刘二大人pytorch实践第十一讲主要内容及课后作业
1.Inception Moudle
Inception网络在同一层级上运行具备多个尺寸的滤波器对数据进行处理,最后再按通道将输出结果拼接起来,兼顾了网络的深度和宽度,降低了网络过拟合的几率。网络基本结构如下:

注:inception网络中1*1的卷积有什么用?----减少运算量。
如下图所示,如果直接对数据进行5*5卷积,卷积一个通道就需要25个卷积参数,输入数据有192个通道,输入卷积完之后相加合成为一个输出通道,输出有32个通道,所以这个运算再继续32次,所以运算量是25*192*32*28^2;
添加了1*1卷积后,第一次卷积的卷积核参数减少25倍

将inception模块应用到手写数字识别
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
batch_size=64
transform=transforms.Compose([
transforms.ToTensor(),#将PIL影像转化为张量,像素值变为0-1,拥有通道数1
transforms.Normalize((0.1307,),(0.3081,))#归一化,均值和标准差
])
#如果没有下载mnist数据集,download设为True
train_dataset=datasets.MNIST(root='DATASET/mnist/',train=True,download=False,transform=transform)
train_loader=DataLoader(dataset=train_dataset,shuffle=True,batch_size=batch_size)
test_dataset=datasets.MNIST(root='DATASET/mnist/',train=False,download=False,transform=transform)
test_loader=DataLoader(dataset=test_dataset,shuffle=False,batch_size=batch_size)
class InceptionNet(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.branch_pool=nn.Conv2d(in_channels,24,kernel_size=1)
self.branch1x1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch55_1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch55_2=nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch33_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch33_2 = nn.Conv2d(16, 24, kernel_size=3,padding=1)
self.branch33_3=nn.Conv2d(24,24,kernel_size=3,padding=1)
def forward(self,x):
branch_pool=F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool=self.branch_pool(branch_pool)
branch1x1=self.branch1x1(x)
branch5x5=self.branch55_1(x)
branch5x5=self.branch55_2(branch5x5)
branch3x3=self.branch33_1(x)
branch3x3=self.branch33_2(branch3x3)
branch3x3=self.branch33_3(branch3x3)
outputs=[branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)#(B,C,W,H)按通道拼接,所以维度是1
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
#这种一层一层敲有点笨笨的,也可以用torch.nn.sequential()方法一次解决
self.cov1=torch.nn.Conv2d(1,10,kernel_size=5)
self.cov2=torch.nn.Conv2d(88,20,kernel_size=5)
self.incep1=InceptionNet(in_channels=10)
self.incep2 = InceptionNet(in_channels=20)
self.mp=torch.nn.MaxPool2d(2)
self.fc=torch.nn.Linear(1408,10)
def forward(self,x):
batch_size = x.size(0)
x = self.mp(F.relu(self.cov1(x)))
x = self.incep1(x)
x = self.mp(F.relu(self.cov2(x)))
x = self.incep2(x)
x=x.view(batch_size,-1)# -1 此处自动算出的是1408
x=self.fc(x)
return x# 最后一层不做激活,要做交叉熵损失
model=Net()
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)#momentum是冲量
def train(epoch):
running_loss=0.0
for i,(inputs,target) in enumerate(train_loader,0):
optimizer.zero_grad()
#forward+backward+updata
outputs=model(inputs)
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if i%300==299:
print('[%d,%5d] loss:%.3f'%(epoch+1,i+1,running_loss/300))
running_loss=0.0
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
images,labels=data
outputs=model(images)
_,predicted=torch.max(outputs.data,dim=1)#列的dim=0,行dim=1,表示输出一行中最大值
total+=labels.size(0)
correct+=(predicted==labels).sum().item()#张量之间的比较运算
print('Accuracy on test set:%d %%'%(100*correct/total))
return correct/total
if __name__=='__main__':
epoch_list=[]
accuracy_list=[]
for epoch in range(10):
train(epoch)
accu=test()
epoch_list.append(epoch)
accuracy_list.append((accu))
plt.plot(epoch_list,accuracy_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
结果:

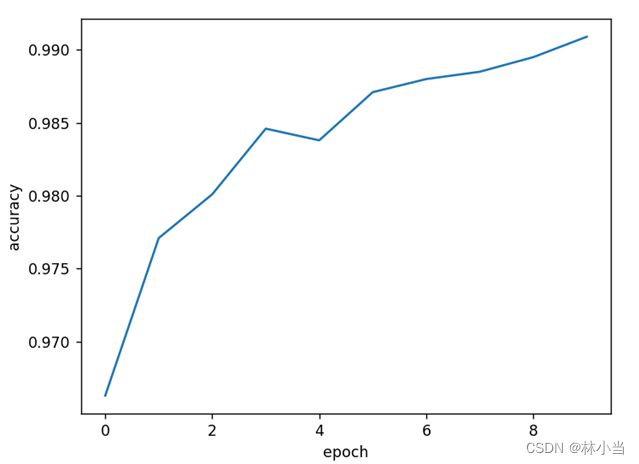
注:epoch_list.append(epoch)处,应该是(epoch+1),搞忘改了,但不影响结果,诸位放心食用。
2. Residual Block
左边是寻常网络结构,右边是残差网络结构。残差结构可以有效防止梯度消失,因为就算F(x)的导数很小,趋近于0,但x的导数为1,所以梯度不会为0。

Residual Block:
class ResidualBlock(nn.Module):
def __init__(self,channels):
super(ResidualBlok, self).__init__()
self.channels=channels
self.cov1=nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.cov2=nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y=F.relu(self.cov1(x))
y=self.cov2(x)
return F.relu(x+y)
按照下列结构 应用于手写数字识别:

class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.cov1=torch.nn.Conv2d(1,16,kernel_size=5)
self.cov2=torch.nn.Conv2d(16,32,kernel_size=5)
self.residual1=ResidualBlok(channels=16)
self.residual2 = ResidualBlok(channels=32)
self.mp=torch.nn.MaxPool2d(2)
self.fc=torch.nn.Linear(512,10)
def forward(self,x):
batch_size = x.size(0)
x = self.mp(F.relu(self.cov1(x)))
x = self.residual1(x)
x = self.mp(F.relu(self.cov2(x)))
x = self.residual2(x)
x=x.view(batch_size,-1)# -1 此处自动算出的是512
x=self.fc(x)
return x# 最后一层不做激活,要做交叉熵损失
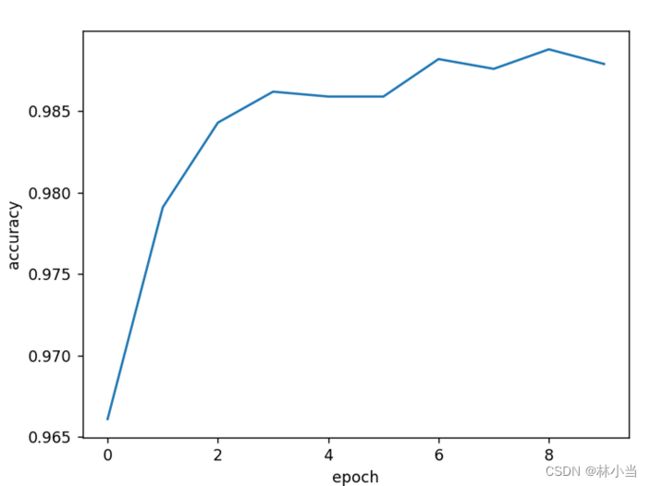
结果:


注:其他代码与Inception模块代码一致,不再贴出。
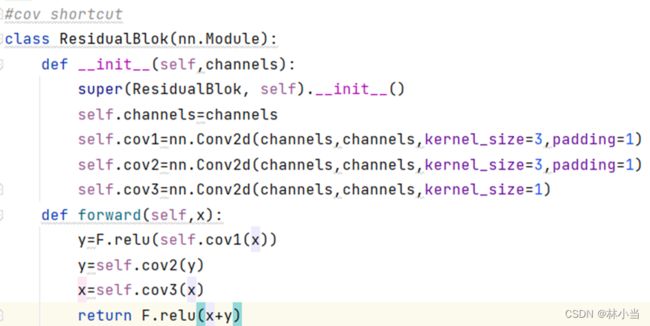
作业1:实现如下Residual Block

(1)左图结构代码如下:

预测效果不如原始的Residual网络好:

(2)右图结构代码:
预测效果不如原始的Residual网络好:

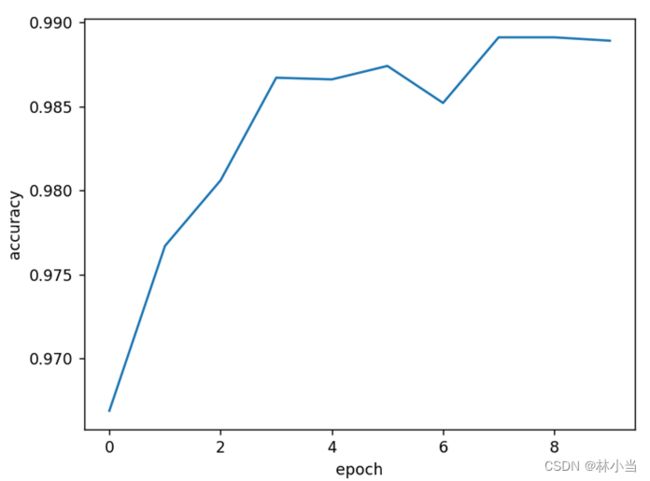
自由娱乐环节:
因为上面那两种残差结构的结果不理想,于是我阅读了这篇文章:《identity mappings in deep residual networks》,发现作者提出的一种改进的residual block:先计算激活层,再计算权重层,能有效优化预测结果,结构如下图(e):

代码如下:

结果确实有优化:


作业2:实现如下DenseNet
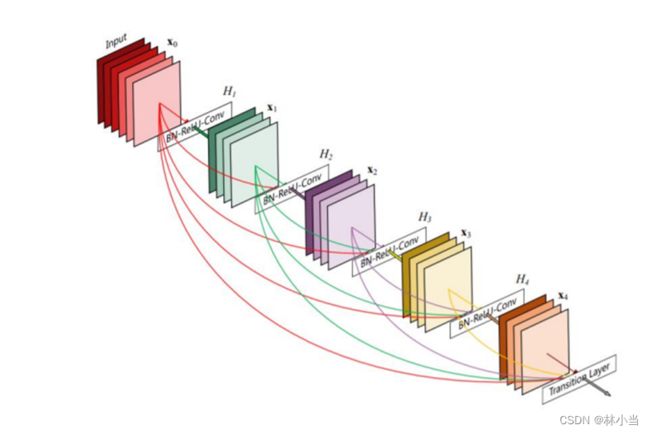
DenseNet采用的是从任何层到所有后续层的直接连接方式。即第![]() 层接收所有前面层输出的特征图
层接收所有前面层输出的特征图![]() 作为输入,数学表达式为
作为输入,数学表达式为![]() ,其中
,其中![]() 表示将第
表示将第![]() 层前所有层输出的特征图进行拼接。
层前所有层输出的特征图进行拼接。
![]() 是三个连续操作的复合函数:BN标准化,ReLU激活函数和一个3x3卷积。
是三个连续操作的复合函数:BN标准化,ReLU激活函数和一个3x3卷积。
池化层
由于下采样层是卷积网络的一个重要组成部分,而在执行下采样后输出特征图的大小发生变化无法与前面层中输出的特征图进行拼接,因此文章中将DenseNets分为多个密集连接模块,模块内使用密集连接结构。而模块间的层被称为过渡层,过渡层一般由BN标准化、1×1卷积和2×2的平均池化构成。

Growth rate(增长率)
假设每个Hl(∙)会产生k个特征图,则为DenseNet的增长率。
假设k0为输入图像的通道数,则第l层的输入有k0+k×(l-1)个特征图。
由于每一层都可以访问同一模块中所有前面层输出的特征图,DenseNet可以在增长率比较小(即网络宽度比较小)的情况下达到很好的精度并且所需要的参数量较少。
瓶颈层
虽然DenseNet每层都只输出k个特征图,但是每层的输入量还是相当大的。因此文章中想到使用瓶颈层的方式来减少输入特征的数量以提高计算效率。具体操作是:对于一个密集连接模块,在每个BN-ReLU-Conv(3×3)构成的小模块前面添加一个BN-ReLU-Conv(1×1)小模块,这些小模块中1×1卷积会产生4k (k为增长率)个特征图以减少实际输入3×3卷积中的特征图数量。文章中把这个添加了瓶颈层的网络称为DenseNet-B。
压缩
为了提高模型的紧凑性,文章中进一步减少过渡层产生的特征图数量,假设θ为压缩因子,输入过渡层的特征图数目为m,则输出过渡层的特征图数目为θm。文章中将θ< 1的DenseNet称为DenseNet-C,将θ< 1并添加了瓶颈层的DenseNet称为DenseNet-BC。
应用于手写数字识别代码如下:
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
batch_size=64
transform=transforms.Compose([
transforms.ToTensor(),#将PIL影像转化为张量,像素值变为0-1,拥有通道数1
transforms.Normalize((0.1307,),(0.3081,))#归一化,均值和标准差
])
train_dataset=datasets.MNIST(root='DATASET/mnist/',train=True,download=False,transform=transform)
train_loader=DataLoader(dataset=train_dataset,shuffle=True,batch_size=batch_size)
test_dataset=datasets.MNIST(root='DATASET/mnist/',train=False,download=False,transform=transform)
test_loader=DataLoader(dataset=test_dataset,shuffle=False,batch_size=batch_size)
def conv_block(in_channel, out_channel):
layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(),
nn.Conv2d(in_channel,4*out_channel,kernel_size=1,bias=False),
nn.BatchNorm2d(4*out_channel),
nn.ReLU(),
nn.Conv2d(4*out_channel, out_channel, kernel_size=3, padding=1, bias=False)
)
return layer
class dense_block(nn.Module):
def __init__(self, in_channel, growth_rate, num_layers):#dense_block里有num_layer个提取特征的层
super(dense_block, self).__init__()
block = []
channel = in_channel
for i in range(num_layers):
block.append(conv_block(channel, growth_rate))
channel += growth_rate
self.net = nn.Sequential(*block)
def forward(self, x):
for layer in self.net:
out = layer(x)
x = torch.cat((out, x), dim=1)
return x
#过渡层
def transition(in_channel, out_channel):
trans_layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(),
nn.Conv2d(in_channel, out_channel, 1),
nn.AvgPool2d(2, 2)
)
return trans_layer
class densenet(nn.Module):
def __init__(self, in_channel=1, num_classes=10, growth_rate=4,block_layers=[4] ):#block_layers=[6, 12, 24, 16]
super(densenet, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channel, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(True),
# nn.MaxPool2d(3, 2, padding=1)因为数据本身w和h较小,不用这么多池化
)
self.DB1 = self._make_dense_block(64, growth_rate,num=block_layers[0])
self.TL1 = self._make_transition_layer(80)#256
self.DB2 = self._make_dense_block(40, growth_rate, num=block_layers[0])#128
self.TL2 = self._make_transition_layer(56)#512
self.DB3 = self._make_dense_block(28, growth_rate, num=block_layers[0])#256
self.TL3 = self._make_transition_layer(44)#1024
self.DB4 = self._make_dense_block(22, growth_rate, num=block_layers[0])#512
# self.global_average = nn.Sequential(
# nn.BatchNorm2d(1024),
# nn.ReLU(),
# nn.AdaptiveAvgPool2d((1,1)),
# )
self.classifier = nn.Linear(38, num_classes)
def forward(self, x):
x = self.block1(x)
x = self.DB1(x)
x = self.TL1(x)
x = self.DB2(x)
x = self.TL2(x)
x = self.DB3(x)
x = self.TL3(x)
x = self.DB4(x)
# x = self.global_average(x)
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x
def _make_dense_block(self,channels, growth_rate, num):
block = []
block.append(dense_block(channels, growth_rate, num))
channels += num * growth_rate #合并前五层通道数
return nn.Sequential(*block)
def _make_transition_layer(self,channels):
block = []
block.append(transition(channels, channels // 2))#通道数减半
return nn.Sequential(*block)
model=densenet()
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)#momentum是冲量
def train(epoch):
running_loss=0.0
for i,(inputs,target) in enumerate(train_loader,0):
optimizer.zero_grad()
#forward+backward+updata
outputs=model(inputs)
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if i%300==299:
print('[%d,%5d] loss:%.3f'%(epoch+1,i+1,running_loss/300))
running_loss=0.0
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
images,labels=data
outputs=model(images)
_,predicted=torch.max(outputs.data,dim=1)#列的dim=0,行dim=1,表示输出一行中最大值
total+=labels.size(0)
correct+=(predicted==labels).sum().item()#张量之间的比较运算
print('Accuracy on test set:%d %% [%d,%d]'%(100*correct/total,correct,total))
return correct/total
if __name__=='__main__':
epoch_list=[]
accuracy_list=[]
for epoch in range(10):
train(epoch)
accu=test()
epoch_list.append(epoch)
accuracy_list.append((accu))
plt.plot(epoch_list,accuracy_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
结果:


原文中设置的增长率是32,数据集为cifer-10,有4个DenseBlock模块,分别含有6,12,24,16个conv_block,但考虑到本身电脑配置,将增长率设置为4,4个DenseBlock模块都设置为4个conv_block。结果比residualNet差一些,可能是通道数较少的原因。