时域卷积网络与蒙特卡洛树搜索相结合的知识图补全模型研究

这个适合第三个方向。。。
摘要

在知识图谱补全 (KGC) 和其他应用程序中,学习如何使用给定查询从源节点移动到目标节点是一个重要问题。它可以表述为给定状态下的强化学习 (RL) 问题转换模型。为了克服稀疏奖励和历史状态编码的挑战,我们开发了一个深度代理网络(graph-agent,GA),它结合了时间卷积网络(TCN)和蒙特卡洛树搜索(MCTS)。将 MCTS 与神经网络相结合,生成更多的正奖励轨迹,从而有效解决稀疏奖励的问题。TCN 用于对历史状态进行编码,分别用于策略和 Q 值。根据这些轨迹,我们使用 Q-Learning 来改进网络和参数共享以增强 TCN 策略。我们反复应用这些步骤来学习模型。在模型的预测阶段,蒙特卡洛树搜索结合Q值方法对目标节点进行预测。在几个图行走基准上的实验结果表明,GA 优于其他基于策略梯度的 RL 方法。 GA 的性能也优于传统的 KGC 基线。
1.介绍
知识图谱的初衷是描述和存储现实世界中的各种实体及其关系。虽然一个典型的知识图谱可能包含数百万个实体和数十亿个关系,但它通常远非完整。知识图谱补全(KGC)的目的是利用现有知识图谱中的关联信息来预测实体之间的缺失关系,以补全知识图谱。 基于嵌入的排序方法,首先基于现有的三元组学习嵌入向量。通过用每个实体替换尾部实体或头部实体,这些方法计算所有候选实体的分数并对前 k 个实体进行排名。实体和关系的嵌入式学习在一些基准测试中取得了显着的性能提升,但它不能对复杂的关系路径进行建模。 在图结构中关系路径推理转向使用路径的信息。随机游走推理已被广泛研究。 此外,通过将实体对之间的路径查找制定为顺序决策,特别是马尔可夫决策过程 (MDP),为多跳推理引入了深度强化学习 (RL)。基于策略的 RL 代理通过知识图环境之间的交互来学习找到与扩展推理路径相关的步骤,其中策略梯度用于训练 RL 代理。与随机游走推理相比,深度强化学习可以获得更好的路径。
基于RL的KGC也可以理解为构造函数f(G, nS, q)来预测目标节点nT,其中f(·)可以从由(nS, q, nT)等样本组成的训练数据集中学习。在这项工作中,我们使用图游走代理来构建 f(G, nS , q) 模型,该模型可以通过智能决策从 nS 游到 nT。由于 nT 未知,因此无法通过常规搜索算法解决该问题。例如 A * -search,它试图在给定的源节点和目标节点之间寻找路径。相反,代理需要从训练数据集中学习其搜索策略,以便在训练之后,代理知道如何遍历图以针对给定的一对 (nS , q) 到达正确的目标节点 nT。而且,每个训练样本都以“(源节点,查询,目标节点)的形式存在。” 但是,代理只收到延迟奖励:当代理正确(或错误)预测训练集中的目标节点时,代理将获得正(或零)奖励。因此,我们将问题描述为马尔可夫决策过程(MDP)并通过强化学习(RL)训练代理。
基于 RL 的 KGC 提出了两个主要挑战。首先,由于MDP的状态是整条行走路径,为了得到正确的决策,通常不仅需要查询,还需要整条行走路径上所有节点的信息。 我的代理必须利用完整的历史信息和输入查询 Q 来做出这个决定。 其次,reward是稀疏的,只有在路径的尽头才能得到路径的reward。
在本文中,我们构建了一个结合 MCTS 和强化学习的图代理网络(GA),可以有效地解决这两个挑战。首先,我们将蒙特卡洛树搜索(MCTS)与 MDP 转换模型相结合,以获得更多具有正奖励的轨迹。其次,GA 引入了一种新的时间卷积网络 (TCN) 结构,它将轨迹的整个历史编码为向量表示,并进一步用于对策略和 Q 函数进行建模。但是,它们的离线策略性质使它们无法被 RL 方法使用。为了解决这个问题,我们设计了一个Q值网络和决策网络之间的参数共享结构,使得离线策略可以通过Q-Learning对离线策略的轨迹进行间接改进。巧妙的是,我们利用获得的轨迹来训练模型并更新参数。我们的方法与现有的基于 RL 的 KGC 方法形成鲜明对比。后者使用policy gradient(强化)方法,通常需要大量提升才能获得正奖励轨迹,尤其是在学习的早期阶段。我在几个基准测试(几个实际的 KBC 任务)上的实验结果表明,我们的方法优于之前基于 RL 的方法和传统的 KGC 方法。该模型在某些任务上的评估结果与其他强化学习方法的评估结果接近,并且在多个完成任务上获得了最好的结果。本文的主要贡献总结如下:
(1) 我们引入时间卷积网络结构,将轨迹的整个历史编码为向量表示,具有时间序列的特点,可以更好地表示历史信息。
(2) 为了解决稀疏奖励的挑战,GA利用了 MDP 转换模型是已知的和确定性的这一事实。因为每当代理采取行动时,通过选择连接到下一个节点的边,下一个节点(环境将转换到的)的身份是已知的。
(3) 我们引入蒙特卡洛树搜索来获得更多具有正奖励的轨迹。
(4) 我们设计了一个Q值网络和决策网络之间的参数共享结构,使得策略网络可以通过Q-Learning对离线策略的轨迹进行间接改进。
第 2 节讨论相关工作。
第 3 节是关于问题陈述。
第 4 节开发深度代理网络 GA,包括模型结构、训练算法和测试算法。
第 5 节给出了实验结果。
最后,我们在第 6 节总结了这篇论文。
离线策略

强化学习中 on-policy与off-policy 的理解;如何区分on-policy 与 off-policy;RL更新策略、policy结构总结_strawberry47的博客-CSDN博客_onpolicy和offpolicy有趣的解释:古时候,优秀的皇帝都秉持着“水能载舟 亦能覆舟”的思想,希望能多了解民间百姓的生活。皇帝可以选择通过微服出巡,亲自下凡了解百姓生活(On-policy),虽然眼见为实,但毕竟皇帝本人分身乏术,掌握情况不全;因此也可以派多个官员去了解情况,而皇帝本人则躺在酒池肉林里收听百官情报即可(Off-policy)。Q-learning vs. Sarsa二者都是基于TD的强化学习策略,但是前者是off-policy(有目标网络和行为网络),后者是on-policy。on-policy与off-polichttps://blog.csdn.net/strawberry47/article/details/125652605
2.相关工作
早期,经典的关系抽取方法,如路径排序算法[2],是利用推理规则和统计方法来实现的。 这个方法将每条不同的关系路径作为一维特征,在知识图谱中对不同的关系路径进行大量统计,构造关系分类的特征向量。 最后,利用特征分析模型对关系特征进行分类,取得了良好的关系抽取效果,成为关系补全的表示方法之一。然而,这种基于关系的共现统计方法面临着严重的数据稀疏问题。
以反序列方法为代表的知识图谱推理与补全模型取得了较好的效果,并产生了多种变体算法。该模型的主要思想是利用知识图谱的语义和结构关系来学习低维密集空间中实体和关系的表示,并利用嵌入中包含的相关性完成后续的推理和完成任务。然而,Trans 模型对超参数敏感且缺乏可扩展性。同时,动态知识图谱和冷启动实体的处理能力不足。近年来,随着深度学习的发展,一些深度神经网络被应用于知识图谱的特征挖掘,如graph-NNs[3]、GCN[4]、GAT[5]等。随着近年来强化学习的普及,强化学习算法被广泛应用于各个领域,如 DeepPath [6]、MINERVA [7] 和 M-walk [8]。DeepPath 要求目标实体信息处于 RL 代理的状态,不能应用于目标实体未知的任务。MINERVA 使用策略梯度方法在训练和测试期间探索路径。M-walk 通过集成 MCTS 算法进一步利用状态转换信息。2021 年,Huang [9] 提出了一种新的知识图完成模型,称为定向多维注意力卷积模型,该模型探索了方向信息和三元组固有的深度表达特征。Jagvaral [10] 提出了一种新的知识图补全方法,它将双向长短期记忆 (BiLSTM) 和卷积神经网络模块与注意力机制相结合。我们提出的方法使用 TCN 来编码历史信息。我们的模型在某些任务上的评估结果与其他强化学习方法的评估结果接近,并且在多个完成任务上获得了最好的结果。
3.问题陈述
在本节中,我们将介绍和解释一些相关概念,并将知识图谱补全问题形式化。
3.1强化学习
强化学习(RL)是指代理在与环境交互的过程中试图从错误的经验中采取行动并学习最优决策策略以解决自然科学中的顺序决策问题的方法,社会科学、工程等领域[11-14]。
