探索多层次内存系统的页面管理设计空间Exploring the Design Space of Page Management for Multi-Tiered Memory Systems
文章目录
- 前言
- Abstract摘要
- 1 Introduction简介
- 2 Background and Motivation背景和动机
-
- 2.1 Large Memory Systems大型内存系统
- 2.2 Performance Characteristics性能特点
- 2.3 OS Support of Multi-Tiered Memory操作系统对多层次内存的支持
- 3 Analysis of Page Management to Multi-Tiered Memory Systems对多层次内存系统的页面管理分析
-
- 3.1 Initial Page Placement最初的页面放置
- 3.2 Dynamic Placement动态放置
- 3.3 Page Reclamation页回收
- 4 Automatic Multi-Tiered Memory自动多层内存
-
- 4.1 Exploiting Multi-Tiered Memory多层次内存开发
- 4.2 Opportunistic Promotion and Migration机会性的升级和迁移
-
- 4.2.1 Predicting the Least Accessed Page预测访问量最少的页面
- 4.3 Hiding Latency of Page Demotion隐藏页面降级的延时
- 5 Evaluation评估
-
- 5.1 Experimental Setup实验设置
- 5.2 Experimental Results实验结果
- 6 相关工作
- 7 Conclusion 总结
- 总结
前言
初步翻译了一遍,可能还存在一些问题,需要对照原文理解
AutoNUMA用于平衡Numa节点间的内存访问,基本思想是:定期统计各进程的内存访问情况, 并unmapping pages,然后触发NUMA hinting fault,在page fault中重新均衡内存访问,目的是使运行 进程的CPU尽量访问本地节点上的内存,提升性能。
Abstract摘要
随着由各种类型的内存组成的分层内存系统的到来,如DRAM和SCM,操作系统对内存管理的支持正变得越来越重要。然而,目前操作系统管理页面的方式是在假设所有的内存都具有基于DRAM的相同能力的情况下设计的。这种过度简化的做法导致了分层内存系统中非最佳的内存被使用。本研究深入地分析了在目前的Linux设计中页面管理方案,将NUMA扩展到支持同时配备DRAM和SCM的系统(英特尔的DCPMM)。在这样的多层内存系统中,我们发现影响性能的关键因素不仅是访问位置,而且还有内存的访问层。当考虑到这两个特性时,有几种替代页放置的方法。然而,目前的运行系统只优先考虑了访问位置。本文探讨了页面管理方案的设计空间, 称为AutoTiering,以有效使用多层内存系统。我们的评估结果表明,与现有的Linux内核相比,我们提出的技术可以通过释放多层内存层次结构的潜力,显著提高各种工作负载的性能。
1 Introduction简介
随着内存计算的出现,如数据分析、键值存储和图形处理,对高密度DRAM的需求在最近几年一直在稳步增长[27]。然而,由于扩大DRAM密度的挑战,一种新的内存类别已经受到关注,以弥补DRAM和SSD之间的性能差距。例如,英特尔最近发布了其基于3DXpoint技术的非易失性存储器,称为Optane DC Persistent Memory Module (DCPMM),它提供了比DRAM更高的密度,同时性能超过了基于闪存的SSD[23]。谷歌、甲骨文、微软和百度等云厂商已经在其云服务中采用了这种存储类内存(SCM) [4, 14, 17,25]。
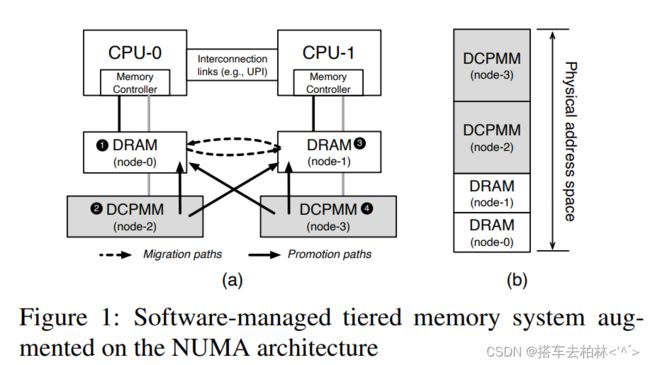
由于现代服务器系统是用非统一内存访问( NUMA)架构构建的,未来的大内存系统将采用传统NUMA架构上的分层内存的形式,称为多层内存。图1展示了本研究中使用的一个真实世界的多层内存系统。每个计算芯片有两种类型的内存:DRAM (上层)和英特尔的DCPMM (下层)。我们将DRAM和DCPMM配置为完全暴露给软件的内存。
本文提出,最近在Linux[15]和分层内存研究[16,20,35]中的进展并没有导致多层内存系统中的最佳页面放置。随着新的内存类别成为主内存的一部分,影响性能的关键因素不仅是访问位置,而且是内存的访问层。然而,目前的页面放置方案是为纯DRAM的NUMA架构建立的,只考虑线程和内存之间的位置[2,8,12,13,21,38]。因此,目前的设计远远没有发挥出多层内存系统的潜在优势。例如,假设从低层(DCPMM)向高层(DRAM)内存升级页面时,本地DRAM变得满了。在这种情况下,目前的技术状况是将页面留在下层内存上,而不管远程DRAM (上层的)是否可用。对于纯DRAM的NUMA系统来说,这样的决定是合理的, 因为替代方案之间没有区别。然而,在多层内存系统中我们不能考虑与访问层相当的所有可能的选择。在放置页面时,应该先考虑内存的访问层,再考虑访问位置,因为访问层对性能有更大的影响。
这个限制促使我们重新审视商用操作系统的页面管理方案,并探索多层内存系统的页面管理的设计空间。在这项研究中,我们引入了一组新的页面管理方案。我们的第一个方案,称为AutoTiering-CPM,在找不到最佳内存节点(如本地DRAM)时,使用访问层和定位度量(locality metric)保守地寻找升级或迁移的替代方案。
虽然这种保守的方法可以通过考虑替代方案来实现更好的性能,但这样的设计并没有释放出软件管理的分层内存的全部潜力。为了有效地利用上层内存的有限容量我们设计了一个为多层内存系统量身定做的页面回收方案。我们的第二项技术是有机会的页面提升或迁移,称为AutoTiering-OPM,它可以明智地将页面从上层内存中剔除。为了有效地回收,我们通过估计页面的访问频率来预测上层内存中访问次数最少的页面作为受害者。当决定提升哪一页时,我们的OPM将该页与受害者进行比较,以确定哪一页的访问量相对较大。通过OPM,我们可以在减少对低层内存的访问的同时,实现上层内存的更好的有效性。
除非上层内存中有空闲空间,否则升级操作要等到降级操作完成后才进行。为了从关键路径上隐藏降级页的延迟,我们在上层内存中保留了一组空闲页,以便立即满足升级请求。当保留页的数量超过阈值时,我们的kdemoted会唤醒并在后台将访问量最小的页面回收到空闲页池中。kdemoted与传统的回收方式不同, 因为它只负责将页面降级到下层内存而不是存储。
