A Comprehensive Introduction to Different Types of Convolutions in Deep Learning
Towards intuitive understanding of convolutions through visualizations
如果您在深度学习中听说过不同类型的卷积(例如2D / 3D / 1x1 /转置/扩张(Atrous)/空间可分离/可深度分离/平展/分组/混洗分组卷积),并且混淆了它们实际意味着什么 ,这篇文章是为了解你的实际工作而编写的。
在本文中,我总结了深度学习中常用的几种类型的卷积,并尝试以每个人都可以访问的方式解释它们。 除了这篇文章之外,还有其他几篇关于这个主题的好文章。 请检查出来(在参考文献中列出)。
希望这篇文章可以帮助您建立直觉,并为您的学习/研究提供有用的参考。 请随时留下意见和建议。
The content of this article includes:
-
卷积v.s.互相关
-
深度学习中的卷积(单通道版本,多通道版本)
-
3D卷积
-
1 x 1 卷积
-
卷积算术
-
转置卷积(反卷积,棋盘格工件)
-
扩张卷积(Atrous Convolution)
-
可分离卷积(空间可分离卷积,深度卷积)
-
扁平卷积
-
分组卷积
-
混合分组卷积
-
逐点分组卷积
-
1.卷积v.s.互相关
卷积是信号处理,图像处理和其他工程/科学领域中广泛使用的技术。 在深度学习中,一种模型架构,即卷积神经网络(CNN),以此技术命名。 然而,深度学习中的卷积本质上是信号/图像处理中的互相关。 这两个操作之间存在细微差别。
如果不深入细节,这就是区别。 在信号/图像处理中,卷积定义为:
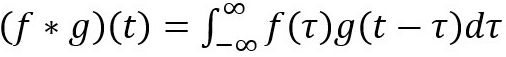
它被定义为两个函数在反转和移位后的乘积的积分。 以下可视化展示了这一想法。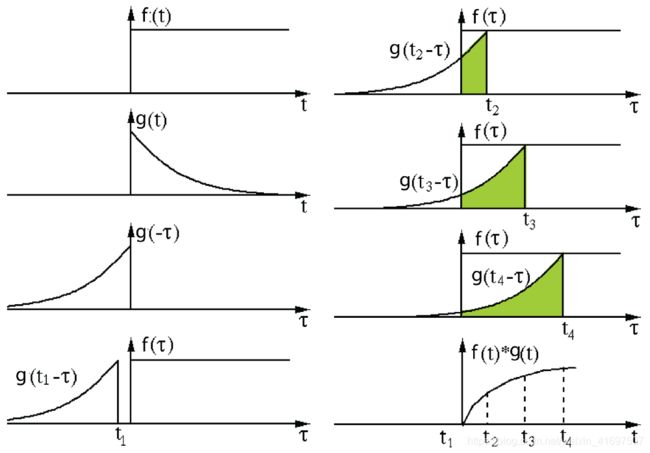
信号处理中的卷积。 过滤器g反转,然后沿水平轴滑动。 对于每个位置,我们计算f和反向g之间的交点面积。 交叉区域是该特定位置的卷积值。 从该链接采用并编辑图像。
这里,函数g是过滤器。 它反转,然后沿水平轴滑动。 对于每个位置,我们计算f和反向g之间的交点面积。 该交叉区域是该特定位置的卷积值。
另一方面,互相关被称为滑动点积或两个函数的滑动内积。 互相关滤波器不会反转。 它直接滑过函数f。 f和g之间的交叉区域是互相关。 下图显示了相关性和互相关之间的差异。
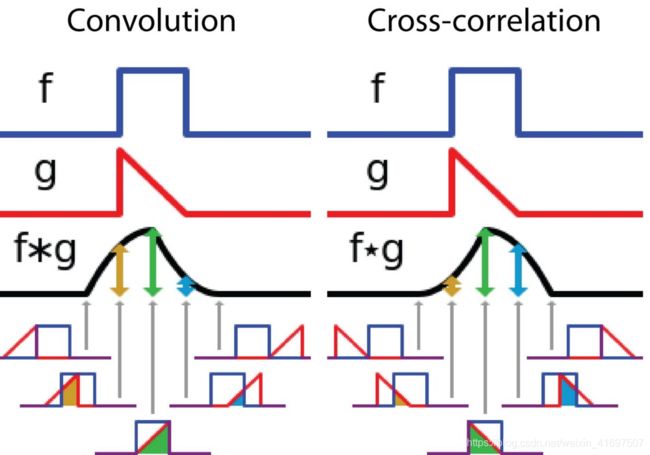
信号处理中卷积和互相关之间的差异。 图像由维基百科采用和编辑。
在深度学习中,卷积中的滤波器不会反转。 严格来说,它是互相关的。 我们基本上执行逐元素乘法和加法。 但是,在深度学习中将其称为卷积是一种惯例。 这很好,因为过滤器的权重是在训练期间学习的。 如果上面示例中的反转函数g是正确的函数,则在训练之后,学习的滤波器看起来像反转函数g。 因此,在训练之前不需要像在真正的卷积中那样反转滤波器。
- 2. 深度学习中的卷积
进行卷积的目的是从输入中提取有用的特征。在图像处理中,可以选择用于卷积的各种不同滤波器。每种类型的过滤器有助于从输入图像中提取不同的方面或特征,例如,水平/垂直/对角线边缘。类似地,在卷积神经网络中,使用在训练期间自动学习权重的滤波器通过卷积提取不同的特征。然后将所有这些提取的特征“组合”以做出决定。
进行卷积有一些优点,例如权重共享和平移不变量。卷积还将像素的空间关系考虑在内。这些对于许多计算机视觉任务尤其有用,因为这些任务通常涉及识别某些组件与其他组件具有某些空间关系的对象(例如,狗的身体通常链接到头部,四条腿和尾部)。
- 2.1. 卷积:单通道版本
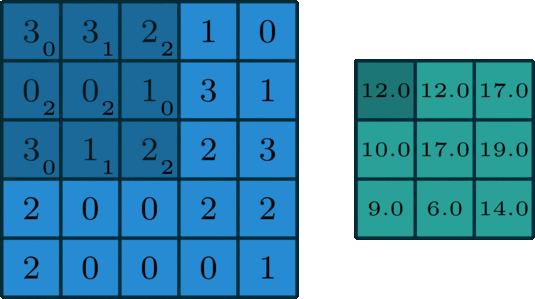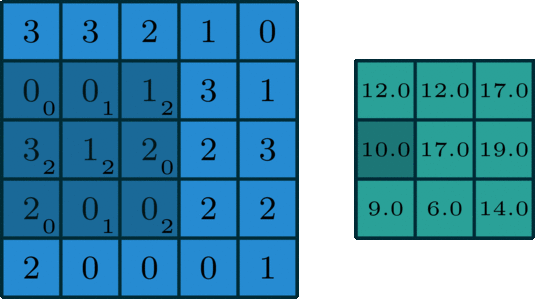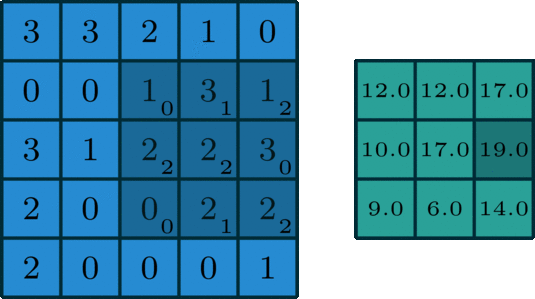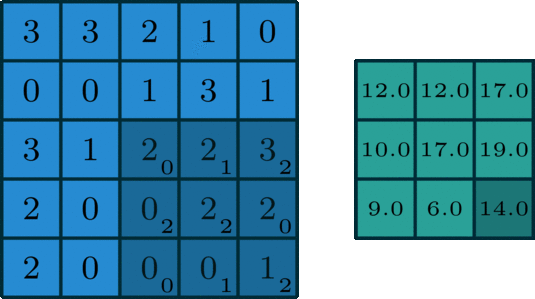
在深度学习中,卷积是元素乘法和加法。 对于具有1个通道的图像,卷积如下图所示。 这里的滤波器是一个3 x 3矩阵,元素为[[0,1,2],[2,2,0],[0,1,2]]。 过滤器在输入端滑动。 在每个位置,它都在进行元素乘法和加法。 每个滑动位置最终都有一个数字。 最终输出是3 x 3矩阵。 (注意,在这个例子中,stride = 1和padding = 0。这些概念将在下面的算术部分中描述。
- 2.2. 卷积:多渠道版本
在许多应用程序中,我们处理的是具有多个通道的图像。 典型的例子是RGB图像。 每个RGB通道都强调原始图像的不同方面,如下图所示。

不同的频道强调原始图像的不同方面。 图像拍摄于中国云南省元阳市。
多通道数据的另一个例子是卷积神经网络中的层。 卷积网络层通常由多个通道(通常为数百个通道)组成。 每个通道描述前一层的不同方面。 我们如何在不同深度的层之间进行过渡? 我们如何将深度为n的图层转换为深度为m的后续图层?
