HiveSQL
HiveSQL
Hive Sql 入门教程基础关键字用法
前置教程
- hive库表知识
hive库是表的一个集合,一个库拥有多个表,hive整个数据库拥有多个库。
hive表代表一个对象,比如一个人设计为一个表就有身高体重等属性,在hive
中实际存储表现为每张表会有一个存储地址,比如表名为people,实际存储会有
- hive中的分区概念
/xx/xx/people,hive中引用了一个很重要的概念分区,分区实际上也是这个表的字段,反映在
实际存储中通常以天为分区,存储在址为/xx/xx/people/2019-01-01/ 相当于把01号的数据只在写在
/xx/xx/people/2019-01-01/这个目录下,目的是为了减少hive处理时的数据量
- 表的字段有多种数据类型
int 数值 12
float 浮点数(就有是小数这种)12.22
string 字符串类型 哄哄
timestramp 时间戳类型 2019-01-01 12:23:42
这几种类型基本能覆盖90%的场景
1.* 代表查询所有字段
select * from tablea
2.查询指定字段
select name,age from tablea
3.limit 限制查询条数
select name,age from tablea limit 10
4.where 代表限定条件
select name,age from tablea where name=‘honghong’
5.where 后面加多个条件
select name,age from tablea where name=‘honghong’ and age=123
6.查询条件是字符串的加上’’
select * from tablea where name=‘honghong’
7.查询条件是数值,
select * from tablea where age=12
8.对于分区,如何判断是不是分区表,执行这个命令show partitions 表名,
如果不报错的话,能看到结果比如dt=2019-01-01 dt就代表分区字段
证明存在分区2019-01-01,需要看下表结构分区字段的数据类型基本上都是字符串类型
9.查询分区数据
select * from tablea where dt=‘2019-01-01’
10.查询多个分区的数据
select * from tablea where dt>‘2019-01-01’ and dt<‘2019-01-10’
11.distinct的用法,distinct 的用途就是去重
表数据
age name
12 honghong
12 honghong
select distinct age,name from tabela
只能查出来一条数据
12,honghong
distinct 只能出现在最前面
13.group by 的用法
group by 翻译成中文就是分组做一些运算,通常与聚合函数配合使用
select city,sum(money) from tablea group by city
翻译成中文就是按城市,求和
select sum(money) from tablea
对所有数据求和
常见的出错写法
select city,sum(money) from tablea select sum(money) from tablea group by city
聚合函数还有max(),min(),count()
14.order by 对数据排序
select id,name from tablea order by id
对数据按id进行排序,默认是按升序,如果要按降序进行在最后加一个desc
在hive中用了order by 要加limit
15.like的用法,like主要用于模糊匹配
select * from tablea where name like ‘%honghong%’
查找name中含有honghong这个字的数据
16.in关键字的用法
select name from table where name in (‘honghong’,‘dou’)
查询name 等于 honghong,dou的数据
17.between and的用法
select id,name from table where id between 12 and 23
包括12,23
18.笛卡尔积
demo
tablea
id name
1 honghong
2 ma
id age
1 12
1 23 select * from tablea,tableb
这样会产生2*2条数据,通常会要tablea.id=tableb.id这种类型的
select * from tablea,tableb
where tablea.id=tableb.id
and tableb.age=12–from 后直接跟多张表就会产生笛卡尔积
where条件是最后的操作,从四条数据中选出符合条件的,这种
通常会产生巨大的中间结果,不建议19.join
join 按照条件把数据连接起来
以18为例
select * from
tablea
join
tableb
on tablea.id=tableb.id
where tableb.age=12
这种只会产生两条中间数据
id name id age
1 honghong 1 12
1 honghong 1 23
where 的顺序在on后面这样只会处理两条数据20.left join
select * from
tablea
left join
tableb
on tablea.id=tableb.id
left join 会把左表的数据全查出来
以18的数据为例
id name id age
1 honghong 1 12
1 honghong 1 23
2 ma null null21.right join
right join 会把右表的数据全查出来
select * from
tablea
right join
table
on tablea.id=tableb.id22.case when 的用法
select case when id=1 then ‘北京’
when id=2 then ‘上海’
else ‘天津’ end as city
from
tablea
23.count()用法
count通常用来计数
select count(*) from tablea
tablea的记录数select count(if(id=1,true,null)) from tablea
查询 id=1的记录数
select count(distinct id) fron tablea
