于5时,其梯度几乎为0,说明训练过程对G没有任何影响。仅当 pg 和 pr 有大量重叠时,用于训练 G 的 JS 散度梯度非零,即当 D 接近最优时,G 将出现梯度消失。在实践中,pr 和 pg 不重叠或重叠可忽略不计的可能性非常高 [3]。

最初的 GAN 工作 [45] 还强调了 − E x ∼ p g l o g [ D ( x ) ] -E_{x∼p_g} log[D(x)] −Ex∼pglog[D(x)] 的最小化,用于训练 G 以避免梯度消失。但是,这种训练策略会导致另一个称为**模式丢弃(mode dropping)**的问题。首先,让我们检查 K L ( p g ∣ ∣ p r ) = E x ∼ p g l o g p g p r KL(pg || pr) = \mathbb{E}_{x∼p_g} log \frac{p_g} {p_r} KL(pg∣∣pr)=Ex∼pglogprpg 。使用最优判别器 D ∗ D∗ D∗, K L ( p g ∣ ∣ p r ) KL(pg || pr) KL(pg∣∣pr) 可以重新表述为
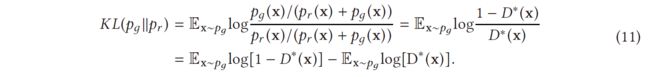
现在可以通过转换等式 (11) 中两侧的顺序来说明 G 的替代损失形式
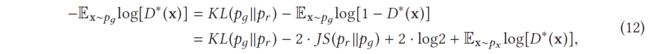
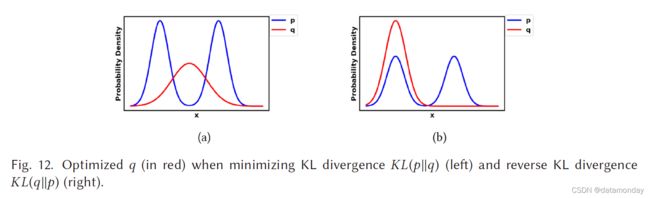
其中等式 (12) 中 G 的替代损失仅受前两项(后两项是常数)的影响,但是,该损失函数由 K L ( p g ∣ ∣ p r ) KL(pg || pr) KL(pg∣∣pr) 控制,因为 J S ( p g ∣ ∣ p r ) JS(pg || pr) JS(pg∣∣pr) 如左侧图 11(a) 所示,边界在 [0, log 2] 内。可以看出,公式 (12) 中的第一项是反向KL散度,其中反向优化的pg与KL散度优化的pg完全不同。图 12 通过对 p 使用两个高斯和对 q 使用单个高斯的混合来说明这种差异。当 p 具有多个模式时,q 尝试将所有模式模糊化以在所有模式上放置一个高概率质量,如图 12(a) 所示。然而,图 12(b) 显示 q 选择恢复单个高斯以避免将概率质量置于两个高斯中心的低概率区域。因此,反向 KL 散度的优化将导致 GAN 训练期间的模式崩溃。这在下面突出显示,
G对两次表现不佳的惩罚是完全不同的。表现不佳的第一个例子是 G 没有产生合理范围的样本,但受到的惩罚非常小。第二个表现不佳的例子涉及 G 产生不可信的样本,但惩罚非常大。第一个示例生成的样本缺乏多样性,而第二个示例生成的样本不准确。考虑到第一种情况,G 生成重复但“安全”的样本,而不是冒险生成多样化但“不安全”的样本,这会导致模式崩溃问题。总之,使用等式(1)中的原始损失将导致训练 G 的梯度消失,而使用等式(12)中的替代损失将导致模式崩溃问题。这类问题不能通过简单地改变架构来解决。因此,可以说 GAN 的最终问题源于损失函数的设计,而这种重新设计损失函数的创新想法可能会解决这个问题。
5.1 Wasserstein GAN
WGAN [4] 通过使用 Earth Mover (EM) 或 Wasserstein-1 [115] 距离作为优化的损失度量,成功解决了原始 GAN 的两个问题。 EM 距离定义为:
![]()
其中 ∏ ( p r , p g ) \prod (p_r,p_g) ∏(pr,pg) 表示所有联合分布的集合, γ ( x , y ) γ (x, y) γ(x,y) 表示其边缘为 pr 和 pg。与 KL 和 JS 散度相比,即使 pr 和 pg 不重叠,EM 也能够反映距离。它也是连续的,因此能够为训练生成器提供有意义的梯度。图 11(b) 说明了 WGAN 梯度与原始 GAN 的比较。值得注意的是,WGAN 具有平滑梯度,可用于训练跨越整个空间的生成器。然而,等式 (13) 中的下确界是难以处理的,但创建者证明了 Wasserstein 距离可以替代地估计为
![]()
其中 fw 可以由 D 实现,但有一些限制(有关详细信息,感兴趣的读者可以参考原始工作 [4]),z 是 G 的输入噪声。这里是 D 中的参数,其中 D 旨在最大化方程 (14) 使优化距离等于 Wasserstein 距离。当 D 被优化时,等式 (13) 将成为 Wasserstein 距离,而 G 旨在最小化它。所以 G 的损失是
![]()