在描述该过程之前,我们想澄清一些术语:层,通道,特征映射,过滤器和内核。 从层次结构的角度来看,层和过滤器的概念处于同一级别,而通道和内核位于下一级。 频道和功能图是一回事。 图层可以有多个通道(或要素图):如果输入是RGB图像,则输入图层有3个通道。 “通道”通常用于描述“层”的结构。 类似地,“内核”用于描述“过滤器”的结构。
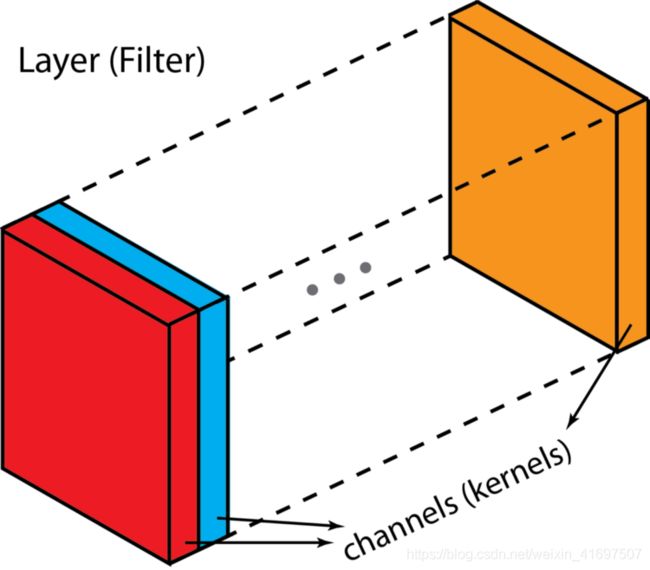
“层”(“过滤器”)和“通道”(“内核”)之间的区别。
过滤器和内核之间的区别有点棘手。 有时,它们可以互换使用,这可能会产生混淆。 从本质上讲,这两个术语有微妙的区别。 “内核”指的是2D重量阵列。 术语“过滤器”用于堆叠在一起的多个内核的3D结构。 对于2D过滤器,过滤器与内核相同。 但是对于3D过滤器和深度学习中的大多数卷积,过滤器是内核的集合。 每个内核都是独一无二的,强调输入通道的不同方面。
有了这些概念,多通道卷积如下。 将每个内核应用到前一层的输入通道上以生成一个输出通道。 这是一个内核方面的过程。 我们为所有内核重复这样的过程以生成多个通道。 然后将这些通道中的每一个加在一起以形成单个输出通道。 下图应该使过程更清晰。
这里输入层是一个5 x 5 x 3矩阵,有3个通道。 滤波器是3 x 3 x 3矩阵。 首先,过滤器中的每个内核分别应用于输入层中的三个通道。 执行三次卷积,产生3个尺寸为3×3的通道。
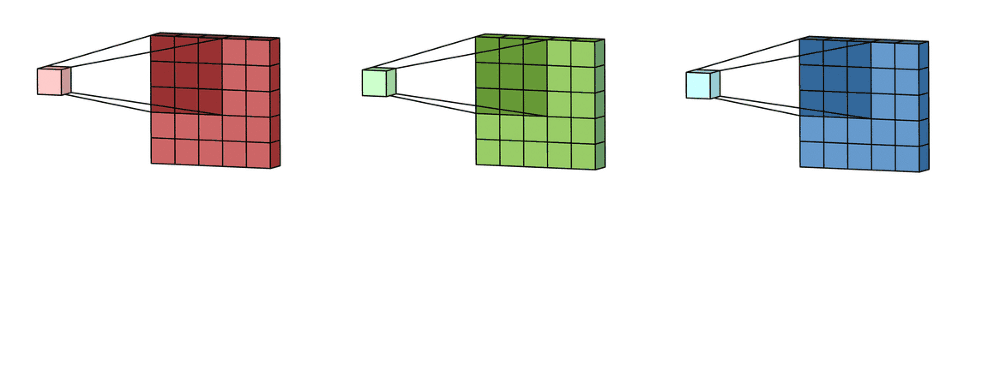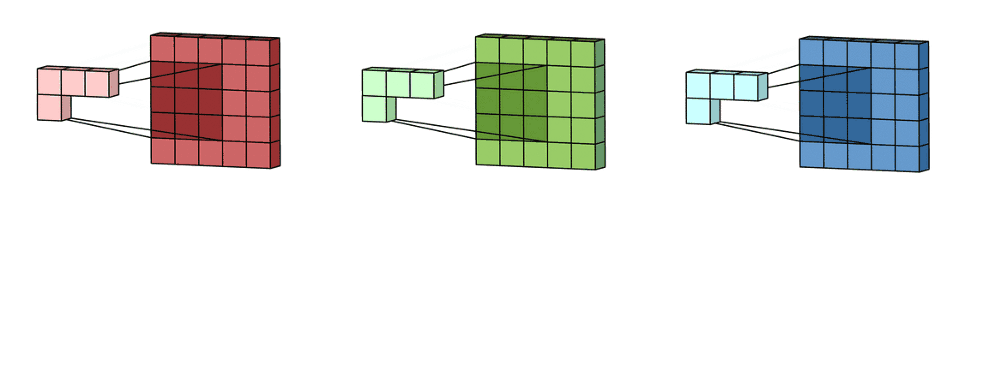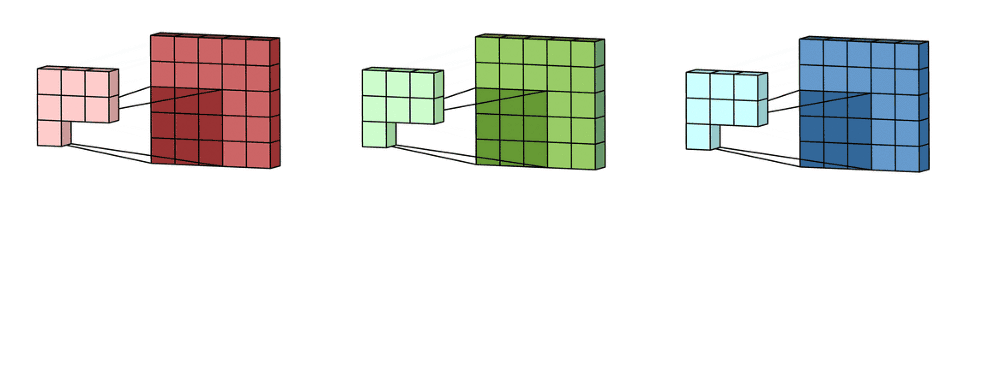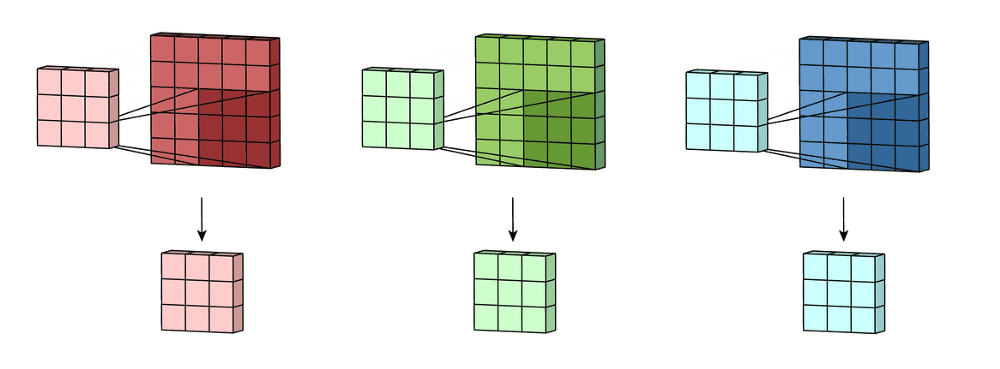
多通道2D卷积的第一步:滤波器中的每个内核分别应用于输入层中的三个通道。
然后将这三个通道相加(元素加法)以形成一个单通道(3 x 3 x 1)。 该通道是使用滤波器(3×3×3矩阵)对输入层(5×5×3矩阵)进行卷积的结果。
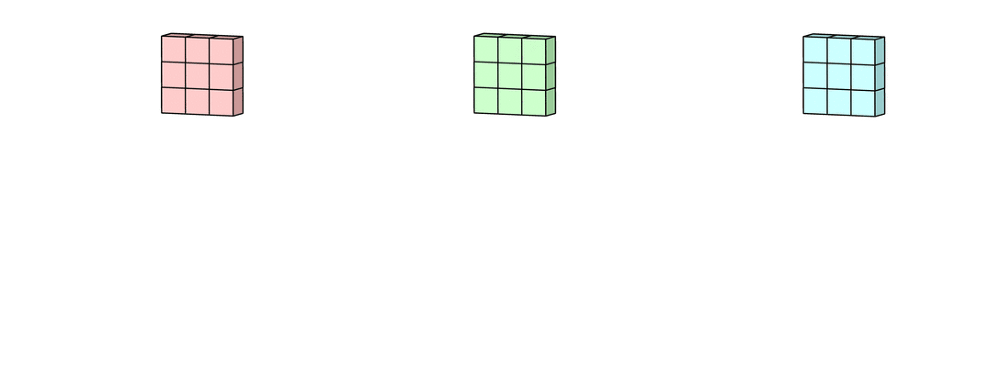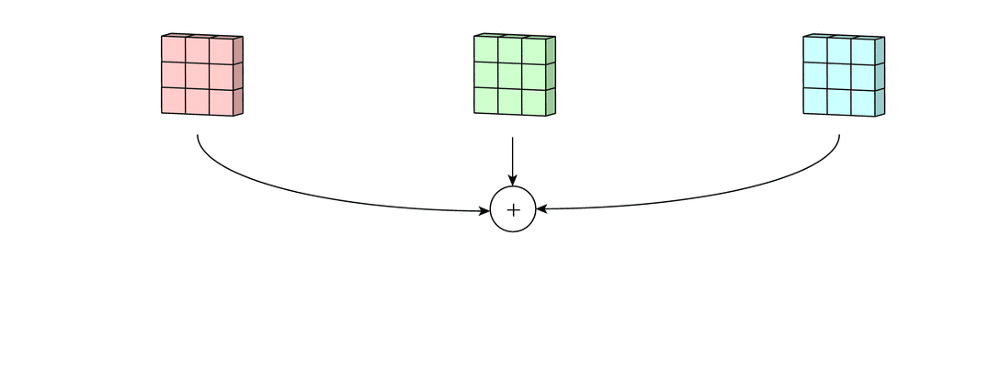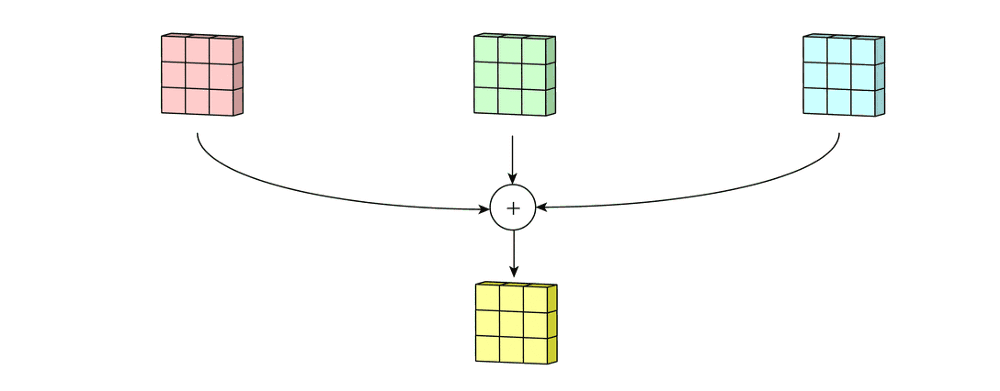
用于多通道的2D卷积的第二步:然后将这三个通道相加在一起(逐元素加法)以形成一个单通道。
同样,我们可以将此过程视为通过输入层滑动3D滤镜矩阵。 请注意,输入层和过滤器具有相同的深度(通道编号=内核编号)。 3D滤镜仅在图像的2个方向,高度和宽度上移动(这就是为什么这种操作被称为2D卷积,尽管3D滤镜用于处理3D体积数据)。 在每个滑动位置,我们执行逐元素乘法和加法,这导致单个数字。 在下面所示的示例中,滑动在水平5个位置和垂直5个位置执行。 总的来说,我们得到一个单一输出通道。
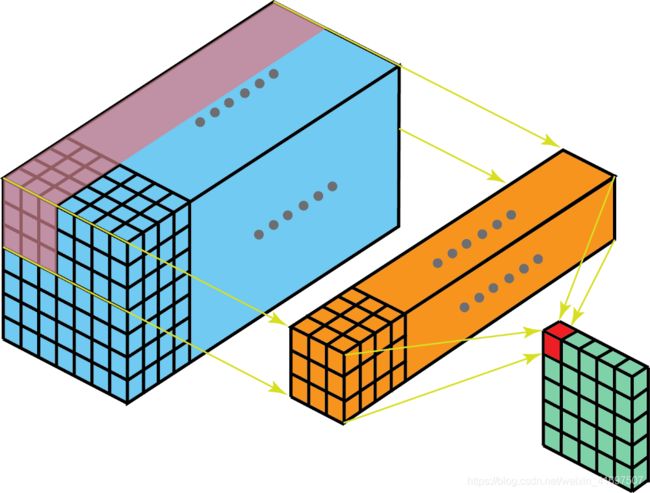
考虑2D卷积的另一种方法:将过程视为通过输入层滑动3D滤镜矩阵。 请注意,输入层和过滤器具有相同的深度(通道编号=内核编号)。 3D滤镜仅在图像的2个方向,高度和宽度上移动(这就是为什么这种操作被称为2D卷积,尽管3D滤镜用于处理3D体积数据)。 输出是单层矩阵。
现在我们可以看到如何在不同深度的层之间进行过渡。 假设输入层有Din通道,我们希望输出层有Dout通道。 我们需要做的是只将Dout过滤器应用于输入层。 每个过滤器都有Din内核。 每个过滤器提供一个输出通道。 应用Dout过滤器后,我们有Dout通道,然后可以将它们堆叠在一起形成输出层。

