好家伙,基于Java+Selenium+HttpClient直接扒下某乎问题下1900多个回答
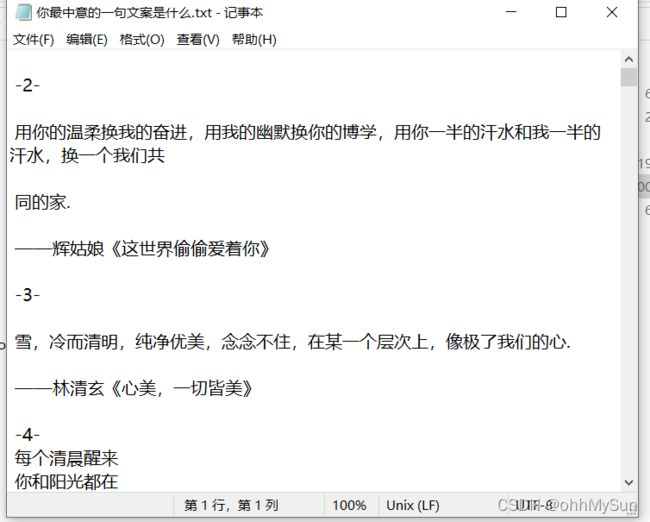
效果展示
一、网页分析
1、F12进入检查状态
正常步骤就是点开首页,用F12,可是我愣是没有找到关于回答的任何URL或者数据。我以前还用过Jsoup来直接获得问题下的所有回答,不过才扒下两个答案,效果不好。
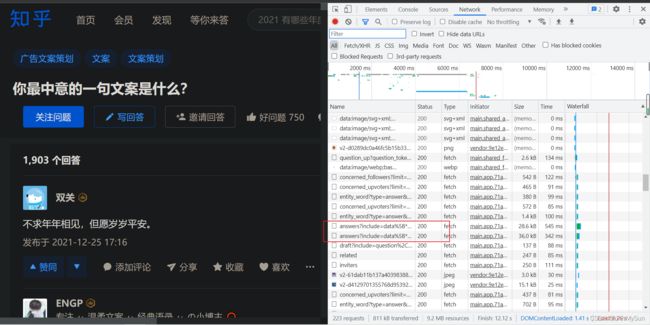
2、找jsonURL
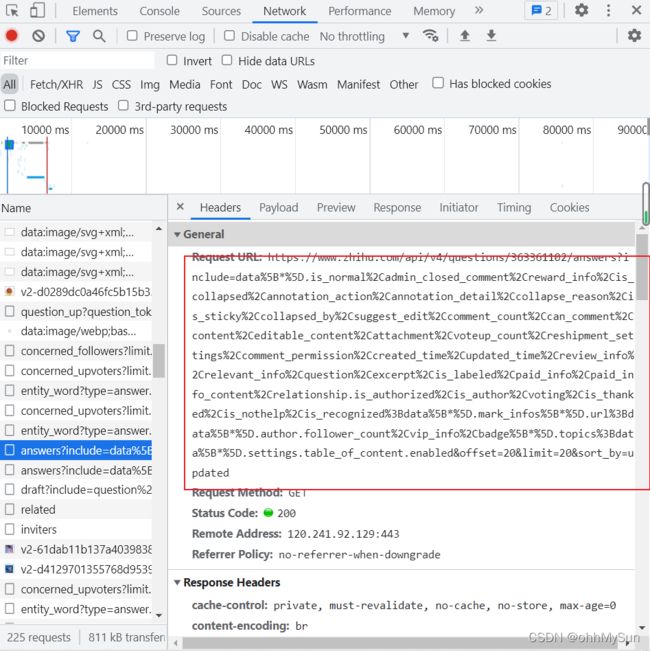
接着我按照时间顺序查看回答,找到了一个以answers开头的链接,大概就是它,包含回答的所有数据。两个随便一个点进去就能够得到回答的json数据了。我们复制后新建页面进去(嘿嘿嘿)
3、找具体的回答
一进去发现,嘿,了不得哦,每一个URL含有20条回答,而且还给出了上下页的回答,这对于我们学习爬虫的就很友善。
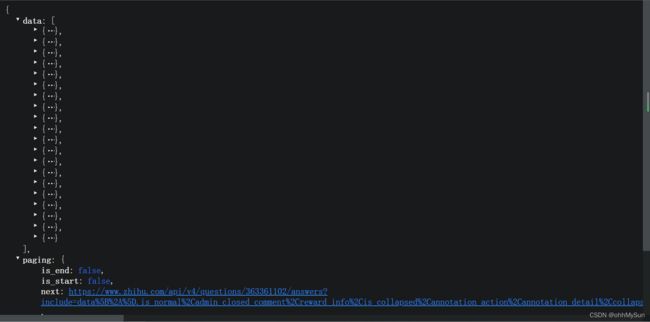
我们想要的回答就在“contents”中,看上去密密麻麻的,好像和原文不一样啊,多了一些前端的标签,没关系,后面敲代码的时候用正则匹配替换掉就行了,问题不大。

二、前期准备
1、注意细节
1、selenium导入
通过maven
org.seleniumhq.selenium
selenium-java
3.141.59
通过jar包直接导入
到selenium官网下载想要使用的版本(我用的是3.141.59),然后打开idea,点开File,找到Project Structure点击
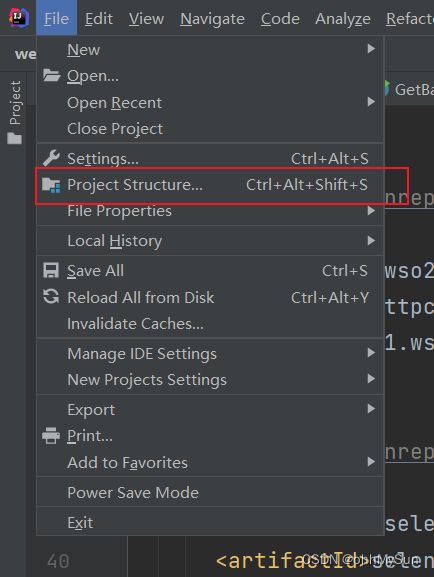

将刚刚下载的selenium jar 包直接添加上就OK了。
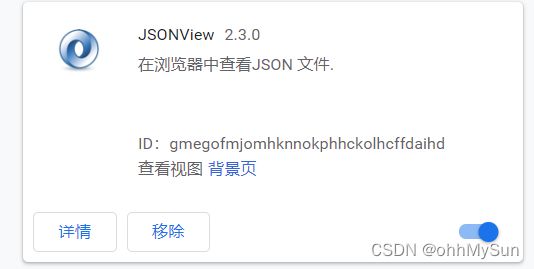
2、jsonview浏览器插件
可以到浏览器上的谷歌应用商店直接下载(需要科学上网)
2、获取思路
首先通过selenium将所有回答的json数据URL拿到,添加到ArrayList集合中,通过遍历该集合,使用Httpclient获取到所有的json数据,从而得到具体的回答。
其实就很简单的三步:获取回答数据json的URL,遍历得到所有json数据,定位到回答内容再获取。
1、获取json的URL
进行网页分析后,我已经知道每一个页面都会给出是否为首页或者尾页的判断,那么可以根据判断获得所有的URL

我们直接从首页开始获取,所以只需要判断 如果不是尾页 就获取下一页的URL。
/**
* 判断该json数据页面是否为首页或者尾页
* @param isEnd
* @param isStart
* @return 布尔
*/
public boolean isBegin(String isEnd,String isStart){
//在第一页才开始抓取,
/*
if((isEnd.equals("false") && isStart.equals("true")) || isEnd.equals("false") && isStart.equals("false")){
return true;
}
//其他情况都不抓取
return false;
*/
//或者直接isEnd == true 就不抓
if(isEnd.equals("true")){
return false;
}
else{
return true;
}
}
2、获取json数据
使用HttpClient,注意设置好默认编码格式,一开始我没注意到这个,得到的回答都是奇形怪状的字符。
/**
* 获取JSON格式的数据
* @param jsonURL
* @return JSON对象
* @throws Exception
*/
public JSONObject getJsonData(String jsonURL) throws Exception {
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//模拟是用户自己访问网址。
HttpGet httpget = new HttpGet(jsonURL);
httpget.addHeader("Accept", "text/html");
httpget.addHeader("Accept-Charset", "utf-8");
httpget.addHeader("Accept-Encoding", "gzip");
httpget.addHeader("Accept-Language", "en-US,en");
httpget.addHeader("User-Agent",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.160 Safari/537.22");
ResponseHandler responseHandler = new ResponseHandler() {
@Override
public String handleResponse(final HttpResponse response) throws ClientProtocolException, IOException {
int status = response.getStatusLine().getStatusCode();
if (status >= 200 && status < 300) {