WGAN 和原始 GAN 的一个重要区别是 D 的功能。原始工作中的 D 用作二元分类器,但 WGAN 中使用的 D 的目的是拟合 Wasserstein 距离,这是一个回归任务。因此,D 的最后一层中的 sigmoid 在 WGAN 中被移除。作者在 LSUN 数据集上以 64 × 64 分辨率训练了 WGAN。重要的是,如果基于动量的优化器如 Adam(使用 β1 > 0),WGAN 的训练将不稳定。因此,RMSProp 用于训练 WGAN。
5.2 WGAN-GP
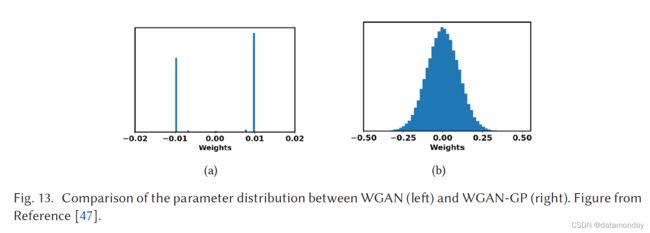
尽管 WGAN 已被证明在提高 GAN 训练的稳定性方面取得了成功,但它并不能很好地推广到更深层次的模型。实验已经确定,由于参数裁剪,大多数 WGAN 参数都定位在 -0.01 和 0.01(参见图 13)。这将大大降低 D 的建模能力。WGAN-GP 已被提议使用梯度惩罚来限制鉴别器的 ∣ ∣ f ∣ ∣ L ≤ K ||f||_L ≤ K ∣∣f∣∣L≤K [47],并且鉴别器的修正损失现在变为
![]()
其中 xr 是从真实数据分布 pr 中抽取的样本数据,xg 是从生成的数据分布 pg 中抽取的样本数据,并且 p^x 沿着从真实数据分布 pr 和生成的数据分布 pg。前两项是 WGAN 中的原始损失,最后一项是梯度惩罚。与 WGAN 相比,WGAN-GP 展示了更好的训练参数分布(图 13)以及在 GAN 训练期间更好的稳定性能。在 WGAN-GP 之前,GAN 的成功训练只发生在由判别器和生成器中的几层组成的模型上,即 DCGAN 在 D 中使用四个卷积层,在 G 中使用 4 个反卷积层。WGAN-GP 成功证明了稳定训练通过使用 ResNet-101 架构作为主干。这对用于大规模图像生成的 GAN 的研究产生了重大影响,即 PROGAN、BigGAN。如上一节所述,WGAN 在使用 Adam 等基于动量的优化器时存在稳定性问题。相比之下,WGAN-GP 通过使用 Adam 优化器展示了稳定的训练,甚至使用相同的训练设置实现了更快的收敛。使用具有 32 × 32 图像分辨率的 ImageNet 数据集、具有 128 × 128 图像分辨率的 LSUN 数据集和具有 32 × 32 图像分辨率的 CIFAR-10 对 WGAN-GP 进行了实验性探索。实验中使用了 α = 1 × 10−4、β1 = 0、β2 = 0.9 的 Adam 优化器。学习率为 2 × 10−4,批量大小为 64。作者发现分段线性激活函数,例如 ReLU、Leaky ReLu 和平滑激活函数,例如 Tanh 都可以稳定地训练 WGAN-GP。
5.3 Least Square GAN (LSGAN)
最小二乘 GAN (LSGAN) 是参考文献 [94] 中提出的一种新方法,用于从判别器确定的决策边界的角度解决 G 的梯度消失问题。这项工作认为,对于那些远离决策边界的生成样本,原始 GAN 的 D 的决策边界会在 G 的更新中惩罚非常小的错误。创建者建议对 D 使用最小二乘损失,而不是原始 GAN 论文 [45] 中所述的 sigmoid 交叉熵损失。建议的损失函数定义为
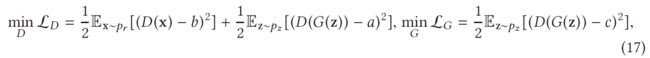
其中a是生成样本的标签,b是真实样本的标签,c是G希望D错误地将生成的样本识别为真实样本的超参数。这种修改有两个好处:
- 1)D生成的新决策边界惩罚了那些远离决策边界的生成样本产生的大错误。这会将那些“糟糕”的生成样本推向决策边界。这在生成改进的图像质量方面是有益的。
- 2)对远离决策边界的生成样本进行惩罚,在更新 G 时提供了足够的梯度,从而解决了训练 G 的梯度消失问题。
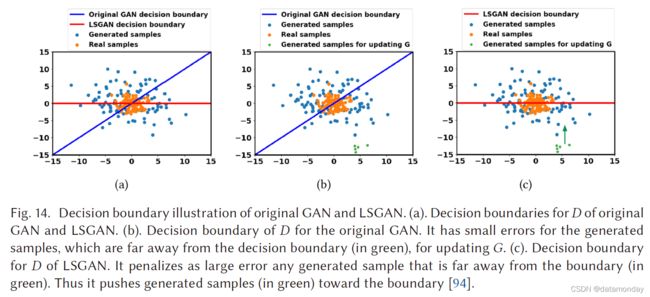
图 14 展示了 LSGAN 和原始 GAN 的决策边界的比较。工作 [94] 已经证明,当 a、b 和 c 服从 b - c = 1 并且 b - a = 2 时,LSGAN 的优化等效于最小化 pr + pg 和 2pg 之间的 Pearson χ 2 散度。与 WGAN 类似,这里的 D 涉及回归,sigmoid 也被移除。 LSGAN 在 LSUN 和 HWDB1.0 [81] 上进行了评估,图像分辨率为 112 × 112。使用 β1 = 0.5 的 Adam 优化器,LSUN 和 HWDB1.0 的学习率分别为 1 × 10-3 和 2 × 10-4。与 DCGAN 类似,ReLU 激活和 Leaky ReLU 激活分别用于生成器和判别器。
5.4 f-GAN