标准2D卷积。 使用Dout过滤器将具有深度Din的一个层映射到具有深度Dout的另一个层。
- 3. 3D 卷积
在上一节的最后一个插图中,我们看到我们实际上是对3D卷执行卷积。 但通常情况下,我们仍将该操作称为深度学习中的2D卷积。 这是3D体积数据的2D卷积。 滤波器深度与输入层深度相同。 3D滤镜仅在双向(图像的高度和宽度)上移动。 此类操作的输出是2D图像(仅限1个通道)。
当然,有三维卷积。 它们是2D卷积的推广。 在3D卷积中,滤波器深度小于输入层深度(内核大小<通道大小)。 结果,3D滤镜可以在所有3个方向(图像的高度,宽度,通道)上移动。 在每个位置,逐元素乘法和加法提供一个数字。 由于滤镜滑过3D空间,因此输出数字也排列在3D空间中。 然后输出是3D数据。
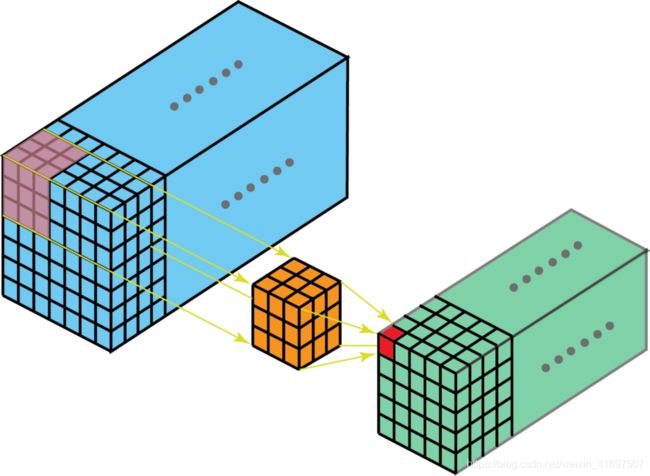
在3D卷积中,3D滤镜可以在所有3个方向(图像的高度,宽度,通道)上移动。 在每个位置,逐元素乘法和加法提供一个数字。 由于滤镜滑过3D空间,因此输出数字也排列在3D空间中。 然后输出是3D数据。
类似于编码2D域中对象的空间关系的2D卷积,3D卷积可以描述3D空间中的对象的空间关系。 这种3D关系对于一些应用是重要的,例如在生物医学想象的3D分割/重建中,例如,生物医学想象的3D分割/重建。 CT和MRI,其中诸如血管之类的物体在3D空间中蜿蜒。
- 4. 1 x 1卷积
由于我们在前面的3D卷积部分讨论了深度操作,让我们看看另一个有趣的操作,即1 x 1卷积。
您可能想知道为什么这有用。 我们只是将一个数字乘以输入层中的每个数字吗? 是和否。对于只有一个通道的图层,操作非常简单。 在那里,我们将每个元素乘以一个数字。
如果输入层有多个通道,事情会变得很有趣。 下图说明了1 x 1卷积如何适用于尺寸为H x W x D的输入层。在滤波器尺寸为1 x 1 x D的1 x 1卷积之后,输出通道的尺寸为H x W x 1.如果我们 应用N这样的1 x 1卷积然后将结果连接在一起,我们可以得到一个尺寸为H x W x N的输出层。

1 x 1卷积,滤波器大小为1 x 1 x D.
最初,在网络网络文件中提出了1 x 1卷积。然后,他们在Google Inception论文中被高度使用。 1 x 1卷积的一些优点是:
降低维度以实现高效计算
高效的低维嵌入或特征池
卷积后再次应用非线性
在上图中可以观察到前两个优点。在1 x 1卷积之后,我们显着地减小了尺寸。假设原始输入有200个通道,1 x 1卷积会将这些通道(功能)嵌入到单个通道中。第三个优点是在1 x 1卷积之后,可以添加诸如ReLU的非线性激活。非线性允许网络学习更复杂的功能。
这些优势在Google的Inception论文中描述为:
“上述模块的一个大问题,至少在这种天真的形式中,即使是一个适度数量的5x5卷积,在具有大量滤波器的卷积层之上也会非常昂贵。
这导致了所提出的架构的第二个想法:明智地应用尺寸减小和投影,否则计算要求将增加太多。这是基于嵌入的成功:即使是低维嵌入也可能包含大量关于相对较大图像补丁的信息…也就是说,在昂贵的3 x 3和5 x 5卷积之前,使用1 x 1卷数来计算减少量。除了用作还原之外,它们还包括使用经过整流的线性激活,这使它们具有双重用途。“
关于1 x 1卷积的一个有趣的观点来自Yann LeCun“在卷积网中,没有”完全连接的层“这样的东西。只有1x1卷积内核和完整连接ta的卷积层ble.”