在这项研究中, 我们在Linux内核v5.3的基础上实现了我们提出的方案。我们利用AutoNUMA设施,它定期扫描内存页面并标记为不可访问,以捕获非本地DRAM访问。一旦这些页面被重新访问,它就会产生一个缺页,称为NUMA暗示缺页。我们把NUMA缺页作为来自DCPMM节点的页面升级或来自远程DRAM节点的迁移的需求信号。我们用基于故障的设施建立每个页面的访问历史,并在降级页面时使用这些信息。
实验结果表明,我们的AutoTiering可以显著提高各种应用的性能。与基线Linux内核[15]相比,GraphMat和graph500的性能分别提高了2.3倍和6.9倍左右。大多数SPECAccel工作负载显示出2倍的速度提升。与英特尔最近的方法[36]相比,我们的性能改进显示出高达3.5倍的速度提升。
2 Background and Motivation背景和动机
2.1 Large Memory Systems大型内存系统
数据中心通常采用多芯片NUMA架构来提高具有高内核数和内存容量的商用服务器的性能。虽然这可以增加每台服务器的DIMM插槽的数量,但扩展DRAM密度仍然是一个重大障碍。它对经济有效地构建大型内存系统提出了挑战。同时,由于SCM提供了字节寻址和非易失性的特性,它在弥合DRAM和SSD之间的性能差距方面正获得越来越多的关注。英特尔最近发布了3DXPoint非易失性内存(DCPMM) ,可以不经修改安装在DIMM上[23]。许多云计算供应商,如谷歌、微软、甲骨文和百度已经在其云计算服务中采用了英特尔的DCPMM[4,14,17,25]。最近,三星公司透露了一种基于CXL (Compute Express Link)的DRAM模块连接到系统中,形成分层的内存系统[1]。由于这种新型内存的速度不如DRAM,它们不能完全取代DRAM。相反,未来的计算机系统将提供一种带有DRAM和SCM的分层内存架构形式。
在这项研究中,我们利用DCPMM作为DRAM和SSD之间的一个新层级。英特尔DCPMM提供了两种类型的分层内存系统,可分为硬件辅助型和软件管理型。在硬件辅助模式下,DCPMM作为主内存暴露给软件而DRAM作为硬件管理的缓存,对软件来说是不可见的。内存控制器自动地将经常访问的数据放在DRAM缓存中,而其余的数据则保存在容量大但速度慢的DCPMM上。另一方面,在操作系统的支持下,DRAM和DCPMM都可以作为正常的内存暴露出来,对软件可见,将内存分为快慢两类[15]。我们把这称为软件管理的分层内存系统。在这种环境下,操作系统的支持可以有效地使用DRAM和DCPMM,因为完全由软件来控制。本文通过了解硬件的组织方式,重点讨论分层内存系统的系统软件方面。
2.2 Performance Characteristics性能特点
我们描述了一个与Linux操作系统一起运行的 、由软件管理的分层内存系统的明显性能特征。图1展示了本研究中使用的系统结构。该系统有两个CPU插座。对于每个CPU插座,都有一个DRAM节点和一个DCPMM节点整个物理地址空间是由DRAM和DCPMM节点组成的。

在多层内存系统中,影响性能的关键因素不仅是访问位置,而且还有内存的访问层数。图2a 显示了从MLC[18]测得的四个内存节点中每个节点的读访问延迟和带宽。访问本地DRAM的性能优于其他三个内存节点,这在传统的NUMA架构中是公认的。另一方面 ,我们观察到由于设备的特性,本地DCPMM (I-DCPMM)比远程DRAM (R-DRAM)要慢。这与本地内存总是比远程内存快的传统观点形成了鲜明的对比。请注意,我们在带宽测量中也观察到类似的模式。
同样,图2b显示了对四个CPU (Intel Xeon Gold 6242)插座和只使用DRAM的系统进行的同类型评估。在访问任何远程DRAM节点的延迟和带宽方面没有明显的差异。因此,在纯DRAM系统中,在远程DRAM节点上放置页面是一个相对简单的任务。
这些明显的特征促使我们去探索操作系统中页面管理的设计空间。操作系统需要有能力通过了解多层内存系统的性能特征来有效地、动态地(重新)定位内存。与纯DRAM系统不同,由于访问层的原因, 不是所有的远程内存节点都可以被认为是平等的。
2.3 OS Support of Multi-Tiered Memory操作系统对多层次内存的支持
本文所关注的多层内存层次结构与传统的两层内存不同。尽管如此,目前的Linux仍然依赖于现有的NUMA框架来支持多层内存系统。这种有限的操作系统支持使得页面放置在多层内存架构中成为次优的。尽管我们可以根据访问延迟重新定义NUMA距离表,但它并没有充分挖掘出多层内存系统的潜力。首先,Linux以二进制的方式将内存节点分类为本地或远程。当升级或迁移页面时,完全不考虑远程节点之间的几种选择。其次,Linux不支持从上层内存向下层内存迁移(或回收)页面。在这项研究中,我们通过考虑跨访问层以及访问位置的性能特征,重新审视了页面放置策略。
3 Analysis of Page Management to Multi-Tiered Memory Systems对多层次内存系统的页面管理分析
在这一节中,我们研究了现有的Linux页面管理技术,这些技术是为纯DRAM的NUMA系统设计的。然后,我们发现对于分层内存系统缺乏足够的支持。尽管AutoNUMA[33]可以用于这种多层内存,但我们观察到它未能充分利用多层内存的优势。
3.1 Initial Page Placement最初的页面放置
随着存储类内存(如Optane DCPMM)在主内存中的引入,传统的仅基于访问位置的页面放置对性能产生了负面影响, 因为性能的最关键因素不仅是位置,而且还有内存层。同时,目前操作系统中的页面放置方案已经在基于DRAM的NUMA架构中得到了很好的确立,只考虑线程和内存之间的访问位置[8,13,21]。在Linux中, 默认的页面分配策略试图尽可能地使用本地内存,以减少访问远程内存所带来的性能损失。只有在本地内存没有空闲空间的情况下,内存分配器才会在被称为fallback路径的远程内存节点上寻找空闲空间[9]。
因此,在多层内存系统中,默认的(本地优先)分配策略被认为是有害的。图1a中的数字介绍了当线程在CPU-0上运行时,仅考虑物理距离,默认回落路径中使用的顺序。如果本地DRAM节点没有足够的空闲空间,内存分配器就会检查回退路径,以确定分配请求应该被发送到哪个内存节点我们预计分配器应该要求远程DRAM节点获得一个空闲页,因为这个节点比本地DCPMM节点提供更好的性能。然而,令人惊讶的是,最先进的Linux内核中的fallback路径显示了本地DCPMM (低层)。它没有考虑到一个明显的特点,即在多层内存系统中,内存类型对性能比访问位置更敏感。
Problem: If the local DRAM is full, the fallback prioritizes allocating from the local DCPMM (lower-tier), even though the remote DRAM (upper-tier) performs better.
