selenium+opencv处理滑块验证码
测试时间:2021年11月11日
大家做爬虫的时候肯定会遇到很多验证码列如本文所指的图像识别:
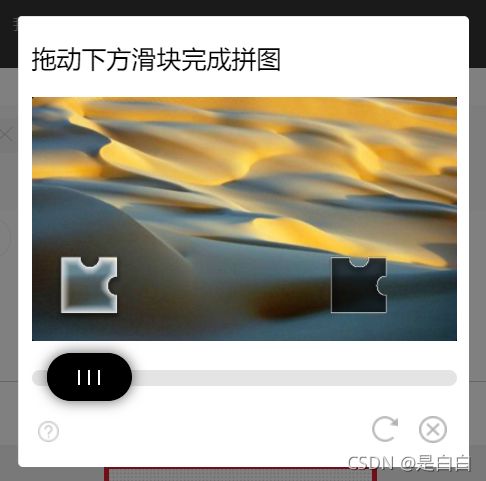
小伙伴们我讲的可能会比较啰嗦,还希望你们不要嫌弃
豆瓣提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。 https://www.douban.com/
https://www.douban.com/
这次以豆瓣登录为例:滑块验证码会在输入账号密码点击登录之后弹出来

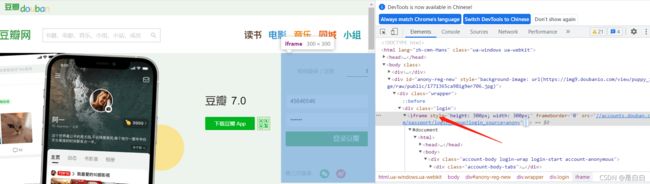
我们现在要做的呢就是获取账号和密码以及登录的元素 ,这个大家应该都会没啥好说的,注意的一点是这个登录界面是一个嵌套网页在iframe里面,需要先切入在获取元素不然获取不到
from selenium import webdriver
import requests
import cv2.cv2 as cv2
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver import ChromeOptions # 这个包用来规避被检测的风险
import time # 延迟
from selenium.webdriver import ActionChains # 动作链
option = webdriver.ChromeOptions()
option.add_experimental_option('useAutomationExtension', False)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver_path = r'驱动得位置' # 定义好路径
driver = webdriver.Chrome(executable_path=driver_path,options=option) # 初始化路径+规避检测
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
url='https://www.douban.com/'
def denglv():
driver.get(url)
time.sleep(4)
driver.switch_to_frame(driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')) #切入登录网址
dianjimimadenglv=driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]').click() #点击账号密码登录
time.sleep(1)
zhanghao=driver.find_element_by_xpath('//input[@id="username"]').send_keys('ununun') #输入账号
time.sleep(1)
mima=driver.find_element_by_xpath('//input[@id="password"]').send_keys('7878787878') #输入密码
time.sleep(2)
denglv=driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click() 现在我们需要获取背景图和滑块图不过滑块也是在iframe里面的,我们需要用代码切入到哪里去,不然直接操作元素是获取不到的,这里我们定义一个函数来写

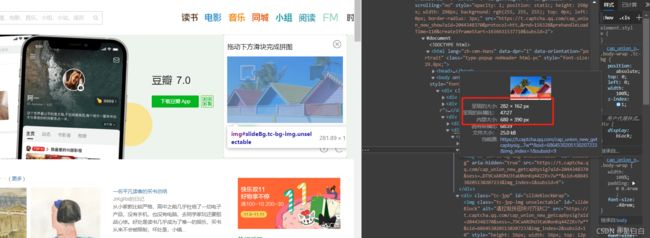
图片地址我们看到是在img标签里面的src属性,定位到之后我们直接使用requests.get_attribute方法去获取,还要将其转码成二进制码

