【推荐系统】ESMM实践应用
| 友情链接 MMoE 算法在淘宝躺平推荐系统中的应用实践 - AIQ (MMoE 算法在淘宝躺平推荐系统中的应用实践) |
论文链接:https://arxiv.org/pdf/1804.07931.pdf
1、理论
多任务学习(Multitask learning)是基于共享表示(shared representation),把多个相关的任务放在一起学习的一种机器学习方法。
多任务学习的两个关键点:1、多个任务必须具有相关性;2、多个任务之间拥有可以共享的底层表示。
多任务模型通过学习不同任务的联系和差异,可提高每个任务的学习效率和质量。多任务学习的的框架广泛采用shared-bottom的结构,不同任务间共用底部的隐层。这种结构本质上可以减少过拟合的风险,但是效果上可能受到任务差异和数据分布带来的影响。
MMOE模型刻画了任务相关性,基于共享表示来学习特定任务的函数,避免了明显增加参数的缺点。
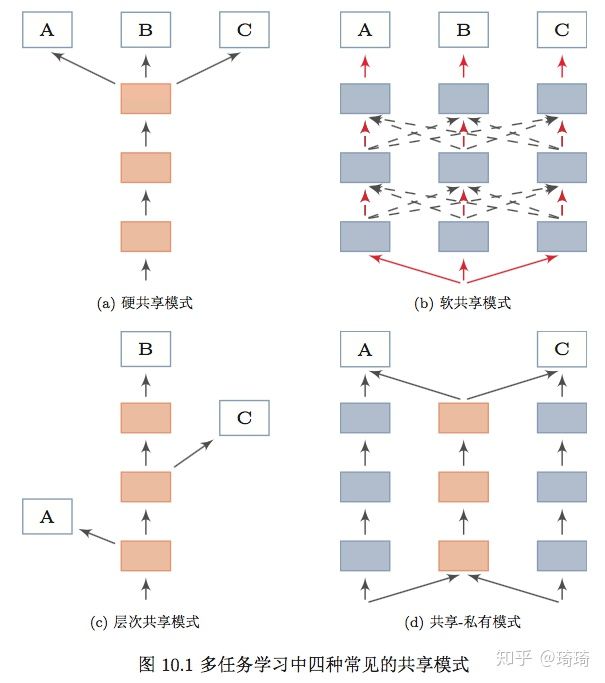
共享模式的总结部分摘自邱锡鹏的《神经网络与深度学习》,十分全面 :
1)参数的硬共享模式:不同任务的神经网络模型共同使用底层的共享模块(Shared Layers)来提取一些通用特征,然后再针对每个不同的任务设置高层的私有模块(Task-specific layers)。
2)参数的软共享模式:无显式共享模块,但每个任务都可以从其他任务中窃取信息,来提高自己的能力。窃取的方式包括直接复制使用其他任务的隐含状态,或使用注意力机制来主动选取有用信息。比如谷歌的MMOE,就是典型的软共享模式。
3)层次共享模式:神经网络中不同层抽取的特征类型不同,尤其对于图像任务而言。底层一般抽取一些低级的局部特征,高层抽取一些高级的抽象语义特征。因此,如果多任务学习中,不同任务也有级别高级之分,那么一个合理的共享模式就是让低级任务在底层输出,高级任务在高层输出。
4)共享-私有模式:这种模式的分工更加明确,将共享模块和任务特定(私有)模块的责任分开,共享模块捕捉一些跨任务的共享特征,而私有模块只捕捉和特定任务相关的特征。最终的表示由共享特征和私有特征共同构成。
ESMM模型回顾
用户的行为遵循一种序列化的模式,即曝光->点击->转化。因此,CVR模型预估的是点击后的转化概率,即 pcvr=p(conversion|click, impression)。
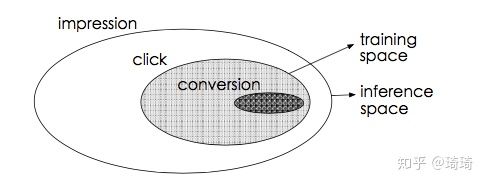
不同于ctr预估问题,cvr预估面临着两个重要问题:1)sample selection bias (SSB) problem:传统CVR模型通常以点击数据作为训练集,点击并转化为正样本,点击未转化为负样本,但我们在线inference预测时,面对的却是整个曝光样本空间。SSB问题会降低模型的泛化性能。2)data sparsity (DS) problem:cvr模型使用的点击训练样本量远小于ctr任务使用的曝光训练样本量。