3.2 Dynamic Placement动态放置
尽管最初的页面放置在给定的内存空间中起着至关重要的作用,但这个决定可能不代表最佳性能, 因为它取决于运行时的内存访问流量。为了根据访问模式调整页面的位置,AutoNUMA 设施已被纳入Linux的一部分,自动将页面迁移到在运行时离运行的线程更近的内存节点[33]。操作系统检查访问位置以发现被访问的页面是放在本地内存还是远程内存上。如果是在远程内存上,该页就会被迁移到本地内存上,以避免次要请求的远程访问。这种方法提高了运行在纯DRAM的NUMA系统上的应用程序的性能。
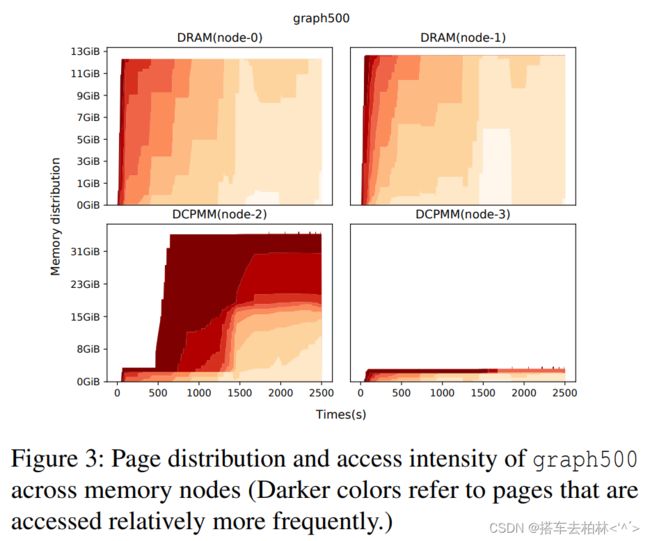
然而,我们发现,目前的设计并没有利用多层内存层次的优势。图3显示了随着时间的推移,Graph500的内存节点对128GB数据集的内存使用率。第5节对实验设置进行了细节解释。首先,我们注意到上层内存没有得到有效利用,因为更频繁访问的页面(深红色)主要驻留在下层内存(节点2)。相比之下,访问频率较低的页面被放置在上层内存中。其主要原因是,当前的内存管理不允许在没有空闲空间的情况下将页面升级或迁移到上层内存。尽管这样的设计决定对于纯DRAM系统来说是合理的,但是对于多层内存系统,我们需要重新考虑这个假设。图4描述了三种情况,即AutoNUMA由于本地DRAM缺乏空闲空间而导致页面升级或迁移失败。
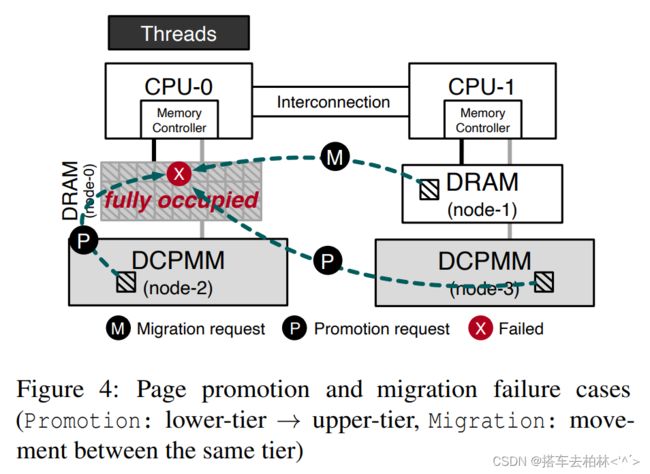
即使不能将页面升级或迁移到满足访问层和访问位置的最佳内存节点上,在多层内存系统中也有有效的替代放置方法。例如,当从远程DCPMM到本地DRAM的页面升级失败时, 我们有两种可能的解决方法:将页面放在远程DRAM上或本地DCPMM上。
Problem: Pages in the lower-tier are not promoted whenthe upper-tier is fully utilized
第二,我们观察到在低层内存的内存节点上,页的分布是倾斜的。这是因为在目前的Linux操作系统中没有考虑到向CPU-less节点(DCPMM)的页面移动。因为传统的操作系统是在假设内存访问性能受CPU和内存节点之间的访问定位影响很大的情况下设计的,所以将页面移动到CPU-less节点的情况不会发生。只有当目标上层内存有空闲空间时,驻留在CPU-less节点(下层内存)的页面才能通过AutoNUMA进行升级。图1a显示了目前Linux内核支持的所有可能的页升级和迁移路径的箭头。即使上层内存已经满了,所以操作系统不能把页放在首选访问层上,我们也需要通过自由地允许页在任何CPU-less的节点上移动来保持下层内存的访问位置性。
Problem: Pages are never migrated to the CPU-less (lower-tier) nodes due to a NUMA policy that does not apply to multi-tiered memory systems.
3.3 Page Reclamation页回收
目前的页面回收也是为基于存储的交换设备支持的纯DRAM系统设计的,而不是分层的内存系统。传统上,当内存节点耗尽时,kswapd会将内存中不活动的页面直接回收到存储中,而不考虑内存层。将低层内存中的页面回收到存储设备上是合理的。然而,当下层内存有足够的空间时, 这对上层内存页来说并不是一个理想的解决方案。这个限制与第3.2节中解释的两个问题交织在一起。
Problem: Frequently accessed pages from the lower-tier cannot be promoted without demoting less frequently accessed pages from the upper-tier.
