多传感器融合目标检测系列:CenterFusion(基于CenterNet)源码深度解读: :DLA34 (四)
文章目录
- 一、CenterFusion与CenterNet
- 二、CenterNet(backbone)
-
- 2.1 DLA34基本结构
- 2.2 DLASeg
- 2.3 DLASeg基本模块
-
- Basic Block
- Root
- Tree
- DLA34
- IDAUP
- 三、Head
-
- 3.1 Primary Head & Secondary Head
- 四、DLA34与Head层连接
- 参考博文与文献
- 针对nuScenes数据集,我发布了一系列连载文章,欢迎大家阅读:
nuScenes自动驾驶数据集:数据格式精解,格式转换,模型的数据加载 (一)
nuScenes自动驾驶数据集:格式转换,模型的数据加载(二)
CenterFusion(多传感器融合目标检测网络)与自动驾驶数据集nuScenes:模型的数据加载(三)
CenterFusion源码深度解读: CenterNet网络结构:DLA34 (四) - 多传感器融合目标检测系列
一、CenterFusion与CenterNet
笔者目前的方向可以概括为基于多传感器融合的小目标检测,在基于CNN的模型中,我选中了田纳西大学提出的CenterFusion作为自己的实验之一,因为CenterFusion对于nuScenes的数据处理是目前CNN模型中较为全面的,这里的全面指的是:对目标的描述详细,输入模型的特征项多(包括三维锚框,速度等),模型的性能较其baseline提升较大,对雷达特征进行了多种处理并采用middle-fusion的融合方法,兼顾了检测的分辨率和语义丰富度,是众多融合模型中综合表现和new idea比较多的一个融合结构。

anchor-based方法:有很多不足的地方:1. 需要后期nms等后处理;2. 图像以框作为输入,引入了大量的非相关因素训练;3. anchor的匹配机制使得对于小目标的检测较弱;4. anchor在训练的过程中存在远超正样本的负样本数量,会造成内存过大且大部分loss都放在易分类的simple data中。综上,基于锚框的方法存在许多问题,基于这些问题,CenterNet的作者提出了基于center point的方法。
anchor-free方法:CenterNet作为无锚框的检测方法(ExtremeNet,CornerNet)之一,主要原理是对backbone产生的feature map进行再次处理:将其后面接入一个名为关键点热力图(heat map),利用heat map对中心点进行预测,同时通过中心点回归到其他目标属性上:包括姿态、肢体检测等应用,这也是CenterFusion作者为什么采用CenterNet结构的原因:可以通过纯图像信息回归(Primary Regression Heads)到目标基本信息。
CenterFusion检测流程:
- 第一次预测:通过纯图像信息利用CenterNet回归目标的初始信息。
- 雷达点云处理:将雷达点pad到统一长宽高并投影到图像中,通过第一次预测的目标框排除背景雷达点。
- 第二次预测:利用backbone的特征图与radar特征图融合,进行第二次高精度回归目标的速度方向及其他属性信息。
- 结合一、二次预测标记目标3D位置。
二、CenterNet(backbone)
CenterNet作为结构的backbone,作者对比了多种不同的构成:DLA34,Hourglass,ResNet,评价不同的backbone下的各项性能指标,最后得出Hourglass综合最优,可以生成最优的关键点估计,源码中采用改进过的DLA34作为例子,因此我们着重介绍DLA作为backbone时,整体的模型搭建流程。
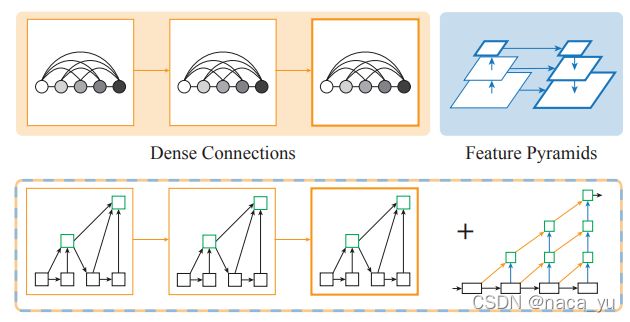
如上图所示,常用的融合方法为DC与FP,其中Dense Connections来自DenseNet,可以聚合语义信息。Feature Pyramids空间特征金字塔可以聚合空间信息。DLA同时结合以上两点,提出了一种树形+双向融合结构。
2.1 DLA34基本结构