先对id 进行去重再统计数量
24.if的用法
select if(id=1,‘北京’,‘上海’) from talbea
如果id=1这个值为北京,否则为上海25.and
and 代表多个条件都要满足
if(tc.job_type=‘IMPORT’ AND job_accepted_time>3,‘Y’,‘N’)
满足两个条件的话,值为Y,否则为N26or
or代表满足其中一个
if(tc.job_type=‘IMPORT’ or job_accepted_time>3,‘Y’,‘N’)
只要满足一个条件,值为Y,否则为N以上都是基本操作
发现有几个问题
当有分区表和left join 时
select *
from tablea
left join
tableb on
tablea.id=table.id
写成下面这种子查询的方法select
*
from
(select * from tablea
where dt=‘2019-01-01’) taleft join
(select * from tablea
where dt=‘2019-01-01’) tb
on ta.id=tb.id
容易犯的错误最外面用的字段,一定要先在子查询中查出来
group by 与聚合函数一定要配合使用27 union all
把数据合起来,条件是字段名与类型必须相同
select id,name from tablea
union all
select id,namea as name from tableb写sql注意理清结构,需要什么数据,在哪个表里,是不是分区表,
范围是多少,一段一段写
hive日期函数地址
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-DateFunctions
返回类型 函数 描述
int day(string date) dayofmonth(date) Returns the day part of a date or a timestamp string: day(“1970-11-01 00:00:00”) = 1, day(“1970-11-01”) = 1.
附加操作
数据插入
tabela 的结构为
id int
name string
1.插入多条数据
insert into table 表名
values(1,‘honghong’),(2,‘ma’)
2.插入覆盖之前的数据
insert overwrite table 表名
values(1,‘honghong’),(2,‘ma’)
会把之前的历史数据覆盖掉
3.查询插入
从表中把数据查出来插入到表a中
insert into tablea select * from tableb
4.对分区表中插入数据
insert overwrite table 表名 partition(dt=‘2019-01-01’)
对2019-01-01这个分区插入数据
Hive 启动及命令
一、hive启动的两种方式:1、直接启动 2、Hive thrift服务
1 hive直接启动:找寻你所在安装的hive文件下的hive驱动 我的驱动是在apps/apache-hive-1.2.1-bin/hive下 执行驱动就可以将hive启动起来
[hadoop@mini1 ~]$ cd apps/apache-hive-1.2.1-bin/
[hadoop@mini1 apache-hive-1.2.1-bin]$ bin/hive
2、Hive thrift服务:将hive作为一个服务器,通过另一个节点用beeline去连接 具体操作如下:
[hadoop@mini1 ~]$ cd apps/apache-hive-1.2.1-bin/
[hadoop@mini1 apache-hive-1.2.1-bin]$ bin/hiveserver2 //先作为服务器启动
重新开一个mini1窗口
[hadoop@mini1 ~]$ cd apps/apache-hive-1.2.1-bin/
[hadoop@mini1 apache-hive-1.2.1-bin]$ bin/beeline //先启动beeline节点,然后在连接你启动的hive服务器// 当进去beeline节点后执行下面操作
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: hadoop //该账号为你登录的服务器用户名
Enter password for jdbc:hive2://localhost:10000: ****** //密码为服务器密码
二、Hive命令之表的操作
现在在一种hive启动下的进行如下操作:
1、创建内部表
create table user(id int,name string)row format delimited fields terminated by ‘,’;//以逗号分隔要导入数据的信息
create table user(id int,name string) row format delimited fields terminated by ‘,’;//以逗号分隔要导入数据的信息
2、向内部表导入数据: hadoop fs -put user.txt /user/hive/warehouse/shizhan03.db/user
导入的数据内容如下:
01,liyaozhou
02,fangjingli
03,wangjun
04,liuyang
05,wangkang
06,malin
07,qianghua
08,gaoyixing
09,huanglichang
10,zhaoliangliang
3、查看内部表信息:select * from user;
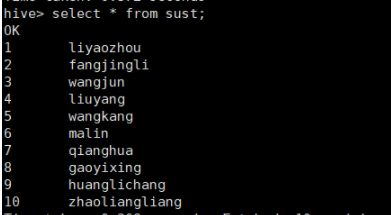
现在在第二种hive启动方式下进行如下操作:
4、创建外表:0: jdbc:hive2://localhost:10000> create external table user1(id int,name string) //创建表名为user1
> row format delimited fields terminated by ‘,’ //使用逗号进行分隔
> stored as textfile //存储形式为文本类型
> location ‘/SUST’; // 指定创建的表存在哪个目录下
5、向外表导入数据:导入的数据内容和内表一样
0: jdbc:hive2://localhost:10000> load data local inpath ‘/home/hadoop/hadoop/susut.txt’ into table sust1;//引导里面是你的导入数据的路径,后面指明你要导入的表