- 5. 卷积算术
我们现在知道如何处理卷积的深度。让我们继续讨论如何处理其他两个方向(高度和宽度)的卷积,以及重要的卷积算法。
以下是一些术语:
内核大小:内核将在上一节中讨论。内核大小定义了卷积的视图。
Stride:它在滑动图像时定义内核的步长。步幅为1意味着内核逐像素地滑过图像。步幅为2表示内核通过每步移动2个像素(即跳过1个像素)滑过图像。我们可以使用步幅(> = 2)对图像进行下采样。
填充:填充定义如何处理图像的边框。填充卷积(Tensorflow中的“相同”填充)将保持空间输出维度等于输入图像,如果需要,通过在输入边界周围填充0。另一方面,未填充卷积(Tensorflow中的“有效”填充)仅对输入图像的像素执行卷积,而不在输入边界周围添加0。输出大小小于输入大小。
下图描述了使用内核大小为3,步幅为1和填充为1的2D卷积。

有一篇关于详细算术的优秀文章(“深度学习的卷积算法指南”)。 可以参考它来获得内核大小,步幅和填充的不同组合的详细描述和示例。 在这里,我只是总结一般案例的结果。
对于大小为i,内核大小为k,p的填充和s的步幅的输入图像,来自卷积的输出图像具有大小o:
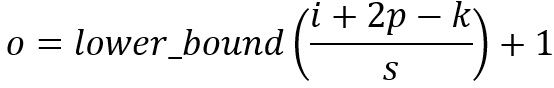
- 6. 转置卷积(反卷积)
对于许多应用程序和许多网络体系结构,我们经常希望进行与正常卷积相反方向的转换,即我们希望执行上采样。一些示例包括生成高分辨率图像并将低维特征映射映射到高维空间,例如自动编码器或语义分段。 (在后面的示例中,语义分割首先在编码器中提取特征图,然后在解码器中恢复原始图像大小,以便它可以对原始图像中的每个像素进行分类。)
传统上,可以通过应用插值方案或手动创建规则来实现上采样。另一方面,诸如神经网络之类的现代架构倾向于让网络本身自动地学习正确的转换,而无需人为干预。为此,我们可以使用转置卷积。
转置卷积在文献中也称为反卷积或分步跨卷积。然而,值得注意的是,“反卷积”这个名称不太合适,因为转置卷积不是信号/图像处理中定义的真实反卷积。从技术上讲,信号处理中的反卷积会逆转卷积运算。这里情况不同。因此,一些作者强烈反对将转置卷积称为反卷积。人们称它为反卷积主要是因为简单。稍后,我们将看到为什么将这种操作称为转置卷积是自然而且更合适的。
始终可以使用直接卷积实现转置卷积。对于下图中的示例,我们使用3 x 3内核在2 x 2输入上应用转置卷积,使用单位步幅填充2 x 2边框。上采样输出的大小为4 x 4。
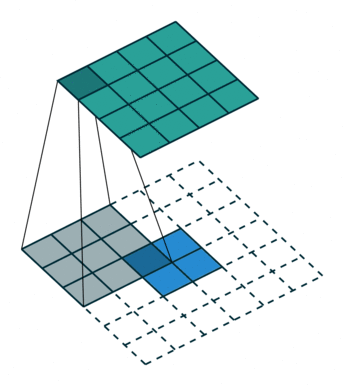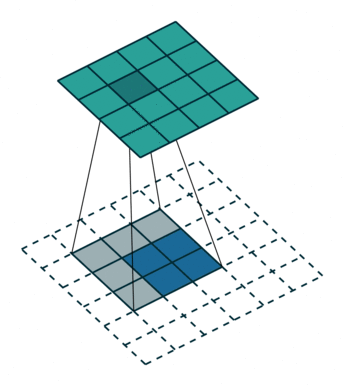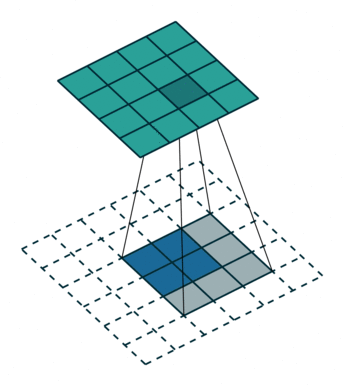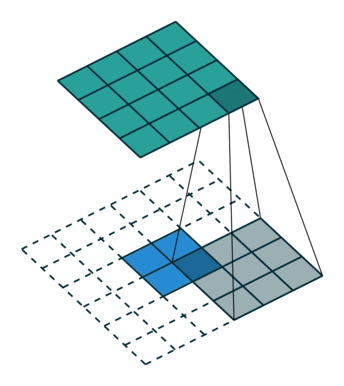
将2 x 2输入上采样到4 x 4输出。
有趣的是,通过应用花式填充和步幅,可以将相同的2 x 2输入图像映射到不同的图像大小。 下面,转置卷积应用于相同的2 x 2输入(在输入之间插入1 0),使用单位步幅填充2 x 2边界的零。 现在输出的大小为5 x 5。
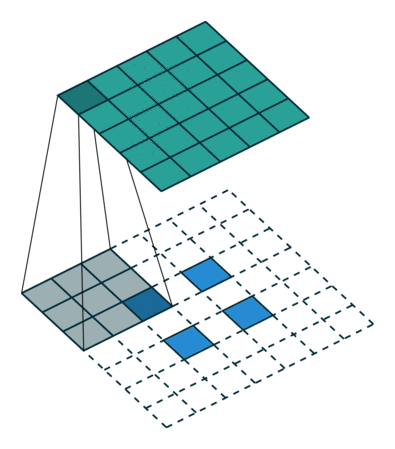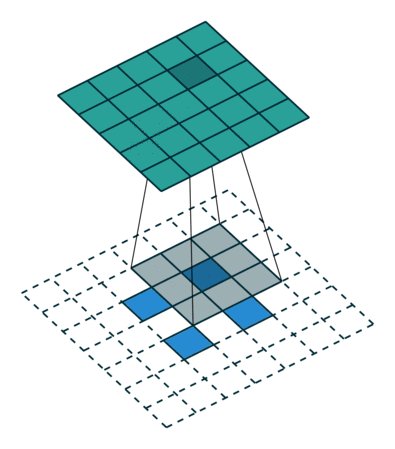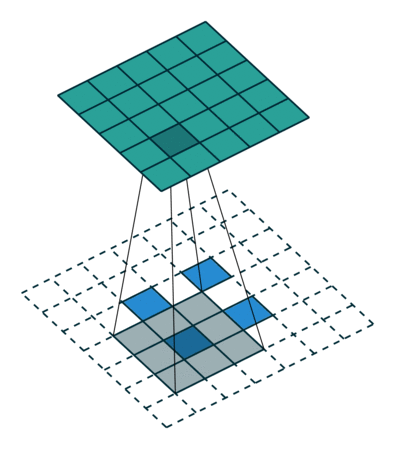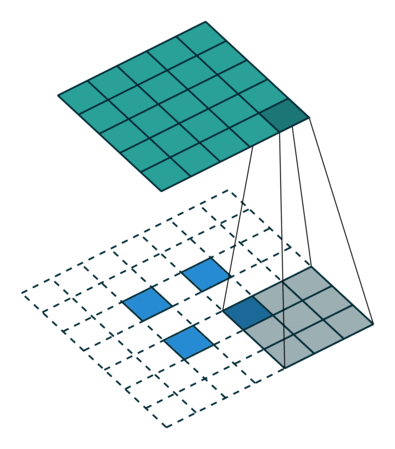
将2 x 2输入上采样到5 x 5输出。
在上面的例子中查看转置卷积可以帮助我们建立一些直觉。 但是为了概括其应用,有必要通过计算机中的矩阵乘法来研究它是如何实现的。 从那里,我们也可以看到为什么“转置卷积”是一个合适的名称。
在卷积中,让我们将C定义为我们的内核,将Large定义为输入图像,将Small定义为来自卷积的输出图像。 在卷积(矩阵乘法)之后,我们将大图像下采样为小输出图像。 矩阵乘法中的卷积的实现遵循C x Large = Small。
以下示例显示了此类操作的工作原理。 它将输入展平为16 x 1矩阵,并将内核转换为稀疏矩阵(4 x 16)。 然后在稀疏矩阵和平坦输入之间应用矩阵乘法。 之后,将得到的矩阵(4×1)转换回2×2输出。

卷积的矩阵乘法:从大输入图像(4 x 4)到小输出图像(2 x 2)。
现在,如果我们在方程的两边多重矩阵CT的转置,并使用矩阵与其转置矩阵的乘法给出单位矩阵的属性,那么我们有以下公式CT x Small = Large,如下所示 下图。
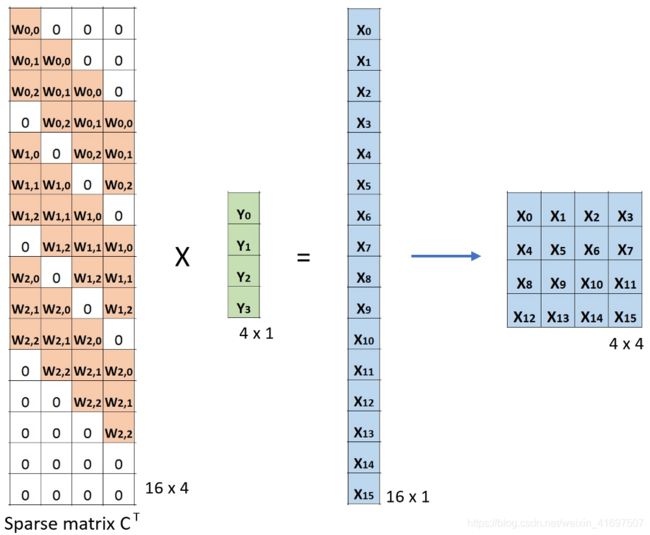
卷积的矩阵乘法:从小输入图像(2 x 2)到大输出图像(4 x 4)。
正如您在此处所看到的,我们执行从小图像到大图像的上采样。 这就是我们想要实现的目标。 现在,您还可以看到“转置卷积”这个名称的来源。
转置卷积的一般算法可以从这篇优秀文章中的关系13和关系14中找到(“深度学习的卷积算法指南”)。
- 6.1. Checkerboard artifacts.
