pandas第五章 -变形--长宽表的变形函数、索引的变形
一、长宽表的变形
定义
什么是长表?什么是宽表?这个概念是对于某一个特征而言的。例如:一个表中把性别存储在某一个列中,那么它就是关于性别的长表;如果把性别作为列名,列中的元素是某一其他的相关特征数值,那么这个表是关于性别的宽表。
pd.DataFrame({'Gender':['F','F','M','M'],
'Height':[163, 160, 175, 180]})
#关于性别的长表,性别放在一列。 long
Out[3]:
Gender Height
0 F 163
1 F 160
2 M 175
3 M 180
pd.DataFrame({'Height: F':[163, 160],
'Height: M':[175, 180]})
#关于性别的宽表,性别放在一行。wide
Out[4]:
Height: F Height: M
0 163 175
1 160 180
长宽表的变形函数
1. pivot
1)pivot 是一种典型的长表变宽表的函数
#index, columns, values 对应变形后的行索引、需要转到列索引的列,以及这些列和行索引对应的数值
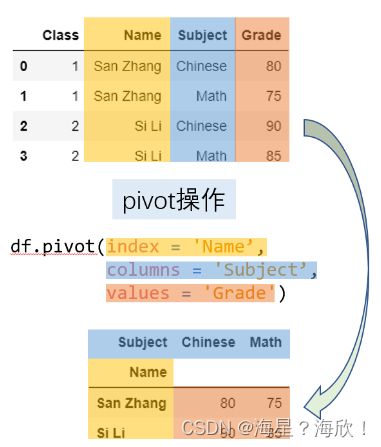
df.pivot(index='Name', columns='Subject', values='Grade')
2)举例:
df = pd.DataFrame({'Class':[1,1,2,2],
'Name':['San Zhang','San Zhang','Si Li','Si Li'],
'Subject':['Chinese','Math','Chinese','Math'],
'Grade':[80,75,90,85]})
#原表形态
df
Out[6]:
Class Name Subject Grade
0 1 San Zhang Chinese 80
1 1 San Zhang Math 75
2 2 Si Li Chinese 90
3 2 Si Li Math 85
#df.pivot之后
df.pivot(index='Name', columns='Subject', values='Grade')
Out[7]:
Subject Chinese Math
Name
San Zhang 80 75
Si Li 90 85
3)要求:唯一性
即由于在新表中的行列索引对应了唯一的 value ,因此原表中的 index 和 columns 对应两个列的行组合必须唯一。不能存在多值,否则会报错
4)多列例子
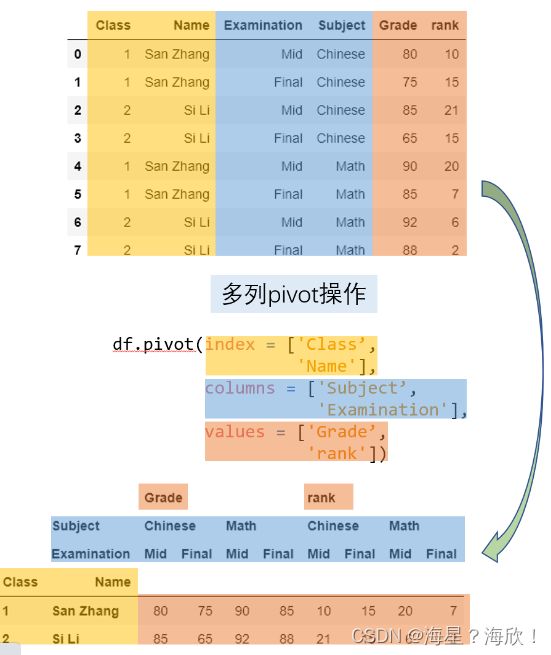
上述转变的pivot函数:
df.pivot(index = ['Class','Name'],columns = ['Subject','Examination'],values=['Grade','rank'])
也要求数据满足唯一性原则
2.pivot_table
1)针对不满足唯一性条件的数据,pivot无法使用,引入pivot_table通过聚合操作使得相同行列组合对应的多个值变为一个值。
pivot_table 相比pivot 多了一个aggfunc 参数,表示使用的聚合函数
df.pivot_table(index = 'Name',
columns = 'Subject',
values = 'Grade',
aggfunc = 'mean')
2)例子:张三参加了两次语文考试,按照学院规定,最后的成绩是两次考试分数的平均值。
df = pd.DataFrame({'Name':['San Zhang', 'San Zhang',
'San Zhang', 'San Zhang',
'Si Li', 'Si Li', 'Si Li', 'Si Li'],
'Subject':['Chinese', 'Chinese', 'Math', 'Math',