在Linux操作系统中,每个进程的虚拟地址空间的一部分可以被映射,即文件支持区或匿名区。在文件备份区域的页包含了内存中现有文件的内容这样以后对同一文件的I/O操作就可以用内存访问代替。另一方面,属于匿名区域的页面不代表任何文件内容。这用于在内存中保留任意数据(例如,malloc)。对于每个内存区域,Linux操作系统将内存页分为活跃和不活跃内核有非活动列表,包含可能不使用的页面,同时将最近访问的页面保留在活动列表中。 然而,目前的页面分类过于保守,无法从活动和非活动列表中,精确区分哪些页面是经常被访问的,哪些是不经常被访问的。
Problem: Binary page classification (either active or inactive) is too coarse-grained to be used for tiering.
最后,当前的页面回收是在后台小心执行的,以隐藏从关键路径访问外存设备的花销。在分层内存系统中,将页面降级到低层内存的成本比将页面换出到存储设备的成本更低。我们需要将降级到低层内存与传统的回收到存储设备的做法脱钩。
4 Automatic Multi-Tiered Memory自动多层内存
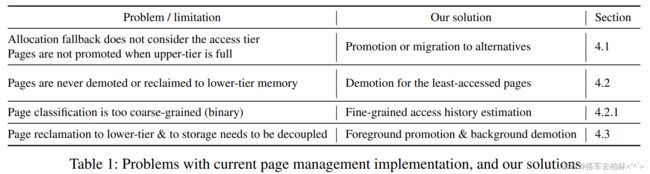
本节探讨了页面管理对分层内存系统的设计空间。我们的页面管理的目标是是充分利用多层内存的优势,以提高证明大内存应用程序的性能。为了保持我们的设计简单我们的设计以AutoNUMA设施为基础。表1总结了每个设计空间的支持机制。在下面的小节中,我们解释每个方案的设计和实现。
4.1 Exploiting Multi-Tiered Memory多层次内存开发
利用多层次的内存如图4所示,我们将NUMA故障作为DCPMM节点或远程DRAM节点的页面升级或迁移的需求信号。请注意,目前的AutoNUMA只在上层(本地DRAM)内存有空闲空间的情况下才处理升级和迁移请求。否则,该请求将被丢弃,而故障页将重新出现在原始内存中。当本地DRAM被完全占用时,我们提出的设计允许页面被提升或迁移到多层内存层次结构中的下一个最佳内存节点。这种方法可以利用多层内存层次结构的优势, 提供比现有Linux内核更高的性能。
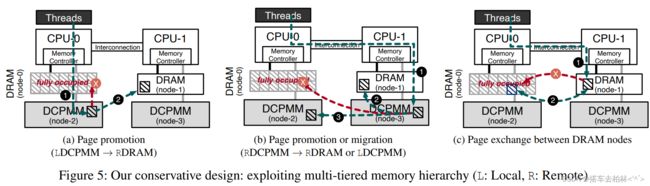
图5描述了当本地DRAM满的时候,我们如何反应。在多层内存系统中,有三个需求来源,即页面迁移或升级到本地DRAM。多层的层次结构为设计内存布局提供了新的机会。首先,(5a)当故障页驻留在本地DCPMM中时①,我们将该页升级远程DRAM中,作为第二最佳位置②。由于远程DRAM提供了比本地DCPMM更低的延迟和更高的带宽,我们可以提高那些最初在低层内存中分配内存的应用程序的性能。第二, (5b)如果出错的页面位于在远程DCPMM①,我们有两个选择, 即开发利用多层内存层次结构的优势。我们试图将该页提升到远程DRAM②。如果如果远程DRAM也没有空闲空间,我们就尝试将该页迁移到本地DCPMM③。与现有的Linux内核不同,我们修改后的内核支持将页面迁移到CPU-less的节点(本地DCPMM)。我们称这种AutoTiering 为保守的升级和迁移(CPM)。最后,(5c) 发生故障的页面在远程DRAM中①。这意味着该页已经在排第二的最佳位置了。现有的AutoNUMA无法完成上层内存节点之间的页面迁移操作。因此,它导致了次优的性能。在这种情况下,我们考虑采用页面交换的方式来满足对内存亲和性的需求②。之前的研究提出了分层内存的页面交换机制[35]。我们重新利用这个机制来解决同层内存节点之间的迁移故障。在内部,对于每个内存节点,我们跟踪哪些页面不能被迁移。然后我们利用这些信息来确定可以通过交换操作解决的迁移需求。我们将此称为AutoTiering CPM with Exchange(CPMX)。
由于这种设计不需要对在现有的Linux操作系统的基础上,它很容易集成到AutoNUMA设施之上。我们预计,我们的构架式设计可以成为这种软件管理的分层内存系统的实用解决方案。
4.2 Opportunistic Promotion and Migration机会性的升级和迁移
由于我们设计了一个保守的方法来寻找最佳的替代方案,这仅限于提取软件管理的分层内存的全部性能优势。在我们的保守设计中,经常使用的页面可以驻留在低层(DCPMM)内存中,而上层(DRAM)内存则存放不经常访问的数据。为了缓解这种不理想的内存位置,我们探索了一种渐进式的策略,即从上层内存中机会主义地降级一个页面,以创造自由空间。这是保守设计和渐进性设计之间的主要区别。通过降级页面,页面升级的请求可以成功。对于页面降级的效率,我们需要有能力选择一个在短时间内极不可能被重用的页面。否则,错误的选择会对性能产生负面影响。我们在下面的小节(4.2.1) 中解释我们如何选择降级的页面。
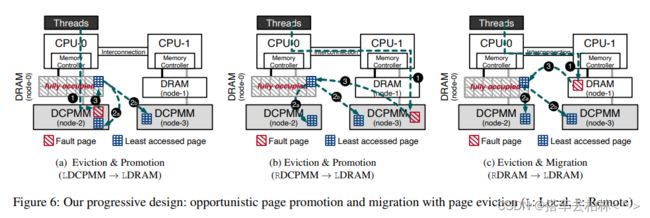
图6描述了我们的渐进式方法是如何进行页面降级的。当NUMA页面故障发生时①, 我们从上层(本地DRAM)内存中找到访问次数最少的页面,并比较访问次数最少的页面和故障页面的访问频率。如果所选页面的访问频率相对低于故障页面,我们就把所选页面降级,把故障页面放在更高层次的内存节点上。否则,我们会阻止页面升级或迁移请求,以保持上层内存有更频繁的访问页面。
