机器学习之模型融合(Stacking、Blending。。。。)
使用介绍
简单快速:平均、投票
全面精准:Stacking、Blending
一、平均:
简单平均法: 简单加权平均,结果直接融合 求多个预测结果的平均值。pre1-pren分别是n组模型预测出来的结果,将其进行加权融
pre = (pre1 + pre2 + pre3 +...+pren )/n
加权平均法: 加权平均法 一般根据之前预测模型的准确率,进行加权融合,将准确性高的模型赋予更高的权重。
pre = 0.3*pre1 + 0.3*pre2 + 0.4*pre3
二、投票:
少数服从多数原则

# 简单投票:模型数为奇数,根据少数服从多数来定最终结果
from xgboost import XGBClassifier
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.model_selection import train_test_split
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
# 鸢尾花数据集为三类,去掉第三类,当作二分类数据集
X, y = iris.data[:100, 1:3], iris.target[:100]
# 以默认的0.25作为分割比例进行分割(训练集:测试集=3:1)
x_train,x_test, y_train, y_test = train_test_split(X, y,test_size=0.25,random_state=2023)
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=4, min_child_weight=2, subsample=0.7,objective='binary:logistic')
vclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('xgb', clf3)],voting='hard')
vclf = vclf.fit(x_train,y_train)
print(f'准确率:{vclf.score(x_test,y_test)}')
三、综合:
排序融合
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from mlxtend.plotting import plot_learning_curves
from mlxtend.plotting import plot_decision_regions
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
# 鸢尾花数据集为三类,去掉第三类,当作二分类数据集
X, y = iris.data[:100, 1:3], iris.target[:100]
#切分一部分数据作为测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2023)
# 存储三个模型所预测的结果
pre = np.zeros((x_test.shape[0],3))
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
clf = [clf1,clf2,clf3]
for i,c in enumerate(clf):
c.fit(x_train,y_train)
pre[:,i] = c.predict_proba(x_test)[:,1]
from scipy.stats import rankdata
print("Rank averaging on", len(clf), "model predictions")
rank_predictions = np.zeros((pre.shape[0],1))
for i in range(len(clf)):
rank_predictions[:, 0] = np.add(rank_predictions[:, 0], rankdata(pre[:, i].reshape(-1,1))/rank_predictions.shape[0])
# Rank averaging后,类别为1的概率
rank_predictions /= len(clf)
log融合
四、Stacking
构建多层模型,并利用多个模型的预测结果组成新的训练特征,再通过简单的LR模型训练预测。
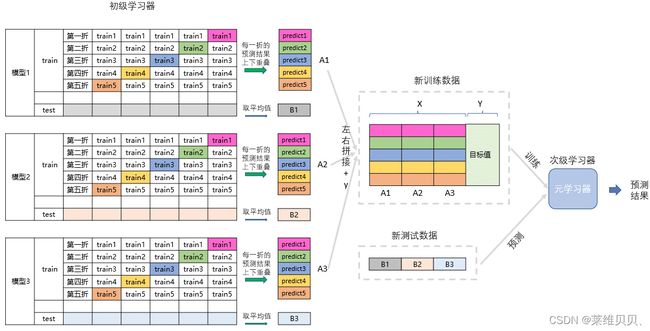
Stacking算法理论介绍
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from mlxtend.plotting import plot_learning_curves
from mlxtend.plotting import plot_decision_regions
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3], meta_classifier=lr)
label = ['KNN', 'Random Forest', 'Naive Bayes', 'Stacking Classifier']
clf_list = [clf1, clf2, clf3, sclf]
fig = plt.figure(figsize=(10,8))
gs = gridspec.GridSpec(2, 2)
grid = itertools.product([0,1],repeat=2)
clf_cv_mean = []
clf_cv_std = []
for clf, label, grd in zip(clf_list, label, grid):
scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))
clf_cv_mean.append(scores.mean())
clf_cv_std.append(scores.std())
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(label)
plt.show()
五、Blending
选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测。
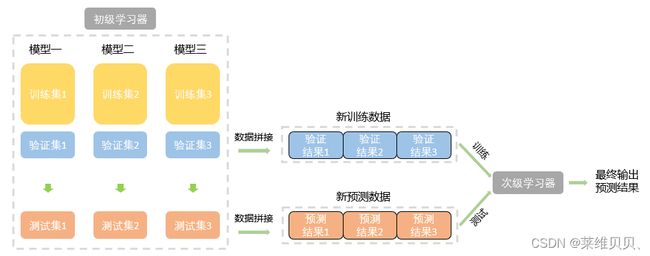
Blending算法理论介绍
import warnings
warnings.filterwarnings('ignore')
import itertools
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.model_selection import cross_val_score, train_test_split
from mlxtend.plotting import plot_learning_curves,plot_decision_regions
from sklearn.metrics import roc_curve, auc, roc_auc_score
# 以python自带的鸢尾花数据集为例
iris = datasets.load_iris()
# 鸢尾花数据集为三类,去掉第三类,当作二分类数据集
X, y = iris.data[:100, 1:3], iris.target[:100]
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=4, min_child_weight=2, subsample=0.7,objective='binary:logistic')
#模型融合中基学习器
clfs = [clf1,clf2,clf3]
#切分一部分数据作为测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=2023)
#切分训练数据集为d1,d2两部分
X_d1, X_d2, y_d1, y_d2 = train_test_split(x_train, y_train, test_size=0.5, random_state=2023)
dataset_d1 = np.zeros((X_d2.shape[0], len(clfs)))
dataset_d2 = np.zeros((x_test.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
#依次训练各个单模型
clf.fit(X_d1, y_d1)
y_submission = clf.predict_proba(X_d2)[:, 1]
dataset_d1[:, j] = y_submission
#对于测试集,直接用这k个模型的预测值作为新的特征。
dataset_d2[:, j] = clf.predict_proba(x_test)[:, 1]
print("val auc Score: %f" % roc_auc_score(y_test, dataset_d2[:, j]))
#融合使用的模型
clf = GradientBoostingClassifier()
clf.fit(dataset_d1, y_d2)
y_submission = clf.predict_proba(dataset_d2)[:, 1]
print("Val auc Score of Blending: %f" % (roc_auc_score(y_test, y_submission)))
参考:
https://tianchi.aliyun.com/notebook/129323
sklearn集成学习之VotingClassifier