人们在使用转置卷积时观察到的一种令人不快的行为是所谓的棋盘格伪影。
一些棋盘工件的例子。本文采用的是图像。
文章“Deconvolution and Checkerboard Artifacts”对这种行为有很好的描述。有关更多详细信息,请查看此文章。在这里,我只概括几个要点。
棋盘伪影是由转置卷积的“不均匀重叠”引起的。这种重叠使得更多的隐喻性绘画在某些地方比其他地方更多。
在下图中,顶部的图层是输入图层,底部的图层是转置卷积后的输出图层。在转置卷积期间,具有较小尺寸的层被映射到具有较大尺寸的层。
在示例(a)中,步幅为1且滤波器大小为2.如红色所示,输入上的第一个像素映射到输出上的第一个和第二个像素。如绿色所示,输入上的第二个像素映射到输出上的第二个和第三个像素。输出上的第二个像素从输入上的第一个和第二个像素接收信息。总的来说,输出中间部分的像素从输入端接收相同数量的信息。这里存在核心重叠的区域。当在示例(b)中滤波器大小增加到3时,接收最多信息的中心部分收缩。但这可能不是什么大问题,因为重叠仍然是均匀的。输出中心部分的像素从输入接收相同数量的信息。
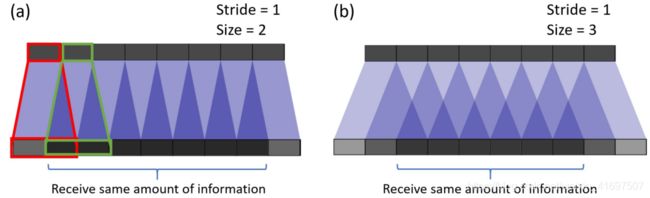
现在,对于下面的示例,我们更改stride = 2.在示例(a)中,滤镜大小= 2,输出上的所有像素都从输入接收相同数量的信息。 它们都从输入上的单个像素接收信息。 这里没有转置卷积的重叠。
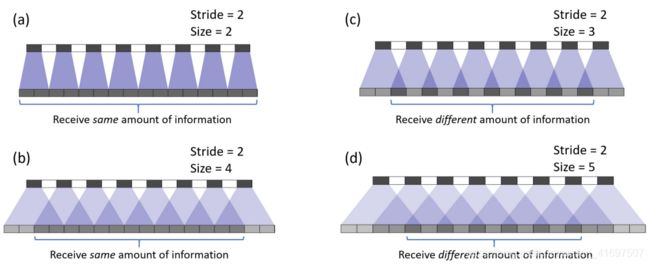
如果我们在示例(b)中将滤镜大小更改为4,则均匀重叠的区域会缩小。但是,仍然可以使用输出的中心部分作为有效输出,其中每个像素从输入接收相同数量的信息。
但是,如果我们在示例(c)和(d)中将过滤器大小更改为3和5,则事情会变得很有趣。对于这两种情况,输出上的每个像素与其相邻像素相比接收不同数量的信息。人们无法在输出上找到连续且均匀重叠的区域。
当滤波器尺寸不能被步幅整除时,转置的卷积具有不均匀的重叠。这种“不均匀的重叠”使得涂料在某些地方比其他地方更多,从而产生棋盘效果。事实上,不均匀重叠的区域在两个维度上往往更加极端。在那里,两个模式相乘,不均匀性变得平方。
在应用转置卷积时,可以做两件事来减少这种伪影。首先,请确保使用由步幅划分的文件管理器大小,以避免重叠问题。其次,可以使用stride = 1的转置卷积,这有助于减少棋盘效果。然而,正如许多最近的模型中所见,工件仍然可以泄漏。
本文进一步提出了一种更好的上采样方法:首先调整图像大小(使用最近邻插值或双线性插值),然后进行卷积层。通过这样做,作者避免了棋盘效应。您可能想要为您的应用程序尝试它。
- 7. 扩张卷积(Atrous Convolution)
扩张卷积在论文(链接)和论文“通过扩张卷积进行多尺度上下文聚合”(链接)中引入。
这是标准的离散卷积:
![]()
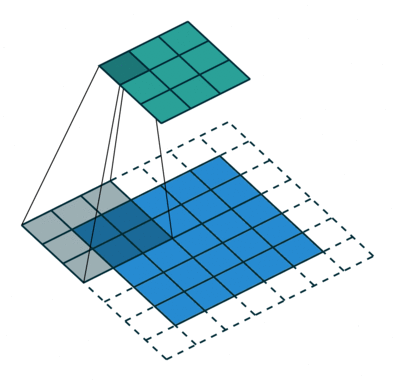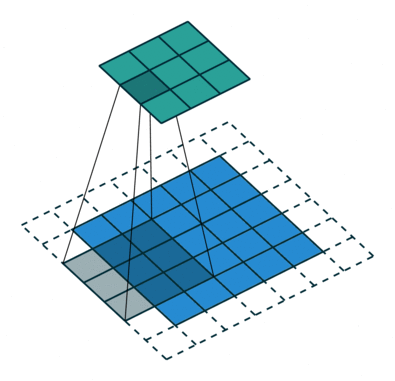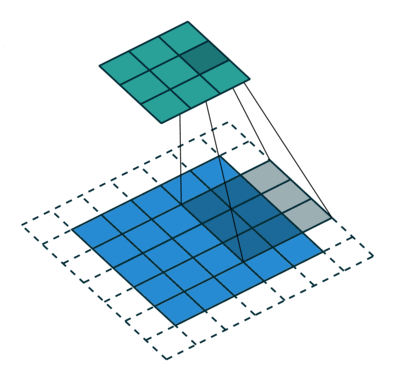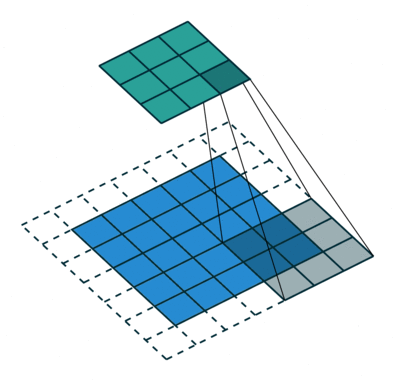
标准卷积。
扩张的卷积如下:
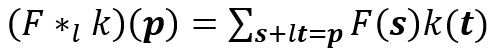
当l = 1时,扩张卷积变为标准卷积。

扩张的卷积。
直观地说,扩张的卷积通过在内核元素之间插入空格来“膨胀”内核。 这个附加参数l(扩张率)表示我们想要扩展内核的程度。 实现可能会有所不同,但内核元素之间通常会插入l-1个空格。 下图显示了l = 1,2和4时的内核大小。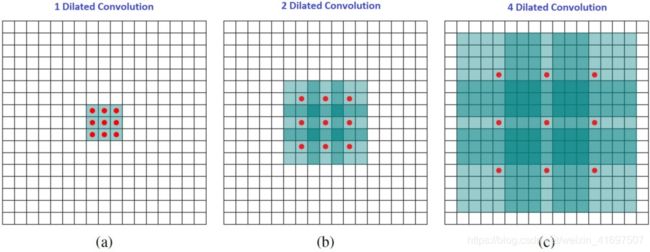
扩张卷积的感受野。我们基本上观察一个大的感受野,而不增加额外的费用。
在图像中,3×3个红点表示在卷积之后,输出图像具有3×3像素。虽然所有三个扩张的卷积都为输出提供了相同的尺寸,但模型观察到的感受野是截然不同的。对于l = 1,接收域为3 x 3。 l = 2时为7 x 7。对于l = 3,接收域增加到15 x 15.有趣的是,与这些操作相关的参数数量基本相同。我们“观察”一个大的接收领域而不增加额外的费用。因此,扩张卷积用于廉价地增加输出单元的接收场而不增加核尺寸,这在多个扩张的卷绕一个接一个地堆叠时尤其有效。
文章“通过扩张卷积进行多尺度上下文聚合”的作者在多层扩张卷积中构建了一个网络,其中扩张率l在每一层呈指数增长。结果,有效的感受野呈指数增长,而参数的数量只与层线性增长!