HttpEntity entity = response.getEntity();
return entity != null ? EntityUtils.toString(entity, StandardCharsets.UTF_8) : null;
} else {
System.out.println(status);
System.exit(0);
throw new ClientProtocolException("Unexpected response status: " + status);
}
}
};
String responseBody = httpclient.execute(httpget, responseHandler);
return JSONObject.parseObject(responseBody);
} finally {
httpclient.close();
}
} 3、定位到content,获取并保存
/**
* 定位具体回答并获取
* @param jsonObject json数据对象
* @param answerList 保存回答的集合
*/
public void getDetail(JSONObject jsonObject,List answerList){
//获取到想要的json对象数组
JSONArray jsonList = jsonObject.getJSONArray("data");
String regex1 = "";
String regex2 = "
";
String regex3 = "";
String regex4 = "";
String regex5 = "
";
String regex6 = "p";
String content = "";
//要将content添加到answerList中,要添加回答的序号
for (int i = 0; i < jsonList.size(); i++) {
JSONObject answer = (JSONObject)jsonList.get(i);
content = answer.getString("content");
content = content.replaceAll(regex1," ");
content = content.replaceAll(regex2,"\n");
content = content.replaceAll(regex3,"");
content = content.replaceAll(regex4,"\n");
content = content.replaceAll(regex5,"\n");
content = content.replaceAll(regex6,"");
// System.out.println(i+" "+content);
answerList.add(content);
}
} 4、保存到本机硬盘
这个比较简单,需要注意的就是要用StringBuffer 从而不滥用内存
/**
* 遍历集合,将其中的内容全部保存到主机本地
* @param list 集合
* @param path 保存路径
* @param question 文件的名称(问题描述)
*/
public void traverse(List list,String path,String question) throws IOException {
File file = new File(path);
//路径不存在则要抛异常或者直接在这里新建一个。
if (!file.exists()) {
file.mkdirs();
}
//文件输出
FileOutputStream fos = null;
StringBuffer sb = new StringBuffer();
//要用到序号,所以还是用for循环
for (int i = 0; i < list.size(); i++) {
sb.append(i+"、"+list.get(i)+"\n");
}
byte[] bytes = sb.toString().getBytes();
fos = new FileOutputStream(path+"\\"+question+".txt");
fos.write(bytes);
fos.flush();
fos.close();
} 三、获取过程比较费时的部分
1、定位元素
以获取paging判断is_end和is_start为例,我还是比较直接用F12定位到该元素,想要直接用class或者id的属性得到它,但是我想得太简单了,敲这段代码不抛出no such element那个异常之前,我还以为很简单。
报错之后,我试了很多种方法,可谓是敲打吗五分钟,改bug两小时,最后还是用by.xpath方法一步步调式才得到最终的结果,在调式的过程中浏览器插件又神叨叨的出错,原因起初还不知道,后来发现是版本问题。
注意:在此还需要打开带有浏览器插件的模拟浏览器。添加一个option,参数是jsonview(即插件)的安装目录
ChromeOptions options =new ChromeOptions();
options.addArguments("load-extension=C:\\Users\\86150\\AppData\\Local\\Google\\Chrome\\User Data\\Default\\Extensions\\gmegofmjomhknnokphhckolhcffdaihd\\2.3.0_0");