def tupian():
driver.switch_to_frame("tcaptcha_iframe")
ele_bj = driver.find_element_by_xpath('//img[@id="slideBg"]') #背景图片
global ele_hk
ele_hk=driver.find_element_by_xpath('//img[@id="slideBlock"]')
src_bj = ele_bj.get_attribute('src')# 获取bj图片下载地址
src_hk = ele_hk.get_attribute('src')# 获取滑块图片下载地址
# 用resqust下载图片
content = requests.get(src_bj).content # 下载背景
f = open('bj.jpg', mode='wb')
f.write(content)
f.close()
print('下载完成背景图片')
time.sleep(1)
content1 = requests.get(src_hk).content # 下载滑块
f = open('hk.jpg', mode='wb')
f.write(content1)
f.close()
print('下载完成滑块图片')可以的朋友能努力坚持看到这里,不断学习的你真棒~
CV2的误区:
好了我们接下来就需要处理下载好的图片,我们需要导入CV2的包来处理,这里我要讲几个误区
首先是下载当初的我傻傻的直接pip install cv2 结果可想而知呜呜呜呜呜,正确的下载应该是:
pip install opencv-python还有就是如果直接import cv2之后它代码不会自动补全,这就很麻烦的呀,需要这样导入
import cv2.cv2 as cv2CV2处理图片:
先是读取背景图片和滑块的RGB码,也就是设计师常说的三色,读取完成之后我们需要将背景图灰度处理
灰度处理调用的是这个COLOR_BGR2GRAY,别选叉了哈
#读取图片的RGB
bj_rgb=cv2.imread('bj.jpg')
#灰度处理
bj_gray=cv2.cvtColor(bj_rgb,cv2.COLOR_BGR2GRAY)
#读取滑块的RGB
hk_rgb=cv2.imread('hk.jpg',0)接着匹配滑块在背景图的位置,然后获取图片位置
#匹配滑块在背景图的位置
res=cv2.matchTemplate(bj_gray,hk_rgb,cv2.TM_CCOEFF_NORMED)
#获取位置
location=cv2.minMaxLoc(res)
print(location)
这里返回的是两个一个是最好的值,一个是最差的值,直接获取452
print(location[2][0])不过这并不是代表要在网页上移动452个距离哦, 我们识别是下载下来的大图,网页上面显示的缩略图所以不能直接用这个数值去移动
这个时候我们要去计算缩放比了,在这之前我们先封装一下灰度处理得代码
def jiexi():
bj_rgb = cv2.imread('bj.jpg')
# 灰度处理
bj_gray = cv2.cvtColor(bj_rgb, cv2.COLOR_BGR2GRAY)
# 读取滑块的RGB
hk_rgb = cv2.imread('hk.jpg', 0)
# 匹配滑块在背景图的位置
res = cv2.matchTemplate(bj_gray, hk_rgb, cv2.TM_CCOEFF_NORMED)
# 获取位置
location = cv2.minMaxLoc(res)
print(location[2][0])
return location[2][0]最终得缺口位置等于之前获取得坐标比如x 【x乘于缩放图在除以原图】,但是还要减去滑块初始得位置 (x * 282 / 680)-22

我们需要写一个循环让它不断去尝试,如果我们没有拖动成功那么肯定是要刷新重新来,而如果成功了就没有刷新按钮则会报错对吧,我们写个while True: 从点击登录按钮开始循环

while True:
tupian()
x=jiexi()
x = int(x * 282 / 680)-22
print(x)
action = ActionChains(driver)
# 按住滑块元素
action.click_and_hold(ele_hk).perform()
# 滑动
action.move_by_offset(x, 0).perform()
# 松开鼠标
action.release(ele_hk).perform()
我测试得时候发现到松开鼠标得时候会报错,解决方法呢就是让他窗口全屏
driver.maximize_window()
不过有些网站会识别滑动轨迹得,这样就不行了我们需要模拟人手动拉得效果,这里我直接贴一段崔庆才博主得轨迹代码
def get_tracks(distance):
# 初速度
v = 0
# 计算间隔
t = 0.2
tracks = []
# 当前位移
current = 0
# 减速阈值
while current < distance:
# 加速度为正 2
a = 2
# 初速度 v0
v0 = v
# 当前速度 v = v0 + at
v = v0 + a*t
# 移动距离 x = v0t + 1/2 * a * t^2
move = v0 * t +0.5 * a * (t * t)
# 当前位移
current += move
# 加入轨
tracks.append(round(move))
v = v0 + a * t
return tracks然后修改一下之前循环部分得代码
while True:
tupian()
x=jiexi()
x = int(x * 282 / 680)-22
print(x)
tracks = get_tracks(x)
action = ActionChains(driver)
# 按住滑块元素
action.click_and_hold(ele_hk).perform()
# 用随机生成得轨迹滑动
for track in tracks:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform()
ActionChains(driver).move_by_offset(xoffset=5, yoffset=0).perform()
ActionChains(driver).move_by_offset(xoffset=-5, yoffset=0).perform()
# 松开鼠标
action.release(ele_hk).perform()
try:
time.sleep(3)
refresh = driver.find_element_by_xpath('//div[@id="reload"]').click() # 刷新按钮
except Exception as e:
break这两段代码呢,是因为模拟假装没拖准确超过了,然后在修正误差更像人手操作