本文中的扩张卷积用于系统地聚合多尺度上下文信息而不会丢失分辨率。该论文表明,所提出的模块提高了当时最先进的语义分割系统的准确性(2016)。请查看论文以获取更多信息。
- 8. 可分离的卷积
可分离的卷积用于一些神经网络体系结构,例如MobileNet(Link)。 可以在空间上(空间可分离卷积)或深度(深度可分离卷积)执行可分离卷积。
- 8.1. 空间可分离的卷积
空间可分离卷积在图像的2D空间维度上操作,即高度和宽度。 从概念上讲,空间可分离卷积将卷积分解为两个单独的操作。 对于下面显示的示例,Sobel内核(3x3内核)被划分为3x1和1x3内核。

Sobel内核可以分为3 x 1和1 x 3内核。
在卷积中,3x3内核直接与图像卷积。 在空间可分离的卷积中,3x1内核首先与图像卷积。 然后应用1x3内核。 在执行相同操作时,这将需要6个而不是9个参数。
此外,在空间上可分离的卷积中需要比卷积更少的矩阵乘法。 对于一个具体的例子,在具有3×3内核(stride = 1,padding = 0)的5×5图像上的卷积需要在水平3个位置(和垂直3个位置)扫描内核。 总共9个位置,如下图所示。 在每个位置,应用9个元素乘法。 总的来说,这是9 x 9 = 81次乘法。
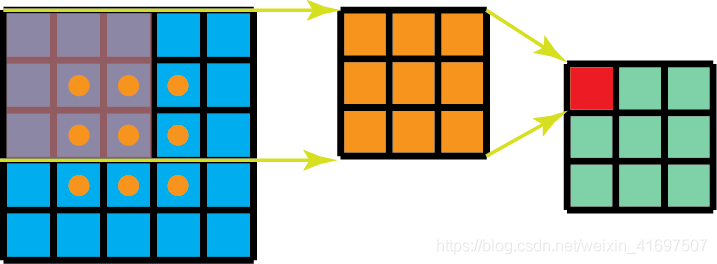
标准卷积,1通道。
另一方面,对于空间可分离卷积,我们首先在5 x 5图像上应用3 x 1滤波器。 我们在水平5个位置和垂直3个位置扫描这样的内核。 总共5 x 3 = 15个位置,如下图所示。 在每个位置,应用3个元素乘法。 那是15 x 3 = 45次乘法。 我们现在获得了3 x 5矩阵。 此矩阵现在与1 x 3内核进行卷积,内核在水平3个位置和垂直3个位置扫描矩阵。 对于这9个位置中的每一个,应用3个元素乘法。 此步骤需要9 x 3 = 27次乘法。 因此,总体而言,空间可分离卷积需要45 + 27 = 72次乘法,这小于卷积。
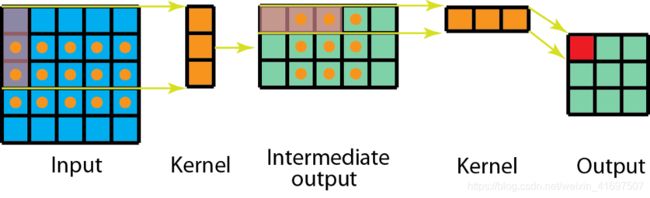
具有1个通道的空间可分离卷积。
让我们稍微概括一下上面的例子。 假设我们现在在具有m×m内核的N×N图像上应用卷积,其中stride = 1且padding = 0。 传统的卷积需要(N-2)×(N-2)×m×m次乘法。 空间可分离卷积需要N×(N-2)×m +(N-2)×(N-2)×m =(2N-2)×(N-2)×m次乘法。 空间可分卷积与标准卷积之间的计算成本比率为

对于图像尺寸N大于滤波器尺寸(N >> m)的层,该比率变为2 / m。 这意味着在这种渐近情况下(N >> m),空间可分卷积的计算成本是3×3滤波器的标准卷积的2/3。 5 x 5过滤器为2/5,7 x 7过滤器为2/7,依此类推。
虽然空间可分离的卷积可以节省成本,但很少用于深度学习。 其中一个主要原因是并非所有内核都可以分为两个较小的内核。 如果我们通过空间可分的卷积替换所有传统的卷积,我们限制自己在训练期间搜索所有可能的核。 训练结果可能不是最佳的。
- 8.2. 深度可分的卷积
现在,让我们继续深度可分离卷积,这在深度学习中更常用(例如在MobileNet和Xception中)。 深度可分离的旋转包括两个步骤:深度卷积和1x1卷积。
在描述这些步骤之前,值得重新审视我之前部分中讨论的2D卷积和1 x 1卷积。 让我们快速回顾一下标准2D卷积。 举一个具体的例子,假设输入层的大小为7 x 7 x 3(高x宽x通道),滤波器的大小为3 x 3 x 3.使用一个滤波器进行2D卷积后,输出层为 尺寸为5 x 5 x 1(仅有1个通道)。
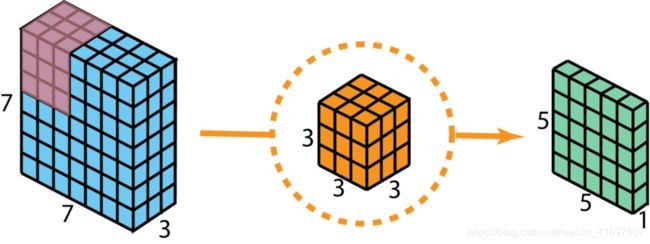
标准2D卷积,使用1个滤波器创建1层输出。
通常,在两个神经网络层之间应用多个滤波器。 假设我们这里有128个过滤器。 在应用这128个2D卷积后,我们有128个5 x 5 x 1输出映射。 然后我们将这些地图堆叠成一个大小为5 x 5 x 128的单层。通过这样做,我们将输入层(7 x 7 x 3)转换为输出层(5 x 5 x 128)。 空间尺寸,即高度和宽度,收缩,同时深度延伸。
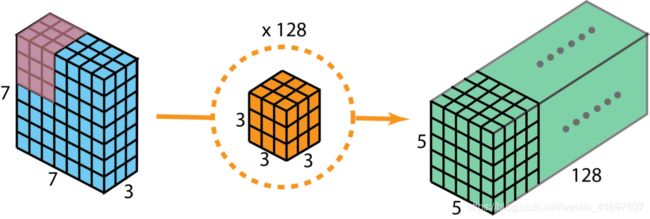
标准2D卷积,使用128个滤波器创建128层输出。
现在有了深度可分离的卷积,让我们看看我们如何实现相同的转换。
首先,我们将深度卷积应用于输入层。 我们不是在2D卷积中使用尺寸为3 x 3 x 3的单个滤波器,而是分别使用3个内核。 每个滤波器的大小为3 x 3 x 1.每个内核与输入层的1个通道进行卷积(仅1个通道,而不是所有通道!)。 每个这样的卷积提供尺寸为5×5×1的图。然后我们将这些图堆叠在一起以创建5×5×3图像。 在此之后,我们的输出尺寸为5 x 5 x 3.我们现在缩小空间尺寸,但深度仍然与以前相同。
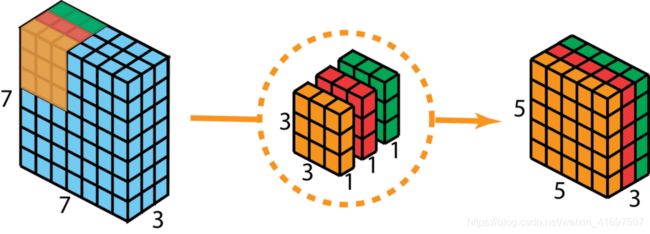
深度可分卷积 - 第一步:我们分别使用3个内核,而不是在2D卷积中使用大小为3 x 3 x 3的单个滤波器。 每个滤波器的大小为3 x 3 x 1.每个内核与输入层的1个通道进行卷积(仅1个通道,而不是所有通道!)。 每个这样的卷积提供尺寸为5×5×1的图。然后我们将这些图堆叠在一起以创建5×5×3图像。 在此之后,我们的输出尺寸为5 x 5 x 3。
作为深度可分离卷积的第二步,为了扩展深度,我们应用1x1卷积,内核大小为1x1x3。 将5 x 5 x 3输入图像与每个1 x 1 x 3内核进行对比,可提供大小为5 x 5 x 1的映射。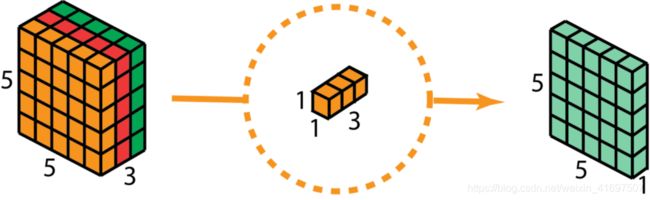
因此,在应用128个1x1卷积后,我们可以得到一个尺寸为5 x 5 x 128的层。
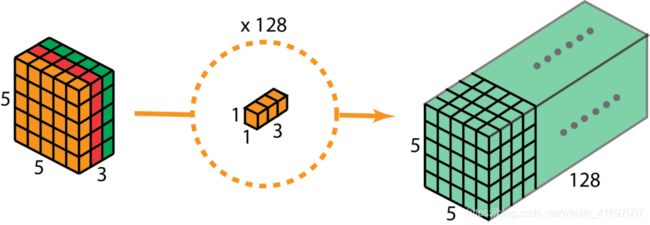
深度可分卷积 - 第二步:应用多个1 x 1卷积来修改深度。
通过这两个步骤,深度可分离卷积还将输入层(7 x 7 x 3)转换为输出层(5 x 5 x 128)。
深度可分离卷积的整个过程如下图所示。
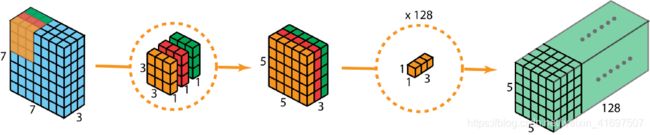
深度可分卷积的整个过程。
那么,深度可分离卷积的优势是什么?效率!与2D卷积相比,对于深度可分离卷积,需要更少的操作。
让我们回顾一下2D卷积示例的计算成本。有128个3x3x3内核移动5x5次。这是128 x 3 x 3 x 3 x 5 x 5 = 86,400次乘法。
可分离的卷积怎么样?在第一个深度卷积步骤中,有3个3x3x1内核移动5x5次。那是3x3x3x1x5x5 = 675次乘法。在1 x 1卷积的第二步中,有128个1x1x3内核移动5x5次。这是128 x 1 x 1 x 3 x 5 x 5 = 9,600次乘法。因此,总体而言,深度可分离卷积需要675 + 9600 = 10,275次乘法。这只是2D卷积成本的12%左右!
