机器学习实战k-近邻算法(kNN)应用之改进婚恋网站配对效果代码解
一.背景简要说明
问题背景不再详细赘述了,《机器学习实战》中有详细介绍,利用KNN想做的就是训练出一个分类器,能根据对方的一些特征判断他(她)对你的吸引程度,是不喜欢,还是一般喜欢,还是很喜欢。以此改进约会配对效果。
二.模块代码及注释
from numpy import *
import operator
#样本数据集创建函数
def creatDataSet():
dataSet = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return dataSet,labels
#k-NN简单实现函数
def classify0(inX,dataSet,labels,k):
#求出样本集的行数,也就是labels标签的数目
dataSetSize = dataSet.shape[0]
#构造输入值和样本集的差值矩阵
diffMat = tile(inX,(dataSetSize,1)) - dataSet
#计算欧式距离
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#求距离从小到大排序的序号
sortedDistIndicies = distances.argsort()
#对距离最小的k个点统计对应的样本标签
classCount = {}
for i in range(k):
#取第i+1近邻的样本对应的类别标签
voteIlabel = labels[sortedDistIndicies[i]]
#以标签为key,标签出现的次数为value将统计到的标签及出现次数写进字典
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#对字典按value从大到小排序
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回排序后字典中最大value对应的key
return sortedClassCount[0][0]
#从文本文件中解析数据
def file2matrix(filename):
fr = open(filename)
#按行读取整个文件的内容
arrayOfLines = fr.readlines()
#求文件行数,即样本总数
numberOfLines = len(arrayOfLines)
#初始化返回数组及列表
returnMat = zeros((numberOfLines,3))
classLabelVector = []
index = 0
for line in arrayOfLines:
#截取掉每一行的回车符
line = line.strip()
#将一行数据根据制表符分割成包含多个元素(特征)的列表
listFromLine = line.split('\t')
#分割后的特征数据列表存入待返回的numpy数组
returnMat[index,:] = listFromLine[0:3]
#将文件每一行最后一列的数据存入待返回的分类标签列表
classLabelVector.append(int(listFromLine[-1]))
#控制待返回的numpy数组进入下一行
index+=1
return returnMat,classLabelVector
#特征变量归一化
def autoNorm(dataSet):
#取出每一列的最小值,即每一个特征的最小值
minVals = dataSet.min(0)
#取出每一列的最大值,即每一个特征的最大值
maxVals = dataSet.max(0)
#每一个特征变量的变化范围
ranges = maxVals - minVals
#初始化待返回的归一化特征数据集
normDataSet = zeros(shape(dataSet))
#特征数据集行数,即样本个数
m = dataSet.shape[0]
#利用tile()函数构造与原特征数据集同大小的矩阵,并进行归一化计算
normDataSet = dataSet - tile(minVals,(m,1))
normDataSet = normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals
#分类器测试
def datingClassTest():
#给定用于测试分类器的样本比例
hoRatio = 0.10
#调用文本数据解析函数
datingDataMat,datingLabels = file2matrix('F:/programming tools/datingTestSet2.txt')
#调用特征变量归一化函数
normMat,ranges,minVals = autoNorm(datingDataMat)
#归一化的特征数据集行数,即样本个数
m = normMat.shape[0]
#用于测试分类器的测试样本个数
numTestVecs = int(m*hoRatio)
#初始化分类器犯错样本个数
errorCount = 0.0
for i in range(numTestVecs):
#以测试样本作为输入,测试样本之后的样本作为训练样本,对测试样本进行分类
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
#对比分类器对测试样本预测的类别和其真实类别
print("the classifier came back with: %d,the real answer is: %d" % (classifierResult,datingLabels[i]))
#统计分类出错的测试样本数
if (classifierResult != datingLabels[i]):
errorCount+=1.0
#输出分类器错误率
print("the total error rate is: %f" % (errorCount/float(numTestVecs)))
#约会网站对新输入分类
def classifyPerson():
#定义一个存储了三个字符串的列表,分别对应不喜欢,一般喜欢,很喜欢
resultList = ['not at all','in small dose','in large dose']
#用户输入三个特征变量,并将输入的字符串类型转化为浮点型
ffMiles = float(input("frequent flier miles earned per year:"))
percentats = float(input("percentage of time spent playing video games:"))
iceCream = float(input("liters of ice cream consumed per year:"))
#调用文本数据解析函数
datingDataMat,datingLabels = file2matrix('F:\programming tools\datingTestSet2.txt')
#调用特征变量归一化函数
normMat,ranges,minVals = autoNorm(datingDataMat)
#将输入的特征变量构造成特征数组(矩阵)形式
inArr = array([ffMiles,percentats,iceCream])
#调用kNN简单实现函数
classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
#将分类结果由数字转换为字符串
print("You will probably like this person",resultList[classifierResult - 1])
三.详细解读
我们在前面kNN的简单实施代码模块的基础上继续添加需要的函数和方法。
kNN的核心实现代码前面已给出:机器学习实战k-邻近算法(kNN)简单实施代码解读
新增了4个函数或方法,分别是文本文件解析函数file2matrix,特征变量归一化函数autoNorm,分类器测试方法datingClassTest以及分类器最终对新输入进行分类的方法classifyPerson。
1.文本文件解析函数file2matrix
接受一个参数,即待解析的文件名,注意传入的时候要带上后缀名,如:xxx.txt,否则会说该目录下没有指定文件。
★arrayOfLines = fr.readlines()
按行读取整个文件的内容,返回一个列表,文件的每一行数据以字符串的形式作为列表的一个元素,故numberOfLines = len(arrayOfLines)求出列表元素的数目,也就是文本一共有多少行数据。
python中需要注意.read(),.readline()和.readlines()的区别,以如下test.txt为例