2、用正则表达式匹配替换掉contents中的标签即其他属性名、参数
重新学了一遍正则,还好也不难,将这几个替换掉就和原文差不多了,剩下一些图片的链接。
for (int i = 0; i < jsonList.size(); i++) {
JSONObject answer = (JSONObject)jsonList.get(i);
content = answer.getString("content");
content = content.replaceAll(regex1," ");
content = content.replaceAll(regex2,"\n");
content = content.replaceAll(regex3,"");
content = content.replaceAll(regex4,"\n");
content = content.replaceAll(regex5,"\n");
content = content.replaceAll(regex6,"");
// System.out.println(i+" "+content);
answerList.add(content);
}
}四、源代码
1、GetJson(获取所有json数据的URL)
package indi.getzhihuAnswer;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.util.List;
/**
* 获取知乎某回答下的所有json数据的URL
* 方式一
* 使用selenium将所有JSONURL拿下
*/
public class GetJsonTest {
private List jsonList;
public GetJsonTest(List jsonURLList){
this.jsonList = jsonURLList;
}
/**
* 得到Json数据的URL
* @param url
* @param jsonList
*/
public void getJson(String url,List jsonList){
//设置不显示浏览器页面
ChromeOptions options =new ChromeOptions();
// options.addArguments("-headless");
options.addArguments("load-extension=C:\\Users\\86150\\AppData\\Local\\Google\\Chrome\\User Data\\Default\\Extensions\\gmegofmjomhknnokphhckolhcffdaihd\\2.3.0_0");
WebDriver driver = new ChromeDriver(options);
//先把第一页URL保存好
jsonList.add(url);
String nextURL = url;
String isEnd = "";
String isStart = "";
try{
int i = 0;
while(true){
driver.get(nextURL);
Thread.sleep(1000);
isEnd = driver.findElement(By.xpath("//div[@id = 'json' ]/ul/li[2]//ul/li[1]/span[2]")).getText();
isStart = driver.findElement(By.xpath("//div[@id = 'json' ]/ul/li[2]//ul/li[1]/span[2]")).getText();
//从第一页开始抓
if(isBegin(isEnd,isStart)){
// System.out.println("我喜欢摇滚");
nextURL = driver.findElement(By.xpath("//div[@id = 'json' ]/ul/li[2]//ul/li[3]//a")).getAttribute("href");
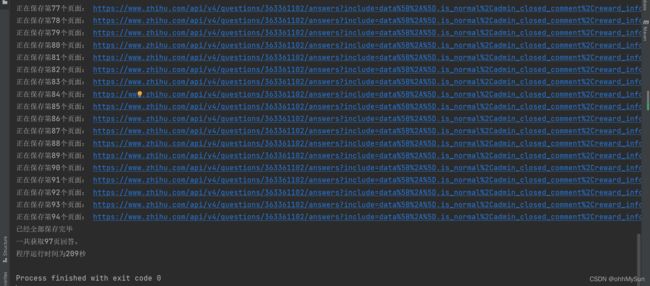
System.out.println("正在保存第"+i+++"个页面: "+nextURL);
jsonList.add(nextURL);
} else{
System.out.println("已经全部保存完毕");
break;
}
}
}catch(Exception e){
e.printStackTrace();
}finally {
driver.quit();
}
}
/**
* 判断该json数据页面是否为首页或者尾页
* @param isEnd
* @param isStart
* @return 布尔
*/
public boolean isBegin(String isEnd,String isStart){
//在第一页才开始抓取,
/*
if((isEnd.equals("false") && isStart.equals("true")) || isEnd.equals("false") && isStart.equals("false")){
return true;
}
//其他情况都不抓取
return false;
*/
//或者直接isEnd == true 就不抓