f-GAN 的工作基于可以使用 f-divergence [104] 训练 GAN。 f-divergence D f ( p r ∣ ∣ p g ) D_f (pr||pg) Df(pr∣∣pg) 测量两个概率分布之间的差异(关于 GAN 的 pr 和 pg),例如前面提到的 KL 散度、JS 散度和 Pearson χ 2,可以概括为
![]()
其中 f 是凸函数,f (1) = 0。需要注意的是,在原始论文 [104] 中将 f 称为生成器函数,这与 GAN 中生成器 G 的概念完全不同。因此,我们在本节中使用 f 或 f -divergence 函数代替原始论文中的生成器函数,以避免与本文中使用的生成器 G 混淆。 f -GAN 根据等式 (18) 中呈现的 f - 散度函数概括了 GAN 的损失函数。具有 f-散度函数的 f-散度列表如表 1 所示。然而,等式 (18) 是难以处理的,因此它需要以可计算的方式进行估计,例如通过使用期望形式。通过使用凸共轭 (Fenchel conjugate) f (u) = supt ∈domf ∗ {tu − f ∗(t)} [50],f -散度可以表示为散度的下界

其中 T 是满足 X → R 的 T 的任意函数类(例如,具有特定激活函数的参数化鉴别器,例如 sigmoid)。上面的推导产生了一个易于处理的 Df (pr||pg) 的下限,因此可以直接计算。 f -GAN 的优化首先的特点是最大化判别器的下界(等式(19)中的最后一行),其目的是使下界成为 f -散度的估计,然后最小化关于生成器的 f-散度使 pg 接近 pr。这种优化称为变分散度最小化 (variational divergence minimization,VDM)。作者在 MNIST(28 × 28 像素图像)和 LSUN(96 × 96 像素图像)上训练了基于 VDM 的生成神经采样器。模型架构和训练设置与 DCGAN 中提出的相同。
5.5 Unrolled GAN
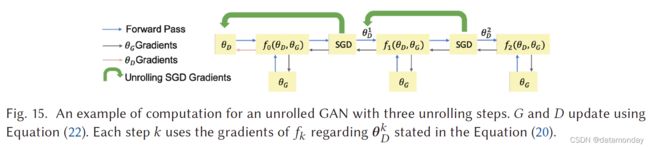
Unrolled GAN (UGAN) 是一种设计,旨在解决 GAN 在训练期间的模式崩溃问题 [98]。 UGAN 的核心设计创新是增加了一个用于更新 G 的梯度项,它具有捕获判别器对生成器变化的响应的能力。 D 的最优参数可以表示为迭代优化过程,如下所示:

需要注意的是,方程(23)中的第一项是原始 GAN 的梯度。这里的第二项反映了 D 如何对 G 的变化做出反应。如果 G 倾向于崩溃为一种模式,那么 D 将增加 G 的损失。因此,这种展开的方法能够防止 GAN 的模式崩溃问题。作者在 MNIST 和 CIFAR10 数据集上训练了 UGAN。所有卷积的核大小为 3 × 3,并进行了批量归一化。鉴别器使用泄漏率为 0.3 的 Leaky ReLU,生成器使用 ReLU。生成器由五层组成,一层全连接层、三层反卷积层和一层卷积层。判别器有四层,其中三层是卷积层,一层是全连接层。实验中使用了生成器学习率为 1 × 10-4 和判别器学习率为 2 × 10-4 的 Adam 优化器。
5.6 Loss Sensitive GAN (LS-GAN)
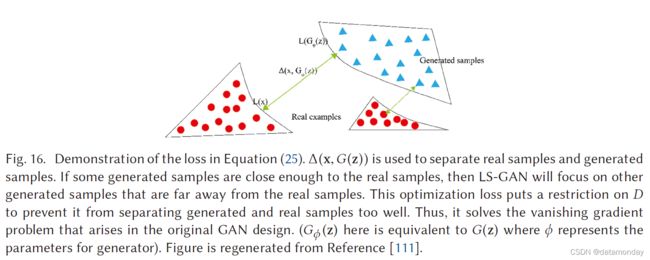
引入 LS-GAN 来训练生成器通过最小化真实样本和生成样本之间的指定边距来生成真实样本 [111]。这项工作认为,原始 GAN 中出现的梯度消失和模式崩溃等问题是由非参数假设引起的,即判别器能够区分真实样本和生成样本之间的任何类型的概率分布。如前所述,真实样本分布和生成样本分布之间的重叠可以忽略不计是非常正常的。此外,D 还能够分离真实样本和生成样本。在这种情况下,JS 散度将变为常数,其中 G 出现梯度消失。在 LS-GAN 中,D 的分类能力受到限制,并通过用 θ 参数化的损失函数 Lθ (x) 学习,该函数假设 a真实样本的损失应该比生成的样本小。损失函数可以合并为以下约束:
![]()
其中 Δ(x,G(z)) 是衡量真实样本和生成样本之间差异的边距。该约束表明真实样本与生成样本的距离至少为 Δ(x,G(z))。然后将 LS-GAN 的优化表示为
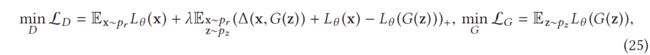
其中 λ 是正平衡参数,(a)+ = max(a, 0) 和 θ 是 D 中的参数。 从等式 (25) 中 LD 的第二项,Δ(x,G(z)) 是添加作为优化 D 的正则化项,以防止 D 过拟合真实样本和生成的样本。图 16 展示了等式 (25) 的功效。 D 的损失限制了 D 的能力,即它挑战了 D 将生成良好的样本与真实样本分离的能力,这是梯度消失的原始原因。更正式地说,LS-GAN 假设 pr 位于一组具有紧凑支持的 Lipschitz 密度中。