6、外表和内表的区别:
Hive 创建内部表时,会将数据移动到数据仓库指定的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
7、删内表:drop table sust;删除外表:drop table sust1:
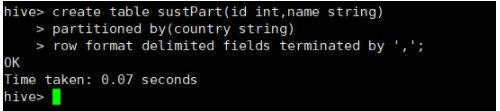
8、创建带分区的内表:
o:jdbc:hive2://loacalhost:10000>create table sustpart(id int ,name string)//创建表名为sust1
/> partitioned by(country string) // 按国家进行分区
/> row format delimited fields terminated by ‘,’;
9、将不同国家的数据导入按国家分区的表中 先创建一个不同国家的数据
数据源如下:
01,anbei
02,cangjingkong
03,meihuizi
04,xiaotianyilang
05,taijun
06,xiaoquan
07,riben
08,bendaohuizi
09,guangdao
10,changqi
先导入中国的数据:
load data local input ‘/home/hadoop/sust.txt’ into table table sustPart partition(country=‘China’);
在导入另一个国家的数据:
load data local inpath ‘/home/hadoop/sust.tex.japan’ into table sustPart partition(country=‘Japan’);
10、查看分区:select * from sustpart;
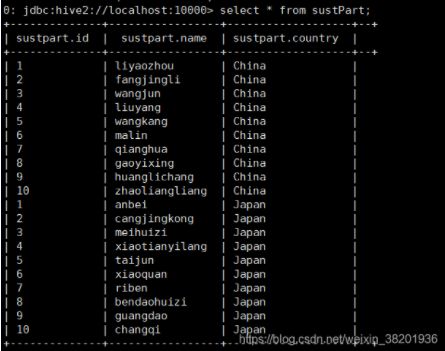
11、根据分区进行查找人名 select count(1) from sustpart where country=‘China’ group by (name=‘liyaozhou’);
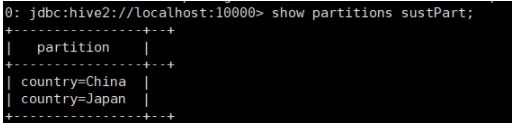
12、展示分区:show partitions+表名;如 show partitions sustpartion;
13、增加分区:alter table sustpart add partition(country=‘america’);
14、减少分区:alter table sustpart drop partition(country=‘america’);
15、表名重命名:alter table +表名 rename to +新表名;
hive经典练习50题
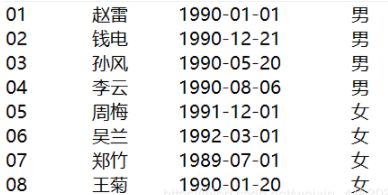
数据展示
student
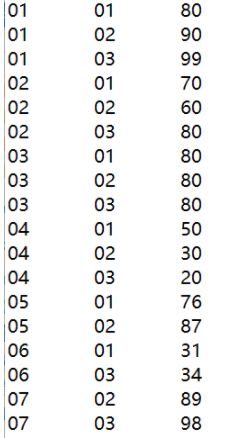
score表
teacher表

course表

在hive中建表导入数据
首先要先在hdfs上为每个数据建一个文件名相同的文件夹,以上为4张表是txt格式的,放在hdfs相对应的文件夹后,使用以下语句建表(数据量不大直接建内部表)
create table if not exists student(
id int,
name string,
birthday string,
sex string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/data/myschool/student';
create table if not exists teacher(
tid int,
tname string
)
row format delimited fields terminated by '\t'
stored as textfile
localtion '/data/myschool/teacher';
creater table if not exists score(
sid int,
cid int,
scores int
)
row format delimited fields terminated by '\t'
stored as textfile
location '/data/myschool/score';
create table if not exists course(
cid int,
cname string,
tid int
)
row format delimited fields terminated by '\t'
stored as textfile
location '/data/myschool/course';
1、查询“01”课程比“02”课程成绩高的学生的信息及课程分数
select stu.*,sco1.scores 01scores,sco2.scores 02score from
student stu join score sco1
on stu.id=sco1.sid and sco1.cid=1
left join score sco2
on stu.id=sco2.sid and sco2.cid=2
where sco1.scores<sco2.scores;
2.查询"01"课程比"02"课程成绩低的学生的信息及课程分数
select stu.*,sco1.score as 01score,sco2.score as 02score
from student stu join
scores sco1
on stu.id =sco1.sid and sco1.cid=1
left join score sco2
on stu.id =sco2.sid and sco2.cid=2
where sco1.scores<sco2.scores;
3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
select stu.id,stu.name,avg(sco.scores)
form student stu join score sco
on stu.id=sco.sid
group by stu.id,stu.name
having avg(sco.scores)>60;
4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩 – (包括有成绩的和无成绩的)
