「AutoML」强化学习如何用于自动模型设计(NAS)与优化?
作者&编辑 | 言有三
一直以来,网络结构的设计是一个非常需要经验且具有挑战性的工作,研究人员从设计功能更加强大和更加高效的模型两个方向进行研究,随着各类经典网络设计思想的完善,如今要手工设计出更优秀的模型已经很难,而以AutoML为代表的自动化机器学习技术就成为了大家关注的热点,其中用于搜索的方法包括强化学习,进化算法,贝叶斯优化等,本期我们首先介绍基于强化学习的方法。
1 模型结构搜索
Google在2017年利用强化学习进行最佳模型架构的搜索[1],引爆了自动设计网络模型(Neural Architecture Search,简称NAS)的研究热潮,其基本流程如下:

强化学习方法需要一些基本组件,包括搜索空间(search space),策略函数(policy),奖励指标(reward)。
搜索空间就是网络组件,也就是基本参数,包括滤波器数量,卷积核高、卷积核宽、卷积核滑动步长高、卷积核滑动步长宽等,如下图(分别是有跳层连接和无跳层连接),每一个参数的预测使用softmax分类器实现,跳层连接则使用sigmoid函数。
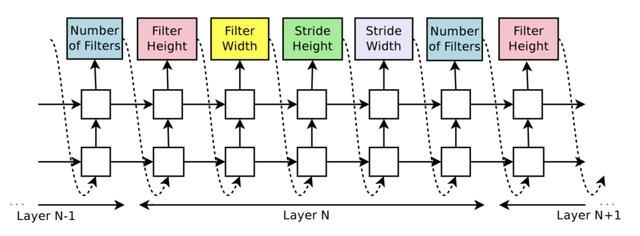

策略函数使用的就是RNN,实际是一个两层的LSTM,每一个隐藏层单元为35。之所以可以这么做是因为网络结构和连接可以使用一个变长的字符串进行描述,终止条件就是达到一定的层数。
奖励指标(reward)使用的是验证集上测试准确率,如下。
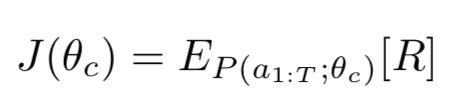
因为上述目标不可微分,所以需要进行近似如下:
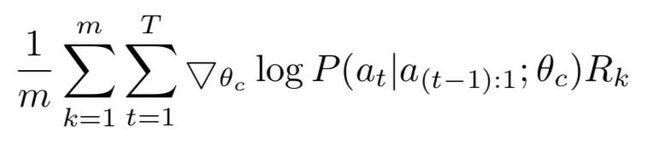
其中m是每一个batch采样的结构,T是需要预测的参数量,
使用了800个GPU训练了28天后,学习到的网络结构如下:

从上面的结构可以看出,它拥有以下特点:
(1) 跨层连接非常多,说明信息融合非常重要。
(2) 单个通道数不大,这是通道使用更加高效的表现。
以上研究催生了Google Cloud AutoML,并在2018年1月被Google发布,AutoML技术的研究开始进入高潮,这几年成为机器学习/深度学习的大热门。
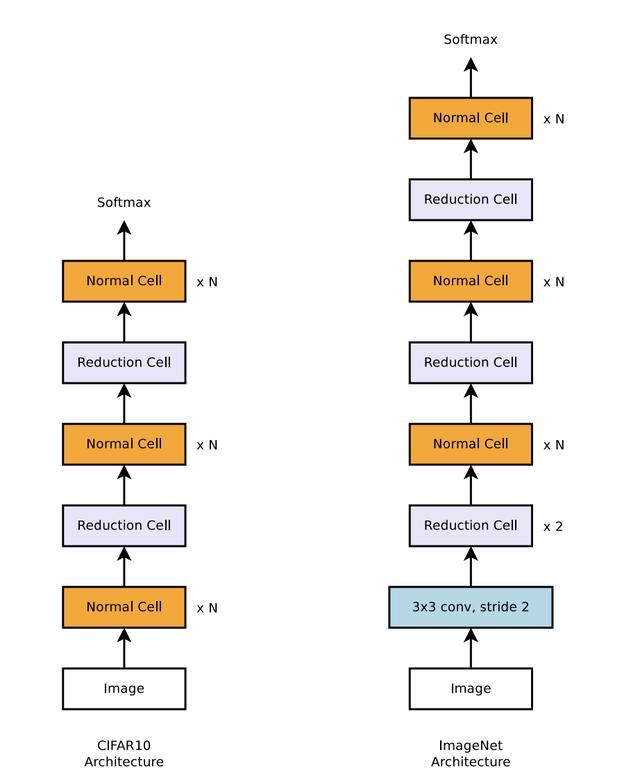
由于上述框架[1]的搜索空间过大,作者后来又其进行了改进,提出了NASNet[2]。NASNet的主要特点是它对网络结构的基本单元进行搜索而不是对整个网络进行搜索,其中两类基本单元分别是Normal Cell和Reduction Cell。
Normal Cell不降低特征图分辨率,Reduction Cell则将分辨率降低为原来1/2的,它们一起使用可以构建大部分网络架构,如下图的CIFAR10和ImageNet架构。
每一个Cell包含了若干个block,每一个block都包含了两个隐藏状态,两个对应的操作,以及融合操作,如下:

如上图灰色的是状态,黄色是对应状态的操作,绿色是融合操作,其中状态对应的操作从以下空间选择:

若干个block就可以组成一个cell,如下图展示了5个block组成的cell。

有了cell之后,我们就只需要定义好重复次数N和初始卷积滤波器的数量就得到了最终的网络结构,这也是当前大部分模型的搭建思想。这两个可以用经验值来设定,比如4@64,表示初始通道数为64,采用4个重复的单元,具体的学习方法与[1]一致。
2 模型结构优化
虽然NAS本身具有模型优化的功能,但是当前也有许多成熟的模型优化方法,比如模型剪枝,量化,蒸馏。
2.1 模型剪枝
AutoML for Model Compression(AMC)[3]是一个利用强化学习自动搜索并提高模型剪枝算法质量的框架,其完整的流程如下:
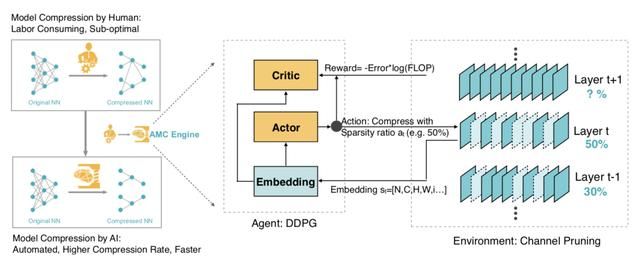
在一般的剪枝算法中,我们通常遵循一些基本策略:比如在提取低级特征的参数较少的第一层中剪掉更少的参数,对冗余性更高的FC层剪掉更多的参数。然而,由于深度神经网络中的层不是孤立的,这些基于规则的剪枝策略并不是最优的,也不能从一个模型迁移到另一个模型。
AMC方法便是在该背景下,利用强化学习自动搜索并提高模型压缩的质量,该框架是每一层进行独立压缩,前一层压缩完之后再往后层进行传播,t层接受该层的输入特征s_t,输出稀疏比率a_t,按照a_t对该层进行压缩后,智能体移动到下一层L_t+1,使用验证集精度作为评估。
作者们对两类场景进行了实验,第一类是受延迟影响较大的应用如移动APP,使用的是资源受限的压缩,这样就可以在满足低FLOP和延迟,小模型的情况下实现最好的准确率;这一类场景作者通过限制搜索空间来实现,在搜索空间中,动作空间(剪枝率)受到限制,使得被智能体压缩的模型总是低于资源预算。
另一类是追求精度的应用如Google Photos,就需要在保证准确率的情况下压缩得到更小的模型。对于这一类场景,作者定义了一个奖励,它是准确率和硬件资源的函数。基于这个奖励函数,智能体在不损害模型准确率的前提下探索压缩极限。
每一层的状态空间为(t, n, c, h, w, stride, k, FLOP s[t], reduced, rest, at−1),t是层指数,输入维度是n×c×k×k,输入大小是c×h×w,reduces就是前一层减掉的flops,rest是剩下的flops。
因为剪枝对通道数特别敏感,所以这里不再是使用离散的空间,如{128,256},而是使用连续的空间,使用deep deterministic policy gradient (DDPG)来控制压缩比率,完整的算法流程如下:

对于细粒度的剪枝,可以使用权重的最小幅度作为阈值,对于通道级别的压缩,可以使用最大响应值。在谷歌Pixel-1 CPU和MobileNet模型上,AMC实现了1.95 倍的加速,批大小为1,节省了34%的内存。在英伟达Titan XP GPU 上,AMC实现了1.53 倍的加速,批大小为50。
2.2 模型量化
同样的,量化也是模型压缩的另外一个技术,是学术界和工业界的重点研究方向,HAQ(Hardware-Aware Automated Quantization with Mixed Precision)[4]是一个自动化的混合精度量化框架,使用增强学习让每一层都学习到了适合该层的量化位宽。
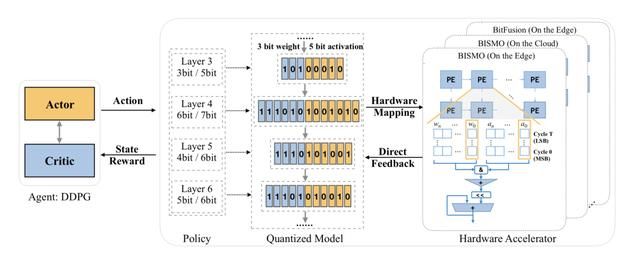
不同的网络层有不同的冗余性,因此对于精度的要求也不同,当前已经有许多的芯片开始支持混合精度。通常来说,浅层特征提取需要更高的精度,卷积层比全连接层需要更高的精度。如果手动的去搜索每一层的位宽肯定是不现实的,因此需要采用自动搜索策略。
另一方面,一般大家使用FLOPS,模型大小等指标来评估模型压缩的好坏,然后不同的平台表现出来的差异可能很大,因此HAQ使用了新的指标,即芯片的延迟和功耗。
搜索的学习过程是代理Agent接收到层配置和统计信息作为观察,然后输出动作行为即权值和激活的位宽,其中算法细节为:
(1) 观测值-状态空间,一个10维变量,如下:
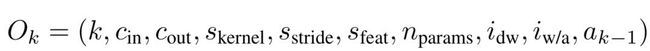
(2) 动作空间,使用了连续函数来决定位宽,离散的位宽如下:
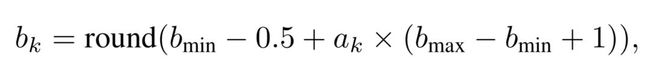
(3) 反馈,利用硬件加速器来获取延迟和能量作为反馈信号,以指导Agent满足资源约束。
(4) 量化,直接使用线性量化方法,其中s是缩放因子,clamp是截断函数。

(5) c的选择是计算原始分布和量化后分布的KL散度,这也是很多框架中的做法。

(6) 奖励函数,在所有层被量化过后,再进行1个epoch的微调,并将重训练后的验证精度作为奖励信号。

使用了深度确定性策略梯度(DDPG)方法进行优化,下图是在延迟约束下,MobileNet-V1/V2模型在边缘端和云端设备上的实验结果,与固定的8bit量化方法相比,分别取得了1.4倍到1.95倍的加速。
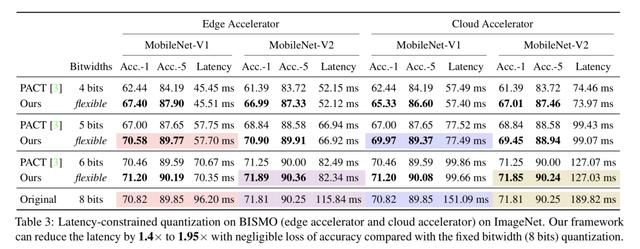
下图分别是边缘端和云端设备上MobileNet-V1各个网络层的量化特点,可以发现在边缘端设备上depthwise卷积有更少的bits,pointwise有更多,在云端则是完全相反。这是因为云设备具有更大的内存带宽和更高的并行性,而depthwise就是内存受限的操作,pointwise则是计算受限的操作,MobileNet-V2上能观察到同样的特点。

2.3 模型蒸馏
N2N learning[5]是一个基于强化学习的知识蒸馏框架,它使用增强学习算法来将teacher模型转化为student模型,框架结构如下:
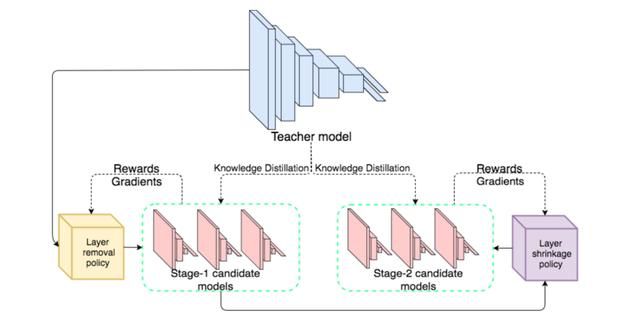
N2N learning基于一个假设,即一个教师网络转化成学生网络的过程可以看作是马尔可夫决策过程Markov Decision Process(MDP),当前的步骤只和有限的之前几步有关系,使用增强学习来进行优化,其基本概念如下:
状态S:将网络的架构作为状态,对于任何一个大的网络,采样后比它小的网络都很多,所以状态空间非常大。
动作A与状态转换T:包括层的缩减以及移除操作。这一个过程通过双向LSTM来实现,它会观察某一层与前后层的关系,学习到是否进行约减或者删除。
奖励r:模型压缩的目标是保证精度的同时尽可能压缩模型,因此reward就是压缩率。
在上图结构中包括了两个动作,实际进行优化时依次进行:
(1) 首先选择一组动作,用来判断当前层的去留;
(2) 然后使用另一个策略选择一组动作,用来决定剩下每一层的裁剪程度,伪代码流程如下:

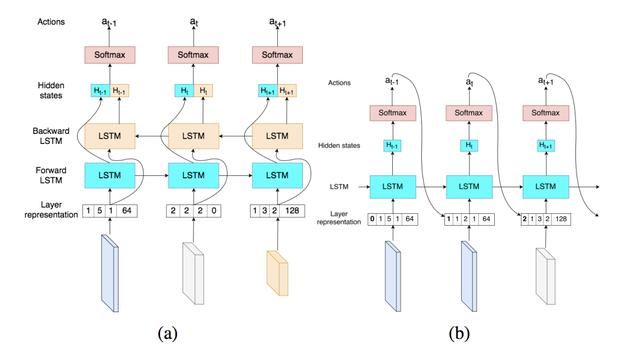
以上两种动作使用的LSTM也有差异,下图(a)是层的去留使用的LSTM,可以看出是一个双向的LSTM,要同时考虑前向和反向的中间状态。
下图(b)是层的裁剪使用的LSTM,可以看出是一个单向的LSTM,其中at的值范围是[0.1,0.2,...,1],表示压缩率。
而奖励reward公式如下:
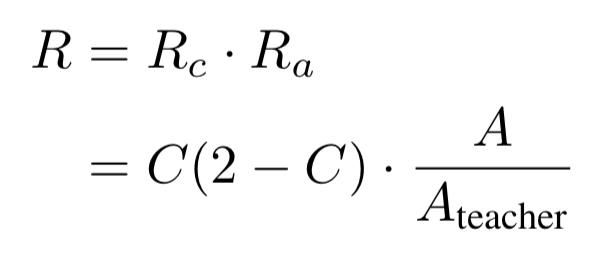
其中C表示压缩率,A表示学生模型准确率,Ateacher表示教师模型准确率,教师网络的输出作为学生网络的真值。
损失函数包括两项,分别是学生网络的分类损失以及蒸馏损失,其中蒸馏损失中教师网络的输出作为学生网络的真值,使用L2距离。
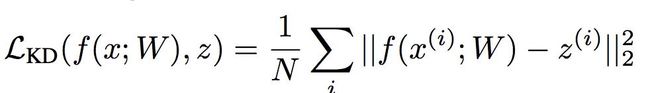