if(isEnd.equals("true")){
return false;
}
else{
return true;
}
}
public String getQuestion(String jsonURL) throws Exception{
ChromeOptions options =new ChromeOptions();
// options.addArguments("-headless");
options.addArguments("load-extension=C:\\Users\\86150\\AppData\\Local\\Google\\Chrome\\User Data\\Default\\Extensions\\gmegofmjomhknnokphhckolhcffdaihd\\2.3.0_0");
WebDriver driver = new ChromeDriver(options);
driver.get(jsonURL);
Thread.sleep(2000);
String question = driver.findElement(By.xpath("//div[@id = 'json' ]/ul/li[1]/ul/li[20]/ul/li[22]/ul/li[5]/span[2]")).getText();
Thread.sleep(1000);
driver.quit();
// question = question.replaceAll("?","");
question = question.replaceAll("?","");
question = question.replaceAll("\"","");
// question = question.replaceAll("?","");
return question;
}
}
2、GetParagaph(定位content并获取)
package indi.getzhihuAnswer;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import net.minidev.json.JSONValue;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.List;
/**
* 基于httpClient和selenium爬取某乎的某一回答下所有回答
* 这个文件为通过打开JSON数据只获取某一小段(即问题的回答),保存到主机硬盘
*/
public class GetParagaph {
//保存回答详情的StringBuffer对象
private List jsonURLList;
public GetParagaph(List jsonURLList){
this.jsonURLList = jsonURLList;
}
//无参
public GetParagaph(){
}
/**
* 获取JSON格式的数据
* @param jsonURL
* @return JSON对象
* @throws Exception
*/
public JSONObject getJsonData(String jsonURL) throws Exception {
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//模拟是用户自己访问网址。
HttpGet httpget = new HttpGet(jsonURL);
httpget.addHeader("Accept", "text/html");
httpget.addHeader("Accept-Charset", "utf-8");
httpget.addHeader("Accept-Encoding", "gzip");
httpget.addHeader("Accept-Language", "en-US,en");
httpget.addHeader("User-Agent",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.160 Safari/537.22");
ResponseHandler responseHandler = new ResponseHandler() {
@Override
public String handleResponse(final HttpResponse response) throws ClientProtocolException, IOException {
int status = response.getStatusLine().getStatusCode();
if (status >= 200 && status < 300) {
HttpEntity entity = response.getEntity();
return entity != null ? EntityUtils.toString(entity, StandardCharsets.UTF_8) : null;
} else {
System.out.println(status);
System.exit(0);
throw new ClientProtocolException("Unexpected response status: " + status);
}
}
};