强化学习中的两个关键问题:环境设计和代理设计。早期的任务依赖于简单的环境,状态数量有限,动作基本固定,因此可以确定状态到动作的映射空间。因此,agent可以保存每个状态的每个动作的值估计,并以表格的形式记录,即Q值表,指导agent进行选择。 鉴于环境复杂,强化学习技术在过去几年取得了长足的进步,其中最重要的是强化学习与深度学习的融合,称为深度强化学习[15]。不再依赖于获取状态空间中的所有状态,而是利用从状态中提取的特征来学习决策策略,并利用深度神经网络拟合更复杂的函数映射,解决了复杂环境设计的问题和复杂的代理设计在一定程度上。
深度强化学习广泛应用于自然语言处理、游戏对抗和机器人控制,如 DeepStack [16]、AlphaGo [17] 和 Deep Q-network (DQN) [18]。 DQN算法是Q-network类型算法中的代表算法之一。它在各个研究领域的出色表现引起了研究人员的关注。 衍生了各种类型的改进算法,如Double-DQN [19]和Duel DQN [20],它们对DQN的过度估计进行了有效的改进,并在性能上进行了优化和提升。强化学习可以分为两类:价值方法和策略梯度方法。Q-Learning是学习各种状态动作的估计值。 此外,还有其他类型的以策略梯度法为主的方法,例如信任区域法[21, 22],确定性策略梯度法[23, 24],离开策略和策略梯度相结合的方法[25, 26],无监督强化和辅助学习[27, 28]等。如今,深度强化学习已经在不同领域或与不同模型相结合的许多问题上进行了探索和实践[29-33]。
3.2蒙特卡洛树搜索
蒙特卡洛树搜索(MCTS)[34]是一类树搜索算法的总称,用作频率概率的估计,可以有效解决一些探索空间巨大的问题。在强化学习的研究中,Deepmind 公司充分发挥了蒙特卡洛树搜索在围棋领域的作用[15, 35]。在使用围棋的状态空间构造搜索树的过程中,叶子节点的数量不能穷尽,即使是以前的剪枝技术也很难在大规模状态树中发挥作用。 MCTS在巨大的搜索空间中采用模拟树节点和扩展的方法进行探索,其中典型的算法UCB(Upper Confidence Bounds[36]是在选择子节点时优先考虑尚未探索的子节点。如果所有子节点都已探索,则选择基于节点的分数。score 不仅与子节点最终获得正奖励的概率呈正相关,而且与子节点被探索的次数呈负相关。 因此MCTS 可以根据配置进行探索,利用不同的权重,可以实现比随机或其他策略更多的启发式方法。
3.3序列建模
序列建模是一个很常见的问题,它涉及到语音处理、语言建模和时间序列预测等应用。 近年来,由于数据量巨大计算能力大,RNN模型[37, 38]如雨后春笋般涌现,序列建模的任务转向使用 RNN 模型。RNN 模型可以记忆历史信息在序列中通过隐藏状态。但是,循环的梯度累积很容易导致梯度消失的问题。Long Short Term Memory (LSTM) [39] 模型在一定程度上解决了梯度消失的问题,可以更好地实现长时记忆。 GRU [40] 提出简化 LSTM 模型并提高训练速度,使循环模型在序列问题的处理中绝对占主导地位。 此外,还出现了使用卷积网络进行序列相关工作的方法。 例如,Wavenet [41] 模型使用空洞因果卷积来处理序列化的音频数据,Gated CNN [42] 模型提出了一种新的门控机制,并将 CNN 与自然语言处理相结合。
2017 年,白等人[43]发表了一篇关于时序卷积网络(TCN)在序列建模中的应用的论文,使得传统的序列建模任务不再仅仅依赖于LSTM和GRU等循环网络结构,结果在多个任务超过了循环神经网络的任务。在 TCN [44] 中,空洞卷积、因果卷积 [45、46] 和残差结构 [47] 用于处理序列建模。TCN 模型在多个序列建模任务中成功超越了传统的递归神经网络。
问题
对于我们框架的输入,我们有给定图的节点嵌入 N ∈ Rn×f 和边嵌入 E ∈ Re×d,我们有源节点 nS 和查询向量 q。我们使用蒙特卡洛树搜索和马尔可夫决策获得更多正路径的过程 P = {n1 , n2 , ..., nt }。我们利用这些轨迹来训练我们的代理网络。

对于我们框架的输出,我们可以通过训练好的代理网络获得的从源节点到目标节点的路径得到目标节点。
我们框架的任务是补全知识图谱。我们使用 TCN 融合历史状态信息和神经网络对动作和状态进行编码。我们可以通过这些轨迹训练的代理得到目标节点。
4.图形代理GA
4.1知识图谱补全的马尔可夫
知识图谱补全的任务是根据环境中给定的实体nS和关系q,准确地找到环境中对应的目标实体,形成一个完整的三元组。过程表示为 (nS , q, ?)一 (nS , q, nT )。强化学习任务通常由马尔可夫决策过程(MDP)来描述。马尔可夫决策过程描述了空间状态从一种状态转移到另一种状态的过程。我在知识图谱上构建MDP如下。
状态空间
MDP 中任何时候的状态都需要包含所有的历史信息。在知识图谱中,如果一个实体的信息被视为当前状态,它就不能满足马尔可夫性质。 我们可以保留节点的转换历史,以确保状态的构造满足马尔可夫性质,这导致每一步转换后的新状态包含比以前更多的节点和边信息,而状态的编码成为一个难以解决的问题。知识图谱上的状态表示如下:

其中 st 和 nt 是时间 t 的状态和节点,at-1 是时间 t-1 的选定动作,Nt 和 Et 是 nt 的邻居和关系集。
动作空间
在图上行走导致状态转换,候选动作的数量取决于当前实体的相邻实体的数量。 在本文中,我们考虑每对实体之间的关系,并将实体及其关系编码在一起以形成候选动作。我们将前一个状态的实体和关系排除在每个状态的动作空间之外,因为在路径中的两个节点之间来回游动是没有意义的。 因此,相邻的实体和关系构成了动作空间 An = {a1 , a2 , . .., ak-1, astop },其中 astop 表示当前状态下的终止动作,表示 MDP 的过程结束,k 表示候选动作的数量。为了保证训练好的agent可以有相同的动作空间,我们使用共享参数编码网络,可以将每个实体的动作空间统一成一个完整的动作空间A = {A1 , A2 , . .., An }。
转移函数
网络结构数据的优点是它的环境是已知的。状态转移函数 P 的描述和定义如下:(1) 当状态 st 中发生动作 a 时,状态会转移到该动作对应的实体,我们的环境状态变为下一个实体支配的新状态 st+1。 (2) agent 选择终端动作 astop ,这意味着它不会选择任何新实体及其关系。
奖励功能
奖励作为给智能体的唯一反馈信号,在智能体训练的过程中起着主导作用。在本文中,我们利用轨迹记忆以off-policy的方式训练agent。对于任何轨迹,奖励由终端节点 T 确定,如下所示:

(s, a, st+1) 得回报是一个非终止状态转移过程。模型的 Q 值是通过使用终止状态的奖励和时差 (TD) 方法来更新的。 此外,这个奖励函数的基本假设是,一个关系连接的两个实体也可以通过更多的跳数被其他关系连接,从而在一定程度上可以用其他关系表示或推断该关系。但是,它们并不完全等价。与查询的关系与路径中的其他关系正相关是一个合理的假设。
4.2图代理
图(例如知识图)中的两个主要问题。
一是状态是连续的实体和关系序列,这些序列的长度不同,很难作为输入。
解决:使用时间卷积网络对状态进行编码,并将序列状态的维度转换为相同的维度。同时,causal(因果)卷积保留了状态的马尔可夫性质。
二是每个状态的可选动作取决于当前状态下实体的相邻关系和实体,它们的数量也是不确定的。
解决:所有动作都由同一个网络编码并转换为相同的隐式完整动作空间。在选择输出动作时,我们只需要考虑候选动作。
本节将详细介绍深度代理(graph-agent)的网络结构,包括动作编码层A-ENC(θ)、状态编码层S-ENC(θ)和决策层πθ。
4.2.1实体和完整动作空间的邻居信息编码
Nt 和 Et 是 nt 的邻居和关系集。
知识图中的一个状态由一个实体 nt 支配,该状态的动作空间随其相邻实体而变化。空间大小是不确定的。它的动作空间包含实体和实体之间的关系。在不同状态下的不同动作空间中,相同的动作应该具有相同的表示。此外,相邻信息 Nt 和 Et 处于状态st = st−1 U {at−1, nt , Nt , Et } 与状态 st 中的动作空间具有相同的含义和表示。因此,具有共享参数的全连接网络用于对实体和关系进行编码。 我们通过所有实体和关系的一维最大池化来提取邻居信息 Nt 和 Et 的表示。
在图 1 中,在时间 t 占主导地位的实体是 nt,其相邻实体是 n1t,n2t,...。.., nkt , 对应关系为 e1t, e2t , ..., 等。 参数共享网络fθa是一个双层全连接网络,输出是每个节点信息的编码hnkt。 为了解决不同实体具有不同数量的相邻实体和关系的问题,采用一维最大池化方法生成相邻信息的表示hAt。 hAt 的每一位的值是每个动作向量中所有对应位的最大值。
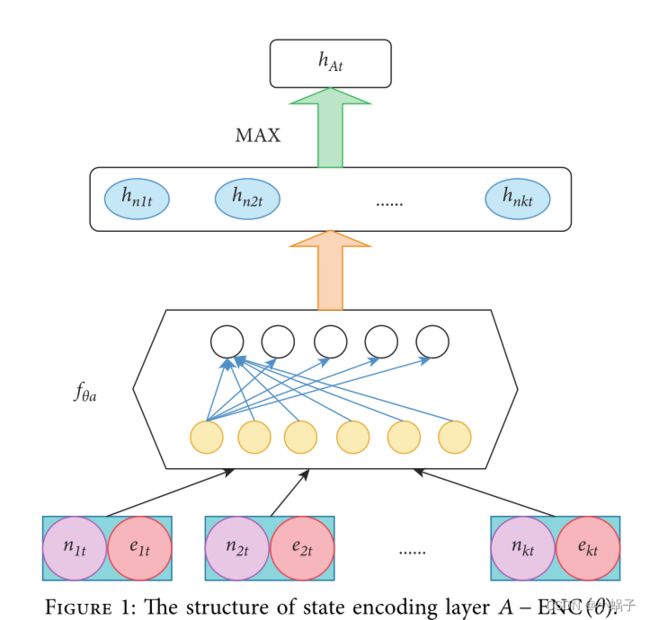
作为深度代理网络的第一部分,完整的动作空间编码层将用于处理动作空间和状态编码中的相邻信息。
相邻信息编码(hAt图一得出的)将是状态编码层 S-ENC(θ) 的输入的一部分,而动作编码将是策略决策层 πθ 的输入的一部分。
4.2.2具有时间卷积网络的状态编码层
在深度代理网络中,状态的输入非常重要。时间卷积网络更擅长捕捉时间依赖性。 卷积更容易捕捉到局部信息,空洞卷积还可以扩大感知范围,让输出在任何时候都能感知到前一次的所有输入。此外,在对完整的动作空间和相邻信息进行编码后,状态 st 可以表示为 st = st−1 U {at−1, nt , hAt }。时间卷积网络用于获取历史状态信息,其结构如图2所示。
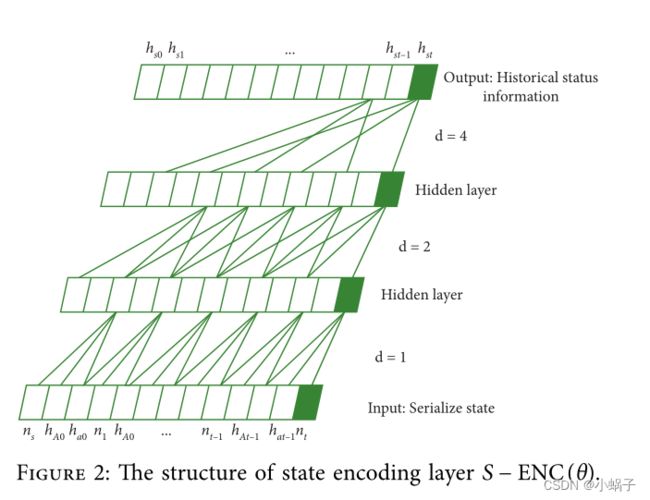
在图2中,nS=n0是状态的初始节点,nt是当前节点,hAt-1是t-1时刻的邻接信息码,hat-1是t-1时刻选择的动作码。将序列化状态编码为序列信息,利用因果卷积来限制时间性,使得后一层任何位置的结果只与前一层该位置之前的数据相关。同时,通过使用扩张卷积来扩展感受野。状态表示的递归结构使终止状态包含了转换的所有先前状态。最后输出完整的历史信息hs0、hs1、hst。为了增强对代理策略网络当前状态的识别,最终状态的编码结合相邻节点编码的hAt和t时刻的历史信息hst,得到t时刻的状态:

4.2.3政策决策层网络
深度代理网络主要集中在决策层,它接收从环境特征中提取的数据,判断每个动作在当前动作空间中的概率。在本文中,使用全连接网络将环境状态特征映射到输出动作。其结构如图3所示。

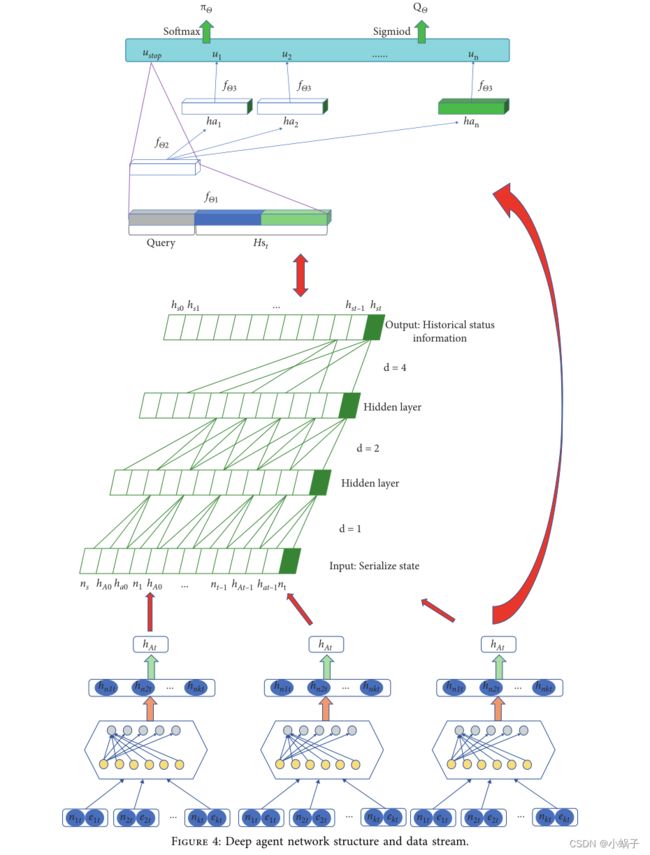
在图 3 中,agent 的决策层网络接收 S − ENC(θ) 层给出的状态特征向量 Hst 和查询关系向量 query 作为决策层 πθ 的输入。压缩后的特征数据应用于两部分,一是生成终端动作astop的选择概率,另一部分是通过结合动作编码层生成的动作编码生成其他动作的选择概率。其结构如下:

其中fθ1、fθ2和fθ3是全连接网络,cat是张量拼接操作,拼接状态特征向量 Hst 和查询关系向量 query ,特征向量 (query, Hst) 由网络 fθ 1 压缩。然后作为环境特征,一方面直接使用特征向量生成ustop。另一方面,结合候选动作由动作编码层生成的向量,每个动作的值通过网络 fθ3 拟合。 δ 代表 sigmoid 函数,用于转换 (ustop , u1 , ..., un ) 到 0 到 1 范围内的 Q 值。 φ 表示 softmax 函数并转换 (ustop , u1 , ..., un ) 转化为候选动作概率。决策网络选择概率最大的动作作为当前代理网络的最终输出动作。
图 4 显示了完整的深度代理网络结构。将原始知识图表示的数据输入最底层的动作编码层,同时输出 hA0 , hA1 ,..., hAt 和每个候选动作 hat。生成的向量用于构建时间历史信息和策略编码层网络以从候选动作中进行选择。
4.3环境探索和智能体训练预测
4.3.1结合策略探索的树上置信界算法