这些模型使用 CIFAR-10、SVHN [102] 和 CelebA 进行了训练,其中包含 64 个小批量图像。所有权重均从标准差为 0.02 的零均值高斯分布初始化。 Adam 优化器用于训练模型,初始学习率设置为 1 × 10-3,β1 设置为 0.5,而学习率每 25 个时期降低 0.8 倍。
5.7 Mode Regularized GAN
模式正则化 GAN 提出了一种正则化度量来惩罚缺失模式 [18],然后将其用于解决模式崩溃问题。这项工作背后的关键思想是使用编码器 E(x): x → z 来为 G 生成潜在变量 z,而不是使用噪声。这个过程有两个好处:
- 1)编码器重构可以为 G 添加更多信息,使得 D 不太容易区分生成的样本和真实样本;
- 2)编码器保证 x 和 z (E(x)) 之间的对应关系,这意味着 G 可以覆盖 x 空间中的不同模式。
所以它可以防止模式崩溃问题。这种模式正则化 GAN 的损失函数是
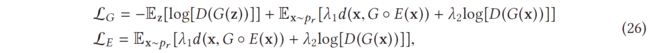
其中 d 是一个几何测量,可以从许多选项中选择,例如,像素级 L2 和提取特征的距离。作者评估了在 MNIST 和 CelebA (64 × 64) 数据集上包含模式正则化的性能。
5.8 Geometric GAN
几何 GAN [80] 的损失函数可以通过将铰链损失最小化为

这种折页损失方式也部署在 4.11 节提到的 SAGAN 和 4.12 节提到的 BigGAN 中。与其他损失函数相比,作者证明了折页损失对于处理高维低样本量问题 [2, 17, 96] 的功效,这是当 mini-batch 大小小得多时引起的分类问题大于特征空间的维度。在本文中,几何 GAN 是基于软边缘 SVM 线性分类器而不是硬边缘 SVM 线性分类器设计的。这些网络在 MNIST(64 × 64 分辨率)、CelebA(64 × 64 分辨率)和 LSUN(64 × 64 分辨率)数据集上进行了训练。在这项工作中部署了使用 RMSprop 优化器训练的 DCGAN 架构,学习率为 2 × 10−4,小批量大小为 64。作者证明几何 GAN 在训练时更稳定,更不容易出现模式崩溃。
5.9 Relativistic GAN

相对论 GAN (RGAN) [60] 被提议作为一种从现有成本函数设计新成本函数的通用方法,即它可以推广到所有 IPM [101, 123] GAN。原始 GAN 中的鉴别器测量给定真实样本或生成样本的概率。作者认为,原始 GAN 中缺少真实数据和生成数据之间的关键相对判别信息。 RGAN 中的鉴别器考虑了给定的真实样本与给定的随机生成样本相比如何更真实。应用于原始 GAN 设计的 RGAN 损失函数表示为
![]()
其中 C(x) 是未转换的层。图 17 展示了与原始 GAN 相比,使用 RGAN 方法对 D 的影响。就原始 GAN 而言,优化旨在将 D(x) 推至 1(右一)。对于 RGAN,优化旨在将 D(x) 推至 0.5(左一),与原始 GAN 相比更稳定。作者还声称,如果那些损失函数属于 IPM,RGAN 可以推广到其他类型的损失变量 GAN。泛化损失表示为
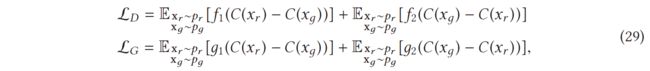
其中 f1(y) = g2(y) = -y 且 f2(y) = g1(y) = y。其他 GAN 的损失泛化的详细信息可以在原始论文 [60] 中找到。
作者在 CIFAR-10 和具有各种图像尺寸(即 64 × 64、128 × 128 和 256 × 256)的 CAT 数据集上训练了网络。使用了带有 Adam 优化器的 DCGAN 架构。已经探索了各种训练设置,更多细节可以在原始论文[60]中找到。作者成功地证明了相对论鉴别器提供了一种改进标准 GAN 方法的方法,并且能够通过其他技巧实现更好的性能,例如光谱归一化和梯度惩罚。更重要的是,作者展示了这种方法的可推广性,其中任何类型的 GAN 都可以通过 RGAN 方式进行训练。
5.10 SN-GAN
SN-GAN [100] 提出使用权重归一化来以更稳定的方式训练判别器。这种技术计算量轻,很容易应用于现有的 GAN。先前稳定 GAN 训练的工作 [4, 47, 111] 强调了 D 应该来自 K-Lipshitz 连续函数集的重要性。 Lipschitz 连续性 [5, 36, 42] 可以被认为是一种更严格的连续性形式,它要求函数不会快速变化。这种平滑的 D 有利于稳定 GAN 的训练。前面提到的工作主要集中在判别器函数的 Lipschitz 常数的控制上。这项工作展示了另一种更简单的方法,通过对 D 的每一层进行光谱归一化来控制 Lipschitz 常数。光谱归一化执行如下
