Transformer的调研及其进展
第一节
ICLR2020最新Transformers进展(上)
涉及模型:
[1] Attention is All You Need
[4] BERT
[5] Transformer-XL
[6] Lite Transformer with Long-Short Range Attention
[7] Tree-Structured Attention with Hierarchical Accumulation
[8] Reformer: The Efficient Transformer
[9] Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention
[10] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
[11] StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
[12] Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
ICLR2020最新Transformers进展(下)
涉及模型:
[13]Encoding word order in complex embedding
[14]Compressive Transformers for Long-Range Sequence Modelling
[15]Universal Transformer
[16]ALBERT: A Lite BERT for Self-supervised Learning of Language
论文链接在原文有。当然这只是该会议的论文,所以还要继续调查。
第二节
AI-Scholar:Transformer话题
2021年更新的文章偏向于计算机视觉
Transformer的发展势不可挡!Transformer改进研究总结Part1
围绕Efficient Transformers: A Survey展开,这篇论文我没找到发表在哪。
目录
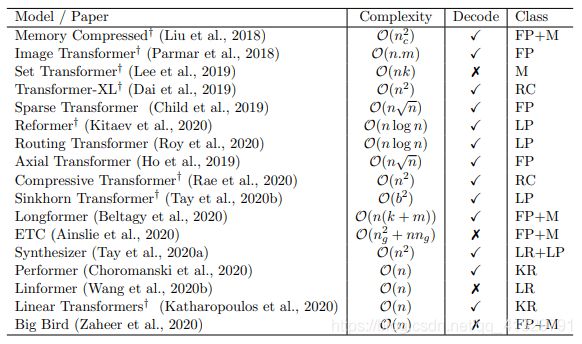
- Transformer的计算量
Multi-Head Self-Attention-时间计算量、空间计算量的瓶颈- Efficient Transformer的分类
2.1. Fixed Patterns (FP)
Blockwise Patterns-将输入序列分成固定的块
Strided Patterns-从输入序列中按一定时间间隔抽取的数据
Compressed Patterns-对输入序列进行压缩计算。
2.2. Combination of Patterns (CP) -结合多种固定模式。
2.3. Learnable Patterns (LP)-将计算限制在相似度高的tokens上
2.4. Memory-全局存储器记录整个序列的信息
2.5. Low-Rank Methods-减少的不是嵌入的特征维度,而是序列长度seq
2.6. Kernels-快速的近似过程来代替Self-Attention计算机制
2.7. Recurrence-递归机制为了应对非常长的序列。- Efficient Transformer相关信息
3.1. 关于评价
3.2. 各种举措
Weight Sharing-Albert
Quantization / Mixed Precision-通过不同的精度降低内存成本
Knowledge Distillation / Pruning-不懂 知识蒸馏
Neural Architecture Search (NAS) -用于视觉
Task Adapters- Efficient Transformer具体实例(另文解释 Part2, Part3)


关于评价:
根据使用模型的目的不同,评价方法也会发生变化,可以说,仍然没有一个通用的优秀模型应该用于任何任务。
在考虑使用高效变压器时,需要注意各型号的特点和评价方法。

Transformer的研究总结第2篇
介绍了一个使用固定模式全局存储器的Efficient Transformer模型的具体例子。
通过适当结合以某种方式限制Attention计算目标的固定模式,以及存储整个序列信息的全局存储器,Transformer中的Attention计算被快速逼近过程所替代。
下面模型的介绍同时参考这一篇
Memory Compressed Transformer
步幅模式:对密钥 K K K和值 V V V进行卷积运算,以减少维度。原文中,内核步长大小设置为3。
后者则是采用跨步卷积,减少注意力矩阵的大小、以及注意力的计算量,减少的量取决于跨步的步幅。
猜测不适用 因为跨步卷积是减少了序列的长度,而与下图在attention矩阵做跨步是不一样的