'Chinese', 'Chinese', 'Math', 'Math'],
'Grade':[80, 90, 100, 90, 70, 80, 85, 95]})
#原表
df
Out[16]:
Name Subject Grade
0 San Zhang Chinese 80
1 San Zhang Chinese 90
2 San Zhang Math 100
3 San Zhang Math 90
4 Si Li Chinese 70
5 Si Li Chinese 80
6 Si Li Math 85
7 Si Li Math 95
#聚合平均后的数据
df.pivot_table(index = 'Name',
columns = 'Subject',
values = 'Grade',
aggfunc = 'mean')
Out[17]:
Subject Chinese Math
Name
San Zhang 85 95
Si Li 75 90
3) aggfunc 除了聚合函数外,还可以传入以序列为输入标量为输出的聚合函数来实现自定义操作。
aggfunc = lambda x:x.mean()
和上述的aggfunc = 'mean' 相同作用
4)同时,pivot_table 具有边际汇总的功能 margins=True
其中边际的聚合方式与 aggfunc 中给出的聚合方法一致。
下面就分别统计了语文均分和数学均分、张三均分和李四均分,以及总体所有分数的均分:
df.pivot_table(index = 'Name',columns = 'Subject',values = 'Grade',aggfunc = 'mean',margins = True)
Out[19]:
Subject Chinese Math All
Name
San Zhang 85 95.0 90.00
Si Li 75 90.0 82.50
All 80 92.5 86.25
3,melt
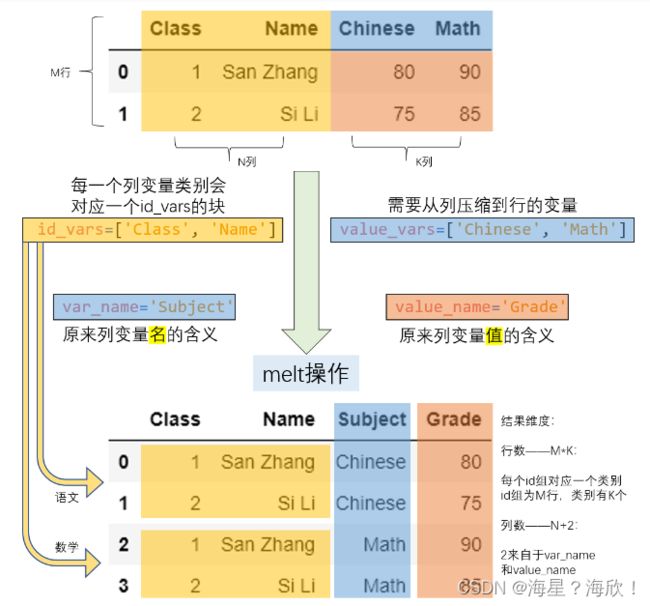
pivot 把长表转为宽表,melt 函数可以通过相应的逆操作把宽表转为长表
例子: Subject 以列索引的形式存储,现在想要将其压缩到一个列中。
df = pd.DataFrame({'Class':[1,2],
'Name':['San Zhang', 'Si Li'],
'Chinese':[80, 90],
'Math':[80, 75]})
df
Out[21]:
Class Name Chinese Math
0 1 San Zhang 80 80
1 2 Si Li 90 75
df_melted = df.melt(id_vars = ['Class', 'Name'],
value_vars = ['Chinese', 'Math'],
var_name = 'Subject',
value_name = 'Grade')
df_melted
Out[23]:
Class Name Subject Grade
0 1 San Zhang Chinese 80
1 2 Si Li Chinese 90
2 1 San Zhang Math 80
3 2 Si Li Math 75
再逆操作一下
df_unmelted = df_melted.pivot(index = ['Class', 'Name'],
columns='Subject',
values='Grade')
df_unmelted # 下面需要恢复索引,并且重命名列索引名称
Out[25]:
Subject Chinese Math
Class Name
1 San Zhang 80 80
2 Si Li 90 75
4,wide_to_long
二、索引的变形
1. stack与unstack
三、其他变形函数
1. crosstab
2. explode
3. get_dummies