在大规模的网络结构中,节点关系复杂,源节点到目标节点的路径数量巨大,这也导致了一个重要问题:策略网络训练过程中的采样效率低。如果采用on-policy方式,模型的训练会变得很慢,因为模型在很长一段时间内都找不到正奖励。因此,我们使用蒙特卡洛树搜索方法构建状态搜索树来保存每个状态的值和访问次数,从而解决稀疏奖励问题。 其核心算法UCT(Upper Confidence Bound Applied to Trees)在知识图中表示如下:

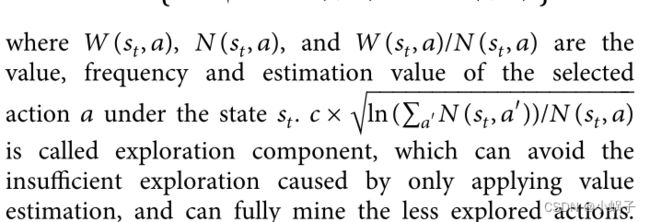 其中 W(st , a)、N(st , a) 和 W(st , a)/N(st , a) 是状态 st 下所选动作 a 的值、频率和估计值。c ×
其中 W(st , a)、N(st , a) 和 W(st , a)/N(st , a) 是状态 st 下所选动作 a 的值、频率和估计值。c ×![]() ln(a′N(st , a′ ))/N(st , a) 称为探索组件,可以避免仅应用价值估计造成的探索不充分,可以充分挖掘探索较少的动作。
ln(a′N(st , a′ ))/N(st , a) 称为探索组件,可以避免仅应用价值估计造成的探索不充分,可以充分挖掘探索较少的动作。
当UCT选择终止动作astop或达到最大搜索深度时,MCTS完成一次模拟,并使用
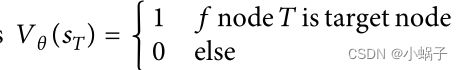
更新W(st, a) 和 N(st, a)。
本文中的采样策略是结合策略决策网络对UCT算法进行改进,增强采样的探索性能,从而降低陷入局部最优的可能性。应用于树结合策略探索(Policy-UCT)的置信上限算法如下
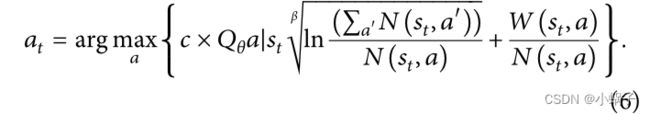
我的核心思想是在 MCTS 的探索过程中,利用策略网络给出的 Q 值来动态调整每个状态下每个动作的探索率。在具有相同探索项值的候选动作中,策略网络给出的更有价值的动作更容易被算法探索。在同一个源节点的情况下,可能有多个路径到目标节点。Q 值随着训练过程的变化而变化,agent 认为值高的动作更可能导致目标节点。 因此,policy-UCT倾向于选择具有高值W(st,a)/N(st,a)的动作进行节点探索,而节点探索倾向于选择具有更高Qq值和更低访问时间N(s,a)的动作。
4.3.2模型训练
本文的关键思想是使用策略增强的蒙特卡罗树搜索来模拟一系列具有正奖励的轨迹的产生。从这些轨迹中学习可以显着改善 πθ。在本文中,我们加强了深度代理网络并反复应用这些步骤来改进探索策略以获得更多的采样轨迹。但是,数据是由不同的深度代理生成的网络参数,即off-policy数据,打破了策略梯度法的固有假设。所以我们使用这个数据用 Q-Learning 方法进行更新。
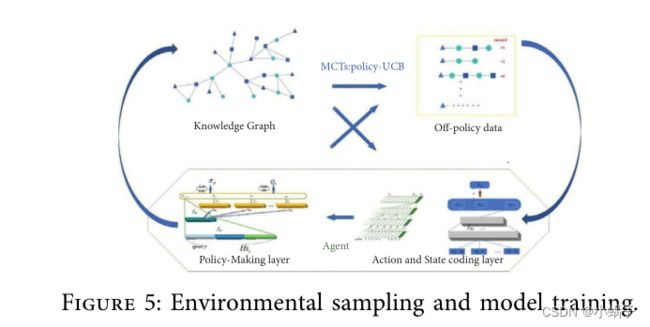
步骤1:知识图谱数据集、动作决策网络和状态编码网络的初始化。初始化具有相同参数的深度代理的动作网络和评估网络。
步骤2:Monte Carlo Tree Search of Policy-UCT算法用于从知识图中收集样本,并将样本以轨迹的形式存储在轨迹存储池中,直到存储池达到最大容量。如果存储池在采样开始前达到最大容量,则新添加的轨迹将替换最早的轨迹。替换达到一定数量后,开始下一步。
步骤3:从存储池中提取轨迹用于网络训练,小批量更新深度代理动作网络参数。
步骤4:新的策略网络 πθ 将继续通过 Policy-UCT 的方式从知识图谱中采样,结合 Monte Carlo Tree Search。重复步骤 2 和步骤 3 更新深度代理网络参数,直到更新 Q-net 评估网络的条件。深度代理的当前网络参数用于覆盖评估网络的参数。
步骤 5:重复步骤 1-4,直到损失误差达到要求或预设的训练次数。输出最终的深度代理网络
简单DQN的更新公式如下:
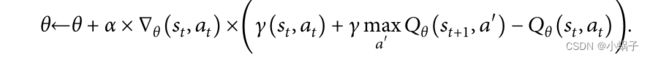
为了避免高估状态值,Double-DQN 用于更新深度代理网络的参数。将动作网络在评价网络中选择的动作a′得Qθ (st+1, a′ ) 的值更改为:
![]() 在目标网络的更新中,动作网络和评估网络具有相同的初始化条件。 为了减少动作网络和评价网络同步更新引起的训练波动的收敛困难,我们使用了Q-Learning中常用的延迟更新,即评价网络在动作网络被同步更新后同步更新。最后,新的行动网络将继续在下一次MCTS中使用,新的评估网络将用于评估行动网络的选定行动。