Image Transformer
摘要
如果每个查询位置要计算的邻域都发生了变化,那么自注意力就不能以两个矩阵相乘的方式计算。
所以将输入数据分为查询块和内存块,将一个查询块中包含的所有查询数据作为同一内存块的区域进行计算。可能不适合解决需要全局信息的任务。
set Transformer 不适用
用于处理“顺序无关”类型,即集合类型数据的模型,利用全局内存的方法。
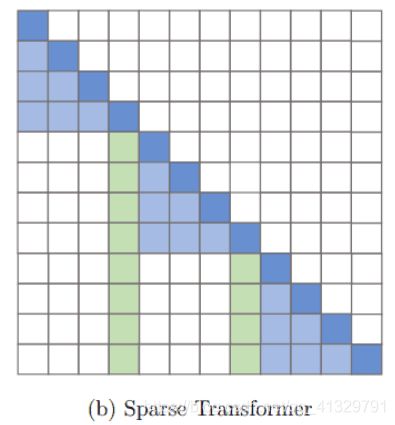
Sparse Transformers
不过这个模型对硬件有所要求,需要自定义GPU内核,且无法直接在TPU等其他硬件上使用。
A ^ i j = { Q i ( K ) j T ( i f ⌊ j / N ⌋ = ⌊ i / N ⌋ ) 0 ( o t h e r w i s e ) \hat{A}_{ij}=\left\{ \begin{array}{ll} Q_i(K)^T_j & (if \lfloor j/N \rfloor = \lfloor i/N \rfloor) \\ 0 & (otherwise) \end{array} \right. A^ij={Qi(K)jT0(if⌊j/N⌋=⌊i/N⌋)(otherwise)
当Q、K除以 N N N时,被认为是同一区块,只有这同一区块被用于计算注意力。
A ^ i j = { Q i ( K ) j T ( i f ( i − j ) m o d N = 0 ) 0 ( o t h e r w i s e ) \hat{A}_{ij}=\left\{ \begin{array}{ll}Q_i(K)^T_j & (if (i-j) mod N = 0) \\ 0 & (otherwise) \end{array} \right. A^ij={Qi(K)jT0(if(i−j)modN=0)(otherwise)
计算广泛的稀疏关注度
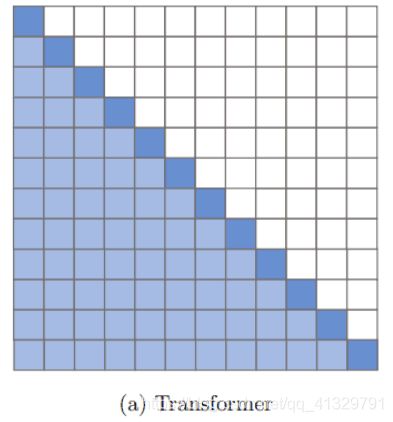
Longformer
三个attention pattern:
Sliding window attention——为每一层使用不同的w值对平衡效率和模型的表示能力可能会有所帮助。
Dilated Sliding Window——其他具有空洞的head专注于较长的上下文
Global Attention——在一些预先选择的位置上(图中标红)添加了全局注意力。
Transformer改进研究总结 Part3
摘要
可学习模式,通过可学习的方法来限制注意力计算的目标。
低阶因子化,减少了键和值等维度的数量。
基于递归的模型,该模型侧重于增加序列长度。
Routing Transformers