实验结果如下:
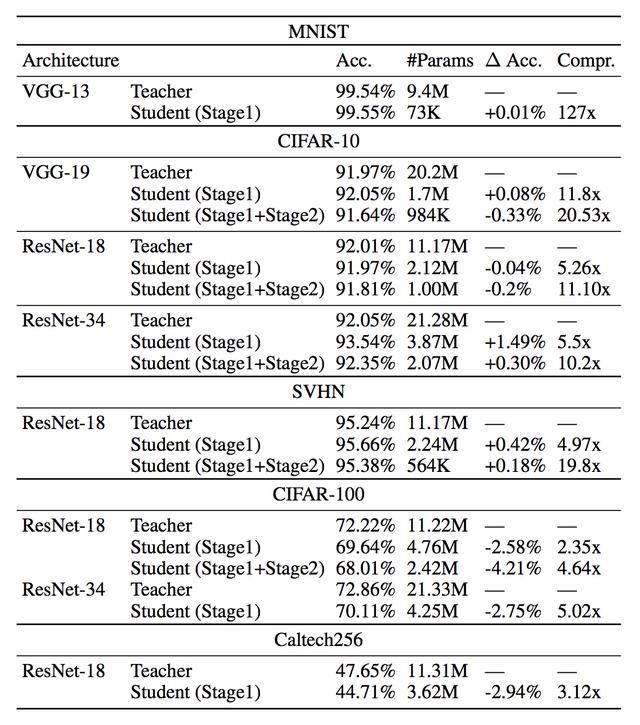
从结果来看,实现了非常高的压缩率,并且性能下降不明显。
3 关于模型优化
如果说要我在深度学习这么多方向里选择一个的话,我会毫不犹豫地选择模型优化,这也是一直在做的事情。公众号写过很多的模型解读了,如下是一些文章总结和直播链接以及资源下载。
「完结」总结12大CNN主流模型架构设计思想
「总结」言有三&天池深度学习模型设计直播汇总,赠超过200页课件
知识星球也有一个模型结构1000变板块,比公众号的内容更深更广。其中的模型优化部分主要包括紧凑模型的设计,剪枝,量化,知识蒸馏,AutoML等内容的详细解读,感兴趣可以移步。

[1] Zoph B, Le Q V. Neural Architecture Search with Reinforcement Learning[J]. international conference on learning representations, 2017.
[2] Zoph B, Vasudevan V, Shlens J, et al. Learning Transferable Architectures for Scalable Image Recognition[J]. computer vision and pattern recognition, 2018: 8697-8710.
[3] He Y, Lin J, Liu Z, et al. Amc: Automl for model compression and acceleration on mobile devices[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 784-800.
[4] Wang K, Liu Z, Lin Y, et al. HAQ: Hardware-Aware Automated Quantization with Mixed Precision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 8612-8620.
[5] Ashok A , Rhinehart N , Beainy F , et al. N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning[C]// ICLR 2018. 2017.