String responseBody = httpclient.execute(httpget, responseHandler);
return JSONObject.parseObject(responseBody);
} finally {
httpclient.close();
}
}
/**
* 定位具体回答并获取
* @param jsonObject json数据对象
* @param answerList 保存回答的集合
*/
public void getDetail(JSONObject jsonObject,List answerList){
//获取到想要的数据
JSONArray jsonList = jsonObject.getJSONArray("data");
String regex1 = "";
String regex2 = "
";
String regex3 = "";
String regex4 = "";
String regex5 = "
";
String regex6 = "p";
String content = "";
//要将content添加到sb中,要添加回答的序号
for (int i = 0; i < jsonList.size(); i++) {
JSONObject answer = (JSONObject)jsonList.get(i);
content = answer.getString("content");
content = content.replaceAll(regex1," ");
content = content.replaceAll(regex2,"\n");
content = content.replaceAll(regex3,"");
content = content.replaceAll(regex4,"\n");
content = content.replaceAll(regex5,"\n");
content = content.replaceAll(regex6,"");
// System.out.println(i+" "+content);
answerList.add(content);
}
}
/**
* 获取知乎问题
* @param jsonObject
* @return 问题文案
*/
public String getQuestion(JSONObject jsonObject){
//获取到想要的数据
JSONArray jsonList = jsonObject.getJSONArray("data");
//随便取一个回答
JSONObject answer = (JSONObject)jsonList.get(3);
//获取其中一个关键字式question的JOSN对象
JSONObject questionObject = answer.getJSONObject("question");
String question = questionObject.getString("title");
return question.replaceAll("?","");
}
// public static void main(String[] args) throws Exception {
// String url = "https://www.zhihu.com/api/v4/questions/356488497/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=20&offset=0&sort_by=updated";
// GetParagaph g = new GetParagaph();
// g.getDetail(g.getJsonData(url),null);
// }
}
3、Downtown(保存到本地)
package indi.getzhihuAnswer;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
/**
* 遍历知乎回答集合,将集合里的元素全部保存到硬盘中
*/
public class Downtown {
//知乎回答集合
private List answerList;
//保存路径
private String path;
public Downtown(List answerList,String path){
this.answerList = answerList;
this.path = path;
}
/**
* 遍历集合,将其中的内容全部保存到主机本地
* @param list 集合
* @param path 保存路径
* @param question 文件的名称(问题描述)
*/
public void traverse(List list,String path,String question) throws IOException {
File file = new File(path);
//路径不存在则要抛异常或者直接在这里新建一个。
if (!file.exists()) {
file.mkdirs();
}
//文件输出
FileOutputStream fos = null;
StringBuffer sb = new StringBuffer();
//要用到序号,所以还是用for循环
for (int i = 0; i < list.size(); i++) {
