Sigmoid型函数、ReLU函数
以下内容主要来自邱锡鹏老师的《神经网络与深度学习》第四章和博客的整理。
1 Sigmoid型函数
Sigmoid型函数是指一类S型曲线函数,为两端饱和函数。常用的Sigmoid型函数有Logistic函数和Tanh函数。
对于函数 ( x ) (x) f(x),若 x → − ∞ x \to −\infty x→−∞ 时,其导数 ′ ( ) → 0 '()\to 0 f′(x)→0,则称其为左饱和。若 x → + ∞ x \to +\infty x→+∞ 时,其导数 ′ ( x ) → 0 '(x) \to 0 f′(x)→0,则称其为右饱和。当同时满足左、右饱和时,就称为两端饱和。
1.1 Logistic函数
Logistic函数定义为
σ ( x ) = 1 1 + e x p ( − x ) (1.1) \sigma(x) = \frac{1}{1+exp(-x)} \tag{1.1} σ(x)=1+exp(−x)1(1.1)
其导数为
σ ′ ( x ) = 0 − 1 ⋅ ( − e − x ) ( 1 + e − x ) 2 = e − x ( 1 + e − x ) 2 = e − x ( 1 + e − x ) ⋅ 1 ( 1 + e − x ) = 1 + e − x − 1 ( 1 + e − x ) ⋅ σ ( x ) = ( 1 − σ ( x ) ) ⋅ σ ( x ) (1.2) \begin{aligned}\sigma^{′}(x) &=\frac{0-1·(-e^{-x})}{(1+e^{-x})^{2}}\\&=\frac{e^{-x}}{(1+e^{-x})^{2}}\\&=\frac{e^{-x}}{(1+e^{-x})}·\frac{1}{(1+e^{-x})}\\&=\frac{1+e^{-x}-1}{(1+e^{-x})}·\sigma(x)\\&=(1-\sigma(x))·\sigma(x)\end{aligned}\tag{1.2} σ′(x)=(1+e−x)20−1⋅(−e−x)=(1+e−x)2e−x=(1+e−x)e−x⋅(1+e−x)1=(1+e−x)1+e−x−1⋅σ(x)=(1−σ(x))⋅σ(x)(1.2)
Logistic函数可以看成是一个“挤压”函数,把一个实数域的输入“挤压”到(0, 1)。当输入值在0附近时,Sigmoid型函数近似为线性函数;当输入值靠近两端时,对输入进行抑制。输入越小,越接近于0;输入越大,越接近于1。这样的特点也和生物神经元类似,对一些输入会产生兴奋(输出为1),对另一些输入产生抑制(输出为0)。和感知器使用的阶跃激活函数相比,Logistic函数是连续可导的,其数学性质更好。
因为Logistic函数的性质,使得装备了Logistic激活函数的神经元具有以下两点性质:1)其输出直接可以看作概率分布,使得神经网络可以更好地和统计学习模型进行结合。2)其可以看作一个软性门(Soft Gate),用来控制其他神经元输出信息的数量。
下图左边是Logistic函数,右边是该函数的导数,由图像可发现:当输入值大于10或者小于-10时局部梯度都是0,非常不利于网络的梯度流传递。

Logistic函数作为激活函数的特点:优点:平滑、易于求导。
缺点:
- 激活函数计算量大(在正向传播和反向传播中都包含幂运算和除法);
- 反向传播求误差梯度时,求导涉及除法;
- σ ( x ) \sigma(x) σ(x) 导数取值范围是[0, 0.25],当 σ ( x ) \sigma(x) σ(x) 中 x x x 较大或较小时,导数接近0,而反向传播的数学依,据是微积分求导的链式法则,当前层的导数需要之前各层导数的乘积,几个小数的相乘,结果会很接近0; σ ( x ) \sigma(x) σ(x) 导数的最大值是0.25,这意味着导数在每一层至少会被压缩为原来的1/4,通过两层后被变为1/16,……,通过10层后为 1 / 1048576 ≈ 0.000000954 1/1048576\approx 0.000000954 1/1048576≈0.000000954,第10层的误差相对第一层卷积的参数[公式]的梯度将是一个非常小的值,这就是所谓的“梯度消失”(即Gradient Vanishing)。请注意这里是“至少”,导数达到最大值这种情况还是很少见的。
- σ ( x ) \sigma(x) σ(x) 的输出恒大于0(不是0均值,即zero-centered),这会导致模型训练的收敛速度变慢;也会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入,随着网络的加深,会改变数据的原始分布。
详细数学分析见文章:http://neuralnetworksanddeeplearning.com/chap5.html
1.2 Tanh函数
Tanh函数也是一种Sigmoid型函数。其定义为
t a n h ( x ) = e x p ( x ) − e x p ( − x ) e x p ( x ) + e x p ( − x ) (1.3) tanh(x)=\frac{exp(x)-exp(-x)}{exp(x)+exp(-x)}\tag{1.3} tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x)(1.3)
Tanh函数可以看作放大并平移的Logistic函数,其值域是(−1, 1)。
t a n h ( x ) = 2 σ ( 2 x ) − 1 (1.4) tanh(x)=2\sigma(2x)-1\tag{1.4} tanh(x)=2σ(2x)−1(1.4)
下图给出了Logistic函数和Tanh函数的形状。Tanh函数的输出是零中心化的(Zero-Centered),而Logistic函数的输出恒大于0。非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。

下图是Tanh函数的导数,与Logistic类似,局部梯度特性不利于网络梯度流的反向传递。

tanh函数作为激活函数的特点:
tanh函数的输出范围为(-1, 1),解决了Logistic函数的不是zero-centered输出问题;但幂运算的问题仍然存在;tanh导数范围在(0, 1)之间,相比 σ ( x ) \sigma(x) σ(x) 的(0, 0.25),梯度消失(gradient vanishing)问题会得到缓解,但仍然还会存在。
1.3 Hard-Logistic 函数
Logistic函数和Tanh函数都是Sigmoid型函数,具有饱和性,但是计算开销较大。因为这两个函数都是在中间(0 附近)近似线性,两端饱和。因此,这两个函数可以通过分段函数来近似。
以Logistic函数 σ ( x ) \sigma(x) σ(x)为例,其导数为 σ ′ ( x ) = σ ( ) ( 1 − σ ( ) ) \sigma{'}(x) = \sigma()(1 − \sigma()) σ′(x)=σ(x)(1−σ(x))。Logistic函数在0 附近的一阶泰勒展开(Taylor expansion)为
g l ( x ) ≈ σ ( 0 ) + x × σ ′ ( 0 ) = 0.25 x + 0.5 (1.5) g_l(x)\approx\sigma(0)+x \times \sigma{'}(0)\\ =0.25x+0.5\tag{1.5} gl(x)≈σ(0)+x×σ′(0)=0.25x+0.5(1.5)
这样Logistic函数可以用分段函数hard-logistic()来近似。
h a r d − l o g i s i t c ( x ) = { 1 g l ( x ) ≥ 1 g l 0 ≤ g l ( x ) ≤ 1 0 g l ( x ) ≤ 1 = m a x ( m i n ( g l ( x ) , 1 ) ) = m a x ( m i n ( 0.25 x + 0.5 , 1 ) , 0 ) (1.6) \begin{aligned} hard-logisitc(x) &= \begin{cases} 1 & g_l(x) \geq 1 \\ g_l & 0 \leq g_l(x) \leq 1 \\ 0 & \text g_l(x) \leq 1 \end{cases} \\ &= max(min(g_l(x), 1)) \\ &= max(min(0.25x+0.5, 1), 0)\end{aligned}\tag{1.6} hard−logisitc(x)=⎩⎪⎨⎪⎧1gl0gl(x)≥10≤gl(x)≤1gl(x)≤1=max(min(gl(x),1))=max(min(0.25x+0.5,1),0)(1.6)
1.4 Hard-Tanh 函数
同样,Tanh 函数在0附近的一阶泰勒展开为
g t ( x ) ≈ t a n h ( 0 ) + x × t a n h ′ ( 0 ) = x (1.7) \begin{aligned} g_t(x) &\approx tanh(0) + x \times tanh{'}(0) \\ &= x\end{aligned}\tag{1.7} gt(x)≈tanh(0)+x×tanh′(0)=x(1.7)
这样Tanh 函数也可以用分段函数hard-tanh()来近似。
h a r d − t a n h ( x ) = m a x ( m i n ( g t ( x ) , 1 ) , − 1 ) = m a x ( m i n ( x , 1 ) , − 1 ) (1.8) \begin{aligned}hard-tanh(x) &= max(min(g_t(x), 1), -1)\\& = max(min(x, 1), -1)\end{aligned}\tag{1.8} hard−tanh(x)=max(min(gt(x),1),−1)=max(min(x,1),−1)(1.8)
下图给出了Hard-Logistic函数和Hard-Tanh函数的形状。

2 ReLU函数
ReLU(Rectified Linear Unit,修正线性单元),也叫Rectifier函数,是目前深度神经网络中经常使用的激活函数。ReLU实际上是一个斜坡(ramp)函数,定义为
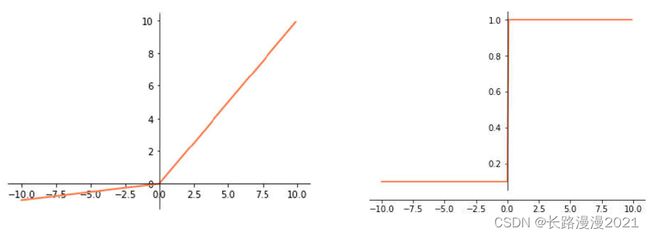
R e L U ( x ) = { x if x > 0 0 if x ≤ 0 = m a x ( 0 , x ) (2.1) \begin{aligned} ReLU(x) &= \begin{cases} x & \text{if x > 0} \\ 0 & \text{if x ≤ 0} \end{cases} \\&= max(0, x) \end{aligned}\tag{2.1} ReLU(x)={x0if x > 0if x ≤ 0=max(0,x)(2.1)
优点: 采用ReLU的神经元只需要进行加、乘和比较的操作,计算上更加高效。ReLU函数也被认为具有生物学合理性(Biological Plausibility),比如单侧抑制、宽兴奋边界(即兴奋程度可以非常高)。在生物神经网络中,同时处于兴奋状态的神经元非常稀疏。人脑中在同一时刻大概只有1% ∼ 4% 的神经元处于活跃状态。Sigmoid型激活函数会导致一个非稀疏的神经网络,而ReLU却具有很好的稀疏性,大约50% 的神经元会处于激活状态。
在优化方面,相比于Sigmoid型函数的两端饱和,ReLU函数为左饱和函数,且在 > 0 > 0 x>0 时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。
缺点: ReLU函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率。此外,ReLU神经元在训练时比较容易“死亡”。在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个ReLU神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远不能被激活。这种现象称为死亡ReLU问题(Dying ReLU Problem),并且也有可能会发生在其他隐藏层。
下图分别是ReLU函数图像和导函数图像,可以发现:当输入大于0时,局部梯度永远不会为0,比较有利于梯度流的传递。

ReLU函数作为激活函数的特点:优点:
- 解决了梯度消失问题 (在正区间)
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度远快于
Logistic和Tanh
缺点:
ReLU的输出不是零中心化Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) 学习率太大导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将学习率设置太大或使用adagrad等自动调节学习率的算法。ReLU在 x > 0 x>0 x>0 下,导数为常数1的好处就是在链式法则中不会出现梯度消失,但梯度下降的强度就完全取决于权值的乘积,这样就可能会出现梯度爆炸问题。解决这类问题:一是控制权值,让它们在(0,1)范围内;二是做梯度裁剪,控制梯度下降强度,如 R e L U ( x ) = m i n ( 6 , m a x ( 0 , x ) ) ReLU(x)=min(6, max(0,x)) ReLU(x)=min(6,max(0,x))
在实际使用中,为了避免上述情况,有几种ReLU的变种也会被广泛使用,如下:
2.1 带泄露的ReLU
带泄露的ReLU(Leaky ReLU)在输入 < 0 < 0 x<0 时,保持一个很小的梯度 γ \gamma γ。这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活。带泄露的ReLU的定义如下:
L e a k y R e L U ( x ) = { x if x > 0 γ x if x ≤ 0 = m a x ( 0 , x ) + γ m i n ( 0 , x ) (2.2) \begin{aligned} LeakyReLU(x) &= \begin{cases} x & \text{if x > 0} \\ \gamma x & \text{if x ≤ 0} \end{cases} \\&= max(0, x) + \gamma min(0, x) \end{aligned}\tag{2.2} LeakyReLU(x)={xγxif x > 0if x ≤ 0=max(0,x)+γmin(0,x)(2.2)
其中 γ \gamma γ 是一个很小的常数,比如0.01。当 γ < 1 \gamma < 1 γ<1 时,带泄露的ReLU也可以写为
L e a k y R e L U ( x ) = m a x ( x , γ x ) (2.3) LeakyReLU(x) = max(x, \gamma x) \tag{2.3} LeakyReLU(x)=max(x,γx)(2.3)
相当于是一个比较简单的maxout单元。
当 γ = 0.01 \gamma=0.01 γ=0.01 时, L e a k y R e L U ( x ) = m a x ( x , 0.01 x ) LeakyReLU(x) = max(x, 0.01x) LeakyReLU(x)=max(x,0.01x),函数和导函数的图像分别如下,可以发现:基本没有“死区”, 也就是梯度永远不会为0。之所以说“基本”,是因为函数在0处没有导数。
理论上来讲,
Leaky ReLU有ReLU的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明Leaky ReLU总是好于ReLU。
2.2 带参数的ReLU
带参数的ReLU(Parametric ReLU,PReLU)引入一个可学习的参数,不同神经元可以有不同的参数。对于第个神经元,其PReLU的定义为
P R e L U i ( x ) = { x if x > 0 γ i x if x ≤ 0 = m a x ( 0 , x ) + γ i m i n ( 0 , x ) (2.4) \begin{aligned} PReLU_i(x) &= \begin{cases} x & \text{if x > 0} \\ \gamma_i x & \text{if x ≤ 0} \end{cases} \\&= max(0, x) + \gamma_i min(0, x) \end{aligned}\tag{2.4} PReLUi(x)={xγixif x > 0if x ≤ 0=max(0,x)+γimin(0,x)(2.4)
其中 γ i {\gamma}_i γi 为 x ≤ 0 x ≤ 0 x≤0 时函数的斜率。因此,PReLU是非饱和函数。如果 γ i = 0 {\gamma}_i=0 γi=0,那么PReLU就退化为ReLU。如果 γ i {\gamma}_i γi 为一个很小的常数,则PReLU可以看作带泄露的ReLU。PReLU可以允许不同神经元具有不同的参数,也可以一组神经元共享一个参数。
2.3 ELU 函数
ELU(Exponential Linear Unit,指数线性单元)是一个近似的零中心化的非线性函数,由Djork等人提出,被证实有较高的噪声鲁棒性,其定义为
E L U ( x ) = { x if x > 0 γ ( e x p ( x ) − 1 ) if x ≤ 0 = m a x ( 0 , x ) + m i n ( 0 , γ ( e x p ( x ) − 1 ) ) (2.5) \begin{aligned} ELU(x) &= \begin{cases} x & \text{if x > 0} \\ \gamma{(exp(x)-1)} & \text{if x ≤ 0} \end{cases} \\&= max(0, x) + min(0, \gamma{(exp(x)-1)}) \end{aligned}\tag{2.5} ELU(x)={xγ(exp(x)−1)if x > 0if x ≤ 0=max(0,x)+min(0,γ(exp(x)−1))(2.5)
其中 γ ≥ 0 \gamma ≥ 0 γ≥0 是一个超参数,决定 x ≤ 0 x ≤ 0 x≤0 时的饱和曲线,并调整输出均值在0 附近。
ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,还不会有Dead ReLU问题,输出的均值接近0,zero-centered。但缺点在于需要计算指数,计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。该函数和导数的图像如下图所示:

2.4 Softplus 函数
Softplus函数可以看作Rectifier函数的平滑版本,其定义为
S o f t p l u s ( x ) = l o g ( 1 + e x p ( x ) ) (2.6) Softplus(x) = log(1+exp(x))\tag{2.6} Softplus(x)=log(1+exp(x))(2.6)
Softplus函数其导数刚好是Logistic函数。Softplus函数虽然也具有单侧抑制、宽兴奋边界的特性,却没有稀疏激活性。

激活函数尽量选择
ReLU函数或者Leakly ReLU函数,相对于Logistic/tanh,ReLU函数或者Leakly ReLU函数会让梯度流更加顺畅,训练过程收敛得更快,但要注意初始化和学习率的设置。
3 其他函数
3.1 Swish 函数
Swish函数是一种自门控(Self-Gated)激活函数,定义为
s w i s h ( x ) = x σ ( β x ) (3.1) swish(x) = x\sigma(\beta x)\tag{3.1} swish(x)=xσ(βx)(3.1)
其中 σ ( ⋅ ) \sigma(⋅) σ(⋅) 为Logistic函数, β \beta β 为可学习的参数或一个固定超参数。 σ ( ⋅ ) ∈ ( 0 , 1 ) \sigma(⋅)\in (0, 1) σ(⋅)∈(0,1) 可以看作一种软性的门控机制。当 σ ( β x ) \sigma(\beta x) σ(βx) 接近于1 时,门处于“开”状态,激活函数的输出近似于 x x x 本身;当 σ ( β x ) \sigma(\beta x) σ(βx) 接近于0 时,门的状态为“关”,激活函数的输出近似于0。
下图给出了Swish函数的示例

当 β = 0 \beta = 0 β=0 时,Swish函数变成线性函数 / 2 /2 x/2。当 β = 1 \beta = 1 β=1 时,Swish函数在 > 0 > 0 x>0 时近似线性,在 < 0 < 0 x<0 时近似饱和,同时具有一定的非单调性。当 β → + ∞ \beta \to +\infty β→+∞ 时, σ ( β x ) \sigma(\beta x) σ(βx) 趋向于离散的0-1函数,Swish函数近似为ReLU函数。因此,Swish函数可以看作线性函数和ReLU函数之间的非线性插值函数,其程度由参数 β \beta β 控制。
3.2 GELU 函数
GELU(Gaussian Error Linear Unit,高斯误差线性单元)也是一种通过门控机制来调整其输出值的激活函数,和Swish函数比较类似。
G E L U ( x ) = x P ( X ≤ x ) (3.2) GELU(x) = xP(X \leq x)\tag{3.2} GELU(x)=xP(X≤x)(3.2)
其中 ( ≤ ) ( ≤ ) P(X≤x) 是高斯分布 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2) 的累积分布函数,其中 μ , σ \mu, \sigma μ,σ 为超参数,一般设 μ = 0 , σ = 1 \mu = 0, \sigma = 1 μ=0,σ=1 即可。由于高斯分布的累积分布函数为S型函数,因此GELU函数可以用Tanh函数或Logistic函数来近似,
G E L U ( x ) ≈ 0.5 x ( 1 + t a n h ( π 2 ( x + 0.044715 x 3 ) ) 或 G E L U ( x ) ≈ x σ ( 1.702 x ) (3.3) GELU(x) \approx 0.5x(1+tanh(\sqrt{\frac{\pi}{2}}(x+0.044715x^3)) \\或 GELU(x) \approx x\sigma(1.702x)\tag{3.3} GELU(x)≈0.5x(1+tanh(2π(x+0.044715x3))或GELU(x)≈xσ(1.702x)(3.3)
当使用Logistic函数来近似时,GELU相当于一种特殊的Swish函数.