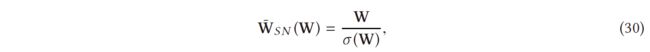
其中 W 表示 D 的每一层的权重,σ (W) 是 W 的 L2 矩阵范数。文章证明这将使 |f| ≤ 1。σ (W) 的快速近似也在原始论文中得到了证明。
作者通过与现有正则化/归一化技术包括权重裁剪 [4]、梯度惩罚 [136]、批量归一化 [57]、权重归一化 [118]、层归一化 [7] 和正交正则化 [14]。已经进行了几种训练设置以进行全面比较。与以前提出的方法相比,作者证明了光谱归一化对生成图像的多样性和质量的功效。
5.11 RealnessGAN
在最初的 GAN 设计中,判别器只输出 0 和 1,即真假,而不是连续分布作为真实性的度量。[137] 提出了 RealnessGAN 来解决这一新观点,它将真实性视为可以从多个角度估计的随机变量。传统的 GAN 采用单个标量(鉴别器输出)作为真实性的度量。作者认为,在图像的情况下,真实性更复杂,涵盖了纹理和整体配置等多个因素。根据这一观察,鉴别器被重新设计以学习真实分布而不是单个标量。为了实现这一点,RealnessGAN 用分布 prealness 替换单个标量,使得 D(x) = {prealness(x,u);u ∈ Ω} 由输入样本给出,其中 Ω 是 prealness 的结果集,而每一个结果u都可以被看作是一个潜在的真实性衡量标准,通过选定的真实性衡量标准。在原始论文中,鉴别器在这 N 个结果 Ω = {u0,u1, . . . ,uN -1} 为
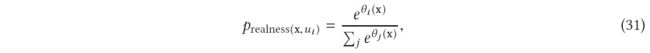
其中 θ = {θ0, θ1, . . . , θN -1} 是 D 的参数。除了结果 Ω 外,还定义了两个分布 A1 代表真实和 A0 代表假。在实际实现中,给定一个 minibatch {x0, x1, . . . , xm−1},即判别器对第 i 个结果计算的 logits,在 {θi (x0), θi (x1), . . . , θi (xm−1)} 上拟合高斯分布 N (μi, σi ),并且新的 logits 被重新计算为 {θ’ i (x0), θ’ i (x1), . . . , θ’ i (xm-1); θ’ i ∼ N (μi, σi )}。增加结果的数量将使 D 更加严格,并对 G 施加更多的约束。换句话说,对于更复杂的数据集,建议使用更多的结果。最小最大损失最终可以表示为
![]()
作者使用 Adam 优化器在 CIFAR10 和 CelebA 上训练 RealnessGAN。 RealnessGAN 的网络架构与 z ∼ N (0, I ) 的 DCGAN 架构相同。对 G 部署批量归一化,对 D 应用光谱归一化。对于 CelebA 和 CIFAR10 数据集,结果的数量分别设置为 51 和 3。
5.12 Sphere GAN
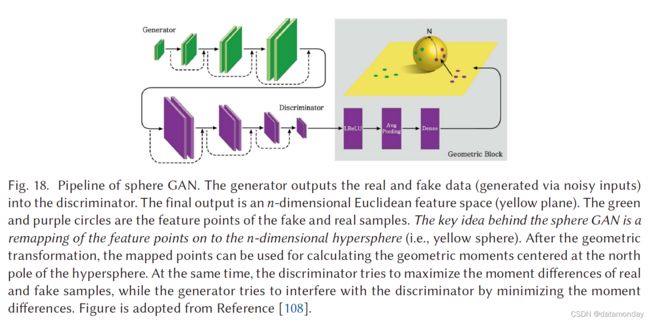
图 18. Sphere GAN 的流水线。生成器将真实和虚假数据(通过噪声输入生成)输出到鉴别器中。最终输出是一个 n 维欧几里得特征空间(黄色平面)。绿色和紫色的圆圈是假样本和真样本的特征点。球体 GAN 背后的关键思想是将特征点重新映射到 n 维超球体(即黄色球体)。经过几何变换后,映射点可用于计算以超球面北极为中心的几何矩。同时,判别器试图最大化真假样本的矩差,而生成器试图通过最小化矩差来干扰判别器。图取自参考文献[108]。
Sphere GAN [108] 是一种新颖的基于 IPM 的 GAN,它使用超球面将 IPM 绑定到目标函数中,从而可以促进训练的稳定性。通过使用几何矩匹配利用数据的高阶统计信息,GAN 模型可以提供更准确的结果。 sphere GAN 的目标函数定义为
![]()
对于 r = 1, . . . , R,其中函数 drs 测量每个样本与超球体北极 N 之间的 r 矩距离。注意下标 s 表示 drs 是在 Sn 上定义的。与基于 Wasserstein 距离的传统鉴别器需要 Lipschitz 约束(强制鉴别器为 1-Lipschitz 函数)不同,Sphere GAN 通过在超球面上定义 IPM 来放松这一条件。图 18 显示了 sphere GAN 的流程。
