密度可达、sklearn高斯混合模型
密度可达
直接密度可达
核心对象q直接密度可达p,反之不一定
只有 核心对象 才有资格 发起密度可达 概念 , 不是核心对象 , 没有资格作为起点

密度可达
核心对象q密度可达p
链上的核心对象要求 : 链的起点 , 和经过的点 , 必须是核心对象 , 链的最后一个点 , 可以是任意对象 ;

密度相连
O 以及到 样本 p 或者 样本 q 中间的样本都必须是核心对象 , 但是 p 和 q 两个对象不要求是核心对象, 它们可以是普通的样本点
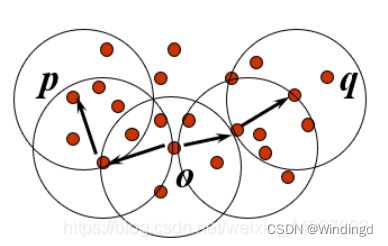
密度聚类
DBSCAN 方法:参考
① 全称 : Density Based Spatial Clustering of Application with Noise , 基于密度兼容噪音的空间聚类应用 算法 ;
② 聚类分组原理 : 数据样本 p 与 q 存在密度连接关系 , 那么 p 和 q 这两个样本应该划分到同一个聚类中 ;
③ 噪音识别原理 : 数据样本 n nn 与 任何样本 不存在 密度连接 关系 , 那么 n nn样本 就是噪音数据 ;
从选定的核心点出发,不断向密度可达的 ϵ ϵ ϵ-邻域扩张,得到一个包含核心点和边界点的最大化区域,区域中任意两点密度相连参考
Python实现
sklearn有对应的包
class sklearn.cluster.DBSCAN(eps=0.5,
min_samples=5,
metric=’euclidean’,
metric_params=None,
algorithm=’auto’,
leaf_size=30,
p=None,
n_jobs=1)
高斯混合模型
-
概率模型
指我们要学习的模型的形式是P(Y|X),在分类过程中通过未知数据X,获得Y取值为的一个概率分布,即训练后模型的输出是对应各个不同类的概率。选取概率最大类作为标签。 -
随机变量
随机变量可以看做是关联了概率值的变量,即变量取每个值有一定的概率。它分为离散型和连续型两种 -
概率
自变量是随机变量,它可以取很多值,每个值都对应这一个概率,这些所有概率加起来等于1
我理解的上述随机变量为样本,对应的值为类别 -
概率分布
随机变量对应每个取值的概率
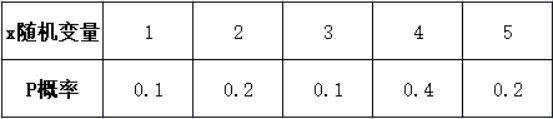
-
概率密度
随机变量是连续的,概率分布叫概率密度 -
概率密度函数参考
- 描述连续型随机变量所服从的概率分布。
- 其中随机变量取每个具体的值的概率为0,但在落在每一点处的概率是有相对大小的。例如在正方形内随机扔一个点,落到任意一点(x, y)的概率值为0,但是其取值落在某一个区间的值可以不为0。因为这一个点的数量为1,而整个正方形内的点数为无穷大,二者之比值为0。、
- 对于概率密度函数,落在各个不同的点处的概率是不相等的。
- 分布函数与概率密度函数相对应,分布函数是概率密度函数的变上限积分。
分布函数:

例如
- 高斯分布-概率密度函数

- 均匀分布-概率密度函数

高斯混合模型
概率模型:学习的模型的形式是P(Y|X),通过未知数据X可以获得Y取值的一个概率分布,也就是是一系列值的概率(对应于分类问题来说,就是对应于各个不同的类的概率),然后我们可以选取概率最大的那个类作为判决对象(软分类soft assignment)
非概率模型:指我们学习的模型是一个决策函数Y=f(X),输入数据X是多少就可以投影得到唯一的一个Y(算硬分类hard assignment)。
GMM:学习的过程就是训练出几个概率分布,所谓混合高斯模型就是指对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率,可以选取概率最大的类所为判决结果
- GMM,学习的过程就是训练出几个概率分布,所谓混合高斯模型就是指对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
理论上可以通过增加Model的个数,用GMM近似任何概率分布 - 混合高斯模型的定义为

其中K为模型的个数
π k π_k πk为第k个高斯的权重
p ( ) p() p()为第k个高斯的概率密度函数,其均值为 u k u_k uk,方差为 σ k σ_k σk
参数估计:最大似然;求解方法:EM算法

对概率密度的估计,就是求得 π k π_k πk, u k u_k uk, σ k σ_k σk各个变量。当求出的表达式后,求和式的各项的结果就分别代表样本x属于各个类的概率。
在聚类中的应用:
当数据事实上有多个类,或者我们希望将数据划分为一些簇时,可以假设不同簇中的样本各自服从不同的高斯分布,由此得到的聚类算法称为高斯混合模型
参考
它相比于K均值算法的优点是:
可以给出一个样本属于某类的概率是多少;
不仅仅可以用于聚类,还可以用于概率密度的估计;
并且可以用于生成新的样本点
sklearn调用
make_blobs聚类数据生成器参考
plt.scatter()函数参数
调用GMM
#matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
#产生实验数据
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=400, centers=4,
cluster_std=0.60, random_state=0)
X = X[:, ::-1] #交换列是为了方便画图
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=4).fit(X)
labels = gmm.predict(X)
plt.scatter(X[:, 0], X[:, 1],c=y_true,s=40, cmap='viridis')
plt.show()
GMM簇分配的概率结果
round()对浮点数进行四舍五入参考
max参考
#由于GMM有一个隐含的概率模型,因此它也可能找到簇分配的概率结果——在Scikit-Learn中用predict_proba方法
#实现。这个方法返回一个大小为[n_samples, n_clusters]的矩阵,矩阵会给出任意属于某个簇的概率
probs = gmm.predict_proba(X)
print(probs.shape)
print(probs[0:5,:].round(3))
# 输出结果
[[0. 0.531 0. 0.469]
[1. 0. 0. 0. ]
[1. 0. 0. 0. ]
[0. 1. 0. 0. ]
[1. 0. 0. 0. ]]