基于深度学习的食品分类系统
1)enhance
from PIL import Image, ImageEnhance
import os
def turn_left_rigth(img):
return img.transpose(Image.FLIP_LEFT_RIGHT)#左右翻折
def brighten_darken(img, val): #亮度调节: 大于1为图片变亮,小于1为图片变暗
return ImageEnhance.Brightness(img).enhance(val)
def saturation_up_down(img, val): #饱和度调节: 大于1为图片饱和度增加,小于1为图片饱和度降低
return ImageEnhance.Color(img).enhance(val)
def Contrast_up_down(img, val): #对比图调节: 大于1为图片对比度增加,小于1为图片对比度减小
return ImageEnhance.Contrast(img).enhance(val)
def Sharpness_up_down(img, val): #锐度调节: 大于1为图片锐度增加,小于1为图片锐度减小
return ImageEnhance.Sharpness(img).enhance(val)
def picture_enhance(dir):
img_list = os.listdir(dir)
for i in range(len(img_list)):
try:
img = Image.open(dir + '\\' + img_list[i])
temp = str(i)
turn_left_rigth(img).convert('RGB').save(dir + '\\turn_left_rigth' + temp + '.jpg')
Contrast_up_down(img, 1.2).convert('RGB').save(dir + '\\Contrast_up' + temp + '_1' + '.jpg')
Contrast_up_down(img, 1.4).convert('RGB').save(dir + '\\Contrast_up' + temp + '_2' + '.jpg')
Contrast_up_down(img, 0.8).convert('RGB').save(dir + '\\Contrast_down' + temp + '_1' + '.jpg')
Contrast_up_down(img, 0.6).convert('RGB').save(dir + '\\Contrast_down' + temp + '_2' + '.jpg')
Sharpness_up_down(img, 1.2).convert('RGB').save(dir + '\\Sharpness_up' + temp + '_1' + '.jpg')
Sharpness_up_down(img, 1.4).convert('RGB').save(dir + '\\Sharpness_up' + temp + '_2' + '.jpg')
Sharpness_up_down(img, 0.8).convert('RGB').save(dir + '\\Sharpness_down' + temp + '_1' + '.jpg')
Sharpness_up_down(img, 0.6).convert('RGB').save(dir + '\\Sharpness_down' + temp + '_2' + '.jpg')
brighten_darken(img, 1.2).convert('RGB').save(dir + '\\brighten' + temp + '_1' + '.jpg')
brighten_darken(img, 1.4).convert('RGB').save(dir + '\\brighten' + temp + '_2' + '.jpg')
brighten_darken(img, 0.8).convert('RGB').save(dir + '\\darken' + temp + '_1' + '.jpg')
brighten_darken(img, 0.6).convert('RGB').save(dir + '\\darken' + temp + '_2' + '.jpg')
saturation_up_down(img, 1.2).convert('RGB').save(dir + '\\saturation_up' + temp + '_1' + '.jpg')
saturation_up_down(img, 1.4).convert('RGB').save(dir + '\\saturation_up' + temp + '_2' + '.jpg')
saturation_up_down(img, 0.8).convert('RGB').save(dir + '\\saturation_down' + temp + '_1' + '.jpg')
saturation_up_down(img, 0.6).convert('RGB').save(dir + '\\saturation_down' + temp + '_2' + '.jpg')
except :
pass
picture_enhance('C:\\pythonwork\\Food\\Food_Orig_Pic\\0')
picture_enhance('C:\\pythonwork\\Food\\Food_Orig_Pic\\1')
picture_enhance('C:\\pythonwork\\Food\\Food_Orig_Pic\\2')
picture_enhance('C:\\pythonwork\\Food\\Food_Orig_Pic\\3')
picture_enhance('C:\\pythonwork\\Food\\Food_Orig_Pic\\4')