select stu.id,stu.name,round(avg(sco.scores),2) as avg_scores
form student stu join score sco
on stu.id=sco.sid
group by stu.id,stu.name
having avg(sco.scores)<60
union all
select stu1.id,stu1.name,0 as avg_scores
from student stu1
where stu1.id not in
(select distinct sid form score);
5.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
select stu.id,stu.name,count(cid),sum(scores)
from student stu left join score sco
on stu.id=sco.sid
group by stu.id,stu.name;
6.查询"李"姓老师的数量
select count(tid) as num,'姓李的老师' as teal
from teacher
where tname like '李%'
7、查询学过“张三”老师授课的学生的信息
select stu.*
from student stu join score sco on stu.id=sco.sid
join course cor on sco.cid=cor.cid
join teacher tea on tea.tid=cor.tid
where tea.tname='张三';
8.查询没学过"张三"老师授课的同学的信息
select s.* from student s
where s.id not in
(select stu.id
from student stu join score sco on stu.id=sco.sid
join course cor on sco.cid=cor.cid
join teacher tea on tea.tid=cor.tid
where tea.tname='张三');
9.查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
select stu.*
from student stu
join
(select sid as tmpid from score
where cid=1
union all
select sid as tmpid from score
where cid=2) ss on stu.id=ss.tmpid
group by stu.id,stu.name,stu.birthday,stu.sex,ss.tmpid
having count(ss.tmpid)=2;
10.查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
-- join一次过滤学号为“01”的学生,left join出学号“02”为null的就为没有学过编号为“02”的课程
select stu.*
from student stu
join (select sid from score where cid=1) sco1
on stu.id=sco1.sid
left join (select sid from score where cid=2) sco2
on stu.id=sco2.sid
where sco2.sid is null;
11、查询没有学全所有课程的同学的信息
-- 过滤出学过所有课程的id
select student.* from student
left join(
select sid
from score
group by sid
having count(cid)=3)tmp
on student.id=tmp.sid
where tmp.sid is null;
12、查询至少有一门课与学号为“01”的同学所有相同的同学的信息
--思路:找到01学号的学生所学的课程编号;根据该编号找到同样学习这些课程的学生的学生id,join学生表,分组过滤
select stu.* from student stu
join (select cid from score where sid=1) tem1
join (select sid,cid from score) tmp2
on tmp1.cid=tmp2.cid and stu.id=tmp2.sid
where stu.id not in(1)
group by stu.id,name,birthday,sex;
13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
-- 先查询出01号学生学的课程,根据这些课程查出学这些课程的学生的信息,去除01学生本人,在group by having过滤出与01号学生学习课程数相同的学生
select stu.*,count(tmp2.cid) from student stu
join (select cid from score where sid=1) tmp1
join (select sid,cid from score) tmp2
on tmp1.cid=tmp2.cid and stu.id=tmp2.sid
where stu.id not in (1)
group by stu.id,name,birthday,sex
having count(tmp2.cid) in (select count(cid) from score where sid=1);
14、查询没学过"张三"老师讲授的任一门课程的学生姓名
-- 思路:老师表中查到老师为张三的id;老师id在课程中找到老师授课id;由老师授课id可以在成绩表中查询到学过该id可的学生id;在学生表中过滤掉这些学生id的信息就是需要的结果。
select stu.id,stu.name from student stu
left join (select sid,cid from score) sco
left join (select cid,tid from course) cor
left join (select tid from teacher where tname='张三') tea
on stu.id=sco.sid and sco.cid=cor.cid and tea.tid=cor.tid
