人工神经网络—梯度下降算法
梯度下降算法
- 1. 回顾
- 2. 思路分析
- 3. 优化网络中待求的参数—梯度下降法
-
- 3.1 梯度下降法的直观描述
- 3.2 梯度下降法的数学描述
- 3.3 多维情况的梯度下降法
- 4. 结尾
- 参考资料
1. 回顾
在上一讲中,我们讲到多层神经网络的结构是由每一层有多个神经元组成的线性结构,加上层与层之间的非线性函数构成。我们同时论证了层与层之间的非线性函数是阶跃函数,那么三层神经网络可以模拟任意的决策函数。然而在实际的应用中,问题是反过来的,我们并不知道决策函数是什么,而是只知道特征空间中一些训练样本和这些训练样本的标签。由于我们不知道决策函数的具体形式,因此我们也无法知道如何表征这个神经网络的结构。
2. 思路分析
我们只能采取另一种思路,即首先假定是某一种结构,然后将一堆训练数据输入到网络中去估计这个网络待求的参数。这两个问题都很复杂,首先假定一个多层神经网络的结构就涉及到不确定的因素,其中最重要的两个因素是
(1)网络有多少层?
(2)每层神经元的个数是多少?
遗憾的是尽管人工神经网络的研究已经有了大半个世纪的历史,但是对上述两个问题却没有标准的答案。我们只能从经验上去说一下设计网络结构的两个准则:
- 如果问题是简单的。
例如像前面学到的分割红细胞和白细胞的问题,如下图所示,在特征空间中,两个类别的区分是明显的,那么一条不是很复杂的曲线就能分开两类,对于这样简单问题,我们设计的神经网络结构也可以简单一点。也就是说神经网络的层数以及每层神经元的个数也可以少一点。

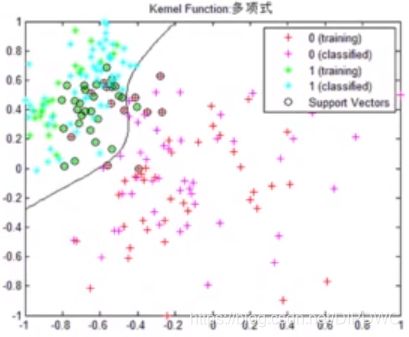

- 如果问题本身是很复杂的
例如人脸识别这样的问题,那么神经网络的层数和每层神经元的个数都需要更多一些,这样神经网络产生的非线性函数才会更加复杂,才更有可能捕捉到训练样本的变化。

另一个方面,网络结构设计和训练样本的数量也有很强的相关性。我们前面讲到,算法模型的复杂度要和训练样本的复杂度相匹配。因此,对于训练样本很多的情况,我们可以增加神经网络的层数和每一层神经元的个数,从而增加神经网络的复杂度,使它与训练的复杂度匹配。而对于训练数据很少的情况,神经网络的复杂度一般不能设置得过高。
上述两个原则并没有直接回答对于某个具体的问题神经网络应该设置多少层,每层神经元的个数应该是多少。在实践中,我们只能通过经验来设置这些重要的参数。如果某一个模型表现得不好,我们就换一个。因此,有人说神经网络参数设置不是科学而是艺术,这也是神经网络这种方法时常被诟病的方面之一。
3. 优化网络中待求的参数—梯度下降法
接下来,我们假定神经网络设置已经确定下来,即神经网络的层数以及每一层神经元的个数已经确定。那么在这样的前提下,我们来看一下如何优化网络中待求的参数,这里还是举两层神经网络的例子,如下图所附的这个例子。

输入 ( X , Y ) (X,Y) (X,Y),其中 X = [ x 1 x 2 ] X= \left[ \begin{matrix} x_1 \\ x_2 \end{matrix} \right] X=[x1x2], Y Y Y是 X X X的标签值(label),即我们希望改变 w w w和 b b b,使得标签值 Y Y Y与实际的网络输出 y y y尽量接近。
这里需要注意的是 Y Y Y 是 X X X 的标签,由训练数据直接给定,而 y y y 是神经网络的输出。在前面一讲中,我们知道 y y y可以写成如下的形式:
a 1 = ω 11 x 1 + ω 12 x 2 + b 1 a_1=ω_{11}x_1+ω_{12}x_2+b_1 a1=ω11x1+ω12x2+b1(第一个神经元)
a 2 = ω 21 x 1 + ω 22 x 2 + b 2 a_2=ω_{21}x_1+ω_{22}x_2+b_2 a2=ω21x1+ω22x2+b2(第二个神经元)
z 1 = φ ( a 1 ) z_1=φ(a_1) z1=φ(a1)(非线性函数)
z 2 = φ ( a 2 ) z_2=φ(a_2) z2=φ(a2)(非线性函数)
y = ω 1 z 1 + ω 2 z 2 + b 3 y=ω_1z_1+ω_2z_2+b_3 y=ω1z1+ω2z2+b3(第三个神经元)
或者我们可以用一个统一的式子来表示:
y = w 1 φ ( ω 11 x 1 + ω 12 x 2 + b 1 ) + w 2 φ ( ω 21 x 1 + ω 22 x 2 + b 2 ) + b 3 (1) y=w_1φ(ω_{11}x_1+ω_{12}x_2+b_1)+w_2φ(ω_{21}x_1+ω_{22}x_2+b_2)+b_3\tag{1} y=w1φ(ω11x1+ω12x2+b1)+w2φ(ω21x1+ω22x2+b2)+b3(1)
我们需要使网络输出的 y y y和标签 Y Y Y尽可能地接近,因此,可以定义目标函数为
M i n i m i z e : E ( w , b ) = E ( X , Y ) [ ( Y − y ) 2 ] (2) Minimize:E(w,b)=E_{(X,Y)}[(Y-y)^2]\tag{2} Minimize:E(w,b)=E(X,Y)[(Y−y)2](2)
其中 E ( X , Y ) E_{(X,Y)} E(X,Y)指的是遍历训练样本及标签的数学期望,这里可以简单的看作是对所有训练样本取平均值。
由于网络输出 y y y是 w , b w,b w,b的非凸函数,因此,我们无法像支持向量机那样求到唯一的全局极值。我们采用梯度下降法(Gradient Descent Method) 来求这个目标函数的局部极值。梯度下降法的做法分为四步:
(1)随机选取 w w w和 b b b的初始值( w ( 0 ) , b ( 0 ) w^{(0)},b^{(0)} w(0),b(0));
(2)应用迭代算法求目标函数的局部极值:
在第n步迭代中, w w w和 b b b的更新公式如下式所示:
w ( n + 1 ) = w ( n ) − α ∂ E ∂ w ∣ w ( n ) , b ( n ) w^{(n+1)}=w^{(n)}-α{\frac{∂E}{∂w}|}_{w^{(n)},b^{(n)}} w(n+1)=w(n)−α∂w∂E∣w(n),b(n)
b ( n + 1 ) = b ( n ) − α ∂ E ∂ b ∣ w ( n ) , b ( n ) b^{(n+1)}=b^{(n)}-α{\frac{∂E}{∂b}|}_{w^{(n)},b^{(n)}} b(n+1)=b(n)−α∂b∂E∣w(n),b(n)
我们来看一下这个公式,首先,这是一个迭代的算法,它和感知器算法是同一个类型,即输入训练数据不断迭代更新 w w w和 b b b,但是这种更新算法和感知器算法有本质的区别。
3.1 梯度下降法的直观描述
我们接下来讲一下梯度下降法主要的数学意思,首先,我们举一个简单的例子,假设目标函数 f ( x ) f(x) f(x)是一个1维函数,如下图所示。
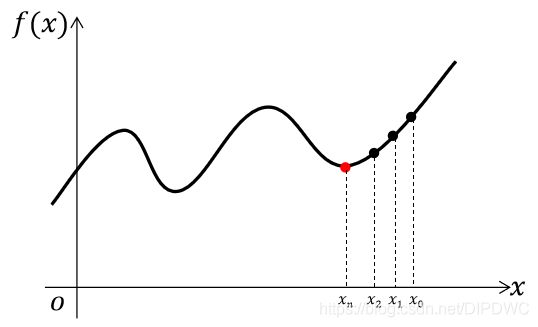
可以看到, f ( x ) f(x) f(x)有好几个极小值,我们用到的梯度下降法是求其中一个局部极小值的算法。梯度下降法在这样的一个1维函数上的步骤如下:
- 首先,随机选取一个点 x 0 x_0 x0。
- 接下来,我们计算 f ( x ) f(x) f(x)在 x 0 x_0 x0这一点的梯度,如图所示,梯度的方向就是( x 0 x_0 x0, f ( x 0 ) f(x_0) f(x0))这个点沿着曲线的切线,我们朝着梯度的负值的方向移动一小步获得 x 1 x_1 x1,即 x 1 = x 0 − α d f d x ∣ x 0 x_1=x_0-α{\frac{df}{dx}|}_{x_0} x1=x0−αdxdf∣x0,那么从图上可以直观地看出 f ( x 1 ) < f ( x 0 ) f(x_1)
- 接下来再求 f ( x ) f(x) f(x)在 x 1 x_1 x1处的导数,继续上述步骤获得 x 2 x_2 x2,也可看出 f ( x 2 ) < f ( x 1 ) f(x_2)
这样一直迭代下去,最后找到局部的极小值,即让 f ( x ) f(x) f(x)的导数为0的谷底。这个过程就像下山一样,我们走到每一步都用导数探索一下周围哪个方向比较低,然后朝较低的方向迈进一小步,如此循环,我们一定可以下到山脚下。

3.2 梯度下降法的数学描述
接下来,我们把上述这种几何的直观用严格的数学来描述:
首先,根据泰勒公式我们有
f ( x 0 + △ x ) = f ( x 0 ) + d f d x ∣ x 0 △ x + o ( △ x ) (3) f(x_0+△x)=f(x_0)+{\frac{df}{dx}|}_{x_0}△x+o(△x)\tag{3} f(x0+△x)=f(x0)+dxdf∣x0△x+o(△x)(3)
如果我们将刚才的那个公式 x 1 = x 0 − α d f d x ∣ x 0 x_1=x_0-α{\frac{df}{dx}|}_{x_0} x1=x0−αdxdf∣x0的值代入上面的式子(3)我们可以得到
f ( x 1 ) = f ( x 0 − α d f d x ∣ x 0 ) = f ( x 0 ) + d f d x ∣ x 0 [ − α d f d x ∣ x 0 ] + o ( △ x ) = f ( x 0 ) − [ α d f d x ∣ x 0 ] 2 + o ( △ x ) < f ( x 0 ) (4) f(x_1)=f(x_0-α{\frac{df}{dx}|}_{x_0})=f(x_0)+{\frac{df}{dx}|}_{x_0}[-α{\frac{df}{dx}|}_{x_0}]+o(△x)=f(x_0)-[α{\frac{df}{dx}|}_{x_0}]^2+o(△x)
可见,如果 α α α是一个足够小的正数,而且 d f d x ∣ x 0 {\frac{df}{dx}|}_{x_0} dxdf∣x0不为0,那么我们将一定有 f ( x 1 ) < f ( x 0 ) f(x_1)
我们把 α α α 叫作学习率(Learning rate),这是人工神经网络中最重要的超参数(hyper parameter)之一,我们需要小心地设置 α α α的值才能保证较快的收敛。
当 α α α 很大时,也就是说,我们下山的步子迈得很大,这样就很容易错过局部极值点。
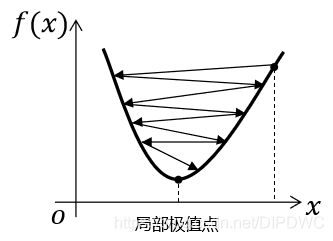
当 α α α 很小时,会出现很久都不能出现收敛局部极值点的情况
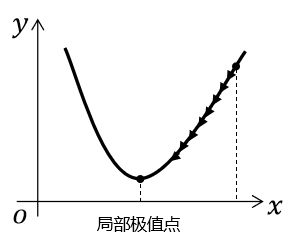
只有当 α α α 设置得恰到好处的时候,才能确保快速地收敛到局部极值点。当然,由于我们并不知道 f ( x ) f(x) f(x)的具体形式,如何把学习率设置到恰到好处,这也是一个没有理论保障的事情。
3.3 多维情况的梯度下降法
我们基于 f ( x ) f(x) f(x) 是一维的情况推导了梯度下降法,我们也可以把这样的关系推广到多维的情况,例如我们要最小化二维函数 E ( w , b ) E(w,b) E(w,b),其中这里的 w , b w,b w,b都是常数,我们可以把这个函数做泰勒展开,将会得到
E ( w 0 + △ w , b 0 + △ b ) = E ( w 0 , b 0 ) + ∂ E ∂ w ∣ ( w 0 , b 0 ) △ w + ∂ E ∂ b ∣ ( w 0 , b 0 ) △ b + o ( w 0 2 + b 0 2 ) (5) E(w_0+△w,b_0+△b)=E(w_0,b_0)+{\frac{∂E}{∂w}|}_{(w_0,b_0)}△w+{\frac{∂E}{∂b}|}_{(w_0,b_0)}△b+o(\sqrt{\ {w_0}^2+{b_0}^2})\tag{5} E(w0+△w,b0+△b)=E(w0,b0)+∂w∂E∣(w0,b0)△w+∂b∂E∣(w0,b0)△b+o( w02+b02)(5)
将
w ( n + 1 ) = w ( n ) − α ∂ E ∂ w ∣ w ( n ) , b ( n ) w^{(n+1)}=w^{(n)}-α{\frac{∂E}{∂w}|}_{w^{(n)},b^{(n)}} w(n+1)=w(n)−α∂w∂E∣w(n),b(n)
b ( n + 1 ) = b ( n ) − α ∂ E ∂ b ∣ w ( n ) , b ( n ) b^{(n+1)}=b^{(n)}-α{\frac{∂E}{∂b}|}_{w^{(n)},b^{(n)}} b(n+1)=b(n)−α∂b∂E∣w(n),b(n)
代入上面式子(5)并化简后可以得到:
E ( w ( n + 1 ) , b ( n + 1 ) ) = E ( w ( n ) , b ( n ) ) − α [ ∂ E ∂ w ∣ w ( n ) , b ( n ) ] 2 − α [ ∂ E ∂ b ∣ w ( n ) , b ( n ) ] 2 + o ( w 0 2 + b 0 2 ) (6) E(w^{(n+1)},b^{(n+1)})=E(w^{(n)},b^{(n)})-α[{\frac{∂E}{∂w}|}_{w^{(n)},b^{(n)}}]^2-α[{\frac{∂E}{∂b}|}_{w^{(n)},b^{(n)}}]^2+o(\sqrt{\ {w_0}^2+{b_0}^2})\tag{6} E(w(n+1),b(n+1))=E(w(n),b(n))−α[∂w∂E∣w(n),b(n)]2−α[∂b∂E∣w(n),b(n)]2+o( w02+b02)(6)
可以看到,同样的道理,如果 ∂ E ∂ w \frac{∂E}{∂w} ∂w∂E和 ∂ E ∂ b \frac{∂E}{∂b} ∂b∂E在 ( w ( n ) , b ( n ) ) (w^{(n)},b^{(n)}) (w(n),b(n))上不全为零,那么就有:
E ( w ( n + 1 ) , b ( n + 1 ) ) < E ( w ( n ) , b ( n ) ) E(w^{(n+1)},b^{(n+1)})
通过合理设置学习率 α α α,我们也可以用上述迭代的方法找到局部的极小值。
刚才的例子是基于目标函数 E E E 是二维的情况,如果目标函数是多余二维的情况,道理也是一样的,有兴趣可自行推导一下。
4. 结尾
这一讲我们主要讲解了人工神经网络的训练策略,包含了两个步骤:
(1)基于实践经验,确定神经网络的层数和每一层神经元个数;
(2)用梯度下降法求解目标函数的局部极小值。
在下一讲中,我们将继续讲解如何用梯度下降法训练人工神经网络。
参考资料
- 浙江大学《机器学习》课程—胡浩基老师主讲
如果文章对你有帮助,请记得点赞与关注,谢谢!