sb.append(i+"、"+list.get(i)+"\n");
}
byte[] bytes = sb.toString().getBytes();
fos = new FileOutputStream(path+"\\"+question+".txt");
fos.write(bytes);
fos.flush();
fos.close();
}
/*
public static void main(String[] args) throws Exception{
String url = "https://www.zhihu.com/api/v4/questions/353386640/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cvip_info%2Cbadge%5B*%5D.topics%3Bdata%5B*%5D.settings.table_of_content.enabled&offset=20&limit=20&sort_by=updated";
String path = "D:\\program study\\爬虫\\ZhiHu\\answer";
String question = "i love u";
List list = new ArrayList<>();
Downtown d = new Downtown(list,path);
GetParagaph g = new GetParagaph();
g.getDetail(g.getJsonData(url),list);
d.traverse(list,path,question);
}
*/
}
4、Main方法(调用)
package indi.getzhihuAnswer;
import com.alibaba.fastjson.JSONObject;
import java.util.ArrayList;
import java.util.List;
/**
* 爬取某乎某个问题下的所有回答
*/
public class GetZhiHuAnswer {
//保存jsonURL的集合
private List jsonURLList;
//保存回答的集合
private List answerList;
public GetZhiHuAnswer(){
//创建对象的同时创建集合对象
jsonURLList = new ArrayList<>();
answerList = new ArrayList<>();
}
public static void main(String[] args) {
//某回答下的第一个页面URL
String firstURL = "https://www.zhihu.com/api/v4/questions/363361102/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=20&offset=0&sort_by=updated";
//保存路径
String path = "D:\\ZhiHu\\answer";
GetZhiHuAnswer gz = new GetZhiHuAnswer();
GetJsonTest gj = new GetJsonTest(gz.jsonURLList);
GetParagaph gp = new GetParagaph(gz.jsonURLList);
Downtown d = new Downtown(gz.answerList,path);
try{
long startTime = System.currentTimeMillis(); //获取开始时间
int i = 1;
//已经将所有的jsonURL保存到集合中了
gj.getJson(firstURL, gz.jsonURLList);
//在这里遍历,将文本回答添加至answerList集合中
for (String jsonUrl : gz.jsonURLList) {
JSONObject jsonObject = gp.getJsonData(jsonUrl);
gp.getDetail(jsonObject, gz.answerList);
i++;
}
d.traverse(gz.answerList,path,gp.getQuestion(gp.getJsonData(firstURL)));
System.out.println("一共获取"+i+"页回答。");
long endTime = System.currentTimeMillis(); //获取开始时间
System.out.println("程序运行时间为"+(endTime-startTime)/1000+"秒");
}catch (Exception e){
e.printStackTrace();
}
}
/*
//先获取json格式数据的所有URL
getAllJsonUrl();
//得到json数据,将数据转化成JSONObject对象
toJSONObject();
//通过JSONObject对象获取到data数据象数据
getAnswerData();
//从data里边找到含有回答的数据项Contents返回List类型数据
List answersList = getContents();
//遍历answerList集合,将数据保存到本机硬盘
saveAnswerData();
*/
}