group by stu.id,name
having count(tea.tid)=0;
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
--思路:条件在成绩表中过滤成绩小于60分的学生,并筛选出课程>=2的学生id,
select stu.*,tmp.savg from student stu
join (select sid,count(cid) noc,round(avg(scores),1) savg
from score where scores<60 group by sid having noc>=2) tmp
on tmp.sid=stu.id;
16、检索“01”课程分数小于60,按分数降低排序的学生的信息
select stu.*,tem.scores from student stu join
(select sid,scores from score where cid=1 and scores<60) tmp
on stu.id=tmp.sid
order by tmp.scores desc;
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
--
select a.sid,tmp1.scores as c1,tmp2.scores as c2,tmp3.scores as c3,
round(avg (a.scores),2) as avgScore
from score a
left join (select sid,scores from score s1 where cid='01')tmp1 on tmp1.sid=a.sid
left join (select sid,scores from score s2 where cid='02')tmp2 on tmp2.sid=a.sid
left join (select sid,scores from score s3 where cid='03')tmp3 on tmp3.sid=a.sid
group by a.sid,tmp1.scores,tmp2.scores,tmp3.scores order by avgScore desc;
18.查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
-- 什么率-》分子(sum(case when .. then 1 else 0 end))/分母(count(cid))
select course.cid,course.cname,tmp.maxScore,tmp.minScore,tmp.avgScore,tmp.passRate,tmp.moderate,tmp.goodRate,tmp.excellentRates from course
join(select
cid,
max(scores) as maxScore,
min(scores) as minScore,
round(avg(scores),2) avgScore,
round(sum(case when scores>=60 then 1 else 0 end)/count(cid),2)passRate,
round(sum(case when scores>=60 and scores<70 then 1 else 0 end)/count(cid),2) moderate,
round(sum(case when scores>=70 and scores<80 then 1 else 0 end)/count(cid),2) goodRate,
round(sum(case when scores>=80 and scores<90 then 1 else 0 end)/count(cid),2) excellentRates
from score group by cid) tmp on tmp.cid=course.cid;
19、按各科成绩进行排序,并显示排名:– row_number() over()分组排序功能(mysql没有该方法)
select cid,sid,scores,row_number() over(partition by cid order by scores desc)
from score;
20、查询学生的总成绩并进行排名
select score.sid,student.name,sum(scores) sum_sco,row_number() over(order by sum(scores) desc) no
from score join student on score.sid=student.id
group by score.sid,student.name;
21、查询不同老师所教不同课程平均分从高到低显示
-- 遇到不同老师不同课程:group by 老师id,课程id
select score.cid,round(avg(scores),2) avg_scores,course.tid
from score join
course on score.cid=course.cid
group by score.cid,course.tid
order by avg_scores desc;
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
-- 看到对什么取前几什么:首先想法哦 row_number() over (partition by 所有的XXX:cid order by scores desc) cno
select tmp.cid,stu.*,tmp.scores,tmp.cno from
student stu join
(select cid,sid,sores,row_number() over(partition by cid order by scores desc) cno
from score) tmp
on stu.id=tmp.sid
where tmp.cno between 2 and 3;
23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
select
score.cid,
course.cname,
round(sum(case when score.scores>=85 and score.scores<=100 then 1 else 0 end)/count(score.scores),2) as 100and85,