与 WGAN-GP、WGAN-CT 和 WGANL 等传统方法不同,球形 GAN 不需要任何额外的约束来迫使鉴别器位于所需的函数空间中。通过使用几何变换,sphere GAN 确保距离函数位于所需的函数空间中,而没有额外的约束项。
5.13 Self-supervised GAN (SS-GAN)
尽管条件 GAN 在自然图像合成方面取得了巨大成功。条件 GAN 的主要缺点是需要标记数据。自监督 GAN [19] 利用对抗性训练和自我监督来弥合有条件和无条件 GAN 之间的差距。
这项工作使鉴别器具有一种学习有用表示的机制,而与当前生成器的质量无关。他们以自监督的方式训练一个预测旋转角度的模型,以便从生成的网络中提取表示,然后建议向鉴别器添加一个自监督任务(基于旋转的损失),如
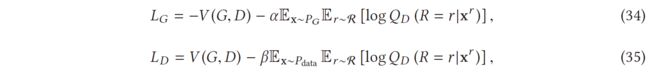
其中 V (G, D) 是原始值函数 [45],r ∈ R 是从一组可能的旋转中选择的旋转 (R = {0◦, 90◦, 180◦, 270◦})。旋转 r 度的图像 x 表示为 xr ,Q (R|xr) 是判别器在样本旋转角度上的预测分布。实现技巧是他们使用添加了线性层的判别器的倒数第二层的输出来预测旋转类型。这项工作试图通过学习旋转信息来强制鉴别器学习良好的表示。
5.14 Summary

我们解释了原始 GAN 设计中存在的训练问题(G 的模式崩溃和梯度消失),并且我们从文献中引入了损失变体 GAN,其主要目的是在三个关键方面提高 GAN 的性能。图 19(a) 说明了本节讨论的损失变量的足迹。图 19(b) 总结了损失变体 GAN 对这些挑战的效果。第 7 节提供了定量结果的更多细节。LSGAN、RGAN 和 WGAN 的损失与原始 GAN 损失非常相似。我们使用一个玩具示例(即图 10 中使用的两个分布)来演示图 11(b) 中关于真实数据分布和生成数据分布之间距离的 G 损失。
可以看出,当判别器优化时,RGAN 和 WGAN 能够固有地解决生成器的梯度消失问题。相比之下,LSGAN 仍然存在生成器梯度消失的问题,但是,当真实数据分布和生成数据分布之间的距离相对较小时,它能够提供比图 11(a) 中的原始 GAN 更好的梯度。这在原始论文 [94] 中得到了证明,其中 LSGAN 被证明更容易将生成的样本推到判别器建立的边界。
损失变体 GAN 可以应用于架构变体。然而,与其他损失变体相比,SN-GAN 和 RGAN 表现出更强的泛化能力,这两种损失变体可以被其他类型的损失变体部署。频谱归一化可以应用于任何 GAN 变体 [100],而 RGAN 概念可以应用于任何基于 IPM 的 GAN [60]。我们强烈建议对所有 GAN 应用使用光谱归一化,如此处所述。本文中提到了许多损失变体 GAN,它们能够解决模式崩溃和训练稳定性问题。
6 APPLICATIONS
6.1 Image Synthesis
图像超分辨率(Image Super-Resolution)
图像超分辨率可以通过上采样从低分辨率图像生成高分辨率图像。 SRGAN [74] 是使用 GAN 进行图像超分辨率的代表性框架。除了 GAN 中的一般对抗性损失之外,SRGAN 通过在超分辨率区域添加内容损失(例如,逐像素 MSE 损失)来扩展损失,这导致如下所示的感知损失:
![]()
其中 L X S R L^{SR}_X LXSR 是内容损失, L G A N S R L^{SR}_{GAN} LGANSR 是 GAN 损失。在实践中,内容损失 L X S R L^{SR}_X LXSR 的选择取决于应用。 SRGAN 提出了三种内容损失:
- 1)标准像素级 MSE 损失 LSR MSE,
- 2)定义在表示较低级别特征 L V G G 22 S R L^{SR}_{VGG22} LVGG22SR 的特征图上的损失,
- 3)定义在表示较高级别特征 LSR V 的特征图上的损失GG54。作者表明,不同的内容损失根据不同的评估指标表现不同。SRGAN 中的生成器以低分辨率图像为条件,这些图像是用 4 倍放大因子推断的。与传统方法相比,作者展示了 SRGAN 的卓越感知性能。
图像补全/修复(Image Completion/Repair)
图像补全/修复是一种常见的图像编辑操作,旨在用合成内容填充图像中缺失或被掩蔽的区域。最有效的传统补全算法 [9, 54] 依赖于低级线索,这些线索用于从同一图像的已知区域搜索补丁,并合成与匹配补丁相似的本地内容。这些方法在后台补全方面表现良好,因为来自背景的模式彼此相似。在某些情况下,可能会违反图像中缺失部分与其他部分相似模式的假设,例如,填充面部图像的缺失部分,其中许多对象具有独特的模式。[77] 提出使用包含 GAN 的自动编码器。部署了两个鉴别器 DG 和 DL(一个用于全局图像内容,另一个用于局部图像内容),这会产生两个用于优化的对抗性损失。整体损失函数表示为