因此,对于具有任意大小的图像,如果我们应用深度可分离卷积,我们可以节省多少时间。让我们稍微概括一下上面的例子。现在,对于大小为H x W x D的输入图像,我们想要使用大小为h x h x D的Nc内核进行2D卷积(stride = 1,padding = 0),其中h是偶数。这将输入层(H x W x D)变换为输出层(H-h + 1×W-h + 1×Nc)。所需的总体乘法是
Nc x h x h x D x(H-h + 1)x(W-h + 1)
另一方面,对于相同的变换,深度可分离卷积所需的乘法是
D xhxhx 1 x(H-h + 1)x(W-h + 1)+ Nc x 1 x 1 x D x(H-h + 1)x(W-h + 1)=(hxh + Nc)x D x(H-h + 1)x(W-h + 1)
深度可分卷积与2D卷积之间的乘法比率现在为:
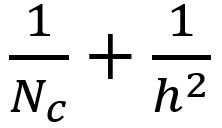
对于大多数现代架构,输出层通常具有许多通道,例如, 几百甚至几千。 对于这样的层(Nc >> h),则上述表达式降低至1 / h / h。 这意味着对于这种渐近表达式,如果使用3 x 3滤波器,则2D卷积的乘法比深度可分离卷积多9倍。 对于5 x 5滤波器,2D卷积的乘法次数增加了25倍。
使用深度可分离卷积有任何缺点吗? 当然有。 深度可分离卷积减少了卷积中的参数数量。 因此,对于小型模型,如果2D卷积被深度可分离卷积替换,则模型容量可以显着降低。 结果,该模型可能变得次优。 但是,如果使用得当,深度可分离卷绕可以在不显着损害模型性能的情况下提供效率。
- 9. 扁平化的卷积
扁平卷积在文章“Flattened convolutional neural networks for feedforward acceleration”中介绍。 直观地说,这个想法是应用过滤器分离。 我们将这个标准滤波器分成3个1D滤波器,而不是应用一个标准卷积滤波器将输入层映射到输出层。 这种想法与上述空间可分卷积中的类似,其中空间滤波器由两个秩-1滤波器近似。
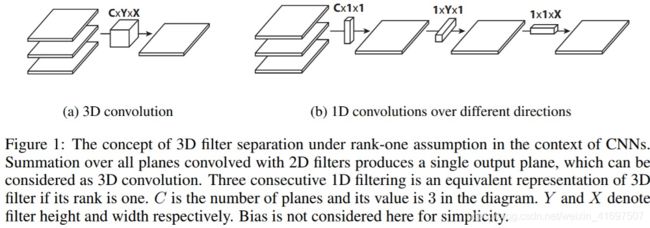
应该注意的是,如果标准卷积滤波器是秩1滤波器,则这种滤波器总是可以分成三个1D滤波器的交叉积。但这是一个强大的条件,标准滤波器的内在等级高于实际中的一个。正如文章中指出的那样“随着分类问题的难度增加,解决问题需要更多的主要组件…深度网络中的学习过滤器具有分布的特征值,并且直接将分离应用于过滤器导致显着的信息丢失。 ”
为了缓解这种问题,本文限制了接收领域的连接,以便模型可以在训练时学习一维分离的过滤器。该论文声称,通过在3D空间中跨越所有方向的连续1D滤波器序列组成的扁平网络训练提供与标准卷积网络相当的性能,由于学习参数的显着减少,计算成本更低。
- 10. 分组卷积
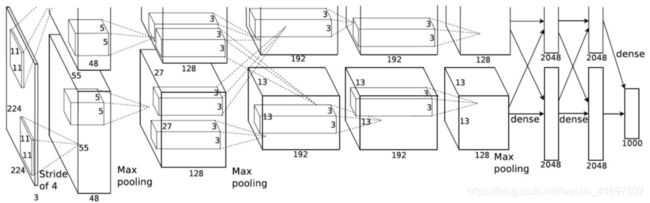
2012年,在AlexNet论文(链接)中引入了分组卷积。实现它的主要原因是允许通过两个具有有限内存(每个GPU 1.5 GB内存)的GPU进行网络训练。 下面的AlexNet在大多数层上显示了两个独立的卷积路径。 它正在跨两个GPU进行模型并行化(当然,如果有更多的GPU,可以进行多GPU并行化)。
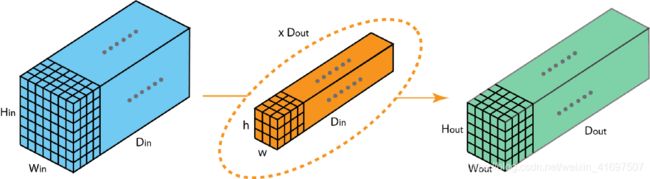
在这里,我们描述了分组卷积如何工作。 首先,传统的2D卷积遵循以下步骤。 在此示例中,通过应用128个滤波器(每个滤波器的大小为3 x 3 x 3),将大小为(7 x 7 x 3)的输入层转换为大小为(5 x 5 x 128)的输出层。 或者在一般情况下,通过应用Dout内核(每个大小为h x w x Din)将大小(Hin x Win x Din)的输入层变换为大小(Hout x Wout x Dout)的输出层。
在分组卷积中,过滤器被分成不同的组。 每组负责具有一定深度的传统2D卷积。 以下示例可以使此更清楚。
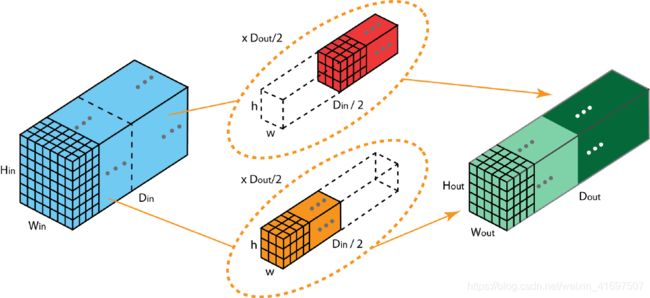
以上是具有2个滤波器组的分组卷积的说明。 在每个滤波器组中,每个滤波器的深度仅为标称2D卷积的深度的一半。 它们具有深度Din / 2.每个滤波器组包含Dout / 2滤波器。 第一个滤波器组(红色)与输入层的前半部分([:,:0:Din / 2])卷积,而第二个滤波器组(蓝色)与输入层的后半部分卷积([: ,:,Din / 2:Din])。 因此,每个过滤器组都会创建Dout / 2通道。 总的来说,两组创建2 x Dout / 2 = Dout频道。 然后,我们使用Dout通道将这些通道堆叠在输出层中。
- 10.1. 分组卷积vs.s. 深度卷积
您可能已经观察到分组卷积与深度可分卷积中使用的深度卷积之间的一些联系和差异。如果滤波器组的数量与输入层通道相同,则每个滤波器的深度为Din / Din = 1.这与深度卷积中的滤波器深度相同。
另一方面,每个过滤器组现在包含Dout / Din过滤器。总的来说,输出层的深度为Dout。这与深度卷积不同,深度卷积不会改变层深度。在深度可分离卷积中,层深度稍后延伸1x1卷积。
进行分组卷积有一些优点。
第一个优势是有效的培训。由于卷积被分成几个路径,因此每个路径可以由不同的GPU分开处理。此过程允许以并行方式对多个GPU进行模型训练。与使用一个GPU训练所有内容相比,多GPU上的这种模型并行化允许每步将更多图像馈送到网络中。模型并行化被认为比数据并行化更好。后者将数据集分成批次,然后我们在每批次上进行训练。然而,当批量大小变得太小时,我们基本上做的是随机性而不是批量梯度下降。这将导致较慢且有时较差的收敛。
分组卷积对于训练非常深的神经网络非常重要,如下面所示的ResNeXt
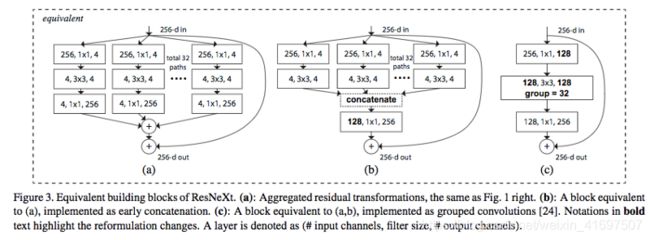
第二个优点是模型更有效,即模型参数随着滤波器组数量的增加而减少。 在前面的示例中,滤波器在标称2D卷积中具有h x w x Din x Dout参数。 具有2个滤波器组的分组卷积中的滤波器具有(h×w×Din / 2×Dout / 2)×2个参数。 参数数量减少一半。
第三个优点有点令人惊讶。 分组卷积可以提供比标称2D卷积更好的模型。 另一个很棒的博客(链接)解释了它。 这是一个简短的总结。
原因链接到稀疏过滤器关系。 下图是相邻层的滤镜之间的相关性。 这种关系很稀疏。
在CIFAR10上训练的网络中网络模型中相邻层的滤波器之间的相关矩阵。 成对的高度相关滤波器更亮,而低相关滤波器更暗。 本文采用的是图像。
分组卷积的相关图怎么样?