3.3 Maxout 单元
Maxout单元也是一种分段线性函数。Sigmoid型函数、ReLU等激活函数的输入是神经元的净输入 z,是一个标量.而Maxout单元的输入是上一层神经元的全部原始输出,是一个向量 = [ x 1 ; x 2 ; ⋯ ; x ] \pmb{} = [x_1; x_2;\cdots; x_] xxx=[x1;x2;⋯;xD]。
每个Maxout单元有 K 个权重向量 w ∈ R D \pmb{w}_ \in \mathbb{R}^{D} wwwk∈RD 和偏置 ( 1 ≤ ≤ ) _ (1 ≤ ≤ ) bk(1≤k≤K)。对于输入 x,可以得到 K 个净输入 _ zk, 1 ≤ ≤ 1 ≤ ≤ 1≤k≤K。
z k = w k T x + b k (3.4) z_k = \pmb{w}^T_k\pmb{x} + b_k\tag{3.4} zk=wwwkTxxx+bk(3.4)
其中 = [ , 1 , ⋯ , , ] T \pmb{}_ = [_{,1},\cdots , _{,}]^T wwwk=[wk,1,⋯,wk,D]T 为第 k k k 个权重向量。
Maxout单元的非线性函数定义为
m a x o u t ( x ) = m a x ( z k ) k ∈ [ 1 , K ] (3.5) maxout(x) = \underset{k\in[1, K]}{max(z_k)}\tag{3.5} maxout(x)=k∈[1,K]max(zk)(3.5)
Maxout单元不单是净输入到输出之间的非线性映射,而是整体学习输入到输出之间的非线性映射关系。Maxout激活函数可以看作任意凸函数的分段线性近似,并且在有限的点上是不可微的。
4 小结
深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
Sigmoid和tanh的特点是将输出限制在(0,1)和(-1,1)之间,说明Sigmoid和tanh适合做概率值的处理,例如LSTM中的各种门;而ReLU就不行,因为ReLU无最大值限制,可能会出现很大值。同样,根据ReLU的特征,Relu适合用于深层网络的训练,而Sigmoid和tanh则不行,因为它们会出现梯度消失。

为什么在
CNN等结构中将原先的sigmoid、tanh换成ReLU可以取得比较好的效果?为什么在RNN中,将tanh换成ReLU不能取得类似的效果?详细解答,请阅读:RNN 中为什么要采用 tanh,而不是 ReLU 作为激活函数?
参考
- 神经网络与深度学习——第四章 前馈神经网络:https://nndl.github.io/nndl-book.pdf
- 激活函数(ReLU, Swish, Maxout) :https://www.cnblogs.com/makefile/p/activation-function.html
- 深度学习的activation function:https://zhuanlan.zhihu.com/p/25110450
- 常用激活函数(激励函数)理解与总结:https://blog.csdn.net/tyhj_sf/article/details/79932893
- 激活函数-面面观(Activation Function):https://blog.csdn.net/cyh_24/article/details/50593400
- 深度学习领域最常用的10个激活函数:https://m.thepaper.cn/baijiahao_11444171
- ReLU(Rectified Linear Units)激活函数:https://www.cnblogs.com/neopenx/p/4453161.html
- Maxout Networks:https://arxiv.org/pdf/1302.4389v4.pdf