6.DeepFM: A Factorization-Machine based Neural Network for CTR Prediction论文详解和代码实现
一、总述
这篇论文来自哈工大&华为诺亚方舟实验室,主要关注如何学习user behavior背后的组合特征(feature interactions),从而最大化推荐系统的CTR。但目前的方法容易得到low-或者high-order interactions。因此这篇论文提出构建一个端到端的可以同时突出低阶和高阶feature interactions的学习模型DeepFM。DeepFM是一个新的神经网络框架,结合了FM在推荐中的优势和深度学习在特征学习中的优势。
二、DeepFM模型的问题阐述和研究背景
2.1 问题阐述
在推荐系统的CTR预估中,学习用户行为背后复杂的特征交互关系非常重要,例如人们通常在吃饭的时间点下载外卖app比较多,这说明时间和item类别之间是有一定联系的,如果我们在吃饭的时间推荐饿了么,肯定比在其它时间段要更加符合用户的需求。(当然影响用户点击行为的因素非常多,这里只是简单举了一个例子,并不是说所有的用户在吃饭的时间都会想点击外卖app,只是一种统计倾向而已)类似,还有很多其它的特征组合关系,有些特征组合关系是我们拍脑门可以想出来的,上面的时间和item类别,年龄和item类别,性别和item类别。。。但是也有那么一些是我们想不出来的(想不出来意味着不大符合我们平时的认知),例如传统的“啤酒和尿布”关系是隐藏在数据里的。(详细介绍可以参见这篇博文)不大容易被我们人为设计出来作为组合特征。这就需要用到机器学习,我们当然希望机器可以帮我们自动学到很多特征。毕竟当原始特征很多的时候,人为设计特征是一件费时也有可能不讨好的事情。
2.2 DeepFM背景
DeepFM可以看做是在FM算法的基础上衍生出来的算法,DeepFM通过将FM与DNN相结合,联合训练FM模型和DNN模型,用FM做特征间的低阶组合,用DNN做特征间的高阶组合。相比于谷歌最新的Wide&Deep模型,DeepFM模型的Deep component和FM component从Embedding层共享数据输入,同时不需要专门的特征工程。
DeepFM广泛应用于CTR预估领域,通过用户的点击行为来学习潜在的特征交互在CTR中至关重要。隐藏在用户点击行为背后的特征交互,无论是低阶交互还是高阶交互都可能会对最终的CTR产生影响。FM算法,可以对特征间成对的特征交互以潜在向量内积的方式进行建模,并表现出不错的效果。然而,FM由于高的复杂性不能进行高阶特征交互,常用的FM特征交互通常局限于二阶。其他的基于神经网络的特征交互的方法要么侧重于低阶或者高阶的特征交互,要么依赖于特征工程,因此,DeepFM出现了。DeepFM表明,通过一个端到端的方式学习所有阶特征之间的交互并且不严格依赖特征工程也是可行的。
DeepFM小结:
- DeepFM是一个结合了FM结构和DNN结构的新的神经网络模型,并且DeepFM能够像FM那样进行低阶特征间的交互,也能够像DNN那样进行高阶特征间的交互。同时,DeepFM能够进行端到端的训练且不依赖于特征工程。
- DeepFM的FM component和Deep component共享相同的输入,因此能够完成高效训练。
三、模型
3.1 CTR数据预估特点
1、输入中既包含离散型数据(性别),也包含连续型数据(年龄)。离散型数据需要one-hot编码,连续型数据可以先离散化再one-hot编码,也可以直接保留原值。
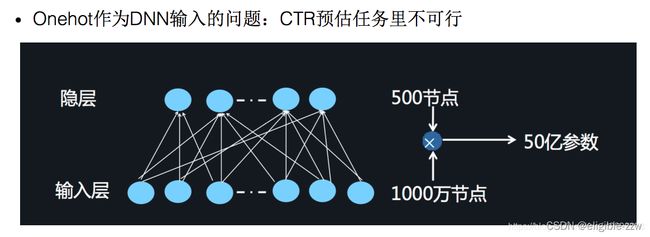
2、维度非常高, 将one-hot类型的特征输入到DNN中,会导致网络参数太多。
3、数据非常稀疏,one-hot以后,大部分数据都为0。
4、特征按照Field分组
CTR预估重点在于学习低阶与高阶的组合特征。注意,组合特征包括二阶、三阶甚至更高阶的,阶数越高越复杂,越不容易学习。FM模型由于计算复杂度太高,一般只计算到二阶。
根据Google的Wide&Deep模型得出:高阶和低阶的组合特征都非常重要,同时学习到这两种组合特征的性能要比只考虑其中一种的性能要好。
那么关键问题转化成:如何高效的提取这些组合特征。
1、引入领域知识人工进行特征工程。这样做的弊端是高阶组合特征非常难提取,会耗费极大的人力。而且,有些组合特征是隐藏在数据中的,即使是专家也不一定能提取出来,比如著名的“尿布与啤酒”问题。
2、将DNN用于高阶的特征组合,是很自然的想法,通过多层的神经网络去解决高阶问题。但是将One-hot类型的特征输入到DNN中,会导致网络参数太多。
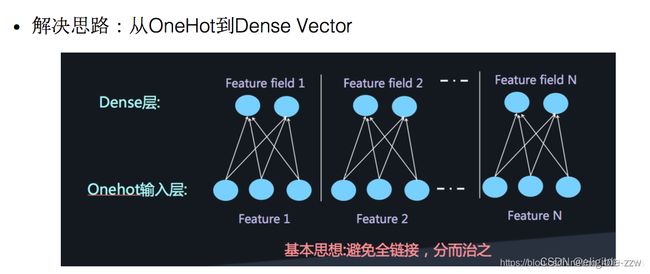
解决思路:将原始数据的one-hot根据不同特征,分别将其编码进行Embedding,这样的可以减少数据稀疏,而且每个feature 在embedding后长度均相同。
然后。将embedding组合输入到两个隐藏层的神经网络,进行高阶特征的组合。
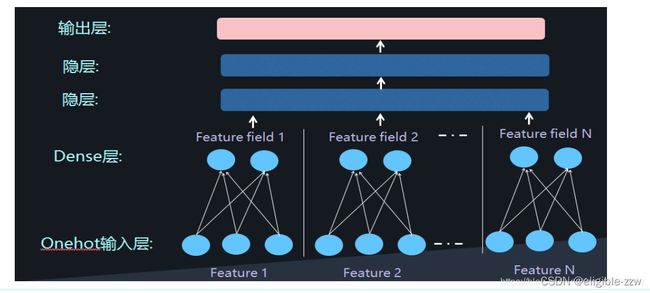
3.2 DeepFM模型结构
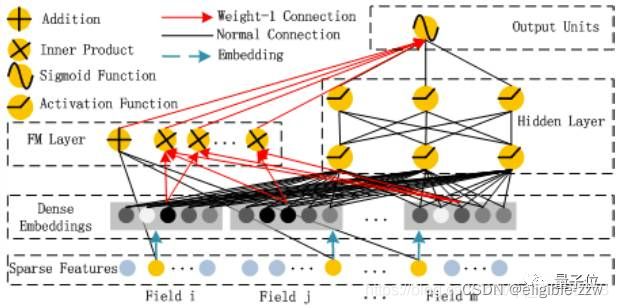
从模型结构图不难看出,DeepFM由两部分组成:FM部分和deep部分,且FM部分和deep部分共享相同的原始特征向量输入,这样可以保证DeepFM能够同时学习低阶和高阶特征组合。这样的模型结构最终保留着以下特点:
- 不需要预训练FM得到隐向量;
- 不需要人工特征工程;
- 能够同时学习低阶和高阶的组合特征;
- FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习。
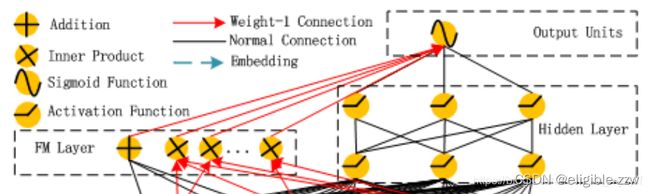
对于特征i,标量wi用来衡量这个特征的1阶重要性,向量Vi用来衡量这个特征和其他特征进行组合后的影响。Vi被输入到FM部分用于对2阶特征组合建模,同时被输入到deep部分用于对高阶特征组合建模。所有的模型参数,包括wi、Vi和其他网络参数可以通过以下的损失函数联合训练得到:
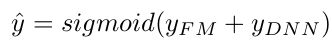
这里,yhat属于(0,1)是预估的ctr,y_{FM}是FM部分的输出,y_{DNN}是deep部分的输出。
从网络结构可以看出,DeepFM模型的网络结构:
- 输入层(Sparse Features):输入数据包括类别特征和连续特征;
- Embedding层(Dense Embeddings):该层的作用是对类别特征进行Embedding向量化,将离散特征映射为稠密特征。该层的结果同时提供给FM Layer和Hidden Layer,即FM Layer和Hidden Layer共享相同的Embedding层。
- FM Layer:该模型主要提取一阶特征和两两交叉特征;
- Hidden Layer:该模块主要是应用DNN模型结构,提取深层次的特征信息;
- 输出层(Output Units):对FM Layer和Hidden Layer的结果进行Sigmoid操作,得出最终的结果。
3.3 DeepFM模型详细介绍
- 输入层

DeepFM的输入可由连续型变量和类别型变量共同组成,且类别型变量需要进行One-Hot编码。正是由于One-Hot编码,导致了输入特征变得高维且稀疏。针对高维稀疏的输入特征,DeepFM采用了word2vec的词嵌入(WordEmbedding)思想,把高维稀疏的向量映射到相对低维且向量元素都不为零的空间向量中,不同的是DeepFM根据特征类型进行了field区分,即将特征分为了不同的field。
在处理特征时候,我们需要对离散型数据进行one-hot转化,经过one-hot之后一列会变成多列,这样会导致特征矩阵变得非常稀疏
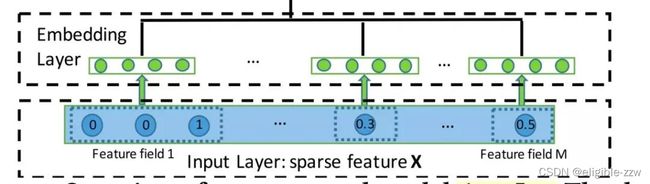
如何处理连续性特征与离散型特征,并将它们转换成field需要进一步介绍。
- Embedding层(Dense Embeddings)

embedding层对类别特征进行embedding向量化,将离散特征映射为稠密特征。embedding层的输入就是分field的特征,也就是说embedding层完成了对不同特征按field进行了向量化。FM层和Hidden层共享的就是embedding层的输出结果。
- FM层(FM Layer)

FM Layer的输入是embedding层的输出,FM Layer主要是提取一阶特征和两两交叉的二阶特征。如上图所示,Field_i、Field_j、Field_m中的黄色圆点指向Addition节点的黑线表示的是FM直接对原始特征做的一阶计算,而embedding层每个field对应的embedding会有两条红线连接到Inner Product节点表示的是FM对特征进行的二阶交叉计算。
观察上图比较容易发现FM Layer 包含一个Addition 和 多个 Inner Product内积单元。Addition反映的是1阶的特征。内积单元反映的是2阶的组合特征对于预测结果的影响。

1、FM模块图中,黑线部分是一个全连接,W就是里面的权重。把输入X和W相乘就得到了输出。至于Addition Unit,我们就不纠结了,这里并没有做什么加法,就把他当成是反应1阶特征对输出的影响就行了。
2、这里最后的结果中是在[1,K]上的一个求和。 K就是W的列数,就是Embedding后的维度,也就是embedding_size。也就是说,在DeepFM的FM模块中,最后没有对结果从[1,K]进行求和。而是把这K个数拼接起来形成了一个K维度的向量。
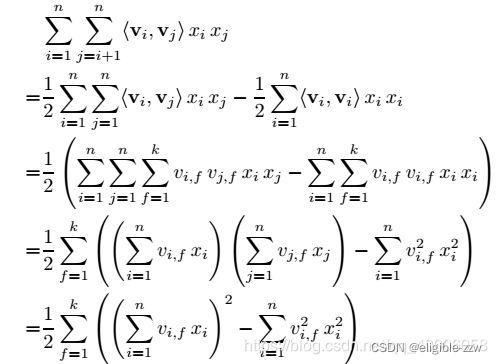
3、FM模块实现了对于1阶(addition)和2阶(inner product)组合特征的建模。
4、FM模型没有进行预训练
5、没有使用人工特征工程
6、embedding矩阵的大小是:特征数量 * 嵌入维度。 然后用一个index表示选择了哪个特征。
7、需要训练的两部分:
注意:
1). input_vector和Addition 相连的全连接层,也就是1阶的Embedding矩阵。
2). Sparse Feature到Dense Embedding的Embedding矩阵,中间也是全连接。
- 隐藏层(Hidden Layer)
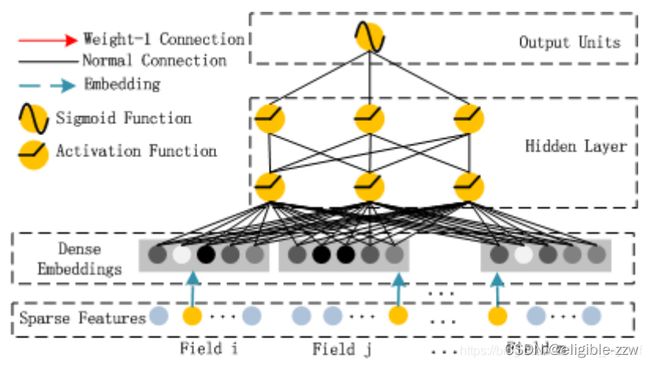
Hidden Layer主要是应用DNN的模型结构,用于提取深层次的特征信息。Hidden Layer的输入也是embedding层的输出(与FM Layer共享输入)。从embedding层输出到Hidden Layer是一种全连接计算。
- 输出层(Output Units)
输出层主要对FM Layer和Hidden Layer的结果进行Sigmoid操作,得出最终的结果。
四、详细介绍架构
4.1 FM Component
DeepFM中的FM部分是一个factorization machine,关于FM可以参考这篇博客【推荐系统】推荐算法系列之FM:Factorization Machines。除了所有特征间的一个线性组合(1阶),FM模型也支持以独立特征向量内积形式的成对特征组合(2阶)。相比于先前的方法,FM在处理2阶特征组合的时更有效,尤其在训练数据集是稀疏的场景。在先前的方法中,特征i和特征j的组合参数只有在特征i和特征j同时出现在相同的数据记录中才能得到训练。然而在FM中,这个参数可以通过向量Vi和向量Vj的内积的形式完成更新。这样,FM能够训练Vi(Vj)无论i(j)是否出现在数据记录中。这样很少出现在训练集中的特征组合也能够被FM很好的学习出来。
DeepFM中FM部分的输出是一个Addition单元和许多个Inner Product单元的累加和。
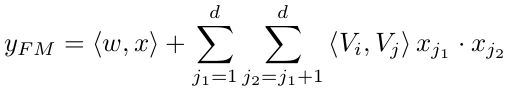
其中,Addition单元(
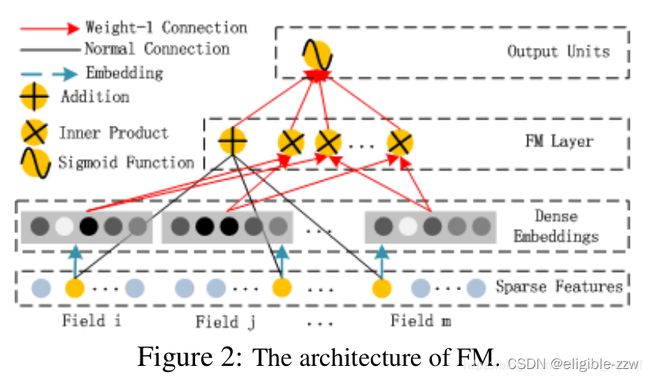
从网络结构可以看出,FM部分的网络结构:
- 输入层(Sparse Features):输入数据包括类别特征和连续特征;
- Embedding层(Dense Embeddings):该层的作用对类别特征进行Embedding向量化,将离散特征映射为稠密特征;
- FM Layer:该模型主要提取一阶特征和两两交叉特征;
- 输出层(Output Units):对FM Layer的结果进行Sigmoid操作,得出最终的结果。
4.2 Deep Component
DeepFM中的deep部分是一个前馈神经网络,用来学习高阶特征组合。
DeepFM中的deep部分将一条向量输入到神经网络。通常,点击预估的任务的神经网络输入要求网络结构的设计。点击预估的原始特征输入向量通常是高度稀疏的、超高维、连续值与绝对值混合、按fields分组的形式,这就需要网络中有一个嵌入层(embedding layer)在将向量输入到第一个hidden层之前来将输入向量压缩成一个低维、实值稠密的向量,否则网络将难于训练。
DNN部分模型结构:
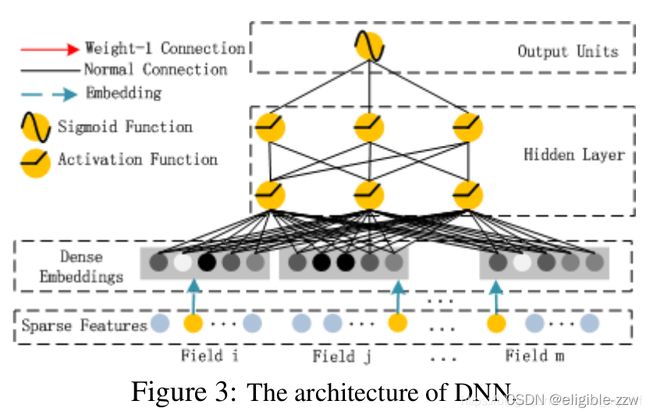
从网络结构可以看出,DNN部分的网络结构:
输入层(Sparse Features):输入数据包括类别特征和连续特征;
Embedding层(Dense Embeddings):该层的作用对类别特征进行Embedding向量化,将离散特征映射为稠密特征;
Hidden Layer:该模块主要是应用DNN模型结构,提取深层次的特征信息;
输出层(Output Units):对FM Layer的结果进行Sigmoid操作,得出最终的结果。
4.3 input-layer到embedding-layer的模型结构:
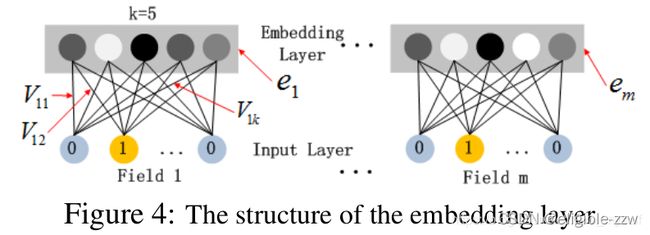
上图展示的是input层到embedding层的网络结构,这个网络结构设计有两点需要说明:
- 尽管不同field的输入长度不同,但是所有field都会embedding成k维;
- FM得到的隐藏特征向量V此时作为用来压缩输入field向量到embedding向量的网络权重。
解释一下上述第2点:假设k=5,首先,对于输入的一条记录,同一个field只有一个位置是1(field是one-hot的形式),那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层与该神经元全连接的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的Vi是相同的。
DeepFM将FM模型和DNN模型都当作全面学习的网络结构,这一点跟一些其他的方法中通过预训练FM的隐藏向量进而对网络进行初始化的方式有些不同。这样的方法可以消除对FM的预训练,并且可以通过端到端的方式完成对整个网络的联合训练。
假设embedding层的输出可表示为:
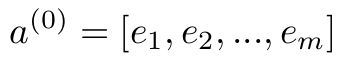
其中,e_{i}是第i个field的embedding,m是field的数量。这样a^{(0)}被输入到DNN网络,其前向传播函数为:

其中,l是DNN每一层的网络深度,\sigma是一个激活函数。a{(l)}是网络输出,W{(l)}是模型权重,b^{(l)}是第l层的偏置项。经过这个网络之后,一个稠密实值特征向量被生成,然后这个稠密实值特征向量被输入到sigmoid函数进行点击预估:

这里,|H|是隐藏层的数量。
需要强调的是FM和DNN共享相同的特征embedding,这样做的好处是:
- 可以从原始数据中学习低阶和高阶的特征组合;
- 不需要专门的额外的特征工程(Wide&Deep模型需要特征工程)。
五、超参数设置
这部分简单的给出论文中尝试的DeepFM一些网络参数设置:
- Activation Function:relu、tanh,相比于sigmoid,relu、tanh更适合deep模型。
- Dropout:We set the dropout to be 1.0, 0.9, 0.8, 0.7,0.6,0.5,Dropout影响一个神经元被保留在网络中的概率,Dropout是折中精度和网络复杂度的一种正则化技术。