round(sum(case when score.scores>=70 and score.scores<85 then 1 else 0 end)/count(score.scores),2) as 85and70,
round(sum(case when score.scores>=60 and score.scores<70 then 1 else 0 end)/count(score.scores),2) as 70and60,
round(sum(case when score.scores>=0 and score.scores<60 then 1 else 0 end)/count(score.scores),2) as 60and0
from score left join course
on score.cid = course.cid
group by score.cid,course.cname;
24、查询学生平均成绩及其名次
select sid,round(avg(scores),2) as avgs,row_number() over(order by avg(scores) desc)
from score
group by sid;
25、查询各科成绩前三名的记录
select tmp.cid,stu.*,tmp.scores,tmp.cno from
student stu join
(select cid,sid,scores,row_number() over(partition by cid order by scores desc) cno
from score) tmp
on stu.id=tmp.sid
where tmp.cno<=3;
26、查询每门课程被选修的学生数
select cid,count(scores) as cnum
from score
group by cid;
27、查询出只有两门课程的全部学生的学号和姓名
select sid,count(cid) as cnum
form score
group by sid
having count(cid)=2
28、查询男生、女生人数
select sex,count(1) as pnum
from student
group by sex;
29、查询名字中含有"风"字的学生信息
select *
from student
where name like '%风%';
30、查询同名同性学生名单,并统计同名人数
select name,sex,count(id)
form student
group by name,sex;
31、查询1990年出生的学生名单
select *
from student
where year(birthday)=1990;
32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
select cid,round(avg(scores),2) as avgs,row_number() over(order by round(avg(scores),2) desc,cid asc)
from score
group by cid;
33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
select stu.id,stu.name,avg(scores) as avgs
from student stu join
score sco on stu.id=sco.sid
group by stu.id,stu.name
having avg(scores)>85;
34、查询课程名称为"数学",且分数低于60的学生姓名和分数
select stu.name,sco.scores
from student stu
join score sco
join course cor
on stu.id=sco.sid and sco.cid=cor.cid
where cor.cname='数学' and sco.scores<60;
35、查询所有学生的课程及分数情况
-- 成绩表与课程表进行join 课程表中的名称为xx 求和对应成绩没对应输出0 按照学生id进行分组;
select stu.id,tmp.chinese,tmp.math,tmp.english
from student stu
left join
(select sco.sid id,
sum(case cor.cname when '语文' then sco.scores else 0 end) as chinese,
sum(case cor.cname when '数学' then sco.scores else 0 end) as math,
sum(case cor.cname when '英语' then sco.scores else 0 end) as english
from score sco
join course cor on sco.cid=cor.cid
group by sco.sid
) tmp on stu.id=tmp.id;
36、查询任何一门课程成绩在70分以上的学生姓名、课程名称和分数
select stu.name,cor.name,sco.scores
from score sco
left join student stu on sco.sid=stu.id
join course cor on sco.cid=cor.cid
where sco.scores>70;
37、查询课程不及格的学生
select sid
from score
where scores<60
group by sid;
38、查询课程编号为01且课程成绩在80分以上的学生的学号和姓名
select sco.sid,stu.name
form score sco
join student stu
on sco.sid = stu.id
where cid=1 and scores>=80;
39、求每门课程的学生人数
select cid,count(sid)
form score
group by cid;
40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
select stu.*,sco.cid,max(sco.scores) max_score
from score sco
left join student stu
on stu.id=sco.sid
join course cor
on sco.cid=cor.cid