![]()
其中 Lr 是自动编码器输出和原始图像之间的 L2 距离,LDG 和 LDL 是 DG 和 DL 的对抗性损失,Lp 是解析网络的像素级 softmax [85, 140]。 λ1、λ2、λ3 是用于控制不同损失引起的影响的超参数。
图像抠图(Image Matting)
自然图像抠图被定义为准确估计图像或视频流中前景对象的不透明度的操作[88]。该领域正在吸引越来越多的兴趣,因为它具有广泛的应用,例如图像编辑和电影后期制作。图像抠图方法要求输入图像具有前景对象和图像背景,可以在数学上表示为
![]()
其中 α i α_i αi 是定义像素 I I I 处的前景不透明度的标量值, F i F_i Fi 是像素 I I I 处的前景对象的标量值, B i B_i Bi 是像素 I I I 处的背景的标量值。Lutz 等人将 GAN 引入该领域,并提出了 AlphaGAN,它可以产生视觉上吸引人的构图。在他们的工作中,他们在与真实 alpha 和预测 alpha 合成的图像上训练鉴别器,并且生成器用于生成合成。
图像到图像的翻译(Image-to-image Translation)
图像到图像的翻译是一类图形问题,其目标是使用一组对齐的图像对来学习输出图像和输入图像之间的映射。 [58] 提出在配对训练数据可用时使用 CGAN 进行图像到图像的转换。当未配对的训练数据不可用于图像到图像的转换时,CycleGAN [153] 被提出作为一种解决方案。 CycleGAN 通过引入循环一致性损失来实现这一点,以强制要求从一个域 X 到另一个域 Y 的映射在每个方向上大致相同。还提出了其他工作,例如 DiscoGAN [66] 和 DualGAN [143],以解决图像到图像转换领域中缺少配对训练数据的问题。更多细节可以在原始论文中找到。
6.2 Video Generation
GAN 在自然图像生成方面已经取得了惊人的成果。最近的一些工作试图将这一成功扩展到视频生成领域 [24, 61, 126]。使用 GAN 生成令人信服的视频仍然是一项重大挑战,因为它加剧了与使用 GAN 生成图像相关的所有问题。由于视频的性质和时间建模的要求,它还存在内存和计算成本增加的问题。此外,由于内存和训练稳定性的限制,随着视频分辨率/持续时间的增加,生成变得越来越具有挑战性。我们认为,通过 GAN 生成视频的当前研究重点是:
- 1)高分辨率视频的制作,例如,高达/超过 256 × 256,
- 2)将生成视频的长度增加到 48 帧以上,
- 3)生成更逼真的视频,以便生成的大部分视频内容不会模糊、模糊甚至超现实。
基于视频的 GAN 不仅需要考虑空间建模问题,还需要时间建模,即视频序列中每个相邻帧之间的运动。
- MoCoGAN [126] 被提议以无监督的方式学习运动和内容,并将图像潜在空间划分为内容和运动空间。
- DVD-GAN [24] 能够基于 BigGAN 架构生成更长、更高分辨率的视频,同时引入可扩展的视频特定生成器和鉴别器架构。DVD-GAN 包含两个判别器 DS(空间判别器)和 DT(时间判别器),其中 DS 从空间角度对输入帧进行评分,DT 从时间角度(运动)对输入帧进行评分。
6.3 Feature Generation
“机器会思考吗?”这是艾伦·图灵在 1950 年题为计算机器与智能[127] 的开创性论文中提出的问题。机器的最终目标是与人类一样智能。当前的 AI 依赖于大型数据集,而不是从小型数据集泛化而来,并且在顺序学习任务时存在灾难性的遗忘问题 [97]。小样本学习(Few-shot learning)和持续学习(continual learning)近年来引起了科学界的极大关注,旨在填补人工智能与人类之间的空白。这两个领域都存在数据缺乏的问题,即,few-shot learning 对每个类别使用很少的样本(例如,通常是 1 个样本或 5 个样本),而持续学习会遇到顺序任务中看不见的数据。[93] 提出使用带有两个附加术语的条件 Wasserstein GAN,即余弦嵌入和循环一致性损失来合成看不见的动作特征以进行零样本动作识别。[119] 提出了一种用于持续学习的深度生成重放框架,其中先前任务的训练数据由生成器采样,并与新任务的训练数据交错。这些表明 GAN 具有为其他机器学习问题提供解决方案的潜在能力。
7 DISCUSSION
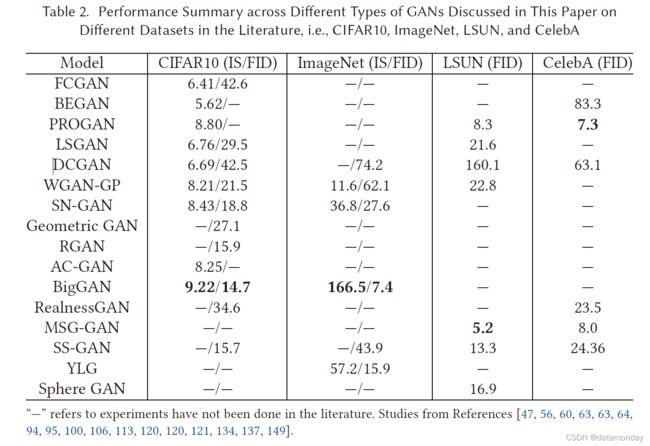