为了从本地DCPMM(6a)或远程DCPMM(6b)中提升一个页面, 我们将访问次数最少的页面降级到低层内存②a或者②b。页面降级目的地取决于该页之前被访问的地方,以保持其位置性。之后,③我们可以最终将该页提升到本地DRAM节点。此外,图6c显示了如何从远程DRAM进行页面迁移的请求。我们把这种称为AutoTiering的机会性推广和迁移(OPM) 。
我们进一步优化我们的渐进式设计 ,将降级和升级(或迁移)融合到一个交换操作中,称为AutoTiering OPM with Exchange (OPMX) 。当降级的目的地与晋升或迁移的来源相同时,我们利用交换操作,而不是单独的晋升和迁移。例如(6a),如果我们需要将一个选定的页面降级到本地DCPMM②a, 并将该页面提升到本地DRAM③,两个单独的操作被融合。该交换操作消除了不必要的页面分配和释放操作。
万一我们找不到要从上层内存中降级的页面,我们会尝试将该页面升级到下一个最佳位置——远程DRAM——就像通常的情况一样。由于我们是以机会主义的方式进行页面升级和迁移,我们可以减少过度的页面升级和降级导致的相关性能开销——页表操作和TLB shootdown。
4.2.1 Predicting the Least Accessed Page预测访问量最少的页面
为了使渐进式设计有效,我们的目标是从上层内存中找到访问最少的页面。正如第3.3节所解释的,Linux操作系统将内存分为文件支持的和匿名的页面,作为LRU列表。当页面升级或迁移由于上层内存缺乏可用空间而失败时,我们会优先调查文件支持区域的页面,如果我们无法从文件支持区域找到访问量最小的页面,则会转移到匿名区域。
①文件支持的页面。我们研究是否可以通过降低属于文件支持区域的页面的等级来腾出空间。由于文件支持的页面被维护在两个LRU列表中,活动和非活动, 我们将非活动列表中最老的页面视为访问量最小的页面。每当文件支持的页面被重新访问时(例如,sys_read或sys_write) ,操作系统会将该页面标记为被访问,并将其移至活动列表。由于操作系统可以跟踪文件支持的页面的访问情况,我们通过查看非活动列表来估计访问最少的页面。如果不是,我们就转到活动列表。注意,我们保留在内核参数中配置的页面缓存的部分( 例如,vfs_cache_pressure)。如果我们不能在文件支持区域找到可重用的空间,那么我们就在匿名区域寻找一个页面作为后备路径。
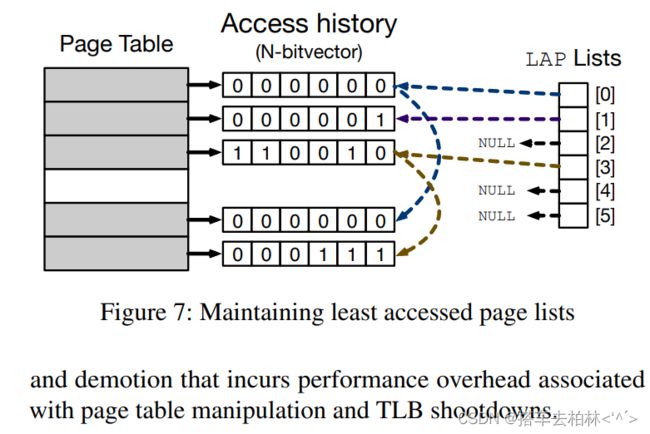
②匿名页面。另一方面,我们保留每个页面的访问(故障)信息,以明智地选择匿名区域中访问最少的页面。为了尽量减少监控开销,我们利用AutoNUMA使用的页面扫描工具,跟踪页面在给定的时间窗口内是否被访问。然后,我们用N比特向量为每个页面建立访问历史。这意味着我们要保持到最后N次的访问历史。我们将N设置为8。基于访问历史,我们将页面分为N个级别(最少访问的页面列表),其中N是被设置的比特数,如图7所示。一旦需要进行页面降级,我们在LAP[0]列表中找到其中一个页面,因为这些页面至少有N次没有被访问了。如果LAP[0]列表是空的,我们尝试从LAP[1]列表找一个,等等。这之后,我们就能选择在高层最少被访问的页面,并且实施页面降级去底层内存。
4.3 Hiding Latency of Page Demotion隐藏页面降级的延时
为了执行页面升级,我们应该将一个页面从目标节点上降级。在完成页面降级之前,由于缺乏空间,我们不能继续进行升级请求。故障处理时间是关键路径中两个操作的总和:页面降级和升级。为了从关键路径中移除页面降级,我们探索了一种软件优化技术。
我们保持一个由几个保留页组成的页面池。我们把4KB和2MB的保留页分别确定为16和4。保留页允许我们在不需要降级过程的情况下立即为升级请求提供服务,即使上层内存已满。这种方法比页面交换方案[35]更具成本效益,因为它将页面降级的延迟隐藏在关键路径中。页面降级到下层内存比页面晋升到上层内存需要更长的时间,因为用于下层外存提供了更好的读取性能而不是写性能。为了在后台有效地降级页面,我们维护了一个新的内核线程,称为kdemoted,在一个批次中降级最少接受的页面。一旦保留页的数量低于某个阈值,我们就唤醒内核线程,开始降级过程。通过敏感性研究,该阈值被设定为4。
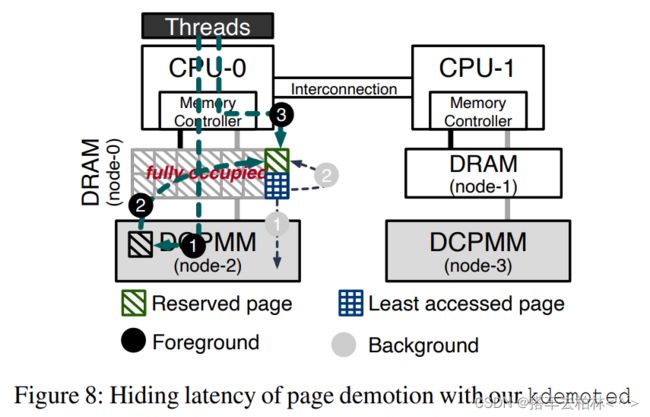
图8描述了简单的优化如何隐藏了页面降级的延迟。对于每一个晋升请求①黑,即使上层内存已满②黑 ,该页也可以被晋升。在完成升级后,NUMA故障处理程序被返回,没有降级过程,而未来对该页面的访问③黑將在上层内存发生。同时kdemoted将降级访问量最小的页面作为一个批次①回收到内存池②的需求。我们将此称为OPM-BD (背景降级)。
5 Evaluation评估
5.1 Experimental Setup实验设置
