MXNet的Faster R-CNN(基于区域提议网络的实时目标检测)《4》
这篇主要了解语义分割(semantic segmentation),语义分割是分类中的一个核心知识点,而且这些语义区域的标注和预测都是像素级的。在语义分割中有两个很相似的重要问题,需要注意下:
图像分割(image segmentation):将图像分割成若干组成区域,这类问题的方法通常利用图像中像素之间的相关性,这个可以去了解下泛洪填充,这个在训练的时候不需要有关图像像素的标签信息,当然在预测的时候也就没法保证分割出来的区域是我们想要的,比如可能出现将一只狗分割成两部分,毛色一样的一部分,黑色脑袋是另一部分。
实例分割(instance segmentation):又叫同时检测并分割(simultaneous detection and segmentation),它研究如何识别图像中各个目标实例的像素级区域。跟语义分割不同的是,实例分割不仅需要区分语义,还要区分不同的目标实例。比如图像中有两只狗,实例分割需要区分像素属于这两只狗中的哪一只。
Pascal VOC2012语义分割数据集
在语义分割中,VOC数据集是一个使用很广泛的重要数据集,由于比较大,建议迅雷下载:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
对于这个数据集,我们在MXNet的Faster R-CNN(基于区域提议网络的实时目标检测)《1》
已有讲过,第一次接触的可以先看上面这篇文章,这里我们先来看下输入图像与对应的标签,这里的read_voc_images函数在d2lzh包中已有,这个函数就是读取data\VOCdevkit\VOC2012\ImageSets\Segmentation里面的train.txt或val.txt,读取的是图片名称,然后遍历data\VOCdevkit\VOC2012\JPEGImages里面的图片features,以及data\VOCdevkit\VOC2012\SegmentationClass里面对应的图片labels
read_voc_images函数在这里就不重复贴了,有兴趣的可以去看下,我们示例如下:
import d2lzh as d2l
n = 5
train_features, train_labels = d2l.read_voc_images()
imgs = train_features[0:n]+train_labels[0:n]
d2l.show_images(imgs, 2, n)
d2l.plt.show()train_features和train_labels是列表,里面是NDArray类型的图片数值,所以train_features[0:n]+train_labels[0:n]这个相加的结果就是将图片和标签相连放在列表中
其中show_images显示图片的函数如下
def show_images(imgs, num_rows, num_cols, scale=2):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
for i in range(num_rows):
for j in range(num_cols):
axes[i][j].imshow(imgs[i * num_cols + j].asnumpy())
axes[i][j].axes.get_xaxis().set_visible(False)
axes[i][j].axes.get_yaxis().set_visible(False)
return axesaxes[i][j].imshow(imgs[i * num_cols + j].asnumpy())这里是显示几行几列在imgs中的位置,比如这里的n=5,也就是2行5列,我们拿第2行第3列举例,显示的就是imgs[1 * 5 + 2]即imgs[7],也就是说第2行的第3列就是图片索引为7的数据。
我们画出前5张输入图像与对应的标签,在第二行的标签中,我们可以看到,白色表示边框,黑色表示背景,其余的不同颜色表示不同的类别。

像素级的类别索引
既然是像素级别的类别,我们先来看下有多少类别,以及对于这些类别标签,我们是怎么表示的?
列出标签中每个RGB颜色的值及其标注的类别:
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]这两个类别与颜色的常量在d2lzh/utils.py中有,数量是21个,可以直接d2l.VOC_CLASSES和d2l.VOC_COLORMAP调用。
有了这两个常量,我们可以很方便的查找标签中每个像素的类别索引。
接下来我们看下,如何通过像素的颜色值来知道类别索引。
train_features, train_labels = d2l.read_voc_images()
colormap2label = nd.zeros(256**3) # 0~255个像素值,RGB三种颜色
VOC_COLORMAP=d2l.VOC_COLORMAP
#RGB颜色值对应类别索引值
for i, colormap in enumerate(VOC_COLORMAP):
#print(colormap)
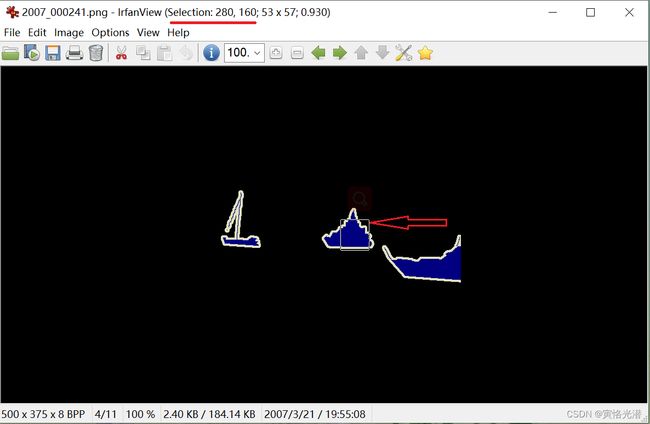
colormap2label[(colormap[0]*256 + colormap[1])*256 + colormap[2]] = i我们选取一张有船的图片,看下这个船的标签对应的RGB颜色值是什么样的
大概选取中间船的位置,另外船,我们知道VOC_CLASSES类别索引是4,意味着,在背景和船这块区域应该要出现的值是0和4。这张船boat的图片是在train.txt的第7个,所以是train_labels[6],我们来看下:
#标签颜色值d2lzh包已有
def voc_label_indices(colormap,colormap2label):
colormap=colormap.astype('int32')
idx=((colormap[:,:,0]*256 + colormap[:,:,1]) * 256 + colormap[:,:,2])
return colormap2label[idx]
#2007_000241
y=voc_label_indices(train_labels[6],colormap2label)
print(y[160:180,280:300])
print(d2l.VOC_CLASSES[4])
'''
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[0. 0. 0. 0. 0. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]
[4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]]
boat
''' 显示的结果确实证实了我们的这张图片对应船这个区域块的地方,背景0,然后右边过来点和向下来点的位置就是船4。另外对于显示这个位置,我是通过irfanView选取的,一款很小巧的优质看图软件,看箭头位置和红色下划线的地方,就可以指出坐标位置。
预处理数据
在以前的输入特征当中,我们采取的是缩放图像使其符合模型的输入形状,在语义分割当中,需要将预测的像素类别重新映射回原始尺寸的输入图像。这样的映射难以做到精确,尤其在不同语义的分割区域。为了避免这个问题,我们将图像裁剪成固定尺寸而不是缩放,具体的就是使用自带的d2l包中voc_rand_crop随机裁剪函数,将输入图像和标签裁剪成相同的区域:
imgs = []
n = 5
for _ in range(n):
imgs += d2l.voc_rand_crop(train_features[0], train_labels[0], 200, 300)
# [::2]表示步长为2,即每隔一个取数;[1::2]表示从第二个开始,每隔一个的取数
# d2l.show_images(imgs,2,n)#跟这个的区别试着对比下
d2l.show_images(imgs[::2]+imgs[1::2], 2, n)
d2l.plt.show()自定义语义分割数据集
我们通过d2l包中的VOCSegDataset来自定义一个语义分割数据集,其中normalize_image函数将输入图像中的RGB三通道的值分别做了标准化处理,filter函数将过滤掉小于指定随机裁剪的输出尺寸的图像,最后通过__getitem__函数,我们可以任意访问数据集中索引为idx的输入图像及其每个像素的类别索引。
crop_size=(500,480)
voc_dir="../data/VOCdevkit/VOC2012"
voc_train=d2l.VOCSegDataset(True,crop_size,voc_dir,colormap2label)
voc_test=d2l.VOCSegDataset(False,crop_size,voc_dir,colormap2label)
'''
read 14 examples
read 16 examples
'''可以看到符合这个高宽500,480的尺寸的训练和测试样本只有14与16张,可以验证是做了过滤的。
我们来打印第一张看看,这里的高宽设置为300,480,第一张图片是电脑:
import matplotlib.pyplot as plt
imgarr=voc_train.__getitem__(0)[0].transpose((1,2,0)).asnumpy()
print(imgarr)
plt.imshow(imgarr)
plt.colorbar()
plt.show()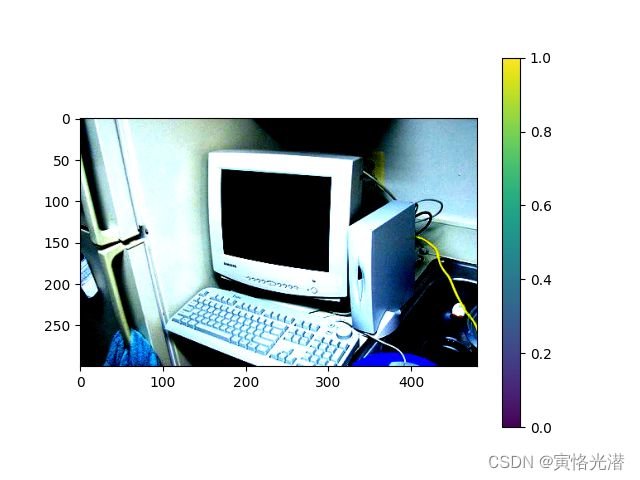
由于这里是做了标准化处理,一些负数的像素值就被舍弃了,因为这个需要是[0..1]或[0..255]之间,属于uint8类型。我们可以读取一张图片来看下:
import matplotlib.image as image
img=image.imread('hi.jpg')
img.min()
img.max()可以知道范围是0~255
当然为了避免下面的错误,可以使用astype(np.uint8)。不然报错如下:
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
我们分别来定义训练集和测试集的迭代器,批处理设置为64,打印第一个小批量的形状看下:
batch_size=64
train_iter=gdata.DataLoader(voc_train,batch_size,shuffle=True,last_batch='discard')
test_iter=gdata.DataLoader(voc_test,batch_size,shuffle=True,last_batch='discard')
for X,y in train_iter:
print(X.shape)
print(y.shape)
break
'''
(64, 3, 300, 480)
(64, 300, 480)
'''这里需要注意的是,标签不同于图像分类和目标识别,这里是一个三维数组。同样验证下这个标签的像素值的类型索引是不是电脑“tv/monitor”对应的20
for i, colormap in enumerate(VOC_COLORMAP):
colormap2label[(colormap[0]*256 + colormap[1])*256 + colormap[2]] = i
crop_size=(300,480)
voc_dir="../data/VOCdevkit/VOC2012"
voc_train=d2l.VOCSegDataset(True,crop_size,voc_dir,colormap2label)
voc_test=d2l.VOCSegDataset(False,crop_size,voc_dir,colormap2label)
print(voc_train.__getitem__(0))
imgarr=voc_train.__getitem__(0)[1]
print(imgarr.max())#20
print(imgarr[100:105,150:160])
'''
[[ 0. 0. 20. 20. 20. 20. 20. 20. 20. 20.]
[ 0. 0. 20. 20. 20. 20. 20. 20. 20. 20.]
[ 0. 0. 20. 20. 20. 20. 20. 20. 20. 20.]
[ 0. 0. 20. 20. 20. 20. 20. 20. 20. 20.]
[ 0. 0. 20. 20. 20. 20. 20. 20. 20. 20.]]
''' 没有问题,显示出来的位置确实是索引20,也就是电脑显示器的类别索引。
其中的VOCSegDataset类也贴出来,d2l包已有,有兴趣的可以查看里面包含的函数。
class VOCSegDataset(gdata.Dataset):
"""The Pascal VOC2012 Dataset."""
def __init__(self, is_train, crop_size, voc_dir, colormap2label):
self.rgb_mean = nd.array([0.485, 0.456, 0.406])
self.rgb_std = nd.array([0.229, 0.224, 0.225])
self.crop_size = crop_size
data, labels = read_voc_images(root=voc_dir, is_train=is_train)
self.data = [self.normalize_image(im) for im in self.filter(data)]
self.labels = self.filter(labels)
self.colormap2label = colormap2label
print('read ' + str(len(self.data)) + ' examples')
def normalize_image(self, data):
return (data.astype('float32') / 255 - self.rgb_mean) / self.rgb_std
def filter(self, images):
return [im for im in images if (
im.shape[0] >= self.crop_size[0] and
im.shape[1] >= self.crop_size[1])]
def __getitem__(self, idx):
data, labels = voc_rand_crop(self.data[idx], self.labels[idx],*self.crop_size)
return (data.transpose((2, 0, 1)),voc_label_indices(labels, self.colormap2label))
def __len__(self):
return len(self.data)