某些策略可以缓解上述两个问题,比如从曝光集中对未点击样本抽样做负例缓解SSB(导致对cvr预估概率的低估),对转化样本过采样缓解DS(对采样率敏感)等。这些方法无法从本质上解决问题。
CVR预估模型的本质,不是预测“商品被点击,然后被转化”的概率(CTCVR),而是“假设商品被点击,那么它被转化”的概率(CVR)。这就是不能直接使用全部样本训练CVR模型的原因,因为我们不知道这个信息:那些未被点击的商品,假设它们被用户点击了,它们是否会被转化。如果直接使用0作为它们的label,会很大程度上误导CVR模型的学习。
ESMM可以从本质上同时解决SSB和DS的问题。
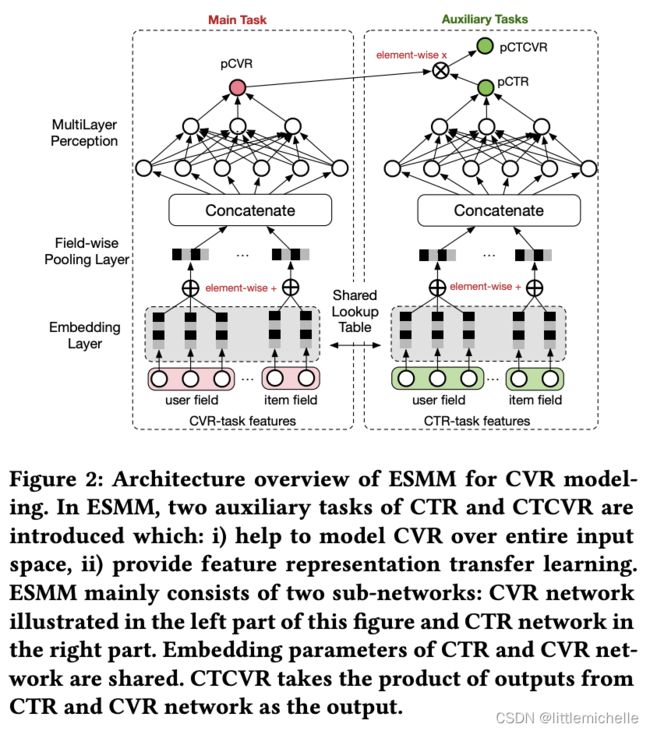
ESMM引入了两个辅助task:预估曝光后的点击概率以及预估曝光后点击且转化的概率。pCTCVR=pCTR*pCVR,模型目标是学习绿色的任务。
- 在ESMM中, 通过 pctcvr=pctr*pcvr间接地学习中间变量 pCvr,pCTCVR 和 pctr都是在全样本空间中进行预估的,因此得到的 也属于全样本空间,由此消除了SSB问题。
- 同时,CVR与CTR网络的底层特征表达的参数是共享的,显然CTR训练所能利用的样本量更多,从而辅助CVR的学习,使CVR任务可以隐式地从大量未点击的曝光样本中学习,这种类似于迁移学习的参数共享机制可以极大缓解DS问题。
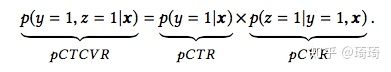
在此公式中, pctcvr是曝光后点击且转化的概率, pCTR是曝光后的点击概率, pcvr是当前商品被用户点击的条件下,被转化的概率。
CTR对应的label是click,CTCVR对应的label是conversion & click。其中,click表示点击,conversion表示转化。
这两个任务可以使用全局曝光样本。论文里通过学习这两个任务,再根据该公式,隐式地学习CVR任务。
隐式学习pCVR 指的是,pCVR仅仅是网络结构中的一个变量,我们并不会将其当作我们的目标,也不会将pCVR加入到目标函数中。
目标函数如下:
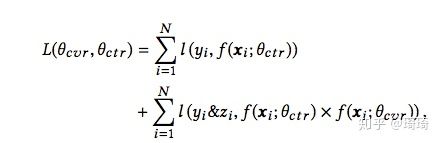
即利用CTCVR和CTR的监督信息来训练网络,隐式地学习CVR,这就是ESMM的精髓。
优缺点
这篇论文可以是Multi-Task Model和预估cvr服务场景相结合的经典之作了。
1、通过CVR task和CTR task共享这个embedding table,这种共享机制比传统的CVR task多学习未点击的曝光的数据,缓解了训练数据稀疏问题。
2、通过设计multi-task loss,解决样本选择偏差的问题。
缺点
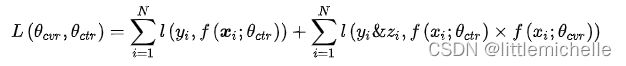