为了评估我们提出的方案,我们使用了一台配备了两个英特尔至强黄金5218处理器的NUMA服务器,并为每个CPU插座配置了一个16GBDDR4-2666 DIMM和一个128GB英特尔Optane DC持久内存(DCPMM) 的多层内存层次结构。服务器系统总共有32GB DRAM和256GB DCPMM作为主内存。为了尽量减少测量变化,我们关闭了硬件功能,包括超线程、 DVFS、Turbo-Boost和预取。我们使用Linux内核5.3和Ubuntu18.04服务器作为我们的基线,并在内核之上实现我们提出的方案。我们的代码可在https://github.com/csl-ajou/AutoTiering。我们运行来自graph500、SpecACCEL (OpenMP)、 Graph-Mat[32]和Liblinear[22]的基准,这些基准在最近的大内存系统中使用[2,35]。我们为所有的基准测试配置了它们,在两个插座上使用所有的32个内核和超过64GB的内存,以充分强调多层内存系统。由于页面大小会以各种方式影响性能我们评估了大页面(2MB)和基本页面(4KB)的性能。
5.2 Experimental Results实验结果
使用我们的保守方法(CPM)的性能。图9显示了比原版Linux内核(第一条)的加速结果。请注意,在默认的Linux内核中,AutoNUMA已经启用。图9中的第二条显示了我们保守的升级和迁移(CPM) 的速度,第三条显示了应用保守的交换(CPMX)时的性能变化。对于我们评估的大多数工作负载,我们可以看到我们的CPM有明显的性能改善。在503.postencil,553.pclvrleaf和560.pilbdc中,与基线相比,速度提高了2倍以上。另外,559.pmniGhost显示了1.6倍的性能提升。我们的保守设计(CPM)可以将页面从低层(DCPMM)内存节点升级到远程DRAM节点,尽管由于远程DRAM比本地DCPMM更快,所以局部性没有得到保留。我们还可以在两个DCPMM节点之间迁移页面,以便在访问低层内存时有更好的访问局部性。因此,我们可以更有效地利用多层内存系统,提高性能。对于graph500和GraphMat,我们看一 下,其速度分别为17%和19%左右。GraphMat和Liblinear将大型数据集从文件中读取到其内存数据结构中。文件支持的页面占据了DRAM节点的很大一部分,而关键的数据结构位于DCPMM节点中。之后,它执行Pagerank算法进行分析。不幸的是,我们无法观察到调用kswapd来释放不活动的文件备份页。因此,我们的CPM和CPMX没有机会有效利用DRAM节点。
另一方面,我们观察到555.pseismic的性能完全没有提高。这表明,在基线中,内存放置在上层和下层内存之间是很平衡的。因此,我们无法利用升级和迁移的机会。
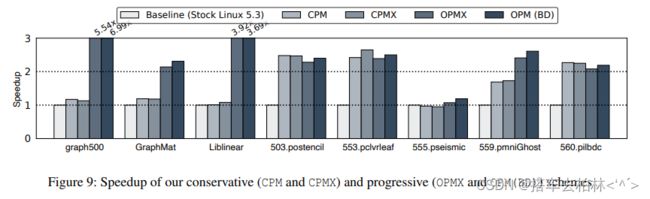
使用我们的渐进式方法(OPM)的性能。我们在第4.2节中描述了我们的渐进式设计,它从上层(本地DRAM)节点中找到访问量最小的页面,并将其降级到下层内存中。如图9所示,OPMX在大多数工作负载中都比CPMX有更好的性能。特别是graph500,GraphMat,Liblinear和559.pmniGhost显示出比CPMX明显的速度提升。503.postencil,553.pclvrleaf和560.pilbdc的性能略有下降,大约下降了7%到8%。560.pilbdc未能摊销页面升级和降级的开销,而553.pclvrleaf显示页面交换的机会减少了。
我们分析了graph500的运行行为,以了解性能的提高。在执行核心图算法之前,它产生了大量的中间数据,占据了DRAM空间。因此,基线和我们的CPMX在运行BFS (广度优先搜索)时花了大部分时间访问低层内存。有趣的是,它在地址空间的一小部分上表现出了内存访问位置性,尽管整个地址空间是巨大的。有了OPMX,我们可以将访问频率较低的数据降级。到低层内存,并将高层内存空间用于更频繁访问的数据。因此,我们可以大幅度地提高性能。
对于GraphMat来说,我们看到显著的性能改善来自于文件支持的页面的降级。通过默认,文件支持的页面最初被放在非活动列表中。在该页面被重新访问后,它将从非活动列表移至活动列表。通过将访问量最小的页面从文件支持的页面中降级,我们可以提高上层内存的利用率。
通过OPM (BD),我们可以进一步提高大多数工作负载的性能。与OPMX相比,graph500和GraphMat的改进是相当大的。555.pseismic和559.pmniGhost显示出明显的改善,其他SPEC工作负载也恢复了交换版本的退化性能。同时,Liblinear显示出轻微的性能下降。
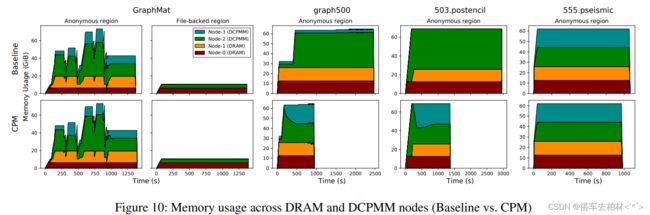
内存使用的分布。我们分析了随着时间的推移,多层次的内存是如何被利用的。图10比较了基线和我们对选定工作负载的渐进式设计的内存使用情况,这从我们的CPM中受益。对于三个SPEC工作负载,低层内存与CPM的平衡性更好。这是因为我们允许页面被迁移到CPU-less的节点上。尽管CPM无法以满足所需的访问层,它可以保留低层内存的访问局部性。对于GraphMat来说,与SPEC工作负载相比,性能改善相对较小,555.pseismic也没有改善。原因是基线已经在较低级别的DIMM上保持内存平衡。在下一段中,我们看一下我们基于OPM的方案对这两个工作负载的有效性。
