联合检测和跟踪的MOT算法(一)
参考:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/105320746
最近一年里,随着 Tracktor++ 这类集成检测和多目标跟踪算法框架的出现,涌现了很多相关的多目标跟踪算法变种,基本都位列 MOT Challenge 榜单前列,包括刚刚开源的榜首 CenterTrack。这里我就对集成检测和跟踪的框架进行分析。
1、D&T:Detect to Track and Track to Detect
论文标题: Detect to Track and Track to Detect
论文作者: Christoph Feichtenhofer, Axel Pinz, Andrew Zisserman
备注信息: ICCV 2017
论文链接:https://arxiv.org/abs/1710.03958
代码链接: https://github.com/feichtenhofer/Detect-Track
论文解读: https://blog.csdn.net/Meihuashan_HUST/article/details/84867690
当前的多目标跟踪算法主流是基于检测的框架,即 Detection based Tracking (DBT),所以检测的质量对于跟踪的性能影响是很大的。
那么在 MOT Challenge 上也分别设置了两种赛道,一种是采用官方提供的几种公共检测器的结果,即 public 赛道,一种是允许参赛者使用自己的检测器,即 private 赛道。
这篇 D&T 就属于 private 类跟踪框架,并初步将检测与跟踪框架进行了结合:
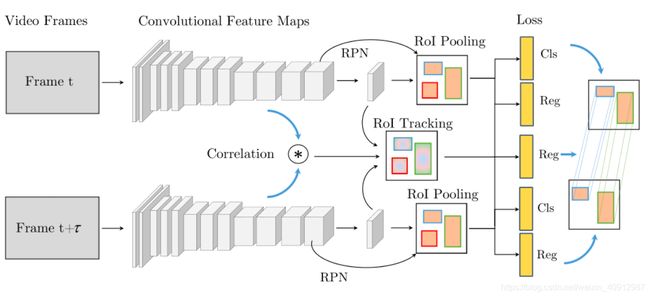
结果:
使用D&T比只有D的R-FCN提高了5个点,将backbone从res-101换为inception v4提高3%,添加的ROI tracking使得时间多了14ms,这是可以接受的。轨迹连接由于不能用GPU加速,会使得CPU的耗时增大46ms,这个增加的有点多。
优点:
1.本文在VID数据集上的评估结果要优于2016年VID比赛的冠军,同时简单高效。
2.本文提出的跟踪损失,对于静态图像的检测也是有益的,同时增加输入帧的时间步长可以得到D&T更快速的版本。
2、MOTDT:Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification
论文标题: Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification
论文作者: Long Chen, Haizhou Ai, Zijie Zhuang, Chong Shang
备注信息: ICME 2018
论文链接: https://arxiv.org/abs/1809.04427
代码链接: https://github.com/longcw/MOTDT
论文解读:https://blog.csdn.net/ycc2011/article/details/84982778
总体概述:
(期待后续…)
3、Tracktor++:Tracking Without Bells and Whistles
论文题目: Tracking Without Bells and Whistles
论文作者: Philipp Bergmann,Tim Meinhardt,Laura Leal-Taixe
备注信息: ICCV2019,MOT15~17: 46.6, 56.2. 56.3 MOTA (public)
论文链接:https://arxiv.org/abs/1903.05625
代码链接:https://github.com/phil-bergmann/tracking_wo_bnw
论文解读:https://blog.csdn.net/ycc2011/article/details/88776690
主要工作:提出一个基于检测器的多目标跟踪框架。
Tracktor++ 算法是去年出现的一类全新的联合检测和跟踪的框架,这类框架与 MOTDT 框架最大的不同在于,检测部分不仅仅用于前景和背景的进一步分类,还利用回归对目标进行了进一步修正。

只要熟悉两阶段目标检测算法的应该都能理解这个算法,其核心在于利用跟踪框和观测框代替原有的 RPN 模块,从而得到真正的观测框,最后利用数据关联实现跟踪框和观测框的匹配。流程图如下:

有了检测模块的加持,自然对于检测质量进行了增强,所以效果也得到了大幅提升:
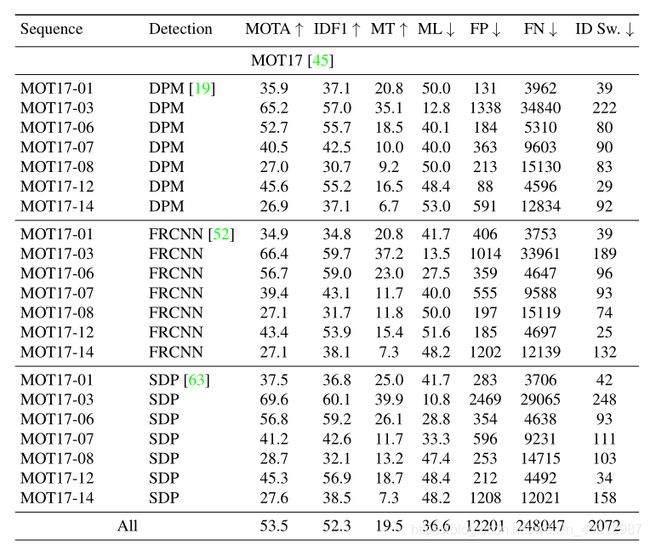
可以看到,DPM、FRCNN 和 SDP 三种检测器输入下的性能差距不大,然而 DPM 检测器的性能是很差的,所以 Tracktor++ 这类算法对于平衡检测输入的效果提升很大。
4、FFT:Multiple Object Tracking by Flowing and Fusing
论文标题: Multiple Object Tracking by Flowing and Fusing
论文作者: Jimuyang Zhang, Sanping Zhou, Xin Chang, Fangbin Wan, Jinjun Wang, Yang Wu, Dong Huang
备注信息: CVPR2020,MOT15~17: 46.3, 56.5. 56.5 MOTA (public)
论文链接:https://arxiv.org/abs/2001.11180
代码链接: 未开源
论文解读:https://www.pianshen.com/article/19471163876/
(期待后续…)
5、JDE:Towards Real-Time Multi-Object Tracking
论文标题: Towards Real-Time Multi-Object Tracking
论文作者: Zhongdao Wang, Liang Zheng, Yixuan Liu, Shengjin Wang
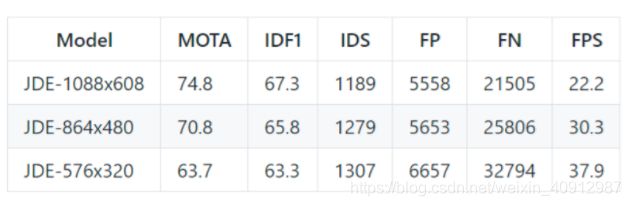
备注信息: 2019,MOT16 74.8 MOTA (private), 22FPS!!
论文链接: https://arxiv.org/abs/1909.12605
代码链接: https://github.com/Zhongdao/Towards-Realtime-MOT
论文解读:
JDE 这篇跟这次的主题不是很相符,但是考虑到这也是近期比较热门的实时多目标跟踪算法,也一起讲。它的框架出发点是为了增加特征的复用性,基于检测算法(作者采用的是 YOLOv3),在原本的分类和回归分支上增加了一个表观特征提取的分支。

文中作者重点介绍了多任务网络框架的训练方式,首先分析了三种 Loss:

对于 triplet loss,这个在表观模型的 metric learning 任务中很常见,作者采用了 batch hard 模式,并提出了 triplet loss 的上界,推导很简单,关键在于多的那个 1 。为了更好地跟交叉熵损失函数进行比较,作者将上界进行了平滑。
那么区别就在于 g ,g 表示的正负样本的权重。在交叉熵损失函数中,所有的负样本都会参与计算,然而在 triplet loss 中,负样本是采样出来的,所以:

作者通过实验也论证了上面的结论,所以在 metric learning 中作者采用了交叉熵损失函数。最后关于各个任务的损失函数的权重,作者提出了一种自适应平衡的加权方式:

其中的 s 是一种度量不同任务下个体损失的不确定性因子,详细的原理可参见 CVPR 2018 的 Multi-task learning using uncertainty to weigh losses for scene geometry and semantics 关于方差不确定性对于多任务权重的影响分析。
效果和速度都很诱人~
6、MIFT:Refinements in Motion and Appearance for Online Multi-Object Tracking
论文标题: Refinements in Motion and Appearance for Online Multi-Object Tracking
论文作者: Piao Huang, Shoudong Han, Jun Zhao, Donghaisheng Liu, HongweiWang, En Yu, and Alex ChiChung Kot
备注信息: 2020,MOT15~17: 60.1, 60.4, 48.1 MOTA (public)
论文链接:https://arxiv.org/abs/2003.07177
代码链接:https://github.com/nightmaredimple/libmot(还未完全开源)
这篇也是我们团队基于 Tracktor++ 框架做的一个框架,主要关注的是运动模型、表观模型和数据关联部分的改进。
(期待后续…)
7、Center Track:Tracking Objects as Points
论文标题: Tracking Objects as Points
论文作者: Xingyi Zhou (CenterNet 的作者), Vladlen Koltun, and Philipp Krähenbühl
备注信息: 2020,MOT17:61.4(public)、67.3(private) MOTA, 22FPS!!!KITTI:89.4MOTA。同时实现了 2D/3D 多目标跟踪,包含人和车辆
论文链接:http://arxiv.org/abs/2004.01177
代码链接:https://github.com/xingyizhou/CenterTrack
从CenterTrack开始就是based anchor-free的检测了。
CenterTrack 是 CenterNet 作者基于 Tracktor++ 这类跟踪机制,通过将 Faster RCNN 换成 CenterNet 实现的一种多目标跟踪框架,因此跟踪框也就变成了跟踪中心点。

通过上图我们可以大致分析出算法框架,除了对相邻两帧利用 CenterNet 进行检测之外,还利用了上文中提到的 D&T 框架的策略,预测同时存在于两帧中目标的相对位移,由此进行跟踪预测。
对于提供的观测框,作者通过将这些观测框的中心点映射到一张单通道的 heatmap 上,然后利用高斯模糊的方式将点的附近区域也考虑进去。
因此 CenterTrack 相对于 CenterNet 的不同之处在于,输入维度增加了(两幅3维图像和一张观测位置 heatmap),输出变成了两张图像的目标中心位置、大小和相对偏移。
对于测试环节的数据关联部分,作者直接通过中心点的距离来判断是否匹配,是一种贪婪的方式,并非匈牙利算法那种全局的数据关联优化。在训练过程中,作者并非只用相邻帧进行训练,允许跨 3 帧。
CenterTrack 在 MOT、KITTI 和 nuScenes 等数据集上的 2D/3D 多行人/车辆跟踪任务上均取得了 SOTA 的成绩。


8、FairMOT:A Simple Baseline for Multi-Object Tracking
论文标题: A Simple Baseline for Multi-Object Tracking
论文作者: yifuzhang,xgwang,liuwy,华科&微软亚研院团队
备注信息: 2020,MOT15~20(private):59.0、68.7、67.5、58.7 MOTA,MOT15:30.5FPS
论文链接:https://arxiv.org/abs/2004.01888
代码链接:https://github.com/ifzhang/FairMOT
这篇论文的立意是两部分,一个是类似于CenterTrack的基于CenterNet的联合检测和跟踪的框架,一个是类似于JDE,但是却又不同的,探讨了检测框架与ReID特征任务的集成问题。
作者称这类框架为one-shot MOT框架,论文一开始作者讨论了检测框架和ReID任务的关系,通过在三个方面的改进来设计检测框架,然后用简单的deep SORT流程进行跟踪,最后精度和速度都取得了意外的效果。
主要贡献:
(1)锚不适合Re-ID。作者首先提出anchor-based的检测框架中存在anchor和特征的不对齐问题,所以这方面不如anchor-free框架,因此作者选择了anchor-free算法——CenterNet,不过其用法并不是类似于CenterTrack中采取的类似于D&T的孪生联合方式,而是采用的Tracktor++的方式。

(2)多层特征聚合。
我们知道原始的anchor-free框架的大多数backbone都是采用了骨骼关键点中的hourglass结构:
因为Re-ID功能需要利用低级和高级功能来容纳大小两种对象,这里作者就谈到了Re-ID网络中典型的多尺度问题,所以就提出要将hourglass结构改成上图中的多尺度融合的形式。最后通过两个分支完成了检测和Re-ID任务的集成。
(3)ReID特征的维数。以前的ReID方法通常学习高维特征,并在其基准上取得了可喜的结果。但是,作者发现低维特征实际上对MOT更好,因为它的训练图像比ReID少。学习低维特征有助于减少过拟合小数据的风险,并提高跟踪的稳健性。
流程分析:
输入一张图片,经过E-D网络之后得到1/4原图大小的特征图,然后经过4个并行的head,分别做中心点预测、目标wh预测、目标中心偏移量预测、ReID特征提取,最后得到目标bbox和ReID特征,作为输入到deep SORT。
优点: 速度快,精度高,排行第一第二
缺点: