PointConv:三维点云卷积操作
摘要
与常规密集网格所代表的图像不同,3D点云数据是不规则且无序的,因此很难将卷积操作应用到3D点云数据。在本文中,我们将动态滤波器扩展成为新的名为PointConv的卷积操作,PointConv可以用于点云数据,创建深度卷积网络。我们将卷积核视为由权重和密度函数组成的3D点的局部坐标的非线性函数。对于给定点,通过核密度估计利用多层感知机网络和密度函数来学习权重函数。这项工作最重要的贡献是为有效计算权重函数提出的新构想,这使我们能够大幅度扩展网络并显著提高网络性能。学习的卷积核可用于计算3D空间中任何点集上的平移不变和置换不变卷积。此外,PointConv还可以用作反卷积运算符,将子采样点云中的特征传播回其原始分辨率。ModelNet40,ShapeNet和ScanNet上的实验表明,基于PointConv构建的深度卷积神经网络能够在3D点云的语义分割基准上达到最高水准。此外,我们将CIFAR-10转换为点云的实验表明,构建在PointConv上的网络可以达到2D图像中具有类似结构的卷积网络的性能。
论文链接:https://arxiv.org/abs/1811.07246
源码链接:https://github.com/DylanWusee/pointconv
主要贡献
将卷积核视为由权重和密度函数组成的3D点的局部坐标的非线性函数。对于给定点,通过核密度估计利用多层感知机网络和密度函数来学习权重函数。这项工作最重要的贡献是为有效计算权重函数提出的新构想,这使我们能够大幅度扩展网络并显著提高网络性能。
本文的工作贡献是:
1、提出了PointConv:PointConv是一种密度重加权卷积,它能够在任何一组3D点上完全逼近3D连续卷积。
2、引入了一种有效提高存储效率的方法来实现PointConv,能够使用改变求和顺序的重构来大大提高存储器效率。最重要的是,它允许它扩展到现代CNN的规模。该方法可以实现与2D卷积网络中相同的平移不变性,以及点云中点的排序的不变性
3、将PointConv扩展到反卷积—PointDeconv,获得更好的分割结果,而大多数先进算法不能实现反卷积操作。
算法框架
1、3D点云的卷积
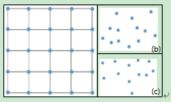
图1 图像中的局部区域和点云之间的差异
3D点云数据的表达方式与图形完全不同,如图一所示。3D点之间没有前后顺序之分,因此,在3D点云上的卷积操作应该具有排列不变性。由此提出了一种称为PointConv的置换不变卷积运算。
在3D空间中,可以把连续卷积算子的权重看做关于一个3D参考点的局部坐标的连续函数。

W和F均为连续函数,(x, y, z)是3D参考点的坐标,(δx, δy, δz)表示邻域 G 中的 3D 点的相对坐标。点云可以被视为来自连续空间的非均匀样本。上式可以离散化到一个离散的3D点云上。
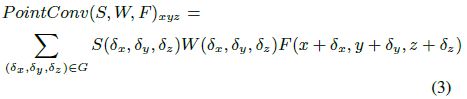
其中,S 表示逆密度系数函数。然后使用逆密度对学到的权重进行加权,补偿不均匀采样。函数 W 的输入是以 (x, y, z) 为中心的 3D 邻域内的 3D 点的相对坐标,输出是每个点对应的特征 F 的权重。使用多层感知机近似权重函数w。S 是一个关于密度的函数,输入是每个点的密度,输出是每个点对应的逆密度系数。使用核化密度估计近似逆密度S,核化密度估计后带有使用多层感知机实现的非线性变换。
PointConv中的MLP的权重在所有点之间共享,以便维持置换不变性。逆密度尺度S(δx, δy, δz)的计算过程为:首先使用核密度估计(KDE)估计离线点云中每个点的密度,然后将密度输入到一维非线性变换的多层感知机中。使用非线性变换的原因是使网络自适应地决定是否使用密度估计。

图2 PointConv操作
图2展示了K个3D点组成的邻域上执行PointConv操作的流程。Cin,Cout为输入特征和输出特征的通道数,k,cin,cout表示索引。输入是点Plocal的邻域位置,其可以通过减去局部区域的质心的坐标和局部区域的特征Fin来计算。 我们使用核为1的卷积构成多层感知机。权重函数的输出是W,密度尺度为S。在卷积后,K近邻邻域的特征Fin被编码到输出特征Fout中,如等式(4)所示。

2、反卷积操作
对于分割任务,需要逐点预测。为了获得所有输入点的特征,需要一种将特征从二次采样点云传播到更密集的点的方法。 PointNet ++建议使用基于距离的插值来传播特征,这并未充分利用反卷积操作来捕获来自粗糙层的传播信息的局部相关性。
该文建议添加一个基于PointConv的PointDeconv层来解决这个问题。如图3所示,PointDeconv由两部分组成:插值和PointConv。首先,采用插值来传播先前层的粗糙特征,通过从3个最近点线性插值特征来进行插值。

图 3 反卷积操作
然后,使用跳跃连接将插值特征与来自卷积层的具有相同分辨率的特征连接起来。然后在连接特征上应用Point-Conv以获得最终的反卷积输出。直到所有输入点的特征已传播至原始分辨率。
3、高效PointConv
该文证明了PointConv可以简化为两个标准操作:矩阵乘法和 2D 卷积,证明部分见原文,大大降低了卷积操作的内存占用量,单层卷积层的内存占用变为原来的1/64。高效PointConv卷积操作如图4所示:
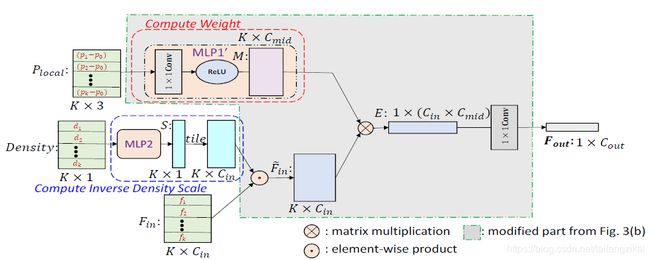
图 4 高效PointConv
主要结果
为了评估PointConv网络,在几个广泛使用的数据集上,包括Model-Net40 ,ShapeNet和ScanNet进行了实验。为了证明PointConv能够完全接近常规卷积,还报告了CIFAR-10数据集的结果。这里简要介绍,具体结果请看论文。
在ModelNet40上的分类,在表1中,PointConv在基于3D输入的方法中实现了最先进的性能。

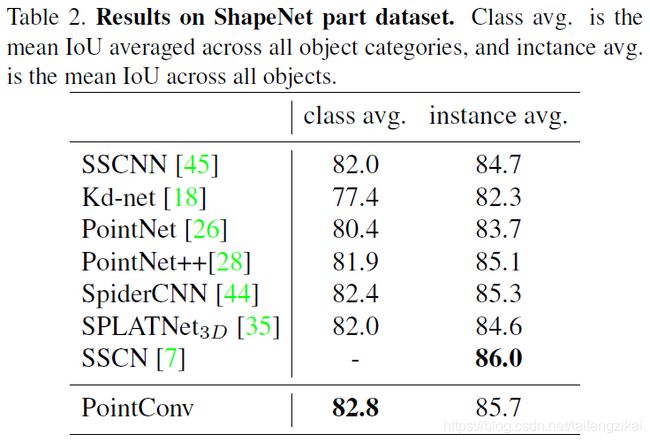
ShapeNet部分分割,使用IoU评估PointConv网络。见表2,类别平均mIoU为82.8%,实例平均mIoU为85.7%,与其他先进算法相同。
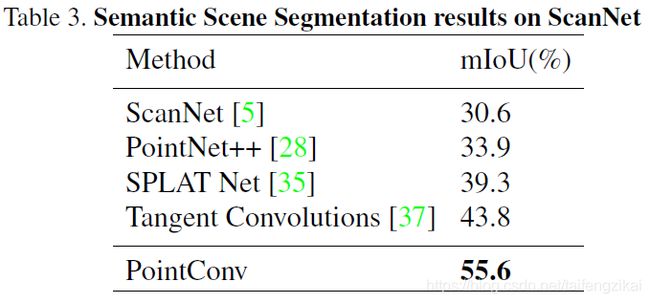
语义场景标签,使用Scan-Net数据集评估PointConv处理包含大量噪声数据的真实点云的能力。mIoU是所有类别中IoU的平均值。见表3,PointConv在很大程度上优于其他算法。
CIFAR-10的分类,该文称PointConv可以与2D CNN等效,那么基于PointConv的网络的性能应该等同于图像CNN的性能。为了验证这一点,使用CIFAR-10数据集作为比较基准。将CIFAR-10中的每个像素视为具有xy坐标和RGB特征的2D点。实验表明,CIFAR-10上的PointConv确实具有与2D CNN相同的学习能力。表4显示了图像卷积和Point-Conv的结果。从表中可以看出,CIFAR-10上PointCNN的准确率为80.22%,远远低于图像CNN。但是,对于5层网络,使用PointConv的网络能够达到89.13%,这与使用图像卷积的网络类似。而且,与VGG19结构相比,PointConv也可以实现与VGG19相比的精确度。

Abstract
Unlike images which are represented in regular dense grids, 3D point clouds are irregular and unordered, hence applying convolution on them can be difficult. In this paper, we extend the dynamic filter to a new convolution operation, named PointConv. PointConv can be applied on point clouds to build deep convolutional networks. We treat convolution kernels as nonlinear functions of the local coordinates of 3D points comprised of weight and density functions. With respect to a given point, the weight functions are learned with multi-layer perceptron networks and density functions through kernel density estimation. The most important contribution of this work is a novel reformulation proposed for efficiently computing the weight functions, which allowed us to dramatically scale up the network and significantly improve its performance. The learned convolution kernel can be used to compute translation-invariant and permutation-invariant convolution on any point set in the 3D space. Besides, PointConv can also be used as deconvolution operators to propagate features from a subsampled point cloud back to its original resolution. Experiments on ModelNet40, ShapeNet, and ScanNet show that deep convolutional neural networks built on PointConv are able to achieve state-of-the-art on challenging semantic segmentation benchmarks on 3D point clouds. Besides, our experiments converting CIFAR-10 into a point cloud showed that networks built on PointConv can match the performance of convolutional networks in 2D images of a similar structure.
请各位关注公众号。更多的文章可以关注公众号查看。