当使用1,2,4,8和16个过滤器组训练时,在CIFAR10上训练的网络中网络模型中相邻层的过滤器之间的相关性。
上图是当使用1,2,4,8和16个滤波器组训练模型时相邻层的滤波器之间的相关性。 文章提出了一个推理(链接):“过滤器组的效果是学习通道维度上的块对角结构稀疏性…具有高相关性的过滤器在具有过滤器组的网络中以更结构化的方式学习。 实际上,不需要学习的过滤器关系在较长时间参数化。 在以这种显着方式减少网络中的参数数量时,过度拟合并不容易,因此类似正则化的效应允许优化器学习更准确,更有效的深度网络。“

AlexNet conv1过滤器分离:正如作者所指出的,过滤器组似乎将学习过滤器组织成两个不同的组,黑白和彩色滤镜。 该图像来自AlexNet论文。
此外,每个过滤器组都学习数据的唯一表示。 正如AlexNet的作者所注意到的,过滤器组似乎将学习过滤器组织成两个不同的组,黑白滤镜和彩色滤镜。
- 11. 混合分组卷积
在来自Magvii Inc(Face ++)的ShuffleNet中引入了混洗分组卷积。 ShuffleNet是一种计算有效的卷积架构,专为具有非常有限的计算能力(例如10-150 MFLOP)的移动设备而设计。
改组分组卷积背后的思想与分组卷积背后的思想(在MobileNet和ResNeXt中用于示例)和深度可分离卷积(在Xception中使用)相关联。
总的来说,混洗分组卷积涉及分组卷积和信道混洗。
在关于分组卷积的部分中,我们知道过滤器被分成不同的组。每组负责具有一定深度的传统2D卷积。总运营量大幅减少。对于下图中的示例,我们有3个过滤器组。第一个过滤器组与输入层中的红色部分进行卷积。类似地,第二和第三滤波器组与输入中的绿色和蓝色部分卷积。每个过滤器组中的内核深度仅为输入层中总通道数的1/3。在该示例中,在第一组分组卷积GConv1之后,输入层被映射到中间特征映射。然后通过第二组分卷积GConv2将该特征映射映射到输出层。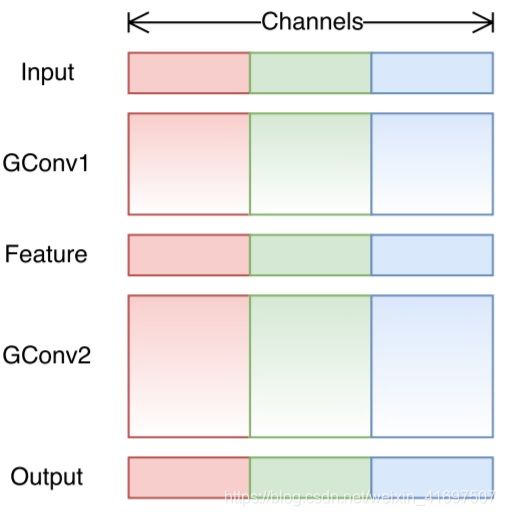
分组卷积在计算上是有效的。但问题是每个过滤器组仅处理从先前层中的固定部分向下传递的信息。对于上图中的示例,第一个滤波器组(红色)仅处理从前1/3输入通道传递的信息。蓝色过滤器组(蓝色)仅处理从最后1/3的输入通道传递下来的信息。因此,每个过滤器组仅限于学习一些特定功能。此属性会阻止通道组之间的信息流,并在训练期间削弱表示。为了解决这个问题,我们应用了频道shuffle。
频道改组的想法是我们想要混合来自不同过滤器组的信息。在下图中,我们在应用具有3个滤波器组的第一组分组卷积GConv1后得到特征图。在将此特征映射馈送到第二个分组卷积之前,我们首先将每个组中的通道划分为多个子组。我们混淆了这些小组。
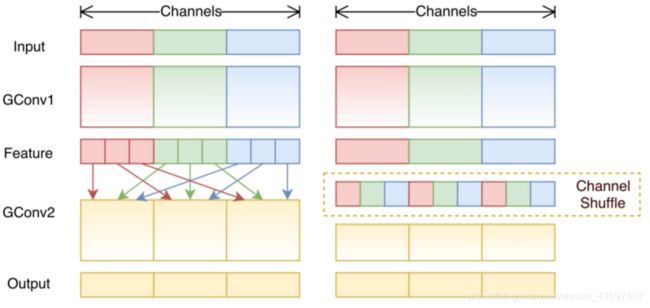
频道随机播放。
在这样的改组之后,我们像往常一样继续执行第二组分组卷积GConv2。 但是现在,由于混洗层中的信息已经混合,我们实质上为GConv2中的每个组提供了特征映射层(或输入层)中的不同子组。 因此,我们允许渠道组之间的信息流动并加强表示。
- 12. 逐点分组卷积
ShuffleNet论文(链接)还介绍了逐点分组卷积。通常,对于分组卷积,例如在MobileNet(链接)或ResNeXt(链接)中,组操作在3x3空间卷积上执行,但不在1 x 1卷积上执行。
shuffleNet论文认为,1 x 1卷积的计算成本也很高。它建议将组卷积应用于1 x 1卷积。正如名称所示,逐点分组卷积执行1 x 1卷积的组操作。该操作与分组卷积相同,只有一个修改 - 在1x1滤波器而不是NxN滤波器(N> 1)上执行。
在ShuffleNet论文中,作者使用了我们学到的三种类型的卷积:(1)混洗分组卷积; (2)逐点分组卷积; (3)深度可分离卷积。这种架构设计显着降低了计算成本,同时保持了准确性。例如,ShuffleNet和AlexNet的分类错误在实际移动设备上具有可比性。然而,计算成本已经从AlexNet的720 MFLOP大幅降低到ShuffleNet的40-140 MFLOP。由于计算成本相对较小且模型性能良好,ShuffleNet在移动设备的卷积神经网络领域获得了普及。
感谢您阅读本文。请随时在下面留下问题和评论。
- Reference
Blogs & articles
oduction to different Types of Convolutions in Deep Learning” (Link)
“Review: DilatedNet — Dilated Convolution (Semantic Segmentation)” (Link)
“ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices” (Link)
“Separable convolutions “A Basic Introduction to Separable Convolutions” (Link)
Inception network “A Simple Guide to the Versions of the Inception Network” (Link)
“A Tutorial on Filter Groups (Grouped Convolution)” (Link)
“Convolution arithmetic animation” (Link)
“Up-sampling with Transposed Convolution” (Link)
“Intuitively Understanding Convolutions for Deep Learning” (Link)
Papers
Network in Network (Link)
Multi-Scale Context Aggregation by Dilated Convolutions (Link)
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs (Link)
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (Link)
A guide to convolution arithmetic for deep learning (Link)
Going deeper with convolutions (Link)
Rethinking the Inception Architecture for Computer Vision (Link)
Flattened convolutional neural networks for feedforward acceleration (Link)
Xception: Deep Learning with Depthwise Separable Convolutions (Link)
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (Link)
Deconvolution and Checkerboard Artifacts (Link)
ResNeXt: Aggregated Residual Transformations for Deep Neural Networks (Link)