三元组法矩阵加法java_推荐系统之隐含语义模型LFM(3)Java代码
前面两篇文章提到(推荐系统之隐含语义模型LFM(1) 推荐系统之隐含语义模型LFM(2)负样本采集 ),我们可以获取用户-物品(User-Item)偏好度矩阵,而根据计算用户u对物品i偏好度的公式:

可知,我们还缺一个关键的K——隐因子。只有知道了K,我们才能将User-Item这个u*i的矩阵分解成Q(u,K)、P(i,K)两个矩阵。
先从矩阵分解说起,常用的奇异值分解(SVD)。矩阵R分解为:

K一般远远小于u、i的数量。
所以,如果我们预测第i个用户对第j个物品的偏好度,计算
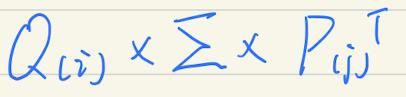
即可。
但是SVD也有其局限性:
- SVD要求被分解的矩阵是稠密的。但从实际生活角度看,无论是购物、听音乐、看电影等,User-Item都是稀疏的。以我个人为例,2019年国内上映的电影共89部,而我也只看了16部,还不到五分之一。如果再扩大到全球历年上映的影片,我个人对这些影片偏好度的矩阵就极其稀疏了。另外,如果将这个稀疏的矩阵通过SVD分解降维,就要进行数据填充,使得这个矩阵的空间需求过大,算法复杂度大增。并且简单粗暴地填充数据也会导致数据失真。
- SVD时间复杂度较高,m*n的矩阵,时间复杂度大概就是n的3次方,在用户数、物品数极大的情况下进行分解,代价太大。
所以这才有了下面要说的优化变种算法Funk-SVD。后面还出现了Basic-SVD、SVD++等,都是基于此算法的。
Funk-SVD算法的基本思路就是,将稀疏的User-Item矩阵R,分解成用户-隐因子矩阵Q,物品-隐因子矩阵P,则有:

那么用户u对物品i的偏好度的预测值:
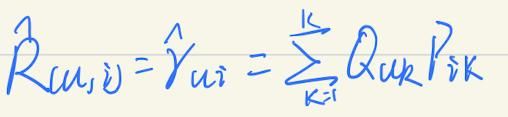
拿用户u对物品i的真实偏好度与预测值相比较,差值越小,则说明预测越准。这里使用和方差SSE作为评测指标,则有:

SSE计算的是真实值与预测值误差的平方和,越趋近于0,说明预测的越准,拟合度越高。
为了防止过拟合,加入L2的正则化项,可得:

其中u、i都是训练集中用户对物品有偏好的数据。
- r(u,i)是用户u对物品i的真实偏好度。
- λ是正则化系数
- e(u,i)是真实值与预测值的误差。
通过随机梯度下降法不断地去学习,使学习出来的Q、P计算得到的预测矩阵逼近真实矩阵R。
首先要求Q(u,k)和P(i,k)的偏导数:
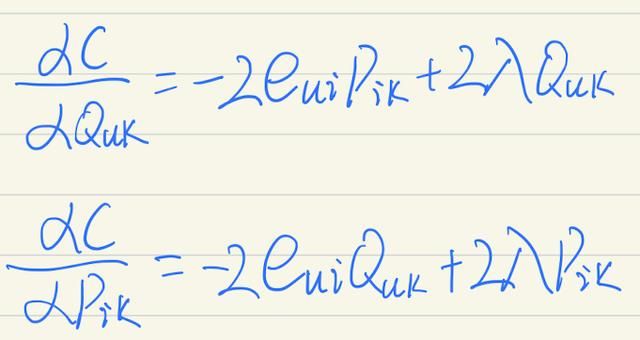
根据随机梯度下降法的要求,我们要按负梯度方向前进,递推公式如下:

- α是学习速率。
- λ是正则化参数。
Java代码如下:
import java.io.BufferedReader;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;import java.util.Collections;import java.util.Comparator;import java.util.List;import java.util.Map;import java.util.Map.Entry;import com.google.common.collect.Lists;import com.google.common.collect.Maps;public class LFM { private double α = 0.02;// 梯度下降学习速率,步长 private static final int F = 100;// 隐因子数 private static final double λ = 0.01;// 正则化参数,防止过拟合 private static final int iterations = 100;// 迭代求解次数 private Map userF = Maps.newHashMap();// 用户-隐因子矩阵 private Map itemF = Maps.newHashMap();// 物品-隐因子矩阵 public static void main(String[] args) { long start = System.currentTimeMillis(); LFM lfm = new LFM(); Map> userItemRealData = lfm.buildInitData(); lfm.initUserItemFactorMatrix(userItemRealData); lfm.train(userItemRealData); lfm.getRecommondItemByUserId(1, 10, userItemRealData); // lfm.getRecommondItemByUserId(2, 10, userItemRealData); // lfm.getRecommondItemByUserId(3, 10, userItemRealData); long end = System.currentTimeMillis(); System.out.println("耗时" + (end - start) / 1000 + "秒"); } /** * 构建初始数据
* 实际开发中,应该读取日志,格式类似:userId,itemId,评分
* 本例采用随机数 * * @return */ public Map> buildInitData() { Map> userItemRealData = Maps.newHashMap(); System.out.println("读取数据......"); String dataPath = "数据文件/ratings.csv"; BufferedReader br = null; try { br = new BufferedReader(new InputStreamReader(new FileInputStream(dataPath), "utf-8")); String line = null; Map itemRating = null; while ((line = br.readLine()) != null) { String[] dataRating = line.split(","); Integer userID = Integer.valueOf(dataRating[0].trim()); Integer itemID = Integer.valueOf(dataRating[1].trim()); double rating = Double.parseDouble(dataRating[2]); if (userItemRealData.containsKey(userID)) { itemRating = userItemRealData.get(userID); itemRating.put(itemID, rating); } else { itemRating = Maps.newHashMap(); itemRating.put(itemID, rating); userItemRealData.put(userID, itemRating); } } br.close(); } catch (IOException e) { e.printStackTrace(); System.exit(1); } return userItemRealData; } /** * 初始化用户-隐因子、物品-隐因子矩阵
* 使用随机数进行填充,随机数应与1/sqrt(隐因子数量)成正比 * * @param userItemRealData */ public void initUserItemFactorMatrix(Map> userItemRealData) { for (Entry> userEntry : userItemRealData.entrySet()) { // 随机填充用户-隐因子矩阵 int userId = userEntry.getKey(); Double[] randomUserValue = new Double[LFM.F]; for (int j = 0; j < LFM.F; j++) { randomUserValue[j] = Math.random() / Math.sqrt(LFM.F); } this.getUserF().put(userId, randomUserValue); // 随机填充物品-隐因子矩阵 Map itemMap = userItemRealData.get(userId); for (Entry entry : itemMap.entrySet()) { int itemId = entry.getKey(); if (this.getItemF().containsKey(itemId)) { continue;// 物品-隐因子矩阵已存在,不再做处理 } Double[] randomItemValue = new Double[LFM.F]; for (int j = 0; j < LFM.F; j++) { randomItemValue[j] = Math.random() / Math.sqrt(LFM.F); } this.getItemF().put(itemId, randomItemValue); } } } /** * 训练 * @param userItemRealData */ public void train(Map> userItemRealData) { for (int step = 0; step < LFM.iterations; step++) { System.out.println("第" + (step + 1) + "次迭代"); for (Entry> userEntry : userItemRealData.entrySet()) { int userId = userEntry.getKey(); Map itemMap = userItemRealData.get(userId); for (Entry entry : itemMap.entrySet()) { int itemId = entry.getKey();// 物品ID double realRating = entry.getValue();// 真实偏好度 double predictRating = this.predict(userId, itemId);// 预测偏好度 double error = realRating - predictRating;// 偏好度误差 Double[] userVal = this.getUserF().get(userId); Double[] itemVal = this.getItemF().get(itemId); for (int j = 0; j < LFM.F; j++) { double uv = userVal[j]; double iv = itemVal[j]; uv += this.α * (error * iv - LFM.λ * uv); iv += this.α * (error * uv - LFM.λ * iv); userVal[j] = uv; itemVal[j] = iv; } } } this.α *= 0.9;// 按照随机梯度下降算法的要求,学习速率每步都要进行衰减,目的是使算法尽快收敛 } } /** * 获取用户对物品的预测评分 * * @param userId * @param itemId * @return */ public double predict(Integer userId, Integer itemId) { double predictRating = 0.0;// 预测评分 Double[] userValue = this.getUserF().get(userId); Double[] itemValue = this.getItemF().get(itemId); for (int i = 0; i < LFM.F; i++) { predictRating += userValue[i] * itemValue[i]; } return predictRating; } /** * 获取用户TopN推荐 * @param userId * @param count * @param userItemRealData * @return */ public List> getRecommondItemByUserId(int userId, int count, Map> userItemRealData) { Map result = Maps.newHashMap(); Map realItemVal = userItemRealData.get(userId); Map predictItemVal = this.getItemF(); // double lowestVal = Double.NEGATIVE_INFINITY;// 最小偏好度,初始为负无穷大 for (Integer itemId : predictItemVal.keySet()) { if (realItemVal.containsKey(itemId)) { continue;// 预测偏好度的物品在真实偏好度物品中,不处理 } double predictRating = this.predict(userId, itemId);// 预测值 if (predictRating < 0) { continue; } result.put(itemId, predictRating); } List> list = Lists.newArrayList(result.entrySet()); Collections.sort(list, new Comparator>() { // 降序 public int compare(Map.Entry o1, Map.Entry o2) { if (o2.getValue() > o1.getValue()) { return 1; } else if (o2.getValue() < o1.getValue()) { return -1; } else { return 0; } } }); List> topN = list.subList(0, count); System.out.println("用户" + userId + "前" + count + "个推荐结果:"); for (Entry entry : topN) { System.out.println(entry.getKey() + ":" + entry.getValue()); } return topN; } public Map getUserF() { return userF; } public void setUserF(Map userF) { this.userF = userF; } public Map getItemF() { return itemF; } public void setItemF(Map itemF) { this.itemF = itemF; }}有两点要说一下:
- 训练集采用的是MovieLens的数据,地址:https://grouplens.org/datasets/movielens/,我选的是最小的数据集ml-latest-small.zip,下载地址:http://files.grouplens.org/datasets/movielens/ml-latest-small.zip。其中的ratings.csv就是用户对电影的评分数据。
- LFM其实更适合预测用户对物品的评分(偏好度),当然了,评分越高自然越推荐了。在getRecommondItemByUserId()方法中,取出TopN推荐,我使用的方法其实不怎么优化,完全可以使用优先队列来处理。