TensorFlow入门必备知识
一、pip安装
- CPU版本
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==1.13.1
- GPU版本
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow-gpu
二、使用
import tensorflow as tf
#查看tensorflow 版本
print(tf.__version__)出现报错:
![]()
解决方法:
https://support.microsoft.com/zh-cn/help/2977003/the-latest-supported-visual-c-downloads
(安装的时候记得看Python版本,如果是64位的,下载visual studio 2015/2017和2019一定要选择64位的。)
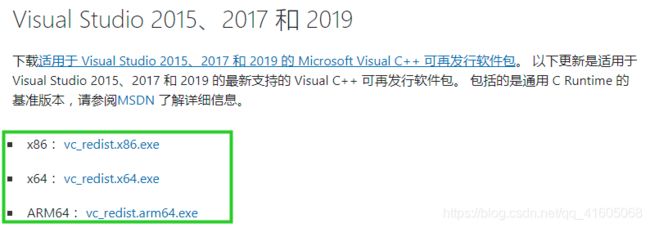
安装时报错:
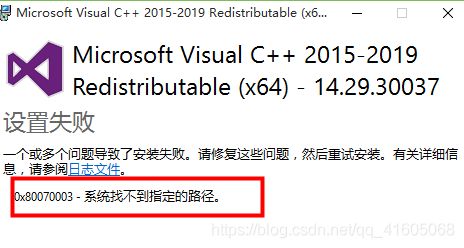
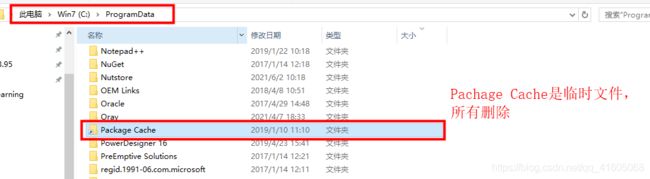
重新安装
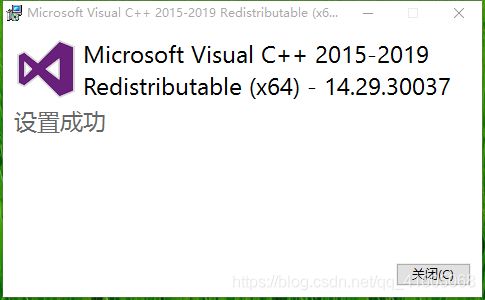
运行结果:
python与tensorflow对应版本:https://tensorflow.google.cn/install/source#gpu
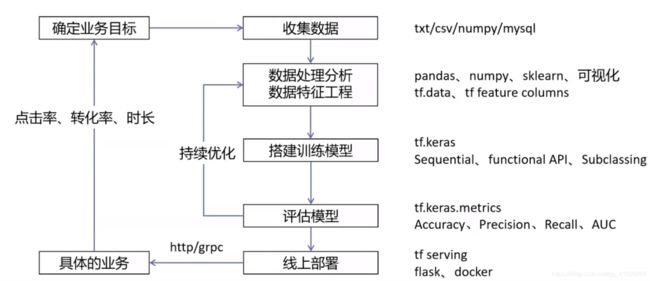
二、Tensorflow机器学习通用流程
三、为什么选择TensorFlow?
- 语言多样性
Tensorflow使用C++实现,然后用Python封装。谷歌号召社区通过SWIG开发更多的语言接口来支持TensorFow。
- 使用分发策略进行分发训练
对于大型ML训练任务,分发策略AOI使在不更改模型定义的情况下,可以轻松的在不同的硬件配置上分发和训练模型。由于Tensorflow支持一些列硬件加速器,如CPU、GPU和TPU。
- Tensorflow可视化
TensorBoard是tensorflow的一组Web应用,用来监控TensorFlow运行过程
- 在任何平台上的生产中进行强大的模型部署
一旦您训练兵保存了模型,就可以直接在应用程序中执行它,或者使用部署库为其提供服务:
1.Tensorflow服务:允许模型通过HTTP/REST或GRPC/协议缓冲区提供服务的Tensorflow库构建。
2.Tensorflow Lite:Tensorflow针对移动和嵌入式设备的轻量级解决方案提供了在Android、IOS和嵌入式系统部署模型的能力。
3.tensorflow.js:支持JavaScript环境中部署模型,例如在Web浏览器或服务器端通过Node.js部署模型。Tensorflow.js还支持在JavaScript中定义模型,并使用类似Kera的api直接在Web浏览器中进行训练。
四、TensorFlow基础
通过一个简单的加法例子学习tensorflow:
a_t = tf.constant(10)
b_t = tf.constant(20)
c_t = tf.add(a_t,b_t)
print("tensorflow实现加法运算:",c_t)
# 开启会话让计算结果出现
with tf.Session() as sess:
sum_t = sess.run(c_t)
print("在sess当中的sum_t:",sum_t)运行结果:
tensorflow实现加法运算: Tensor("Add_1:0", shape=(), dtype=int32) 在sess当中的sum_t: 30
4.1TensorFlow结构分析
tensorflow程序通常被组织成一个构建图阶段和一个执行图阶段。
在构建阶段,数据与操作的执行步骤被描述成一个图。
在执行阶段,使用会话执行构建好的图中的操作。
- 图和会话:
图:这是tensorflow将计算表示为指令之间的依赖关系的一种表示方法
会话:tensorflow跨一个或多个本地或远程设备运行数据流图的机制。
- 张量:tensorflow中的基本数据对象
- 节点:提供图当中执行的操作
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源框架。
节点(operation)在图中表示数学操作,线(edges)则表示在节点间相互联系的多维数组,即张量(tensor)
4.1.1图
图包含了一组tf.operation代表的计算单元对象和tf.Tensor代表的计算单元之间流动的数据。
默认图:get_default_graph()
此时,我们创建一个新图,去做加法运算:
new_g = tf.Graph()
with new_g.as_default():
new_a = tf.constant(10)
new_b = tf.constant(20)
new_t = tf.add(new_a,new_b)
#打印Tensor的图
print("构造的图:",new_a.graph)
# 开启会话让计算结果出现
#将默认图修改为你自定义的图
with tf.Session(graph=new_g) as sess:
print("sess的图:",sess.graph)
sum_t = sess.run(new_t)
print("在sess当中的sum_t:",sum_t)构造的图:sess的图:
4.1.2TensorBoard可视化
TensorFlow可用于训练大规模深度神经网络所需的计算,使用该工具涉及的计算往往复杂而深奥,为例方便TensorFlow程序的理解、调优和优化,TensorFlow提供了tensorBoard可是化工具。
1.数据序列化events文件
file_writer = tf.summary.FileWriter("路径名./temp/",graph=sess.graph)将在指定目录中生成一个event文件,其名称格式如下:
events.out.tfevents.{timestamp}.{hostname}
2.启动TensorBoard
tensorboard --logdir="./tensorboard" --host=127.0.0.1
出现报错:
因为numpy版本太高,修改numpy版本:
pip uninstall numpy
pip install numpy==1.16.0
地址:127.0.0.1:6006

4.1.3常见OP
| 类型 | 实例 |
|---|---|
| 标量运算 | add,sub,mul,div,exp,log,greater,less,equal |
| 向量运算 | concat,slice,splot,constant,rank,shape,shuffle |
| 矩阵运算 | matmul,matrixinverse,matrixdateminant |
| 带状态运算 | Variable,assgin,assginadd |
| 神经网络组件 | softmax,sigmoid,relu,convolution,max_pool |
| 存储,恢复 | Save,Restroe |
| 队列及同步运算 | Enqueue,Dequeue,MutexAcquire,MutexRelease |
| 控制流 | Merge,Switch,Enter,Leave,Nextiteration |
- 所有的定义,以tensorflow定义数据都是op
- op是一个运算节点,返回的是数据的tensor
# 后边的0是不变的,前边的名称是唯一的_自增 Tensor("Const_2:0", shape=(), dtype=int32)
并且每一个op指令都对应一个唯一的名称,如上面的Const_2:0
指定op名称:
#name属性
a_t = tf.constant(10,name="a_t")
变量op:
tensorflow变量是表示程序处理的共享持久状态的最佳方法,变量通过tf.Variable OP类进行操作,变量的特点:
- 存储持久化
- 可修改值
- 可指定被训练
tf.Variable(initial_value=None,trainable=True,collections=None,name=None)
- initial_value:初始化的值
- trainable:是否被训练
- collections:新变量将添加到列出的图的集合中collections,默认为[GraphKeys.GLOBAL_VARIABLES],如果trainable是True变量也被添加到图形集合GraphKeys.TRAINABLE_VARIABLES
- 变量需要显示初始化,才能运行值
a = tf.Variable(initial_value=3)
b = tf.Variable(initial_value=4)
c = tf.add(a,b)
#手动初始化变量
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print("结果:",sess.run(c))4.1.4会话
一个运行tensorflow operation的类。
在控制台中,可以使用tf.InteractiveSession()开启一个session。
1. tf.Session()
tf.Session(target='',graph=None,config=None)
- target:为空(默认),会话将仅使用本地计算机中的设备,可以指定grpc://网址,以便指定TensorFlow服务器的地址,这使得会话可以访问该服务器控制的计算机上的所有设备。
- graph:默认情况下,新的tf.Session将绑定当前的默认图。
- config:此参数允许指定一个tf.ConfigProto以便控制会话的行为。例如,ConfigProto协议用于打印设备使用信息。
tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True))运行结果:
a_t: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2021-07-05 16:55:14.537052: I tensorflow/core/common_runtime/placer.cc:1059] a_t: (Const)/job:localhost/replica:0/task:0/device:CPU:0
b_t: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2021-07-05 16:55:14.542800: I tensorflow/core/common_runtime/placer.cc:1059] b_t: (Const)/job:localhost/replica:0/task:0/device:CPU:0
指定运行的cpu:
tf.device("job:localhost/replica:0/task:0/device:CPU:0")
2. run()
run(fetches,feed_dict=None,options=None,run_metadata=None)
- 通过使用sess.run()来运行
- fetches:单一的operation,或者列表、元组(不属于tensorflow的类型不行)
- feed_dict:参数允许调用者覆盖图中张量的值,运行时赋值,与tf.placeholder搭配使用,则会检查值的形状是否与占位符兼容【实际上基本不用】
例子:
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
sum_add = tf.add(a,b)
print("sum_add:",sum_add)
#开启会话
with tf.Session() as sess:
r = sess.run(sum_add,feed_dict={a:3.0,b:4.0})
print("结果:",r)使用tf.operation.eval()也可以运行operation,需要在会话中运行:
a = tf.constant(5.0)
b = tf.constant(6.0)
c = tf.add(a,b)
#创建会话
sess = tf.Session()
#计算C的值
print(sess.run(c))
#必须在session上下文环境中
print(c.eval(session = sess))3. feed操作
run()中的feed_dict属性。
4.1.5张量(Tensor)
其实就是一个n维数组,类型为tf.Tensor。tensor具有以下两个重要的属性:
- type:数据类型
- shape:形状(阶)
1.张量的类型
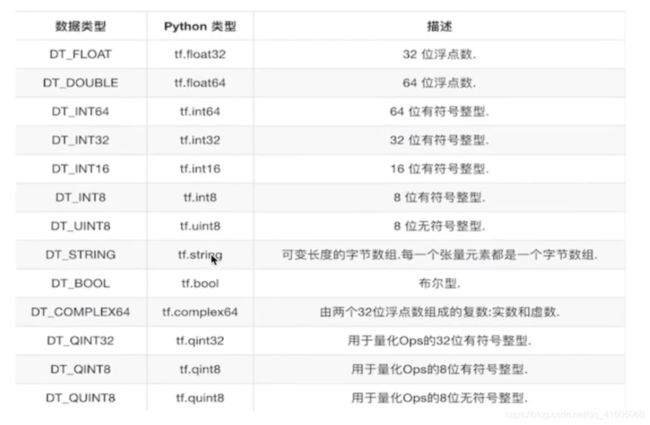
2.张量的阶
 3.张量的指令
3.张量的指令
- 固定值张量
#创建所有元素设置为零的张量,此操作返回一个dtype具有形状shape和所有的元素设置为零的类型的张量
tf.zeross(shape,dtype=tf.float32,name=None)
#给tensor定单张量,此操作返回tensor与所有元素设置为零相同的类型和形状的张量
tf.zeros_like(tensor,dtype=None,name=None)
#创建一个所有元素设置为1的张量,此操作返回一个类型的张量,dtype形状shape和所有元素设置为1
tf.ones(shape,dtype=tf.float32,name=None)
#给tensor定单张量,此操作返回tensor与所有元素设置为1相同的类型和形状的张量
tf.ones_like(tensor,dtype=None,name=None)
#创建一个填充了标量值的张量,此操作返回一个张量的形状dims并填充它value
tf.fill(dims,value,name=None)
#创建一个常数张量
tf.constant(value,dtype=None,shape=None,name='Const')- 随机值张量
#从截断的正太分布中输出随机值,和tf.random_normal()一样,但是所有数字都不能超过两个标准差
tf.truncated_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
#从正态分布中输出随机值,有随机正态分布的数字组成的矩阵
#mean平均值
#stddev标准差
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)- 类型转换
tf.cast(x,dtype,name=None)- 形状转换
# tf.reshape(a,[2,3])
#新的张量
tf.reshape(x,shape)
#设置一开始不清楚的张量
#设置了一次了就不能再设置了
tf.set_shape([4,5])五、Tensorflow版本对比
Tensorflow 2.0的许多优化器与1.0的不同,编写代码时找不到,看了下官方文档,在此记录下。
Convert v1.train to keras.optimizers
Here are things to keep in mind when converting your optimizers:
升级您的优化器可能使旧的检查点不兼容。
所有的epsilons(应该是α β之类的参数)现在默认为1e-7而不是1e-8(在大多数情况下可以忽略不计)。
v1.train.GradientDescentOptimizer 可以直接被替换为 tf.keras.optimizers.SGD.
v1.train.MomentumOptimizer 可以直接被替换为 SGD 优化器, 使用动量参数: tf.keras.optimizers.SGD(…, momentum=…).
v1.train.AdamOptimizer 可以转换为tf.keras.optimizers.Adam. 参数 beta1 和 beta2 重命名为 beta_1 和 beta_2.
v1.train.RMSPropOptimizer 可以转换为 tf.keras.optimizers.RMSprop. 参数decay 重命名为 rho.
v1.train.AdadeltaOptimizer 可以直接转换为 tf.keras.optimizers.Adadelta.
tf.train.AdagradOptimizer 可以直接转换为 tf.keras.optimizers.Adagrad.
tf.train.FtrlOptimizer 可以直接转换为 tf.keras.optimizers.Ftrl. 参数 accum_name 和 linear_name arguments 已经被移除.
The tf.contrib.AdamaxOptimizer 和 tf.contrib.NadamOptimizer, 可以直接转换为 tf.keras.optimizers.Adamax 和 tf.keras.optimizers.Nadam. 参数 beta1 和 beta2 重命名为 beta_1 和 beta_2.