join teacher tea
on tea.tid=cor.tid
where tea.tname='张三'
group by sco.cid,stu.id,stu.name,stu.birthday,stu.sex
limit 1;
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
select s1.sid,s1.cid,s1.scores
from score s1,score s2
where s1.cid<>s2.cid and s1.scores=s2.scores;
42、查询每门课程成绩最好的前三名
select tmp.cid,stu.*,tmp.scores,tmp.cno from
student stu join
(select cid,sid,scores,row_number() over(partition by cid order by scores desc) cno
from score) tmp
on stu.id=tmp.sid
where tmp.cno<=3;
43、统计每门课程的学生选修人数(超过5人的课程才统计):
-- 要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
select cid,count(sid) as num
from score
group by cid
having num>=5
order by num desc,cid asc;
44、检索至少选修两门课程的学生学号
select sid
from score
group by sid
having count(cid)>=2;
45、查询选修了全部课程的学生信息
-- 成绩表中根据学生id统计出一共学了多少课程,
select stu.*
from student stu
join
(select sid,count(cid) cnum from score group by sid) tmp
on stu.id=tmp.sid
where tmp.cnum=3;
46、查询各学生的年龄(周岁):
--按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一
with tmp as
(select id,year(current_date())-year(birth)) as tage
form student)
select stu.id,sum(case month(current_date())>month(stu.birthday) true then tmp.tage-1 else tmp.tage end) s_age
from student stu
join tmp
on stu.id=tmp.id
group by stu.id;
47、查询本周过生日的学生:
select *
from student
where weekofyarn(concat(year(current_date)),'-',date_format(birthday,'MM-dd')))=
weekofyear(current_da)
48、查询下周过生日的学生:
select *
from student
where weekofyear(concat(year(current_date()),'-',date_format(birthday,'MM-dd')))=
weekofyear(current_date())+1;
49、查询本月过生日的学生:
select *
form sudent
where month(birthday)=month(current_data())
50、查询12月份过生日的学生:
select * from student where month(birthday)=12
hive经典练习50题链接
https://blog.csdn.net/weixin_41639302/article/details/107434639?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-6.control&dist_request_id=1619762269967_47807&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-6.control
hiveSQL常见面试题
场景一:分组求TopN
先看数据:
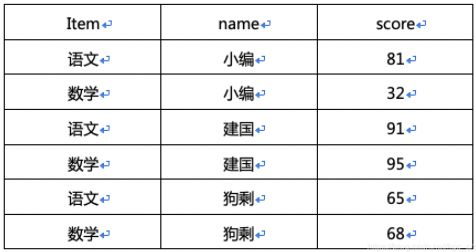
需求要求每一门科目,成绩排名前两名的同学。
使用HiveSQL常见的方式为:
select * from table
row_number() over (partition by item order by score desc) rank
where rank<=2;
输出结果为:
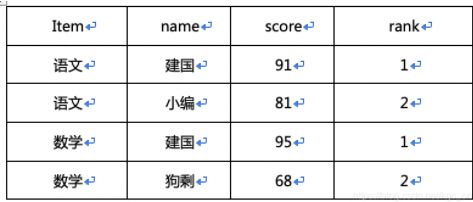
解析:row_number()函数基于over对象分组、排序的记过,为每一行分组记录返回一个序号,该序号从1开始,依次递增,遇到新组则从1开始。也就是说,该函数计算的值表示每组内部排序后的顺序编号。
然后在语句中加入限制条件rank<=2来筛选具体选取top几,从最终的结果可以看出,语文成绩考试前两名的同学分别是建国和小编、数学成绩排名前两名的同学分别是建国和狗剩。
场景二:行转列/列转行
数据如下:
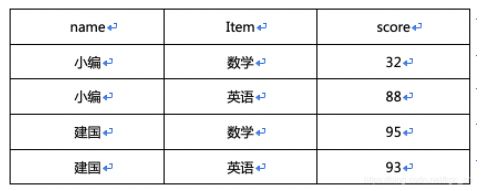
现在需要转换为:
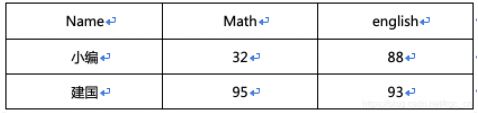
使用hive实现需求的话,可以使用:
select name,
max(case when item='数学' then score else 0 end) as 'match',
sum(case when item='英语' then socre end) as 'english',
from table
group by name
解析:首先写出select name from table group by name ,因为select 后有几个字段,最终输出的就是这几个字段,所以我们需要把目标数据的math”和“english”两个字段想办法得出来。
之后可以对item字段所有枚举的结果进行case when判断,将score填值进入,因为最后我们需要对name做一下聚合,需要明确的是一般选取的的字段一定要出现在groupby里面。
聚合函数可以不同,所以我们在外面套一层sum,这样的到的sum,max的结果和单人得分的结果是一致的,以为我们以name做一遍聚合,而每一个用户对一门课程只有一个成绩,所以这样就可以得到最终的结果。
如果将表4与表3内容转换为的内容应该怎么做
一种比较好的方式:
select table_4.name,
a.item,
a.score
from table_4
lateral view explode(
str_to_map(concat('math=',math,'&english=',english),'&','=')
)a as item,score;
解析:首先使用str_to_map函数将math字段与english字段拼接后的结果转换为map类型,然后通过侧视图和explode函数将其炸开,给生成的临时侧视图一个名字,取名a并给列名取名为item,score,因为explode(map)爆炸的结果是每一个item为行,key为1列,value为1列,这样就恰好形成我们想要的结果。这个实例理解起来稍微有点难度。
一、sql执行顺序
- from
- join
- on
- where
- group by(开始使用select中的别名,后面的语句中都可以使用)
- avg,sum…
- having
- select
- distinct
- order by
- limit
高性能:sql调优,主要是考虑降低:consistent gets和physical reads的数量
count(1)与count(*)比较:
如果你的数据表没有主键,那么count(1)比count(*)快
如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快
如果你的表只有一个字段的话那count(*)就是最快的
count(*) count(1)两者比较。主要还是要count(1)所相对应的数据字段。
count(1)跟count(主键)一样,只扫描主键。
count(*)跟count(非主键):
总结:
1、如果在开发中确实需要用到count()聚合,那么优先考虑count(*)做了特别的优化处理。
有主键或联合主键的情况下,count(*)略比count(1)快一些。
没有主键的情况下count(1)比count(*)快一些。
如果表只有一个字段,则count(*)是最快的。
2、使用count()聚合函数后,最好不要跟where age =1;这样的条件,会导致不走索引,降低查询效率。除非该字段已经建立了索引。使用count()聚合函数后,若有where条件,且where条件的字段末建立索引,直接扫描了全表。
3、count(字段),非主键字段,这样的使用方式最好不要出现。因为它不会索引
9、学过01也学过02课程:from student join( select sid as tmpid from score where cid=1 union all select sid as tmpid from score where cid=2) ss on xx group by xx,ss.tmpid having count(ss.tmpid)=2;->创建临时表临时表中取出上过01课程学生id,unionall 取出上过课程02学生的id,同一id出现两次这为都学过
10、学过01没学过02的=课程的学生的; from student join (学过01编号的学生id) sco1 on 学生表id =sco1id left join(select sid from score where cid=2) sco2 on stu.id=sco2.sid where sco2.sid is null;-> join的时候筛选出学过课程01课程学生id,left join 学过课程2的id 这个时候左面是学过01课程的没学过02的 sid is null;
12、查询至少有一门课与学号为01的同学所学相同的同学的信息
select stu.* from student stu
join (select cid from score where sid=1) tmp1
join (select sid,cid from score) tmp2
on tmp1.cid=tmp2.cid and stu.id=tmp2.sid
where stu.id not in (1)
group by stu.id,name,birthday,sex;
--取出学号为01的学生 ;询出学号为01的学生所学课程的id ;成绩表中查询出学过该课程id的学生id 课程id ;根据学生id 姓名 生日性别分组输出。
13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
select stu.*,count(tmp2.cid) from student stu
join (select cid from score where sid=1) tmp1
join (select sid,cid from score) tmp2
on tmp1.cid=tmp2.cid and stu.id=tmp2.sid
where stu.id not in (1)
group by stu.id,name,birthday,sex
having count(tmp2.cid) in (select count(cid) from score where sid=1);
--首先 有01号学生id ;查出学的科目的id ;由学的科目id 在成绩表中找到学生id 和科目id;关联学生信息表;排除01学生本身,having 过滤出与01学生学的科目数相同的科目数的学生
14、查询没学过"张三"老师讲授的任一门课程的学生姓名
select stu.id,stu.name from student stu
left join (select sid,cid from score) sco
left join (select cid,tid from course) cor
left join (select tid from teacher where tname='张三') tea
on stu.id=sco.sid and sco.cid=cor.cid and tea.tid=cor.tid
group by stu.id,name
having count(tea.tid)=0;
--首先没学过张三老师的课程的学生可能什么课程都没学过 所以用left join
--学过张三老师的课的学生根据学生进行分组后count那一列非张三老师教的课程的老师id为null所以此时就可以将count的时候就只能为0才保证没学过该老师课程