我们已经介绍了原始 GAN 设计中存在的最重要问题,即更新 G 时的模式崩溃和梯度消失。我们调查了重要的 GAN 变体,这些变体通过两个设计考虑来解决这些问题:(1) 架构变体。这方面侧重于 GAN 的架构选项。这种方法使 GANs 能够成功地应用于不同的应用,但是,它并不能完全解决上述问题; (2) 损失变量。我们已经详细解释了为什么在原始 GAN 中会出现这些问题。这些问题本质上是由原始 GAN 中的损失函数引起的。因此,修改这个损失函数可以解决这个问题。但是应该注意的是,对于某些架构变体,损失函数可能会发生变化,并且在许多情况下,它是特定于架构的损失。因此,它无法推广到其他架构。表 2 通过使用文献中介绍的 Inception Score 和 FID,展示了我们对本工作中提出的 GAN 的性能的总结。摘要中考虑了四个图像数据集,即 CIFAR10、ImageNet、LSUN 和 CelebA,它们是使用最广泛的基准数据集。
架构和损失之间的联系(Interconnections between Architecture and Loss)
在本文中,我们强调了原始 GAN 设计中固有的问题。在强调后续研究人员如何解决这些问题时,我们分别探讨了 GAN 设计中的架构变体和损失变体。但是,应该注意的是,这两种类型的 GAN 变体之间存在相互联系。如前所述,损失函数很容易集成到不同的架构中。通过重新设计的损失函数从改进的收敛性和稳定性中受益,架构变体能够实现更好的性能并完成更困难问题的解决方案。例如,BEGAN 和 PROGAN 使用 Wasserstein 距离而不是 JS 散度。 SAGAN 和 BigGAN 部署了光谱归一化,它们基于多类图像生成实现了良好的性能。这两种变体类型同样有助于 GAN 的进步。
未来方向(Future Directions)
GAN 最初是为了生成可信的合成图像而提出的,并在计算机视觉领域取得了令人兴奋的性能。 GAN 已应用于一些其他领域(例如,时间序列生成 [15, 39, 48, 87] 和自然语言处理 [8, 40, 76, 147])并取得了一些成功。与计算机视觉相比,GANs 在其他领域的研究仍然有些局限。限制是由图像与非图像数据固有的不同属性引起的。
- 例如,GAN 可以生成连续值数据,但自然语言基于单词、字符和字节等离散值,因此很难将 GAN 成功应用于此类数据。由于这也是一个非常有前景的领域,该领域的成功将带来许多应用,例如为直播生成字幕和评论等。
- 健康等研究领域对隐私问题尤其敏感,成功的数据增强将对这些领域产生重大影响。但是,仅以有限的方式探索了与此类应用领域相关的其他数据模式的生成,例如时间序列数据。这里的显着挑战包括缺乏有效的指标来评估 GAN 在这些领域的表现。这些领域需要更多的研究。
自 2014 年提出第一个 GAN 以来,它们的发展在激发新的研究理念以及通过对研究和学术界以外的世界产生影响方面带来了许多好处。然而,GAN 的不当使用可能会带来挑战,应该引起社会关注,例如,GAN 可用于生成特定人的虚假视频,并伪造可能从未发生过的事件的证据,从而创建与特定人不符的媒体资源人的意见和行动,损害他们的声誉,甚至可能影响他们的人身安全[1, 53]。因此,我们也应该专注于开发伪造检测和流程,以有效地检测 AI 生成的图像(包括使用 GAN 开发的图像)。
8 CONCLUSION
在本文中,我们回顾了基于更高图像质量、更多样化图像和训练稳定性方面的性能改进的 GAN 变体。我们从架构和损失基础上回顾了 GAN 相关研究的现状。
- 具有更大批量大小的更复杂架构与图像质量和图像多样性的增加相关,即 BigGAN。但是,有限的 GPU 内存可能是处理大批量图像的问题。
- 作为替代方案,PROGAN 中使用的渐进式训练策略可以提高图像质量,而无需大量图像。
- 在图像多样性方面,向生成器和判别器添加自注意力机制已经取得了令人兴奋的结果,SAGAN 使用 ImageNet 数据集展示了引人注目的性能。
- 在训练稳定性方面,损失函数在这里起着重要作用,并且已经提出了不同类型的损失函数来应对这一挑战。在回顾了不同类型的损失函数后,我们发现谱归一化具有良好的泛化质量,即它可以应用于每个 GAN,易于实现且计算成本非常低。
- 当前最先进的 GAN 模型(例如 BigGAN 和 PROGAN)能够在计算机视觉领域产生高质量的图像和多样化的图像。
然而,将 GAN 应用于更具挑战性的视频场景的研究是有限的。此外,时间序列生成和自然语言处理等其他领域的 GAN 相关研究在性能和能力方面落后于计算机视觉。我们得出结论,特别是在这些领域,未来的研究和应用显然有机会。