①.read()是一次读取整个文件的内容,并把 文件内容放到一个字符串变量中 。如下:

②.readline()每次读取文件的一行,将读取到的一行内容放到一个字符串变量中,再次调用时会继续读下一行。如下:

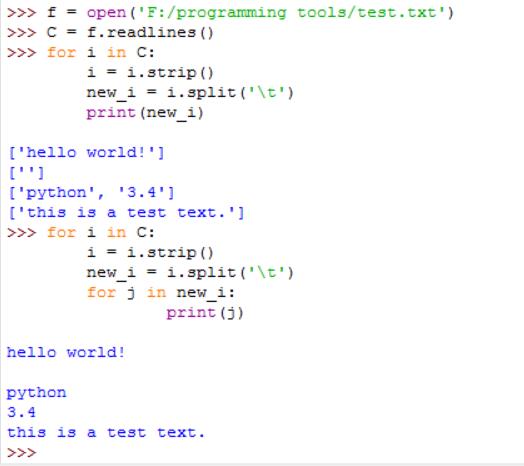
③.readlines()每次按行读取整个文件内容,将读取到的内容放到一个列表中,文件每一行内容以字符串的形式作为列表的一个元素。如下:

注意:hello world下方有三行空行的原因是文件每行结尾都有一个换行符(除了最后一行),再加上print()本身输出一个元素后会自动换行。
★line = line.strip()
按行读取文本内容时,截取掉每一行的回车符。如下:

★listFromLine = line.split('\t')
将一行数据根据制表符分割成包含一个或多个元素(特征)的列表,例如如下的test文件中第三行python与3.4之间存在制表符,则这一行返回的列表包含两个元素,每个元素都是一个字符串,其几行因为没有制表符,故返回的是只含有一个元素的列表。对列表直接print的结果和对列表按元素print的结果也是不同的。应用这条语句的目的是把文件中每行以制表符分隔开的多个特征数据分别作为一个元素提取到列表中。
★returnMat[index,:] = listFromLine[0:3]
将分割后的特征数据列表存入待返回的numpy数组。这里只存前3列的数据,因为前3列代表特征变量,最后一列是分类标签。
★classLabelVector.append(int(listFromLine[-1]))
将文件每一行最后一列的数据存入待返回的分类标签列表,我们提取到的是字符串形式的标签,要转换为整型后再存入代表分类标签的列表。
2.特征变量归一化函数autoNorm
使用特征变量归一化的目的是在计算欧式距离时防止那些数字差值很大的特征变量对计算结果的影响太大,尽量维持特征的等权重,不让某一个特征对分类结果的影响明显大于其他特征。利用下面的公式将任意取值范围的特征值转换为0到1区间内的值:
newValue = (oldValue-min) / (max-min) (☆)
★minVals = dataSet.min(0)
取出每一列的最小值,即每一个特征的最小值。
★maxVals = dataSet.max(0)
取出每一列的最大值,即每一个特征的最大值。.min(0)和.max(0)里的0代表按列取最小值和最大值,若要取出每一行的最小或最大值则要使用.min(1)或.max(1)。
★normDataSet = zeros(shape(dataSet))
初始化待返回的归一化特征数据集,shape以一个元组的形式返回dataSet的行数m和列数3。zero((m,3))将其初始化为一个m行3列的全0矩阵。
★normDataSet = dataSet - tile(minVals,(m,1))
★normDataSet = normDataSet/tile(ranges,(m,1))
★normDataSet = normDataSet/tile(ranges,(m,1))
利用tile()函数构造与原特征数据集同大小的矩阵,并利用(☆)式进行归一化计算。
关于tile()的用法,前面已经提到,这里再给出链接,numpy库tile用法。
3.分类器测试函数datingClassTest
将一些分类标签已知的测试样本输入分类器,比较分类器的输出结果和样本的实际分类标签,以测试分类器的错误率。错误率=对测试样本分类出错的个数/测试样本总数。
★hoRatio = 0.10
给定用于测试分类器的样本比例为0.1,另外90%的样本作为训练样本。
★datingDataMat,datingLabels = file2matrix('F:/programming tools/datingTestSet2.txt')
调用文本数据解析函数,得到特征变量和分类标签。
★normMat,ranges,minVals = autoNorm(datingDataMat)
调用特征变量归一化函数,得到归一化的特征变量,每一个特征的范围,每一个特征的最小值。
★numTestVecs = int(m*hoRatio)
求出用于测试分类器的测试样本个数,因为样本个数必须为整数,故使用int取整。
★classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
以测试样本作为输入,测试样本之后的样本作为训练样本,对测试样本进行分类。这里调用了kNN简单实现函数classify0。
normMat[i,:]为当前的测试样本归一化的输入特征,normMat[numTestVecs:m,:]为训练样本归一化的特征矩阵,datingLabels[numTestVecs:m]为与之对应的训练样本的分类标签向量,3代表k的取值,实际操作时可以自行更改。
4.约会网站预测函数classifyPerson
★resultList = ['not at all','in small dose','in large dose'] 定义一个存储了三个字符串的列表,分别对应不喜欢,一般喜欢,很喜欢
★ffMiles = float(input("frequent flier miles earned per year:"))
percentats = float(input("percentage of time spent playing video games:"))
iceCream = float(input("liters of ice cream consumed per year:"))
percentats = float(input("percentage of time spent playing video games:"))
iceCream = float(input("liters of ice cream consumed per year:"))
注意这里用户输入的东西会被当成是字符串,所以一定要转换为我们需要的类型。
★inArr = array([ffMiles,percentats,iceCream])
将输入的特征变量构造成特征数组(矩阵)形式。
★classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
调用kNN简单实现函数对新的输入进行分类,注意要将输入特征归一化。
★print("You will probably like this person",resultList[classifierResult - 1])
将分类结果由数字转换为字符串。
四.运行结果
