运行paddlenlp入门示例:训练与演算
0. 环境
win10 + NVIDIA GeForce GTX 1660 Ti 6GB
python3.9
cuda 10.2
cudnn 7.6.5
paddlepaddle 2.2.0(已经搭建好GPU版本)
1. 安装PaddleNLP
python -m pip install --upgrade paddlenlp -i https://pypi.org/simple
2. 运行脚本
2.1 创建文件E:\Workspaces\python\nlp\pynlp_10min.py,添加以下内容
import paddlenlp as ppnlp
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset(
"chnsenticorp", splits=["train", "dev", "test"])
print(train_ds.label_list)
for data in train_ds.data[:5]:
print(data)
# 设置想要使用模型的名称
MODEL_NAME = "ernie-1.0"
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
ernie_model = ppnlp.transformers.ErnieModel.from_pretrained(MODEL_NAME)
import paddle
# 将原始输入文本切分token,
tokens = tokenizer._tokenize("请输入测试样例")
print("Tokens: {}".format(tokens))
# token映射为对应token id
tokens_ids = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens id: {}".format(tokens_ids))
# 拼接上预训练模型对应的特殊token ,如[CLS]、[SEP]
tokens_ids = tokenizer.build_inputs_with_special_tokens(tokens_ids)
# 转化成paddle框架数据格式
tokens_pd = paddle.to_tensor([tokens_ids])
print("Tokens : {}".format(tokens_pd))
# 此时即可输入ERNIE模型中得到相应输出
sequence_output, pooled_output = ernie_model(tokens_pd)
print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
# 一行代码完成切分token,映射token ID以及拼接特殊token
encoded_text = tokenizer(text="请输入测试样例")
for key, value in encoded_text.items():
print("{}:\n\t{}".format(key, value))
# 转化成paddle框架数据格式
input_ids = paddle.to_tensor([encoded_text['input_ids']])
print("input_ids : {}".format(input_ids))
segment_ids = paddle.to_tensor([encoded_text['token_type_ids']])
print("token_type_ids : {}".format(segment_ids))
# 此时即可输入ERNIE模型中得到相应输出
sequence_output, pooled_output = ernie_model(input_ids, segment_ids)
print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
# 单句输入
single_seg_input = tokenizer(text="请输入测试样例")
# 句对输入
multi_seg_input = tokenizer(text="请输入测试样例1", text_pair="请输入测试样例2")
print("单句输入token (str): {}".format(tokenizer.convert_ids_to_tokens(single_seg_input['input_ids'])))
print("单句输入token (int): {}".format(single_seg_input['input_ids']))
print("单句输入segment ids : {}".format(single_seg_input['token_type_ids']))
print()
print("句对输入token (str): {}".format(tokenizer.convert_ids_to_tokens(multi_seg_input['input_ids'])))
print("句对输入token (int): {}".format(multi_seg_input['input_ids']))
print("句对输入segment ids : {}".format(multi_seg_input['token_type_ids']))
# Highlight: padding到统一长度
encoded_text = tokenizer(text="请输入测试样例", max_seq_len=15)
for key, value in encoded_text.items():
print("{}:\n\t{}".format(key, value))
# ---------------------------------------------------------------------------------------------------
# 数据读入
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
import numpy as np
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"], max_seq_len=max_seq_length)
# input_ids:对文本切分token后,在词汇表中对应的token id
input_ids = encoded_inputs["input_ids"]
# token_type_ids:当前token属于句子1还是句子2,即上述图中表达的segment ids
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
# qid:每条数据的编号
qid = np.array([example["qid"]], dtype="int64")
return input_ids, token_type_ids, qid
def create_dataloader(dataset,
trans_fn=None,
mode='train',
batch_size=1,
batchify_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
if mode == "train":
sampler = paddle.io.DistributedBatchSampler(
dataset=dataset, batch_size=batch_size, shuffle=shuffle)
else:
sampler = paddle.io.BatchSampler(
dataset=dataset, batch_size=batch_size, shuffle=shuffle)
dataloader = paddle.io.DataLoader(
dataset, batch_sampler=sampler, collate_fn=batchify_fn)
return dataloader
# 模型运行批处理大小
batch_size = 8 # 32
max_seq_length = 128
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# ---------------------------------------------------------------------------------------------------
# PaddleNLP一键加载预训练模型
ernie_model = ppnlp.transformers.ErnieModel.from_pretrained(MODEL_NAME)
model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=len(train_ds.label_list))
# ---------------------------------------------------------------------------------------------------
# 设置Fine-Tune优化策略,接入评价指标
from paddlenlp.transformers import LinearDecayWithWarmup
# 训练过程中的最大学习率
learning_rate = 5e-5
# 训练轮次
epochs = 1 #3
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
# ---------------------------------------------------------------------------------------------------
# 模型训练与评估
import paddle.nn.functional as F
def evaluate(model, criterion, metric, data_loader):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
# print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu))
model.train()
metric.reset()
return np.mean(losses), accu
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model, criterion, metric, dev_data_loader)
model.save_pretrained('E:\\Workspaces\\python\\nlp\\checkpoint')
tokenizer.save_pretrained('E:\\Workspaces\\python\\nlp\\checkpoint')
# ---------------------------------------------------------------------------------------------------
# 模型预测
from utils import predict
data = [
{"text":'这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'},
{"text":'怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'},
{"text":'作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'},
]
label_map = {0: 'negative', 1: 'positive'}
results = predict(
model, data, tokenizer, label_map, batch_size=batch_size)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text, results[idx]))
2.2 创建文件E:\Workspaces\python\nlp\utils.py,添加以下内容
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
def predict(model, data, tokenizer, label_map, batch_size=1):
"""
Predicts the data labels.