在实际应用中,往往点击、转化的样本非常稀疏,通常曝光到点击率可能只有1%,而且点击到转化可能也只有1%。这样就会造成损失函数的第二部分常常为0。按照点击到转化可能也只有1%算的话,大概和第一部分差100倍。这样损失函数的值的大小可能就由第一部分决定了。

Entire Space Multi-Task Model(ESMM)阅读体会 - 千寻的文章 - 知乎
如何优化
多目标分别优化解决方案
多目标学习--多目标分别优化解决方案 - 千寻的文章 - 知乎
主要核心思想:增加优化器,实际上隔离ctr、cvr值之间的影响,增加两个任务之间的独立性能。
原来线上使用 ESMM 模型进行点击率(ctr)和转化率(cvr)的多目标预估。该模型将点击率和转化率任务的 loss 简单求和后用于更新网络参数。
通过线下的实验发现在一个 batch(约几万条样本) 中点击率和转化率任务的 loss 数值相差30-50倍,会造成点击率任务的 loss 主导所有参数的更新,从而导致转化率任务学习效果较差。
方案:将网络分成ctr网络参数、cvr网络参数、底层共享网络参数三部分。ctr网络参数用ctr的loss优化,cvr网络参数用cvr的loss优化,共享网络参数用ctr的loss+cvr的loss优化。三个优化器,每个优化器对 使用不同的loss对负责的网络参数进行优化,并每个优化器设置不同学习率。这样就缓解转化率(cvr)任务loss的数值远远小于点击率(ctr)任务loss的问题,并获得转化率任务效果的提升。使用LazyAdam。
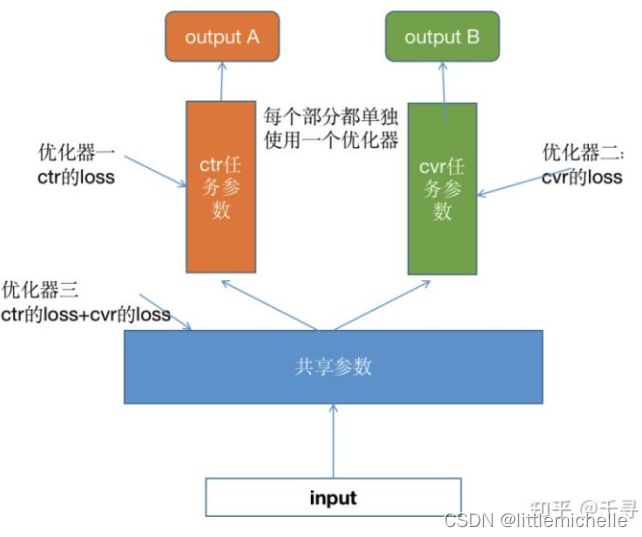
原来是
线下实验发现,多组实验:ctr的auc基本保持不变或者略有提升,cvr的auc提升千分之一志千分之二,并且提升置信,线上预估服务,模型输出的ctr、cvr都使用。
线上:cost提升2%,cpm提升4%
基于ESMM模型的多目标优化实践——蘑菇街商城篇 - 琦琦的文章 - 知乎
基于ESMM模型的MTL多目标优化实践——用户活跃度影响排序机制——蘑菇街首页信息流推荐 - 琦琦的文章 - 知乎
引入点击行为序列,点击序列会同时作为ctr和cvr任务attention模块的输入,attention结构中的参数共享。
基于ESMM的多目标实践
ESMM 模型是通过ctr + ctcvr loss来进行梯度下降的,ctr和ctcvr都会用click=0的样本,也就是全局样本。cvr网络可以从有曝光无点击的样本中间接学习。
ESMM模型可以同时输出 pctr,pcvr,pctcvr。在实际应用中,若将多任务网络输出的 pCTCVR直接替换ctr单目标模型产出的 pctr ,并接入线上排序时,会出现点击率大幅度下跌的现象。
用 pCTCVR 代替原来的 pCTR 进行排序,以同时提高点击&转化的概率。真实cvr=pay/clk=0.18左右
也可以使用,
- 存在的问题,利用CTCVR直接代替DIN的CTR出现了点击率大幅下跌的问题。——》怎么解决的呢?