在目标网络的更新中,动作网络和评估网络具有相同的初始化条件。 为了减少动作网络和评价网络同步更新引起的训练波动的收敛困难,我们使用了Q-Learning中常用的延迟更新,即评价网络在动作网络被同步更新后同步更新。最后,新的行动网络将继续在下一次MCTS中使用,新的评估网络将用于评估行动网络的选定行动。
4.3.3模型预测
为了充分利用网络结构的优点,MCTS和Q值相结合,在预测过程中生成蒙特卡洛树搜索,就像训练过程一样。在搜索的过程中,路径不断产生。搜索结束,反馈传播的值将不再使用0和1的标签值,而是使用Vθ(sT)=Q(sT,astop)。最后对生成的多条路径进行加权,得到路径分数Score(path) = Npath /N,其中所有生成路径的个数为N,路径个数为Npath,Scose(path)表示比例当前路径分数。因此,目标实体的最终预测分数如下:

其中 pathnT 表示具有终止节点 nT 的路径,sT path 表示路径的终止状态 sT。可以想象,具有终止节点 nT 的路径可能具有不同的终止状态。因此,当我们考虑通过不同路径游到同一个终止节点nT的情况时,根据agent给出的终止动作值Q(sT path , astop )计算当前状态下的网络得分。根据搜索过程中目标节点的频率和终止状态,Scose(nT) 充分整合了代理网络决策和网络结构数据。然后补全节点根据分数进行排序。最后,许多信息检索评估算法,如MRR和MAP,将用于评估完成结果的排序顺序。
5.实验
5.1数据集和评估指标

我们使用 WN18RR [48] 和 NELL995 来验证我们的模型 GA 的实际效果。知识图谱补全数据集的 统计量如表 1 所示。我的 WN18RR 数据集是从 Dettmers.T 处理的原始 WN18 数据 [49] 中获得的。NELL995 数据集由熊 [19] 处理和发布,并被处理成多个关系的单独数据部分。我们使用与 [19-21] 中相同的数据分割和预处理方法。实验和在 NELL995 中对 10 个关系任务进行了评估。
我们使用 HITS@K 和平均循环秩 (MRR) 作为 WN18RR 的评估指标。
- HITS@K计算目标实体在top K中的百分比。MRR计算目标实体排名倒数的平均值,表示目标实体排名越高,MRR得分越高。
使用平均准确度均值(MAP)作为 NELL995 数据集的评估指标。
GA模型与DeepPath比较和基于强化的 MINERVA在知识图谱的补全任务中学习,基于嵌入的方法 DistMult [50]、ComplEx [51] 和 TransE,以及学习逻辑规则的方法 NeuralLP [52]。对于所有基线方法,我们将采用相应作者发表的实验设置和他们论文中的最佳实验结果。
5.2实验结果
数据集 NELL995 和 WN18RR 的整体性能分别如表 2 和表 3 所示。很明显,与 MINERVA、DeepPath、PRA、TransE 和 TransR 相比,GA 通常在 NELL995 中取得了最好的结果。GA 仍然表现良好,WN18RR 优于 MINERVA、ComplEx、ConvE、DistMult 和 NeuralLP。
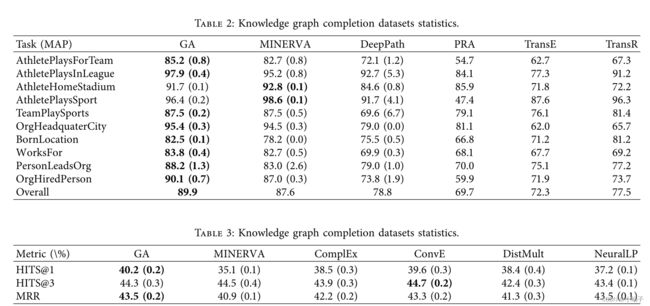 从表 2 和表 3 的实验结果可以看出,时间卷积网络可以用于对知识图谱上的历史状态进行编码,类似于递归神经网络编码。并且在一些相对较长的关系路径中可以获得更好的结果。
从表 2 和表 3 的实验结果可以看出,时间卷积网络可以用于对知识图谱上的历史状态进行编码,类似于递归神经网络编码。并且在一些相对较长的关系路径中可以获得更好的结果。
在 NELL995 的十个关系中,GA 几乎是最好的结果。在 WN18RR 的训练过程中,可以清楚地发现大多数目标实体和源实体仅通过一跳关系连接。 因此,使用 HITS 作为评估指标,GA的效果往往是对比中最好的。
5.3Policy-UCT 算法的影响

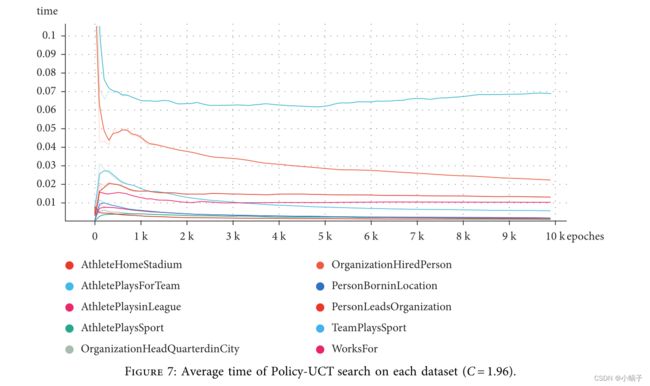
蒙特卡洛树搜索可以根据奖励函数完全返回正奖励,如图 6-8 所示是图 6 和图 7 数据集的预测生成路径的过程。显然,MCTS充分利用了类似于树形结构的图结构,大大提高了MCTS探索的效率。在探索的早期,我们倾向于在广度上进行探索,这既费时又难以获得奖励。在探索的后期,我们更倾向于选择价值较大的目标节点,每次搜索的路径基本较短。在实验中,我们经常可以看到生成正奖励的路径长度一般为2、3、4(最长的探索路径为10)。从计算时间可以看出,随着模型对环境的探索更全面,模型的平均探索长度也在减少,算法更倾向于容易获得正奖励的路径。 在环境中进行连续搜索,算法的平均正回报率在 80% 以上。只是在蒙特卡洛树搜索的后期也有很多重复的正奖励路径。虽然奖励的正向率不断上升,但也带来了智能体陷入局部最优的风险。 因此,在实验中,当正向奖励率高于某个值时,采样方式会使用agent的自主行走,将得到的路径加入到轨迹存储池中,使用随机批量训练来降低数据之间的相关性。
5.4结果的可解释性分析
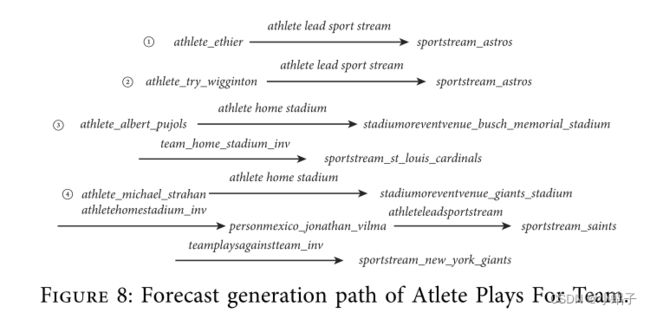
与流行的嵌入模型相比,我们的模型在补全知识图谱方面具有更高的可解释性。提出的模型使用强化学习从源节点开始走,每一步由模型决定关系和对应的下一个节点,直到模型选择终端动作,从而生成从源实体到目标的完整路径实体。由于路径是实体和关系的集合,我们可以看到路径每一步的关系转换。面对一个问题,人们往往通过问题之间的关系把它与他人联系起来。因此,模型产生结果的方式非常接近人类的思维方式。为了验证行走路径是否符合人类推理认知,在NELL995数据集中,我们从关系完成结果中随机抽取4条完成路径(Atlete Plays For Team),分析目标选择全过程路径的合理性,以便解释模型在自然界中的可解释性,而不是量化。
从以上结果可以看出,要完成的实体是运动员,对应关系是“运动员为哪个队效力”。前两项之间的关系是“运动员领导的团队”,它准确地解释了运动员为哪个团队效力。在第三种情况下,路径经过中间节点,两个关系从运动员指向主场,然后找到主场球队来确定运动员的球队。当主场和运动队是唯一对应的时候,这条路径具有很好的可解释性。即使不是唯一对应,该路径在一定程度上也可以作为推理的依据。我的第四个完成路径是比较复杂。该模型虽然通过存在关系找到目标团队,但并不能完美地用关系来解释。因为实际模型的每一步的选择都是由关系和实体决定的。而且,“队对队”不具体,削弱了解读能力。
如构建马尔科夫过程所述,以能否找到目标节点为唯一奖励,代理只将策略与目标节点关联,行走路径与完成目标节点的真正原因正相关,但不等价。然而,完成路径的解释能力仍然难以量化。 我在路径中相同的关系有不同查询关系的解释。例如,如果要查询的关系是“Athlete Plays In League”,那么“队对队”可以成为通向目标的桥梁,具有极好的解释能力,因为对战队的联赛也是在运动员所扮演的。 因此,模型的可解释性需要进一步研究。
6.结论
论文在前人的基础上进行了总结和扩展,在网络结构上构建了强化学习马尔可夫过程描述,并设计了环境探索和深度代理网络。知识图谱上马尔可夫过程的定义也适用于其他形式的图结构。考虑到知识图谱环境中的状态是由序列数据表示的,通常采用易于并行化的时间卷积网络进行状态的特征提取和编码。灵活的卷积核大小更适合捕获递归状态结构。与循环神经网络的输出和输入相比,大大降低了时间的消耗。 此外,由于网络结构和交叉链接的复杂性,由于搜索正奖励的能力有限,很难有效地训练代理网络。本文采用 M-walk 和 AlphaGO 环境探索方法 Monte Carlo Tree Search,大大提高了正向奖励的获取率,并充分利用了图与搜索树的相似性。在测试数据集中的平均积极奖励超过 80%。经过充分的训练,代理可以准确地走到目标节点。我们使用了合理的正相关假设,但该关系对应的真实完成路径并不完全等同于使用正奖励生成的路径。 在接下来的工作中,我们可以考虑一组更接近的正相关假设,并以具有附加约束的新返回函数的形式对其进行描述。完成模型的可解释性也有一些挑战,可以成为未来工作的一部分。