使用k-means方法对输入的tokens进行聚类,并计算同一聚类中分类的tokens的Attention。对R矩阵采用k-means法。簇的数量设置为 n \sqrt{n} n。
X i ′ = ∑ j ∈ C i , j ≤ i A i j V j X^{\prime}_i=\sum_{j∈C_i,j≤i}A_{ij}V_j Xi′=j∈Ci,j≤i∑AijVj
在这种情况下, C i C_i Ci是分配给向量 R i R_i Ri的簇。系统计算分类在同一簇中的令牌的注意力。计算复杂度为 n n n\sqrt{n} nn。
Sinkhorn Transformers 不适用
以块为单位对密钥K和值V进行排序,并进行局部块化Attention计算。
φ是一个沉角平衡算子,它将nB×nB矩阵转换为软替代矩阵。这是一个用于排序的函数,nB是块的总数。
Linformer 猜测不适用
通过为密钥 K K K和值 V V V引入一个额外的投影层,将 N × d N×d N×d维度转换为 k × d k×d k×d维度。由于序列长度 N N N减少到 k k k,需要注意时间方向信息丢失的危险。单次转换中按维度混合序列信息。
可能对单个实体:技能,交互作encoding时,可以对序列长度压缩
Synthesizers
这个模型研究了调节在自注意力机制中的作用,它合成了一个自注意力模块,近似了这个注意权重。
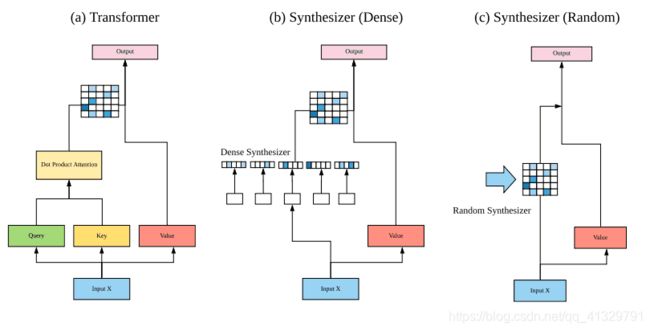
明显,方法一是输入X通过全连接来模拟注意力矩阵;方法二是直接生成一个随机矩阵,参数可训练。
Linear Transformers
当使用自回归模型中使用的Causal Masking(一种设置,其中第 i − t h i-th i−th令牌被掩盖,使其仅受 j < = i j<=i j<=i 令牌的影响)时,Transformer可以被替换为 O ( N ) O(N) O(N) RNN。
线性变换器的关键假设是,注意力的计算可以由以下公式改写。
V i ′ = ∑ j = 1 p s i m ( Q i , K j ) V j ∑ j = 1 p s i m ( Q i , K j ) V^{\prime}_i = \frac{\sum^p_{j=1} sim(Q_i,K_j)V_j }{\sum^p_{j=1} sim(Q_i,K_j)} Vi′=∑j=1psim(Qi,Kj)∑j=1psim(Qi,Kj)Vj
s i m ( q , k ) : = ϕ ( q ) T ϕ ( k ) sim(q,k):=\phi(q)^T\phi(k) sim(q,k):=ϕ(q)Tϕ(k)是一个任意的相似度函数,在LinearTransformer中被表示为一个内核函数。在原文中, ϕ ( X ) = e l u ( x ) + 1 \phi(X)= elu(x)+1 ϕ(X)=elu(x)+1,elu(⋅)是一个ELU(指数线性单位)。
递归模型
基于递归的模型。这些模型不太注重降低计算复杂性,而更注重引入递归机制来处理长序列。
Tranformer-XL:
查询 q τ + 1 n q^n_{τ+1} qτ+1n是由 h τ + 1 n − 1 h^{n-1}_{τ+1} hτ+1n−1计算出来的,而密钥 k τ + 1 n k^n_{τ+1} kτ+1n和值 v τ + 1 n v^n_{τ+1} vτ+1n是由 h ~ τ + 1 n − 1 \tilde{h}^{n-1}_{τ+1} h~τ+1n−1计算出来的。
使用相对位置编码,即一个token相对于其他token的位置。
Compressive Transformers:
压缩式变压器是Transformer-XL的扩展版。关键的区别是强调维护历史信息。
内存——>压缩——>记忆重建(可能会重建记忆上的注意力,而不是重建记忆本身。)
论文讲解
reformer英文这一篇分数提高不多,需要花时间才能看懂。
longformer训练过程
下图引用来源

ETC——global token是要训练的参数,可以认为它保存了整个序列的信息
普通变压器模型与25种不同变体的比较Google Research
Do Transformer Modifications Transfer Across Implementations and Applications?
1.激活、归一化、深度、嵌入参数共享和softmax等修改方法,这些方法对特定的任务是有效的,但这些技术还没有被广泛采用。商议论文进行测试
2.使用科学界多年来提出的几种架构进行测试。不同的架构文章没有提到。
收获
Informer Beyond Efficient Transformer for Long Sequence Time-Series Forecasting——AAAI 2021年度第一的论文
知识追踪的网络结构其实就是一层的GPT,我们需要mask掉当前token后面的信息,且只有交互attention部分
Transformer按使用方法分类:
只用编码器:可用于分类
只用解码器:可用于语言建模
编码器-解码器:可用于机器翻译
疑问:informer里面用到了对输入的压缩(池化层)

那究竟能不能应用到知识追踪里面去,因为他涉及压缩,会不会导致信息泄露(没有mask)
下一步:
Compressive Transformers对应的论文
2020ECNU_Deep Knowledge Tracing with Convolutions这一篇用到3D卷积
**不确定**:但由于无法计算因果掩码,ETC不能用于自动回归解码。
Decode表示模型的解码器部分(对应交叉注意力的部分,而不是自注意力)是否可用。
什么叫不可用???