- Number of Neurons per Layer:DeepFM performs stably when the number of neurons per layer is increased from 400 to 800,In our dataset, 200 or 400 neurons per layer is a good choice,增加每层神经元的个数可能造成网络更复杂,复杂的模型容易过拟合。
- Number of Hidden Layers:1, 3, 5,7,增加隐藏层的数量在模型开始的时候会提升效果,但是如果隐藏层的数量一直增加可能会造成效果下降,这也是一种过拟合现象。
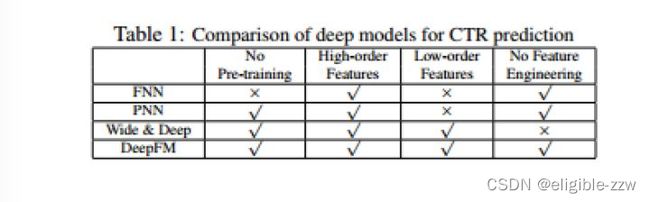
六、DeepFM与其他模型的比较
FNN模型是用FM模型预先训练好的embedding做初始输入,之后接dnn,这样做的缺点之一就是embedding受FM模型的影响比较大,而且这样只是提取了高级特征。另外因为需要预先训练FM模型,所以会增加训练复杂度。
PNN模型是在embedding层和隐藏层之间使用了内积(或者外积,或者2者混合)提取了组合特征,之后和原始的embedding层concat组成隐藏层,之后dnn提取高级特征。而且因为内积的输出和后面隐藏层的所有单元都连接,所以参数会很多。deepFM的FM部分的内积后面只接了一个单元。
谷歌的wide&deep模型,wide&deep模型的wide部分的输入特征是需要人为设计的,例如在app推荐的任务中,可能需要设计一些组合特征。deepFM模型直接把原始特征作为输入,用deep模型和FM自动提取特征,不需要做特征工程。
一个主要的扩展就是将谷歌的wide&deep模型的wide部分用FM代替,后面实验会说明这样效果没有deepFM好。论文中的解释是deepFM模型特征的embedding是共享的,这样学到的embedding会更好一些。也就是说它做扩展实验的时候并没有设成共享的?我个人觉得还有一个原因就是wide部分的交叉特征如果是用FM的话,一般交叉特征出现的频率很低,学到的交叉特征的embedding并不好。
虽然后面实验表明deepFM比wide & deep模型效果好,但是会不会只在他们的数据集上比较好,因为FM只是提取了交叉特征,丢掉了单个特征,如果某个特征很重要的话,感觉wide & deep效果会更好一些?或者会不会类似PNN的方法,把单个特征和交叉特征都用上,之后再接lr,会好一些呢?

七、实验
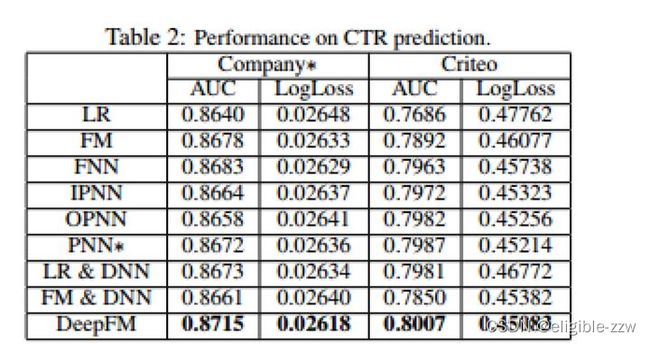
数据集:Criteo数据集 4500万用户点击记录
公司的数据集 10亿用户点击记录
评价方式:AUC 和logloss
结果:
八、代码实现(出自某位大佬)
github链接为:https://github.com/ZiyaoGeng/Recommender-System-with-TF2.0
数据集采用的是:Criteo,下载链接为:(https://pan.baidu.com/s/1sYsY88APFTNldcZ2n3sKlA):96f2
九、总结
总体来讲,我感觉最大的优势就是不需要人为设计特征,可以自动捕获到高级和低级特征组合,也不需要提前预训练。