Args:
model (obj:`paddle.nn.Layer`): A model to classify texts.
data (obj:`List(Example)`): The processed data whose each element is a Example (numedtuple) object.
A Example object contains `text`(word_ids) and `se_len`(sequence length).
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
label_map(obj:`dict`): The label id (key) to label str (value) map.
batch_size(obj:`int`, defaults to 1): The number of batch.
Returns:
results(obj:`dict`): All the predictions labels.
"""
examples = []
for text in data:
input_ids, segment_ids = convert_example(
text,
tokenizer,
max_seq_length=128,
is_test=True)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input id
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment id
): fn(samples)
# Seperates data into some batches.
batches = []
one_batch = []
for example in examples:
one_batch.append(example)
if len(one_batch) == batch_size:
batches.append(one_batch)
one_batch = []
if one_batch:
# The last batch whose size is less than the config batch_size setting.
batches.append(one_batch)
results = []
model.eval()
for batch in batches:
input_ids, segment_ids = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
segment_ids = paddle.to_tensor(segment_ids)
logits = model(input_ids, segment_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader):
"""
Given a dataset, it evals model and computes the metric.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
criterion(obj:`paddle.nn.Layer`): It can compute the loss.
metric(obj:`paddle.metric.Metric`): The evaluation metric.
"""
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu))
model.train()
metric.reset()
def convert_example(example, tokenizer, max_seq_length=512, is_test=False):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A BERT sequence has the following format:
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A BERT sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If only one sequence, only returns the first portion of the mask (0's).
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`numpy.array`, data type of int64, optional): The input label if not is_test.
"""
encoded_inputs = tokenizer(text=example["text"], max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
def create_dataloader(dataset,
mode='train',
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
if mode == 'train':
batch_sampler = paddle.io.DistributedBatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
else:
batch_sampler = paddle.io.BatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle)
return paddle.io.DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
3. 运行结果
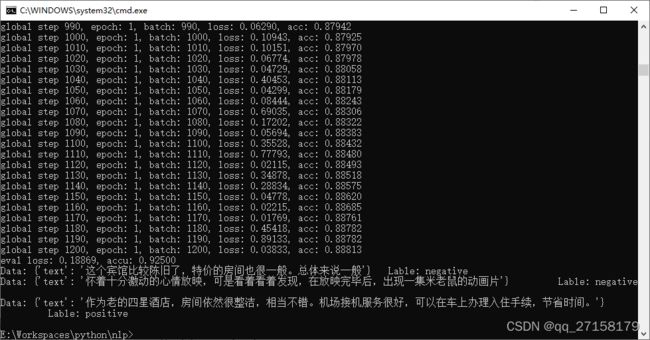
4. 小结
4.1 缺少了utils.py,在参考[3]中找到了。
4.2 当GPU内存不够用时候,需要将batch_size降低。原本batch_size是32的,我的GPU顶不住,改为8,可以顺利运行本示例。
参考
参考[1],10分钟完成高精度中文情感分析
https://paddlenlp.readthedocs.io/zh/latest/get_started/quick_start.html
参考[2],超简单【推特文本情感13分类练习赛】高分baseline
https://blog.csdn.net/weixin_41450123/article/details/120520141?spm=1001.2014.3001.5501
参考[3],『NLP经典项目集』02:使用预训练模型ERNIE优化情感分析,https://blog.csdn.net/qq_15821487/article/details/117123555