谷歌:基于深度强化学习的芯片放置
论文:Chip Placement with Deep Reinforcement Learning
相关文章:
知乎: Forever snow: Google芯片自布局论文解读
CSDC: 布谷AI : 深究强化学习在谷歌芯片布局上的应用
介绍
谷歌在这篇文章中提出了一个基于强化学习的芯片放置方法,芯片放置位于图中的红色方框中,是芯片设计过程中最为耗时和复杂的阶段之一。普通情况下,该阶段需要专业工程师花费使用现有工具工作数周时间进行迭代,以满足各种设计需求,而该方法方法可以将时间压缩至6个小时。芯片放置的复杂度来源于网表的大小 、选择网格粒度及用EDA工具计算真实的目标指标,该问题的复杂度可能达到10的9000次方,远超国际象棋和围棋等。

谷歌将芯片布局作为一个强化学习问题,训练一个代理进行芯片布局。每次训练迭代中,代理将芯片中的所有宏模块按次序放置,然后通过力导向的方法放置标准单元。宏模块的次序由宏的大小及其拓扑序决定,除最后一步的奖励由布线长度及拥挤度计算,其他步骤的奖励为0。
该文章完成的工作是将芯片中宏单元的放置,对于标准的单元依然采用了传统的方法,其结果略优于19年提出的Replace方法,类似或优于专家几周的工作成果。
马尔科夫决策
马尔科夫决策过程由含有5个元素的元组组成,分别为状态、动作、转移概率、奖励和折现因子,但在谷歌的工作中,仅取了其中三个,状态、动作和奖励。分别如下:
状态:
网表图、其节点特征(宽度、高度、类型等)的信息,边缘特征(连接数)、要放置的当 前节点(宏),以及网表和底层技术的元数据(布线分配、导线总数、宏和标准单元簇等)
动作:
谷歌将芯片布局转换为m×n网格。因此,对于任何给定的状态,动作空间是当前宏在m×n网格上的位置的概率分布。动作是这个概率分布的argmax。
奖励:
由线长和拥塞计算的近似代价函数。其中,线长定义为半周长布线长度HPWL, 网表中所有节点的边界框的半周长,并假设所有离开标准单元簇的导线都起源于簇的中心。拥塞分别跟踪每个网格单元的垂直和水平分配,取前10%的平均拥塞。
其他细节
密度:
将密度视为一个硬约束,不允许将宏放置到密度超过最大值或导致不可行的宏重叠的位置 减少产生的无效位置数量,并减少了搜索空间,计算更快。
宏次序:
按宏的大小降序排序,并使用拓扑排序,使连接的节点彼此靠近。
标准单元:
使用了一种类似于经典的力导向方法的方法。
后处理 :
为了使用商业EDA工具评估布局,执行了一个贪婪的合法化步骤,在遵守最小间距约束的同 时,将宏捕捉到最近的合法位置后固定位置,使用EDA工具放置标准单元并评估布局。
奖励函数的计算
由于传统芯片布置所关注的功耗、性能和面积(统称PPA)难以计算,因此采用了简单的线长和拥塞来代替,实验也证明了对于后者的优化也达到了对PPA的优化。
为了快速获取线长和拥塞并计算出奖励函数,设计了一种图神经网络架构(GCN),该架构输入为网表信息,通过串联节点特征,对每一个节点采用矢量表示,节点特征包括节点类型,宽度,高度以及坐标。GCN的框架如下图。
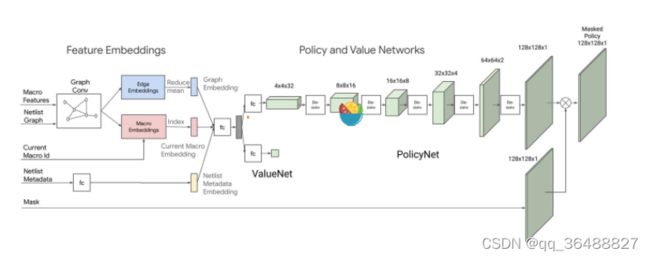
为了训练这个网络,谷歌用了5个block,为每一个block建立了 2000中布局,共1w个芯片放置数据信息,
结果
论文中提到了一系列对比,总体结果为经过微调的策略网络能更好的适应从未见过的芯片布置任务,布置成本更低。随着增大训练集数据,能够加快训练过程并更快地产生更高质量的结果,并且对于宏模块的较多的网表布置结果更好。
此外,还与模拟退火算法和Repalce和人工布置比较,明显优于模拟退火算法(好久前的东西了),跟Replace和人工布置的结果似乎伯仲之间(Replace是19年提出的新算法),还算不错的。谷歌提出的方法产生的结果来看其实略优于Replace,但用了3-6小时完成,而Replace则为 1-3.5个小时。