picture_enhance('C:\\pythonwork\\Food\\Food_Orig_Pic\\5')
2)make_list
import os
def generate_list(dir, label):
files = os.listdir(dir) #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
listText = open(dir + '\\' + 'list.txt', 'w') #\\的转移字符对应\, 创建list.txt文件
for file in files:
name_label = dir + '\\' + file + ' ' + str(int(label)) + '\n'
listText.write(name_label)
listText.close()
#两个参数,arg1:dir(sunflowers, roses) arg2:label
generate_list('C:\\pythonwork\\Food\\Food_Orig_Pic\\0', 0)
generate_list('C:\\pythonwork\\Food\\Food_Orig_Pic\\1', 1)
generate_list('C:\\pythonwork\\Food\\Food_Orig_Pic\\2', 2)
generate_list('C:\\pythonwork\\Food\\Food_Orig_Pic\\3', 3)
generate_list('C:\\pythonwork\\Food\\Food_Orig_Pic\\4', 4)
generate_list('C:\\pythonwork\\Food\\Food_Orig_Pic\\5', 5)
#分别将两个文件夹下的list.txt在上级目录下合并成一个list.txt
file0 = open('C:\\pythonwork\\Food\\Food_Orig_Pic\\0\\list.txt', 'r')
donuts_list = []
for i in file0.readlines():
donuts_list.append(i)
file0.close()
file1 = open('C:\\pythonwork\\Food\\Food_Orig_Pic\\1\\list.txt', 'r')
egg_tarts_list = []
for i in file1.readlines():
egg_tarts_list.append(i)
file1.close()
file2= open('C:\\pythonwork\\Food\\Food_Orig_Pic\\2\\list.txt', 'r')
hanmburgers_list = []
for i in file2.readlines():
hanmburgers_list.append(i)
file2.close()
file3 = open('C:\\pythonwork\\Food\\Food_Orig_Pic\\3\\list.txt', 'r')
pizzas_list = []
for i in file3.readlines():
pizzas_list.append(i)
file3.close()
file4 = open('C:\\pythonwork\\Food\\Food_Orig_Pic\\4\\list.txt', 'r')
steak_list = []
for i in file4.readlines():
steak_list.append(i)
file4.close()
file5 = open('C:\\pythonwork\\Food\\Food_Orig_Pic\\5\\list.txt', 'r')
ice_creams_list = []
for i in file5.readlines():
ice_creams_list.append(i)
file5.close()
file = open('C:\\pythonwork\\Food\\Food_Orig_Pic\\list.txt', 'w') #创建上层目录list.txt,用于合并roses和sunflowers文件夹下的list.txt
for i in donuts_list:
file.write(i)
for i in egg_tarts_list:
file.write(i)
for i in hanmburgers_list:
file.write(i)
for i in pizzas_list:
file.write(i)
for i in steak_list:
file.write(i)
for i in ice_creams_list:
file.write(i)
file.close()
os.remove('C:\\pythonwork\\Food\\Food_Orig_Pic\\0\\list.txt')
os.remove('C:\\pythonwork\\Food\\Food_Orig_Pic\\1\\list.txt')
os.remove('C:\\pythonwork\\Food\\Food_Orig_Pic\\2\\list.txt')
os.remove('C:\\pythonwork\\Food\\Food_Orig_Pic\\3\\list.txt')
os.remove('C:\\pythonwork\\Food\\Food_Orig_Pic\\4\\list.txt')
os.remove('C:\\pythonwork\\Food\\Food_Orig_Pic\\5\\list.txt')


3)make dataset
import os
import numpy as np
from PIL import Image
def readData(txt_path):
print('Loading images........')