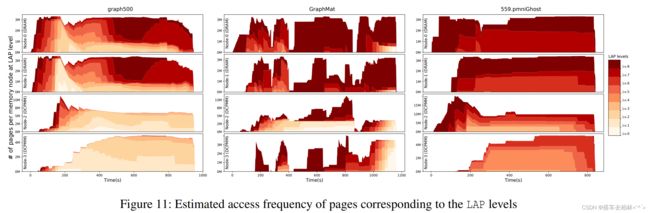
LAP分类的有效性。为了评估我们的LAP方案的有效性,我们将所有的页面分解到每个LAP级别,并随着时间的推移建立一个直方图。图11显示了选定的三个工作负载,与CPM相比,OPMX显示了明显的改善。对于graph500,GraphMat和559.pmniGhost,相对频繁访问的页面(深红色)对应于第7级或第8级被放置在DRAM节点上,而DCPMM节点服务于相对较少访问的页面。这个结果表明,我们的OPMX对于工作集适合于上层内存的应用是有效的。
为了实现我们的LAP方案,每个页面都需要额外的空间来保存访问历史(8B)、两个列表指针(16B)、页面帧号(8B)和最后故障的CPU编号(1B)。与基线相比,由于8字节的对齐方式,我们需要每页32字节的元数据,它导致系统内存32GB的288MB DRAM与256GB DCPMM。它稍微减少了0.91%的有效DRAM内存空间。
使用后台降级的延迟隐藏。我们测量了晋升和交换延迟在页面上的分布我们用ftrace以及内核和用户时间来测量页面故障路径中的推广和交换延迟分布。图12显示了为OPM(BD)的页面推广和OPMX的页面交换服务的延迟CDFOPM(BD)和OPMX的页面交换的延迟CDF。实线是分布,包括延迟隐藏方案(OPM(BD)),而虚线是OPMX方案。这两种方案的故障延迟都不同。我们观察到,OPM(BD)在所有工作负载中都显示出比交换版本更好的延迟分布,因为降级是在关键路径之外。特别是graph500和555.pseismic对后台降级有利。
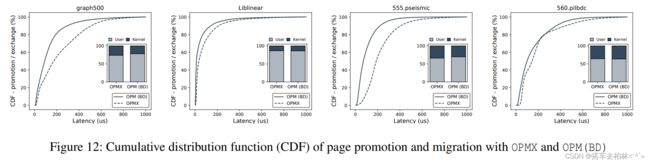
另一方面,Liblinear的最终表现在图9中显示,Liblinear的最终性能没有得到改善。即使延迟减少了,内核的执行时间也没有明显改变。时间并没有显著改变。这是由于有可能引起应用程序线程和后台内核线程之间的内存访问争夺。我们计划在我们未来的工作中用严格的kdemoted调度来解决不希望出现的后台降级情况。
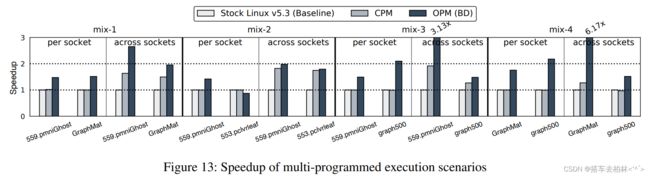
多程序工作负载的性能。我们评估了我们提出的方案在每个套接字和跨套接字两种情况下对多程序工作负载的工作情况。图13显示了两个应用程序在同一台服务器上运行时,CPM和OPM(BD)的速度提升。我们用工作负载的组合模拟了四种多程序的场景(mix-1到4)。当基于套接字(每个套接字)隔离应用程序时,CPM没有提供任何预期的性能改进,因为它缺乏利用内存的多层次结构的机会。另一方面,我们可以观察到OPM(BD)在所有情况下都有明显的性能改进,除了553.pclvrleaf在mix-2中,因为更多经常访问的页面可以被放在上层内存上。当允许应用程序跨套接字运行时,它们可能无法有效地利用上层内存节点,因为应用程序的线程之间的内存使用并不是均匀分布的。在跨套接字设置中,我们观察到CPM可以通过利用多层内存层次结构而发挥作用。此外,与CPM相比,OPM(BD)可以进一步提高性能。与CPM相比,在所有情况下都能进一步提高性能。
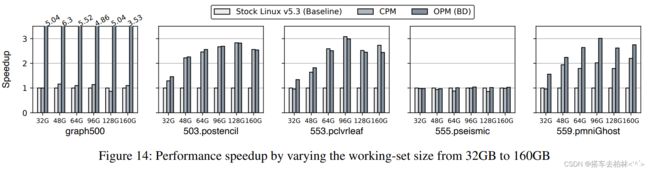
工作集的敏感性。图14显示了工作集大小从32GB到160GB变化时的性能。160GB的选定工作负载的性能。我们观察到,graph500和559.pmni,Ghost的性能被CPM和OPM(BD)显著提高。对于503.postencil和然而,对于503.postencil和553.pclvrleaf,OPM(BD)和CPM显示出类似的随着工作集大小的增加,OPM(BD)和CPM表现出类似的性能改进。正如在LAP分类段落中所解释的,在这些基准中,大部分的
在那些对OPM(BD)不太有利的基准中,大部分页面都是均匀访问的。对OPM(BD)有利。请注意,与原版Linux(Baseline)相比,我们的方法的提速是显著的,而且仍然有效。由于其他工作负载,如GraphMat和Liblinear。有固定的问题输入大小,我们无法评估工作集的敏感性。
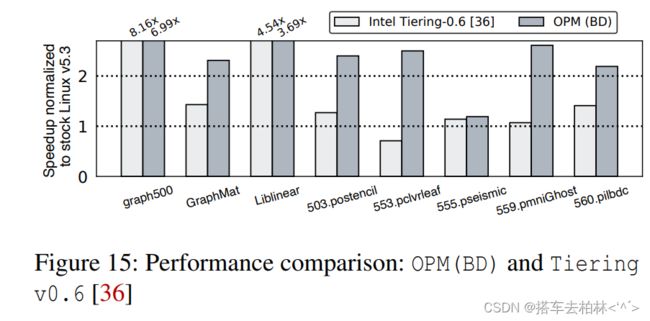
与先前研究的性能比较。图15展示了与英特尔最近提出的名为Tieringv0.6[36]的性能比较结果。请注意,Tieringv0.6是基于Linux内核5.9版本的,但没有并入主线。我们表明,我们的OPM (BD)在大多数工作负载中的性能超过了Tiering v0.6。对于匿名内存区域,Tieringv0.6通过使用AutoNUMA框架,将页面升级到上层定时器内存。通过监控设施,他们调查该页是否在最近两次连续扫描中被访问。如果是这样,他们认为该页是热的,并升级它。另一方面,我们的OPM(BD)保持了过去N(8)次的访问历史。这个决定比看前两次访问更准确此外,Tieringv0.6也继承了传统AutoNUMA的限制。一旦本地DRAM满了,它就不允许将页面推广到远程DRAM或本地DCPMM上。相反,kswapd会被触发,将页面回收到较低层的内存。相比之下,我们的LAP方案通过有选择地执行升级和降级,使上层内存得到更好的利用。对于graph500,我们观察到Tieringv0.6比OPM (BD)表现得更好。我们的方案在执行前构建图形的时间上表现出色,但在遍历图形时,与Tieringv0.6相比采用OPM(BD)的graph500访问了更多的低层内存中的页面。在Liblinear中,它表明Tieringv0.6更积极地将文件支持的页面降级,导致上层内存的更好利用。