测试结果也是完美成功呀
完整代码如下:
from selenium import webdriver
import requests
import cv2.cv2 as cv2
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver import ChromeOptions # 这个包用来规避被检测的风险
import time # 延迟
from selenium.webdriver import ActionChains # 动作链
option = webdriver.ChromeOptions()
option.add_experimental_option('useAutomationExtension', False)
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver_path = r'驱动得位置' # 定义好路径
driver = webdriver.Chrome(executable_path=driver_path,options=option) # 初始化路径+规避检测
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
url='https://www.douban.com/'
driver.maximize_window()
def denglv():
driver.get(url)
time.sleep(4)
driver.switch_to_frame(driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')) #切入登录网址
dianjimimadenglv=driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]').click() #点击账号密码登录
time.sleep(1)
zhanghao=driver.find_element_by_xpath('//input[@id="username"]').send_keys('ununun') #输入账号
time.sleep(1)
mima=driver.find_element_by_xpath('//input[@id="password"]').send_keys('7878787878') #输入密码
time.sleep(2)
denglv=driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[1]/div[5]/a').click() #点击登录
time.sleep(3)
while True:
tupian()
x=jiexi()
x = int(x * 282 / 680)-22
print(x)
tracks = get_tracks(x)
action = ActionChains(driver)
# 按住滑块元素
action.click_and_hold(ele_hk).perform()
# 滑动
for track in tracks:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform()
ActionChains(driver).move_by_offset(xoffset=5, yoffset=0).perform()
ActionChains(driver).move_by_offset(xoffset=-5, yoffset=0).perform()
# 松开鼠标
action.release(ele_hk).perform()
try:
time.sleep(3)
refresh = driver.find_element_by_xpath('//div[@id="reload"]').click() # 刷新按钮
except Exception as e:
break
def tupian():
driver.switch_to_frame("tcaptcha_iframe")
ele_bj = driver.find_element_by_xpath('//img[@id="slideBg"]') #背景图片
global ele_hk
ele_hk=driver.find_element_by_xpath('//img[@id="slideBlock"]')
src_bj = ele_bj.get_attribute('src')# 获取bj图片下载地址
src_hk = ele_hk.get_attribute('src')# 获取滑块图片下载地址
# 用resqust下载图片
content = requests.get(src_bj).content # 下载背景
f = open('bj.jpg', mode='wb')
f.write(content)
f.close()
print('下载完成背景图片')
time.sleep(1)
content1 = requests.get(src_hk).content # 下载滑块
f = open('hk.jpg', mode='wb')
f.write(content1)
f.close()
print('下载完成滑块图片')
def jiexi():
bj_rgb = cv2.imread('bj.jpg')
# 灰度处理
bj_gray = cv2.cvtColor(bj_rgb, cv2.COLOR_BGR2GRAY)
# 读取滑块的RGB
hk_rgb = cv2.imread('hk.jpg', 0)
# 匹配滑块在背景图的位置
res = cv2.matchTemplate(bj_gray, hk_rgb, cv2.TM_CCOEFF_NORMED)
# 获取位置
location = cv2.minMaxLoc(res)
print(location[2][0])
return location[2][0]
def get_tracks(distance):
# 初速度
v = 0
# 计算间隔
t = 0.2
tracks = []
# 当前位移
current = 0
# 减速阈值
while current < distance:
# 加速度为正 2
a = 2
# 初速度 v0
v0 = v
# 当前速度 v = v0 + at
v = v0 + a * t
# 移动距离 x = v0t + 1/2 * a * t^2
move = v0 * t + 0.5 * a * (t * t)
# 当前位移
current += move
# 加入轨
tracks.append(round(move))
v = v0 + a * t
return tracks
if __name__ == '__main__':
denglv()声明
本文仅限于做技术交流学习,请勿用作任何非法商用!