list_file = open(txt_path, 'r')
content = list_file.readlines()
image = []
label = []
for i in range(len(content)):
print(i)
try:
line = content[i]
im = Image.open(line.split()[0]) #split()默认以空格进行分割,line.split()[0]:表示空格之前的内容,line.split()[1]:表示空格后面的内容
im = im.convert('RGB').resize((64,64), Image.ANTIALIAS) #缩小图片过程中,使用ANTIALIAS过滤器,尽量使图片压缩过程中保证图片的质量
im = np.array(im)
image.append(im)
line.split()[1] = np.array(int(line.split()[1]))
label.append(line.split()[1])
except:
pass
image_np_array = np.array(image)
label_np_array = np.array(label)
return (image_np_array, label_np_array)
(data_image, data_label) = readData('C:\\pythonwork\\Food\\Food_Orig_Pic\\list.txt')
#制作最终的数据集
np.savez('Food_DataSet_64.npz', train_image = data_image, train_label = data_label)

4)model train
import numpy as np
import matplotlib.pyplot as plt
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.models import Sequential
from keras.utils import np_utils
#加载数据集
dataset = np.load('Food_DataSet_64.npz')
image = dataset['train_image']
label = dataset['train_label']
print('dataset_number: ', len(image))
#rose:9000(train:8000(train:6400 valid:1600), test:1000) sunflower:9000(train:8000(train:6400 valid:1600), test:1000)
train_image_0 = []
train_label_0 = []
train_image_1 = []
train_label_1 = []
train_image_2 = []
train_label_2 = []
train_image_3 = []
train_label_3 = []
train_image_4 = []
train_label_4 = []
train_image_5 = []
train_label_5 = []
test_image = []
test_label = []
for i in range(len(image)):
if (label[i] == '0') & (len(train_label_0) < 7500): #分类为0取7500项用于训练数据
train_image_0.append(image[i])
train_label_0.append(label[i])
continue
if (label[i] == '1') & (len(train_label_1) < 7500): #分类为1取7500项用于训练数据
train_image_1.append(image[i])
train_label_1.append(label[i])
continue
if (label[i] == '2') & (len(train_label_2) < 7500): #分类为2取7500项用于训练数据
train_image_2.append(image[i])
train_label_2.append(label[i])
continue
if (label[i] == '3') & (len(train_label_3) < 7500): #分类为3取7500项用于训练数据
train_image_3.append(image[i])
train_label_3.append(label[i])
continue
if (label[i] == '4') & (len(train_label_4) < 7500): #分类为4取7500项用于训练数据
train_image_4.append(image[i])
train_label_4.append(label[i])
continue
if (label[i] == '5') & (len(train_label_5) < 7500): #分类为5取7500项用于训练数据
train_image_5.append(image[i])
train_label_5.append(label[i])
continue
test_image.append(image[i]) #剩余的部分作为测试数据(1000+1000 = 2000)
test_label.append(label[i])
train_image_0 = np.array(train_image_0)
train_label_0 = np.array(train_label_0)
train_image_1 = np.array(train_image_1)
train_label_1 = np.array(train_label_1)
train_image_2 = np.array(train_image_2)
train_label_2 = np.array(train_label_2)
train_image_3 = np.array(train_image_3)
train_label_3 = np.array(train_label_3)
train_image_4 = np.array(train_image_4)
train_label_4 = np.array(train_label_4)
train_image_5 = np.array(train_image_5)
train_label_5 = np.array(train_label_5)
test_image = np.array(test_image)
test_label = np.array(test_label)
print(train_image_0.shape, train_label_0.shape)
#取出80%的数据用作训练数据,20%的数据用作验证数据
train_image = np.vstack((train_image_0[:6000], train_image_1[:6000],train_image_2[:6000], train_image_3[:6000],train_image_4[:6000], train_image_5[:6000]))
valid_image = np.vstack((train_image_0[6000:], train_image_1[6000:],train_image_2[6000:], train_image_3[6000:],train_image_4[6000:], train_image_5[6000:]))
print(train_image.shape)
print(valid_image.shape)
train_label = np.concatenate((train_label_0[:6000], train_label_1[:6000],train_label_2[:6000], train_label_3[:6000],train_label_4[:6000], train_label_5[:6000]))
valid_label = np.concatenate((train_label_0[6000:], train_label_1[6000:],train_label_2[6000:], train_label_3[6000:],train_label_4[6000:], train_label_5[6000:]))
print(train_label.shape)
print(valid_label.shape)
def show_image(img):
plt.imshow(img)
plt.show()
show_image(train_image[0])
#数据预处理:特征部分进行标准化,标签部分进行一位有效编码转换
train_image_normalize = train_image.astype(float) / 255
train_label_onehotencoding = np_utils.to_categorical(train_label)
valid_image_normalize = valid_image.astype(float) / 255
valid_label_onehotencoding = np_utils.to_categorical(valid_label)
test_image_normalize = test_image.astype(float) / 255
test_label_onehotencoding = np_utils.to_categorical(test_label)
model = Sequential()
model.add(Conv2D(filters=32,kernel_size=(3,3), padding='same', input_shape=(64,64,3), activation='relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Conv2D(filters=16,kernel_size=(3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(units=100, kernel_initializer='normal', activation='relu'))
model.add(Dropout(0.25))
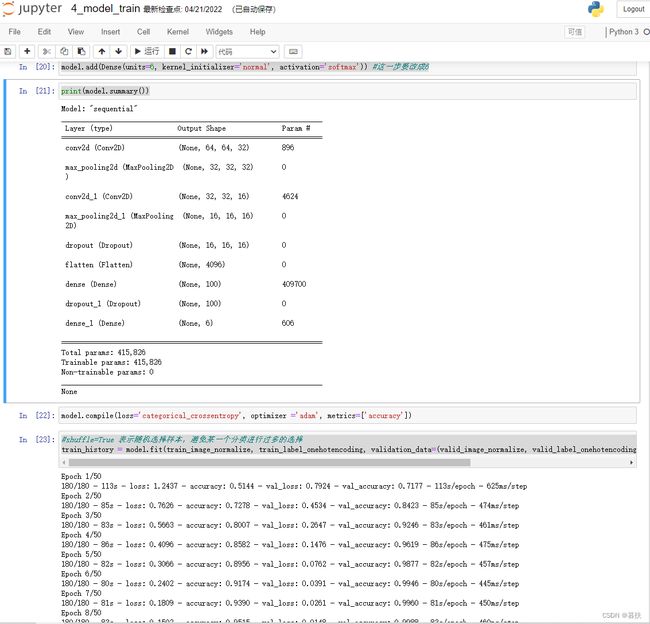
model.add(Dense(units=6, kernel_initializer='normal', activation='softmax')) #这一步要改成6
print(model.summary())
model.compile(loss='categorical_crossentropy', optimizer ='adam', metrics=['accuracy'])
#shuffle=True 表示随机选择样本,避免某一个分类进行过多的选择
train_history = model.fit(train_image_normalize, train_label_onehotencoding, validation_data=(valid_image_normalize, valid_label_onehotencoding), shuffle=True, epochs=50, batch_size=200, verbose=2)
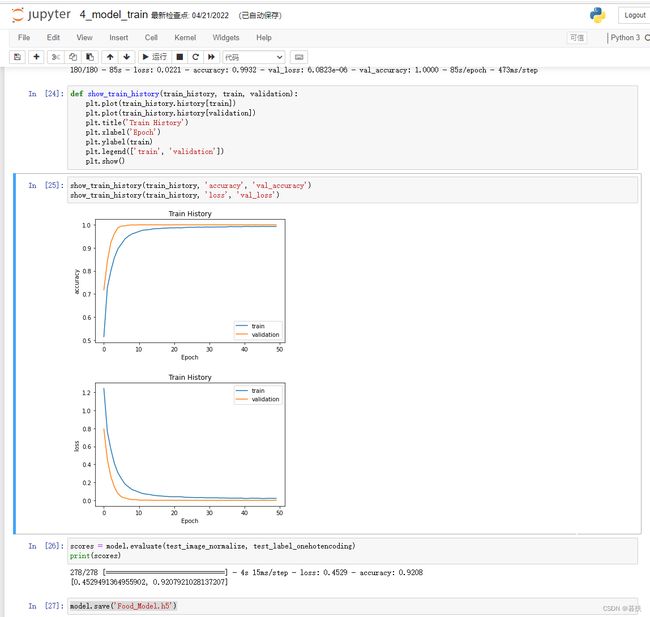
def show_train_history(train_history, train, validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.xlabel('Epoch')
plt.ylabel(train)
plt.legend(['train', 'validation'])
plt.show()
show_train_history(train_history, 'accuracy', 'val_accuracy')
show_train_history(train_history, 'loss', 'val_loss')
scores = model.evaluate(test_image_normalize, test_label_onehotencoding)
print(scores)
model.save('Food_Model.h5')


5)predict
from keras.models import load_model
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
my_model = load_model('Food_Model.h5')
def show_image(img):
plt.imshow(img)
plt.show()
img = Image.open('p6.jpg')
img = img.resize((64,64), Image.ANTIALIAS)
show_image(img)
number_data = img.getdata()
number_data_array = np.array(number_data)
number_data_array = number_data_array.reshape(1,64,64,3).astype(float)
number_data_array_normalize = number_data_array / 255
prediction = my_model.predict(number_data_array_normalize)
print(prediction)
index = np.argmax(prediction)
if index == 0:
print('甜甜圈')
elif index == 1:
print('蛋挞')
elif index == 2:
print('汉堡')
elif index == 3:
print('披萨')
elif index == 4:
print('牛排')
elif index == 5:
print('冰淇淋')