ESMM中的ctr和cvr任务是共享底层embedding参数的。电商场景仅仅共享底层embedding是不够的,cvr任务需要通过ctr任务学习到的其他参数来进一步辅助cvr的训练。 1)+attention 2)+对序列类特征进行了拓展,deep结构中加入成交相关的统计类特征。(其实就是side information对原始信息进行补充) 为了进一步增强cvr侧的能力,我们对序列类特征进行了拓展,加入了包含销量、价格、喜欢数在内的泛化统计类特征。一般而言,泛化类特征(商品的一般性特征)包括:店铺、品牌、类目、销量、价格、喜欢数等。 加入了商品类目、商品价格、商品销量、商品喜欢数共四种特征。 |
| 如何将连续类特征巧妙地加入到deep模型中,从而提高模型的泛化能力呢? 对销量/喜欢数/价格等连续类特征进行分桶。首先需要统计样本中,商品各属性的最大值/最小值/分位数等,确定分桶的边界。将每个连续统计类特征分成8桶。 分桶后,我们会对每种连续类特征进行编码,构建其专属的embedding矩阵。 训练时,会使用这些连续类特征对用户的历史点击序列进行信息补充。需要说明的是,这些统计类特征也是以序列的方式呈现的,且与历史点击序列中的每个商品id一一对应,也就是说,序列中的每个商品,都有销量/喜欢数/价格等特征对其进行补充。 具体的做法就是将这些编码后的统计类序列特征与原始点击序列的embedding表达在最后一个维度进行拼接。 在点击序列的基础上,增加喜欢数/销量/价格等side info类特征,可以同步明显提升ctr侧以及cvr侧的能力。增加side info的点击序列的attention参数在两个任务之间仍是共享的,这类信息的加入可以同步提高两侧任务的AUC。 其实就是side information对原始信息进行补充,具体操作, 比如商品embd映射后是none,m,k,side_info也是none,m,k,二者在axis=-1处做拼接后生成none,m,2*k(就是concat),之后再和target_item做attention pooling。 但一般商品embedding维度较大,比如64,side info的embedding维度较小(因为本身较少,无需这么多维),比如16或者8。拼接以后,最后一维变成64+16或者64+8。然后这个整体结果再做attention。 |
| 额外学习 cvr中的item远比ctr中的少,并且cvr中高热item的样本占比很高,(多个模型单独训练然后再融合)然后我们通过融合公式来决定最终的排序,但是这样目前出现一个问题,推出的是一些高热,如果降低cvr的权重,用户留存及时长(我们关心的一个核心指标)会明显降低,一般这种会有哪些解决方案或者思路呢? 这种问题的原因是,你们对于新品的处理不够。也就是说,新商品的embedding,你们是如何处理的呢?是否只给了个默认值呢?这个默认值位于全局的什么位置呢? CTR = 0 的样本也会用来 CVR 网络吗? ctr=0的样本,也就是click=0的样本,包括有曝光无点击的,也包括有成交无点击的,前者是ctr网络的负样本,也会作为cvr网络训练的信息补充。后者是有问题的label,一般我们在实践中会将其剔除掉,避免其影响模型训练效果。 |
直接用ESMM输出的ctr,对比用DeepFM预测的ctr,应该差异不大吧?差异不是特别大。都可以的。
也可以使用esmm输出的ctr和cvr,再利用ctr*sigmoidCVR公式,作为最终排序。
train auc本身就比test auc偏高些,不过也可能存在轻微过拟合。
优化后的多任务模型里有self-attention,也有traditional-attention。
- target attention参照阿里的DIN论文。基本是参照那篇论文实现的。
核心——排序机制
若我们直接使用多目标模型预估出的ctcvr替代deepFM点击率单目标模型预估出的ctr,线上点击率指标是有明显下跌的,跌幅可能在20%+。
最终选择,沿用deepFM模型预估出的ctr分数,乘以使用MTL(多目标模型)预估出的cvr分数,多目标结构的cvr分数通过ctr间接计算得到,充分利用了已曝光未点击的样本信息,因此准确率相较于纯cvr模型,有较明显的优势。
直接相乘也有问题
这个现象的深层次原因是,成交存在巨大随机性,cvr预估结果极其不置信,即便是再高大上的模型,cvr预估的稀疏性和不确定性只能得到缓解,无法得到根除。因此,我们对MTL模型产出的cvr预估分数进行了值域约束,在ctr和cvr之间,选择更相信ctr预估结果,降低cvr分数对整体值域的影响。
传统attention
target attention
与self-attention相比,输入序列的两两元素之间无任何交互。
self-attention
点积缩放结构,

为什么要点积缩放?
- 点积模型的方差会较大,从而导致softmax函数的梯度较小(softmax后非0即1,无信息量)。缩放点积模型就可以很好地解决这个问题,使内积不至于太大。
- softmax函数值域[0,1]。
基于ESMM模型的多目标优化实践——蘑菇街商城篇 - 琦琦的文章 - 知乎 基于ESMM模型的多目标优化实践——蘑菇街商城篇 - 知乎