DLA结构,由 五大部分组成:base_layer是前两个方块,进行快速的下采样,后面四个红框,每一个红框是一个Tree-树结构,树结构之间也同时存在流动,如 橙色箭头线(上采样)所示,将上一级的Tree的图像上采样之后融合。
总结一下:
- 红色框代表的是用树结构链接的层次结构,能够更好地传播特征和梯度。
- 橙色链接代表的是IDA,负责链接相邻两个stage的特征让深层和浅层的表达能更好地融合。
- 蓝色连线代表进行了下采样
2.2 DLASeg
作者没有完全照搬传统的DLA结构,而是提出了DLASeg,改进DLA34,将可变形卷积DeformConv等引入传统的DLA模型中。以下是作者原话:
We follow CenterNet and use a modified version of the Deep Layer Aggregation (DLA) network as the backbone.
作者先:
- 初始化两个预测头:primary heads 和 secondaryheads;
- 然后初始化DLA34作为backbone;
- 随后,作者初始化DLAUP和IDAUP对各个树根进行上采样与融合,输出最终的融合特征图hm_head,wh_head等;

如上是DLASeg的模型构建流程图。
class DLASeg(BaseModel):
def __init__(self, num_layers, heads, head_convs, opt):
## BaseModel中初始化了模型的head,通过setarr()方法存储预测头,forward中通过getarr()调用初始化好的预测头进行连接
super(DLASeg, self).__init__(heads, head_convs, 1, 64 if num_layers == 34 else 128, opt=opt)
down_ratio=4
self.opt = opt
self.node_type = DLA_NODE[opt.dla_node] # 作者引入的dcn,可变形卷积:node-type
print('Using node type:', self.node_type)
self.first_level = int(np.log2(down_ratio))
self.last_level = 5
#加载DLA34作为self.base,gloabal()这里是引用外部dla34()函数初始化并返回DLA网络
self.base = globals()['dla{}'.format(num_layers)](pretrained=(opt.load_model == ''), opt=opt)
#channels是每个根部的Root向量维度,最后输出为512channels
channels = self.base.channels#[16, 32, 64, 128, 256, 512]
scales = [2 ** i for i in range(len(channels[self.first_level:]))]#[1,2,4,8]是上采样的倍数
'''
输入信息
first_level = 2
channels = [16, 32, 64, 128, 256, 512]
scales = [1,2,4,8]
'''
self.dla_up = DLAUp(
self.first_level, channels[self.first_level:], scales,
node_type=self.node_type)
out_channel = channels[self.first_level]
self.ida_up = IDAUp(
out_channel, channels[self.first_level:self.last_level],
[2 ** i for i in range(self.last_level - self.first_level)],
node_type=self.node_type)
#相当于forward,在DLA的基础上使用Deformable Convolution和Upsample组合多层信息,y[-1]为最后的输出
def img2feats(self, x):
x = self.base(x)
x = self.dla_up(x)
y = []
for i in range(self.last_level - self.first_level):
y.append(x[i].clone())
self.ida_up(y, 0, len(y))
return [y[-1]]
2.3 DLASeg基本模块
Basic Block
这是模型中的方块,也是最基本的组成结构。
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1, dilation=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3,
stride=stride, padding=dilation,
bias=False, dilation=dilation)
self.bn1 = BatchNorm(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=dilation,
bias=False, dilation=dilation)
self.bn2 = BatchNorm(planes)
self.stride = stride
def forward(self, x, residual=None):
if residual is None:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.relu(out)
return out
Root

- Root用来聚合不同尺度的特征信息,绿色的框为Root;
- 红色框为Tree,由一个根节点(level root)和多个子节点(basic block)组成;
class Root(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, residual):
super(Root, self).__init__()
self.conv = nn.Conv2d(
in_channels, out_channels, 1,
stride=1, bias=False, padding=(kernel_size - 1) // 2)
self.bn = nn.BatchNorm2d(out_channels, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.residual = residual
def forward(self, *x): # *x代表多个输入
children = x
x = self.conv(torch.cat(x, 1))#从channel维度上把多层次特征信息concate
x = self.bn(x)
if self.residual: # 类似于resnet的残差
x += children[0]
x = self.relu(x)
return x
Tree
Tree的定义中,最关键的核心是Tree的递归结构,levels决定树是几层的结构
- 如果level=1时,对应如下结构:

如下是借鉴的某个大佬画的细节推导图[引用连接]:

- 如果levels=2,则需要递归建立双层结构,其中有一个子树如左部所示:

如下图片同引自于相同博主。

- 每次进入递归中level-1,直到level=1,level=1时的动作时建立子树的动作是一样的。
class Tree(nn.Module):
#以第一次输入举例(level = 1):1, Basciblock, 32, 64, 2, False
def __init__(self, levels, block, in_channels, out_channels, stride=1,
level_root=False, root_dim=0, root_kernel_size=1,
dilation=1, root_residual=False):
super(Tree, self).__init__()
if root_dim == 0:
root_dim = 2 * out_channels # 64 * 2
if level_root:
'''
如果是树根,除了要concate自己的两个子树之外,还要链接上一个s树的downsample作用下的输出,
如forward中children = [bottom,x1,x2],因此加in_channels
'''
root_dim += in_channels
if levels == 1:#level=1,即第1层root,它子节点是两个block
self.tree1 = block(in_channels, out_channels, stride,
dilation=dilation)
self.tree2 = block(out_channels, out_channels, 1,
dilation=dilation)
else:#递归调用Tree类
self.tree1 = Tree(levels - 1, block, in_channels, out_channels,
stride, root_dim=0,
root_kernel_size=root_kernel_size,
dilation=dilation, root_residual=root_residual)
self.tree2 = Tree(levels - 1, block, out_channels, out_channels,
root_dim=root_dim + out_channels,
root_kernel_size=root_kernel_size,
dilation=dilation, root_residual=root_residual)
if levels == 1: # 连接两个子节点并将根节点维度转为out_channel
self.root = Root(root_dim, out_channels, root_kernel_size,
root_residual)
self.level_root = level_root
self.root_dim = root_dim
self.downsample = None
self.project = None
self.levels = levels
if stride > 1:
self.downsample = nn.MaxPool2d(stride, stride=stride)
if in_channels != out_channels:#project用在当root融合的两个子节点channel不同时的单纯映射
self.project = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels, momentum=BN_MOMENTUM)
)
def forward(self, x, residual=None, children=None):
children = [] if children is None else children
bottom = self.downsample(x) if self.downsample else x # 这里stride都是2,所以进行降采样
residual = self.project(bottom) if self.project else bottom # 映射至统一维度,从而进行concate
if self.level_root:
children.append(bottom)
x1 = self.tree1(x, residual)
if self.levels == 1:
x2 = self.tree2(x1)
x = self.root(x2, x1, *children)
else:
children.append(x1)
x = self.tree2(x1, children=children)
#需要append的数据有:bottom, x1,分别是初始输入,左子树输出,一共加起来的channels=in_channels + out_channels * 2
return x
DLA34
- 这部分负责将Tree按照顺序连接起来,在forward()中定义
#DLA([1, 1, 1, 2, 2, 1],[16, 32, 64, 128, 256, 512], block=BasicBlock, **kwargs)
class DLA(nn.Module):
def __init__(self, levels, channels, num_classes=1000,
block=BasicBlock, residual_root=False, linear_root=False,
opt=None):
super(DLA, self).__init__()
self.channels = channels
self.num_classes = num_classes
self.base_layer = nn.Sequential(
nn.Conv2d(opt.num_img_channels, channels[0], kernel_size=7, stride=1,
padding=3, bias=False),
nn.BatchNorm2d(channels[0], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True))
#level0,1作为前面两个小方块
self.level0 = self._make_conv_level(
channels[0], channels[0], levels[0])
self.level1 = self._make_conv_level(
channels[0], channels[1], levels[1], stride=2)
#tree是每个红色框,是树根
self.level2 = Tree(levels[2], block, channels[1], channels[2], 2,
level_root=False,
root_residual=residual_root)#1, Basciblock, 32, 64, 2, False
self.level3 = Tree(levels[3], block, channels[2], channels[3], 2,
level_root=True, root_residual=residual_root)#2, Basciblock, 64, 128, 2, True
self.level4 = Tree(levels[4], block, channels[3], channels[4], 2,
level_root=True, root_residual=residual_root)#2, Basciblock, 128, 256, 2, True
self.level5 = Tree(levels[5], block, channels[4], channels[5], 2,
level_root=True, root_residual=residual_root)#1, Basciblock, 256, 512, 2, True
IDAUP
- 负责上采样并在DeformConv中加入可变形卷积提高卷积核的视野范围、根据任务优化卷积核形状,有利于后面的姿态估计等任务。
class IDAUp(nn.Module):
'''
IDAUp(channels[j], in_channels[j:], scales[j:] // scales[j])
ida(layers, len(layers) -i - 2, len(layers))
'''
def __init__(self, o, channels, up_f):
super(IDAUp, self).__init__()
for i in range(1, len(channels)):
c = channels[i]
f = int(up_f[i])
proj = DeformConv(c, o)
node = DeformConv(o, o)
up = nn.ConvTranspose2d(o, o, f * 2, stride=f,
padding=f // 2, output_padding=0,
groups=o, bias=False)
fill_up_weights(up)
setattr(self, 'proj_' + str(i), proj)
setattr(self, 'up_' + str(i), up)
setattr(self, 'node_' + str(i), node)
def forward(self, layers, startp, endp):
for i in range(startp + 1, endp):
upsample = getattr(self, 'up_' + str(i - startp))
project = getattr(self, 'proj_' + str(i - startp))
layers[i] = upsample(project(layers[i]))
node = getattr(self, 'node_' + str(i - startp))
layers[i] = node(layers[i] + layers[i - 1])
三、Head
3.1 Primary Head & Secondary Head


class BaseModel(nn.Module):
#heads, head_convs, 1, 64 if num_layers == 34 else 128, opt=opt
def __init__(self, heads, head_convs, num_stacks, last_channel = 64, opt=None):
super(BaseModel, self).__init__()
self.opt = opt
if opt is not None and opt.head_kernel != 3:# 3X3的kernel
print('Using head kernel:', opt.head_kernel)
head_kernel = opt.head_kernel
else:
head_kernel = 3
self.num_stacks = num_stacks#1
self.heads = heads
self.secondary_heads = opt.secondary_heads
# opt.secondary_heads = ['velocity', 'nuscenes_att', 'dep_sec', 'rot_sec']
last_channels = {head: last_channel for head in heads}#primary heads
for head in self.secondary_heads:#secondary heads
last_channels[head] = last_channel + len(opt.pc_feat_lvl)#在原本基础上增加雷达特征通道
#opt.pc_feat_lvl = ['pc_dep','pc_vx','pc_vz'],如果有雷达相关,那通道数增加len()个数量
# 定义每个head的网络结构
for head in self.heads:
classes = self.heads[head]#channel大小
head_conv = head_convs[head]#conv层
if len(head_conv) > 0:
#网络架构:out = nn.conv2d(256, classes, kernel_size = 1...)
out = nn.Conv2d(head_conv[-1], classes, #最后一层,输出为head的通道数
kernel_size=1, stride=1, padding=0, bias=True)
conv = nn.Conv2d(last_channels[head], head_conv[0],#作为第一层,输入时last_channel
kernel_size=head_kernel,
padding=head_kernel // 2, bias=True)
convs = [conv]
for k in range(1, len(head_conv)):
convs.append(nn.Conv2d(head_conv[k - 1], head_conv[k],
kernel_size=1, bias=True))
'''
convs的结构是[conv1(64, 256, 1x1), conv2... out(256, , classes, 1x1)]
下面将每个conv部分后面加上激活函数,并最后放上out(1x1的卷积)
'''
if len(convs) == 1:
fc = nn.Sequential(conv, nn.ReLU(inplace=True), out)
elif len(convs) == 2:
fc = nn.Sequential(
convs[0], nn.ReLU(inplace=True),
convs[1], nn.ReLU(inplace=True), out)
elif len(convs) == 3:
fc = nn.Sequential(
convs[0], nn.ReLU(inplace=True),
convs[1], nn.ReLU(inplace=True),
convs[2], nn.ReLU(inplace=True), out)
elif len(convs) == 4:
fc = nn.Sequential(
convs[0], nn.ReLU(inplace=True),
convs[1], nn.ReLU(inplace=True),
convs[2], nn.ReLU(inplace=True),
convs[3], nn.ReLU(inplace=True), out)
if 'hm' in head:#如果包含heat_map项,添加偏置
fc[-1].bias.data.fill_(opt.prior_bias)
else:
fill_fc_weights(fc)
else:#head_conv <= 0
fc = nn.Conv2d(last_channels[head], classes,
kernel_size=1, stride=1, padding=0, bias=True)
if 'hm' in head:
fc.bias.data.fill_(opt.prior_bias)#'--prior_bias', type=float, default=-4.6
else:
fill_fc_weights(fc)
self.__setattr__(head, fc)#类实例的每个属性进行赋值时,都会首先调用__setattr__()方法,并在__setattr__()方法中将属性名和属性值添加到类实例的__dict__属性中
四、DLA34与Head层连接
def img2feats(self, x):
x = self.base(x)
x = self.dla_up(x)
y = []
for i in range(self.last_level - self.first_level):
y.append(x[i].clone())
self.ida_up(y, 0, len(y))
return [y[-1]]
DLASeg 从model\networks\base_model.py中的BaseModel基类中,继承forward。
def forward(self, x, pc_hm=None, pc_dep=None, calib=None):#这是模型最后的forward,组合前面的DLA34与head进行前向预测
## extract features from image
feats = self.img2feats(x) # y[-1],返回的是最后一层backbone的融合特征图
out = []
for s in range(self.num_stacks):#num_stacks = 1,这里指的是堆叠DLA的个数
z = {}
## Run the first stage heads-primary head,如果只有图片数据
for head in self.heads:
if head not in self.secondary_heads:
z[head] = self.__getattr__(head)(feats[s])#z代表head输出
if self.opt.pointcloud: # 雷达点云存在时生成radar heatmap和second head
# get pointcloud heatmap
if not self.training:
if self.opt.disable_frustum:
pc_hm = pc_dep
if self.opt.normalize_depth:
pc_hm[self.opt.pc_feat_channels['pc_dep']] /= self.opt.max_pc_dist
else:
pc_hm = generate_pc_hm(z, pc_dep, calib, self.opt)
ind = self.opt.pc_feat_channels['pc_dep']
z['pc_hm'] = pc_hm[:,ind,:,:].unsqueeze(1)
## Run the second stage heads second regression head
sec_feats = [feats[s], pc_hm]
sec_feats = torch.cat(sec_feats, 1)
for head in self.secondary_heads:
z[head] = self.__getattr__(head)(sec_feats)
out.append(z)
return out
到这里,最后的返回的out,是所有head的最终输出结果,用作Loss。
参考博文与文献
- CenterNet的骨干网络之DLASeg
- CenterFusion
- CenterNet
- anchor-free