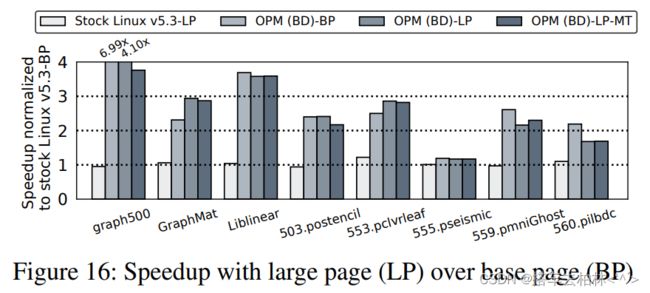
大页的性能。为了尽量减少大内存应用的TLB缺失的开销,现代计算机系统提供了大页面选项。图16显示了当我们利用大页面(2MB)而不是基本页面大小(4KB)时的速度提升结果。对于GraphMat和553.pclvrleaf,在OPM (BD)方案中可以观察到大页面的性能改进。另一方面,大多数的工作负载并没有出现明显的差异。559.pmniGhost和560.pilbdc的性能有所下降。当分析具有大页面的SPEC工作负载的LAP直方图时,与基础页面相比,我们的方案可以快速将页面分离到LAP级别。然而,由于在移动大页面时,页面降级的开销会增加,所以会出现性能下降的情况。为了减少开销,我们利用了复制页面的多线程(MT)版本的优势[35]。559.pmniGhost只显示了改进的性能,但其他工作负载变得更差。正如前面一段提到的(延迟隐藏),我们将在未来的工作中进一步研究如何扩展我们的方案以减轻性能开销。
6 相关工作
在整个硬件和软件方面,为有效使用分层(或异质)内存系统做出了巨大努力。我们将我们的方案与之前的方法进行比较。首先,以前的研究大多集中在设计两层内存系统的分页机制和策略[3, 10, 11, 19, 20, 24, 26, 29, 35]与之前的工作不同,本研究将问题空间扩展到分层内存在传统的NUMA架构上增加了一个多层次的内存系统。由于在多层内存系统中, 有几种替代性的页面放置方式本文在放置、升级和删除页面时利用了这些机会。第二,AutoTiering 并没有用先前工作中使用的预定义阈值将页面区分为热和冷[3,19,20]。在这项研究中,晋升和降级的决定是根据整个内存层的相对访问频率和重复性做出的。为了估计页面访问活动,我们依靠AutoNUMA设施。最后,我们使用一个真实世界的基础设施来评估我们提出的基于英特尔的OptanePersistentMemory (DCPMM) 的想法,它最近引起了关注。之前的工作模拟或仿真了基于DRAM的两级内存系统[3,11,1.9,20,35]。尽管现实世界中的存储类内存(SCM)在读写性能上显示出不对称性,但在用DRAM模拟分层内存
时,它并没有被正确建模。
下面,我们将介绍操作系统界以前在软件方面的努力为了了解Linux中内存系统的异质性,ACPI6.2规范引入了异质性内存属性表( HMAT),为用户提供各种内存类型的性能信息[39]。从Linux内核5.0-rc1开始,持久性内存(这里指英特尔的DCPMM)可以被用作易失性主内存,尽管它比DRAM慢[15]。它可以提供丰富的主内存空间, 但支持分层内存层次的策略和机制还处于起步阶段。最近,一个新的用于硬件管理的DRAM缓存的内存分配器被称为shuffle page allocator,在Linux内核中被引入[34]。 然而,它不足以提取分层内存的全部性能,因为它没有考虑内存节点之间的距离和NUMA类型。另外,已经有一些努力来有效地支持快内存和慢内存之间的页面迁移,但是这些仍然依赖于活动和非活动列表管理[5,16,30],直到现在还没有被合并到Linux内核的主线中。在Windows操作系统中,他们通过Mi ComputeNumaCost测量系统初始化时各种页面操作的成本, 并建立-个类似于Linux的NUMAdis-tance的表格,但这反映的是访问成本[37]。 由于Windows操作系统的信息有限,我们无法找到它们对多层内存的作用。
架构界的研究人员介绍了有效利用两层内存系统的硬件技术,同时将估计访问频率的性能开销降到最低[7,28,29,31]。Choe等 人提出了硬件辅助的多层内存系统的内存分配方案,其中DRAM节点对软件是不可见的[6]。除此以外,没有一项工作考虑到多层内存系统的情况。通过架构的支持,跟踪和迁移页面等开销可以大大减少,但是考虑到放置的替代方案,做出晋升和降级决定的灵活性是有限的。
7 Conclusion 总结
这项工作探索了一套名为AutoTiering的新的页面管理方案,它从多层内存系统中获益。我们发现,Linux操作系统关注的是NUMA所带来的访问局部性,而不是内存层。然而,在多层内存系统中,访问内存的成本并不只与局部性成正比。我们通过考虑两个因素,即访问层和局部性,全面解决了利用多层内存系统的不同方面。我们用一个真实世界的分层内存系统建立了一个概念验证。我们的评估显示,在各种基准测试中,与现有的Linux内核5.3版本和英特尔的Tieringv0.6之前的方法相比,性能有了明显的改善。
未来的分层存储系统预计会更加多样化和异质化。为了使我们的方法更加普遍,我们可以维护一个描述可能的替代安置的表格。在操作系统中初始化内存时,我们可以测量各内存节点的实际性能。有了这样一个新的表格, AutoTiering 可以调整页面需要晋升、降级或迁移的地方,正如所解释的那样,没有一个静态的决定。
总结
提示: