2020 AI 算法工程师常见知识点整合
算法工程师基础理论
- 0.写在前面
- 机器学习流程
-
- 基本概念
-
- 数据
- 从数据到答案
- 将原始数据映射到特征
- 模型:数据关系的近似描述
- 高屋建瓴
- 1. 特征工程
-
- 预处理:将原始数据变为特征向量
-
- 1.数值变量:归一化/标准化处理
-
- 1.1 归一化/标准化
- 1.2 L1/L2范数标准化
- 2. 分类变量:one-hot 编码
- 3. 缺失值、特殊值处理
- 4. 特征转换、构造新特征
- 特征选择(=降维?)
-
- 1. 过滤法(Filter)
- 2. 包装法(Wrapper)
- 3. 嵌入法(Embedded)
- 寻找高级特征
- 补充:处理不平衡数据
-
- 1. 权重法
- 2. 采样法
- 3. SMOTE算法
- AUC曲线
- 降维
- 补充问题
-
- 1. 有哪些文本表示模型?它们各有什么优缺点?
- 2. 图像数据不足时的处理方法
- 2. 模型评估
-
- 1. (离线)评估指标的局限性
- 2. ROC曲线(受试者工作特征曲线)
- 3. 余弦距离的应用
- 4.(在线)A/B测试的陷阱
- 5. (离线)模型评估的方法
- 6. 超参数调优
- 7. 模型过拟合与欠拟合
- 3. 经典算法
-
- 3.1 支持向量机
- 3.2 逻辑回归
- 3.3 决策树
- 3.4 降维
- 3.5 非监督学习
-
- 3.5.1 K-means
- 3.5.2 高斯混合模型(GMM)
- 3.5.3 自组织映射神经网络(SOM)
- 3.5.4 聚类算法的评估
- 3.6 概率图模型(这块是空白)
- 4.优化算法
-
- 4.1 常见损失函数
- 4.2 优化问题
- 4.3 经典优化算法
- 4.4 随机梯度下降及改进
- 4.5 L1正则化与稀疏性
- 5. 采样
-
- 5.1 采样的作用
- 5.2 常见的采样方法
- 5.7 样本不均衡问题
- 深度学习
- 6. 前向神经网络
-
- 6.1 多层感知机与布尔函数
- 6.2 神经网络的激活函数
- 6.3 多层感知机的反向传播算法(这块是薄弱)
- 6.4 神经网络训练技巧
- 6.5 深度卷积网络
- 6.6 深度残差网络
- 循环神经网络
- 强化学习
- 集成学习
- NLP
- CV
- Coding
- 数学
- 参考
-
- 其它总结博客
- 知识点参考
- 总结
-
- 特征工程
- 数据预处理(特征工程的核心)
记录所学,方便复习。
特征工程
|
模型评估
|
经典算法
|
降维
|
非监督学习
|
优化算法
|
采样
|
集成学习
|
神经网络
(0)问题:自我检验: 面试经验 | AI 算法工程师(面试官角度)
(1)综合知识点整理:
- 2020 AI 算法岗春招汇总 & 面经大全来了!点击接收你的招聘秘籍
2.机器学习算法岗面试与提问总结
(2)零散知识
数据预测处理:
合鲸:干货 | 教你一文掌握数据预处理
(3)随文详解 :自己记录详细的知识
- 特征工程——一些知识点
0.写在前面
机器学习流程
基本概念
学了那么多机器学习的理论和算法模型,回过头来再看看这最基础的几个概念:数据、特征和模型。
数据
数据是对现实世界现象的观测。
例如,股票市场数据包括对每日股价、各个公司的盈余公告,甚至专家学者发表的股评文章的观测;个人的生物特征数据包括对每分钟的心率、血糖水平、血压等指标的测量。不同领域的数据示例无穷无尽,不一而足。
每份数据都是管中窥豹,只能反映一小部分现实,把这些观测综合起来才能得到一个完整的描述。
但这个描述非常散乱,因为它由成千上万个小片段组成,而且总是存在测量噪声和缺失值。
总而言之,我们用数据来描述客观事物。这些数据总是会不同程度地存在着噪声和缺失值。
想要(理想地)完整描述需要无穷尽的数据,所以这个描述显得非常散乱。
从数据到答案

从数据到答案的路上,充满了错误的开始和死胡同,经常是有意栽花花不发,无心插柳柳成荫。
数据处理工作流往往是多阶段的迭代过程。
举个例子,股票价格是在交易所中观测到的,然后由像汤森路透这样的中间机构进行汇集并保存在数据库中,之后被某个公司买去,转换为一个 Hadoop 集群上的 Hive 仓库,再被某个脚本从仓库中读出,进行二次抽样和各种处理,接着通过另一个脚本进行清洗,导出到一个文件,转换为某种格式,然后你使用 R、Python 或 Scala 中你最喜欢的建模程序进行试验。接着,预测结果被导出为一个CSV 文件,再用一个估值程序进行解析。模型会被迭代多次,由产品团队用 C++ 或 Java 重写,并在全部数据上运行,然后最终的预测结果会输出到另一个数据库中保存起来。
然而,如果我们不被这些杂乱的工具与系统所迷惑,就能够发现这个过程包括两个构成机器学习基础的数学实体:特征和模型。
将原始数据映射到特征
特征就是,于己而言,特征是某些突出性质的表现,于它而言,特征是区分事物的关键。(参考知乎某答)
我们将描述事物的特征分为数值型特征(定量特征)和非数值型特征(定性特征)。根据数据是否无限可分,可以将数值型特征再继续细分为连续特征和离散特征。
(关于统计学中连续变量和离散变量的定义可参考:
在统计学中,变量按变量值是否连续可分为连续变量与离散变量两种。在一定区间内可以任意取值的变量叫连续变量,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。例如,生产零件的规格尺寸,人体测量的身高、体重、胸围等为连续变量,其数值只能用测量或计量的方法取得。
反之,其数值只能用自然数或整数单位计算的则为离散变量。例如,企业个数,职工人数,设备台数等,只能按计量单位数计数,这种变量的数值一般用计数方法取得。)
即:
离散特征 = 定性特征 ?——(X)
连续特征 = 定量特征 ?——(X)
定量特征:离散特征 + 连续特征(√)
关于变量:点击
从上一节的例子中可以得知,我们平时验证自己的模型时用到的数据集大多数都是已经是被整理过和处理好的数据(由特征和特征值组成)
很多机器学习算法要求输入的样本特征是数学上可计算的, 因此在机器学习之前我们需要将这些不同类型的数据转换为向量表示.即将数据特征向量化
,完成数据的特征表示。(原始数据空间——特征空间)
(也有一些机器学习算法,比如决策树,不需要向量形式的特征,当然也就不需要特征工程中的归一化等处理)
模型:数据关系的近似描述
数据的数学模型 描述了数据不同部分之间的关系。
例如,预测股票价格的模型可以是一个公式,它将公司的收入历史、过去的股票价格和行业映射为预测的股票价格。音乐推荐模型可以基于收听习惯测量用户之间的相似度,然后向收听大量同种歌曲的用户推荐同一个音乐家。
- 线性模型、非线性模型
常见的机器学习模型可以简单的划分为线性模型和非线性模型。

线性模型和非线性模型的区别:
a.线性模型可以用曲线拟合样本,线性模型可以是用曲线拟合样本,但是分类的决策边界一定是直线的,例如logistics模型(广义线性模型,将线性函数进行了一次映射)。
b. 区分是否为线性模型,主要是看一个乘法式子中自变量x前的系数w,如果w只影响一个x,那么此模型为线性模型。或者判断决策边界是否是线性的
c. 其实最简单判别一个模型是否为线性的,只需要判别决策边界是否是直线,也就是是否能用一条直线来划分
更多线性/非线性模型概念:点击
- 生成式模型、判别式模型
对于监督学习来说,其任务就是学习一个模型,应用这一模型,对给定的输入预测相应的输出。
监督学习方法又可以分为生成方法(generative approach)和判别方法(discriminative approach)。所学到的模型分别称为生成模型(generative model)和判别模型(discriminative model)。
更多点击:
由生成模型与判别模型引发出的思考、是什么机器学习中生成模型/判别模型?
高屋建瓴
启发
数据
|
特征 <-特征工程:空间转换(欧式空间-向量表示)、归一化、特征选择、降维
|
模型 <- 数据关系的近似描述:“距离”比较(距离、相似度计算)…
|
答案 <-描述结果:分类、回归、排序…
简单地说,我们的最终目的非常清晰明了:发现数据 + 理解数据。
如果以数据为视角,在本质上来看,整个机器学习的流程不过是一个进行数据分析的过程,只不过因为在将数据变为有用的特征和数据关系描述建模,即特征和模型这两块用到了数学的方法,因此显得比较专业化。前者即是特征工程的任务,主要包括我们目前所熟知的向量化、归一化和缺失值处理等预处理工作,以及特征选择和降维等主要步骤而后者,模型的构建主要是利用常见的数学模型,例如机器学习中常用到的线性回归和逻辑回归等线性模型,决策树、随机森林和梯度提升(gradient boosting)等树模型以及以CNN为代表的的神经网络模型等。
1. 特征工程
问题:
-
离散、连续特征一般怎么处理(onehot、归一化、why、方法 等);
-
特征变换、构造/衍生新特征(woe、iv、统计量 等);
-
特征筛选(离散、连续、多重共线性 等);
-
采样(除了随机呢?);
-
缺失值处理(离散、连续)
-
…
特征工程的概念:
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
通过总结和归纳,人们认为特征工程包括以下方面:(感觉是真的站在了工程的角度上来总结)
- 特征使用方案(数据来源+可用性评估)
- 特征获取方案(获取+存储)
- 特征处理(特征清洗+预处理——是核心部分)
- 特征监控(特征有效性分析+监控重要)
特征工程的核心:特征处理
特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。
框架如下:
预处理:将原始数据变为特征向量
这里主要将 数据分为数值变量和分类变量来进行,而不是现在经常见到的连续型变量和离型变量(这种分法很直观,但是好像不太正确,在下面会阐述)
1.数值变量:归一化/标准化处理
作用:① 无量纲化:将不同规格的数据转换到同一规格——以使得不同的特征具有相同的尺度(Scale),以解决不同指标无法比较的问题。②在训练神经网络的过程中,通过将数据标准化,能够加速权重参数的收敛(加快了梯度下降求最优解的速度)。
写在前面:标准化和归一化这两个词经常混用,所以不用具体纠结于区分标准化和归一化,自己喜欢的话,可以统一叫做”标准化/归一化“。
1.1 归一化/标准化
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种:
-
零均值归一化(Z-Score Normalization) / z-score 标准化 / 方差缩放
零均值归一化是最常见的特征预处理方式,它的作用是将原始数据中心化(分子部分),并标准化成均值为0、标准差为1的一个服从正态分布的数据。
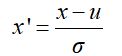
如何本质上理解0均值归一化?其实就是取其离散程度的比值:(依据数据分布)将数据原来x到中心点μ的距离和标准差的比值当做新的x‘(”像标准分布靠拢“)
-
线性函数归一化(Min-Max Scaling)/ min-max 归一化/min-max缩放/极差变换
对原始数据进行线性变换,将其映射到 [0,1]的范围

如何本质上理解线性函数归一化?其实就是取其极差的比值:(将数据看为在一维直有限直线上的分布)将x在原来线段长度上所占的比值作为新的x’(”像标准线段靠拢“)
注意:不要“中心化”稀疏数据!
在稀疏矩阵上执行 0 均值归一化和 min-max 归一化会将其变成密集特征向量,因为他们都会从原始特征值中减去一个量(min 或者μ)。

归一化相关更详细解释:点击1 、点击 2
1.2 L1/L2范数标准化
根据范数来进行 Normalization

将|x1|到 |xn| 先取p次幂再取 1/p 次幂不仅计算麻烦而且没啥用啊,所以取每一个 |xn|的p次幂,求和之后再取 1/p 次幂!——纯属YY
可见,L2范数即为欧式距离,则规则为L2的Normalization公式如下所示,易知,其将每行(条)数据转为相应的“单位向量”。


范数归一化的过程是将每个样本缩放到单位范数(结合单位向量进行理解,p=2时为单位向量,其他为单位范数),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。
更多参考之前的文章:“距离”、“范数”和范数正则化
补充:
-
归一化的好处:加快梯度下降收敛的速度;

-
适用范围:包括线性回归、逻辑回归、支持向量机、神经网络等使用梯度下降求解的模型,不适用于决策树等模型,因为归一化并不会改变样本在特征x上的信息增益。
2. 分类变量:one-hot 编码
数据一般的处理方法:
对数值变量进行归一化,比如零均值归一化;
对分类变量进行 one-hot 编码和序号编码。
序号编码:序号编码通常用于处理类别间具有大小关系的数据。例如高表示为3、中表示为2、低表示为1,转换后依然保留了大小关系。
其它需要进一步转换的情况:
- 将离散特征连续化——将数据向量化(满足模型输入);增加模型非线性性
- one-hot 编码:对离散特征进行编码
- embedding(特征嵌入)
- 将离散特征离散化——有时候就算你需要的是离散值,也是没法直接使用的
- one-hot 编码
- dummy coding 虚拟编码/哑编码
- 将连续特征离散化
- 区间划分:根据阈值进行分组
3. 缺失值、特殊值处理
(1)缺失值
特征有缺失值是非常常见的,对于连续特征,一般采取两种方式来处理:
- 取含有该特征所有样本的平均值作为缺失值的填充
- 取中位数来进行填充
对于离散型特征,一般取“众数”来进行填充,即选择所有有该特征值的样本中最频繁出现的类别值
在sklearn中,可以使用preprocessing.Imputer来选择这三种不同的处理逻辑做预处理。
(2)特殊值
有些特征的默认取值比较特殊,一般需要做了处理后才能用于算法,比如日期时间。
对于时间原始特征,处理方法有很多:
- 使用连续的时间差值法
即计算出所有样本的时间到某一个未来时间之间的数值差距,这样这个差距是UTC的时间差,从而将时间特征转化为连续值 - 离散化,根据时间所在的年,月,日,星期几,小时数,将一个时间特征转化为若干个离散特征
- 权重法,即根据时间的新旧得到一个权重值。
具体可参考: 特征工程之特征表达
4. 特征转换、构造新特征
(1)特征变换——解决非正态性的问题
数据变换一般分为单变量变换和多变量变换。
一般来说多变量变换就成为了特征抽取(Feature Extraction),维度压缩(Dimension Reduction),数据分解(Decomposition)等, 譬如主成分分析(PCA)。这里主要还是单变量的变换。
单变量的变换又分为线性变换和非线性变换, 这里主要是利用一些非线性变换, 来获取合适数据分布的常见方法。
常见的变换方法有如下几种:

(未包括线性变换)
一般使用经验:
(破折号后面代表使用的条件/情况)
-
直接标准化——变换前,数据接近正态分布
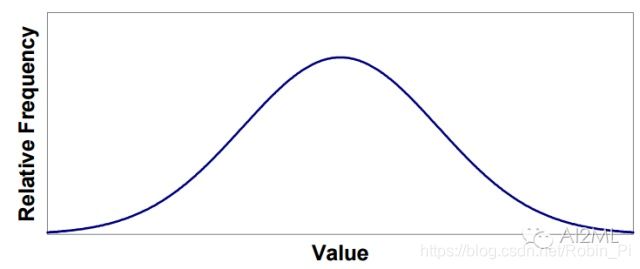
-
square-root变换(取均方根)——变换前数据分布,偏中前
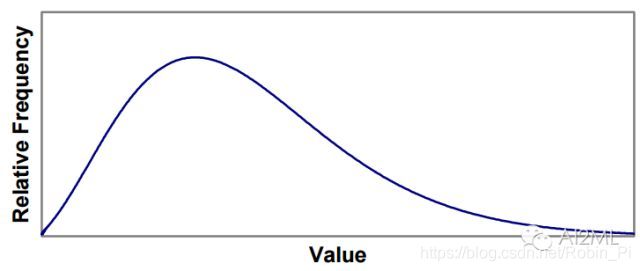
-
logarithmic变换(取 log)——变换前数据分布,偏前

-
inverse/reciprocal变换(取倒数函数)——变换前数据分布,集中前面

-
square变换(取平方)——变换前数据分布,偏中后

-
exponential变换(取指数函数)——变换前数据分布,偏后

个人理解:为什么这些个情况,通过这些函数的变换就可以将数据分布向正态分布靠拢?其实结合这些常见数学函数的图像就可以理解了:

- 转换函数的目的是将原来在某一部分(非中心位置)集中的 y 值变得分散,所以可以选择那些在相应位置y的取值随着x变化非常剧烈(y被打散)的函数。
- 原数据越是表现得极端(极端靠近分布的两头),就越应该使用在相应位置变化趋势越快的那些转换函数;
- 靠近头部/前部的袁(原始)数据的都比较小,取平方根、log 、倒数函数会更有效(效果依次递增),而靠近尾部/后部的(原始)数据都比较大,取平方、指数函数的作用会更明显(效果依次递增)
更多参考:点击
(2)构造/衍生新特征
参考下面的小结:[寻找高级特征]
特征选择(=降维?)
首先,看当业务已经整理好各种特征数据时,第一步是找到该领域懂业务的专家,让他们给一些建议。
其次,通常来说,我们需要从特征是否发散(看方差)和特征与目标的相关性这两个方面来考虑选择特征。
特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
这样看来,特征选择与降维似乎是一个意思?
不不不,特征选择和降维有着些许的相似点,这两者达到的效果是一样的,就是试图去减少特征数据集中的属性(或者称为特征)的数目;
但是两者所采用的方式方法却不同:降维的方法主要是通过特征间的关系,如组合不同的特征得新的属性,这样就改变了原来的特征空间;而特征选择的方法是从原始特征数据集中选择出子集,是一种包含的关系,没有更改原始的特征空间。参考点击
具体来说,常规特征选择的方法有以下三类:
1. 过滤法(Filter)
其主要思想是:对每一维的特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该维特征的重要性,然后依据权重排序。
-
方差
最简单的方法就是方差筛选。方差越大的特征,那么我们可以认为它是比较有用的。在实际应用中,我们会指定一个方差的阈值,当方差小于这个阈值的特征会被我们筛掉。如果方差较小,比如小于1,那么这个特征可能对我们的算法作用没有那么大。最极端的,如果某个特征方差为0,即所有的样本该特征的取值都是一样的,那么它对我们的模型训练没有任何作用,可以直接舍弃。最极端的,如果某个特征方差为0,即所有的样本该特征的取值都是一样的,那么它对我们的模型训练没有任何作用,可以直接舍弃。
-
相关系数
分别计算所有训练集中各个特征与输出值之间的相关系数,设定一个阈值,选择相关系数较大的部分特征。 -
假设检验
比如卡方检验,卡方检验可以检验某个特征分布和输出值分布之间的相关性。
还可以使用 F 检验和 t 检验 -
互信息
即从信息熵的角度分析各个特征和输出值之间的关系评分。互信息值越大,说明该特征和输出值之间的相关性越大,越需要保留。
2. 包装法(Wrapper)
包装法的解决思路没有过滤法这么直接,它会选择一个目标函数来一步步的筛选特征。
其主要思想是:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这里有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,PSO,DE,ABC等。
最常用的方法是递归消除特征法(recursive feature elimination,RFE)。递归消除特征法使用一个机器学习模型来进行多轮训练,每轮训练后,消除若干权值系数的对应的特征,再基于新的特征集进行下一轮训练。
我们下面以经典的SVM-RFE算法来讨论这个特征选择的思路。这个算法以支持向量机来做RFE的机器学习模型选择特征。它在第一轮训练的时候,会选择所有的特征来训练,得到了分类的超平面˙+=0后,如果有n个特征,那么RFE-SVM会选择出中分量的平方值2最小的那个序号i对应的特征,将其排除,在第二类的时候,特征数就剩下n-1个了,我们继续用这n-1个特征和输出值来训练SVM,同样的,去掉2最小的那个序号i对应的特征。以此类推,直到剩下的特征数满足我们的需求为止。
3. 嵌入法(Embedded)
嵌入法也是用机器学习的方法来选择特征,但是它和RFE的区别是它不是通过不停的筛掉特征来进行训练,而是使用的都是特征全集。
其主要思想是:在模型既定的情况下,学习出对提高模型准确性最好的属性,其主要方法是正则化。
最常用的是使用L1正则化和L2正则化来选择特征。正则化惩罚项越大,那么模型的系数就会越小,当正则化惩罚项继续增大到一定程度时,所有的特征系数都会趋于0. 但是我们会发现一部分特征系数会更容易先变成0,这部分系数就是可以筛掉的。也就是说,我们选择特征系数较大的特征。常用的L1正则化和L2正则化来选择特征的基学习器是逻辑回归。
此外也可以使用决策树或者GBDT。
寻找高级特征
寻找更高级特征的方法,可以最常采取的方法有:
- 若干项特征加和: 我们假设你希望根据每日销售额得到一周销售额的特征。你可以将最近的7天的销售额相加得到。
- 若干项特征之差: 假设你已经拥有每周销售额以及每月销售额两项特征,可以求一周前一月内的销售额。
- 若干项特征乘积: 假设你有商品价格和商品销量的特征,那么就可以得到销售额的特征。
- 若干项特征除商: 假设你有每个用户的销售额和购买的商品件数,那么就是得到该用户平均每件商品的销售额。
当然,寻找高级特征的方法远不止于此,它需要你根据你的业务和模型需要而得,而不是随便的两两组合形成高级特征,这样容易导致特征爆炸,反而没有办法得到较好的模型。个人经验是,聚类的时候高级特征尽量少一点,分类回归的时候高级特征适度的多一点。
更多参考:
特征工程之特征选择
机器学习中的特征——特征选择的方法以及注意点
An Introduction to Feature Selection
补充:处理不平衡数据
不均衡数据:因变量y(不是特征)在不同类别中的分布不均衡
这个问题其实不算特征预处理的部分,不过其实它的实质还是训练集中各个类别的样本的特征分布不一致的问题,所以这里我们一起讲。
我们做分类算法训练时,如果训练集里的各个类别的样本数量不是大约相同的比例,就需要处理样本不平衡问题。也许你会说,不处理会怎么样呢?如果不处理,那么拟合出来的模型对于训练集中少样本的类别泛化能力会很差。举个例子,我们是一个二分类问题,如果训练集里A类别样本占90%,B类别样本占10%。 而测试集里A类别样本占50%, B类别样本占50%, 如果不考虑类别不平衡问题,训练出来的模型对于类别B的预测准确率会很低,甚至低于50%。
如何解决这个问题呢?一般有几种方法:权重法、采样法和使用AUC指标等。
1. 权重法
权重法是比较简单的方法,我们可以对训练集里的每个类别加一个权重class weight。如果该类别的样本数多,那么它的权重就低,反之则权重就高。如果更细致点,我们还可以对每个样本加权重sample weight,思路和类别权重也是一样,即样本数多的类别ƒ样本权重低,反之样本权重高。
2. 采样法
针对类别不均衡的问题,采样有两种思路:
- 过采样:对类别样本数多的样本做子采样
- 欠采样:对类别样本数少的样本做过采样
3. SMOTE算法
上述两种常用的采样法很简单,但是都有个问题,就是采样后改变了训练集的分布,可能导致泛化能力差。
所以有的算法就通过其他方法来避免这个问题,比如SMOTE算法通过人工合成的方法来生成少类别的样本。
生成方法是:选取数据少的类别的一点,找出它的最近点,算出差值,随机生成一个0和1之间的随机数,差值乘以随机数。
补:关于采样
其实我们在训练模型的过程,都会经常进行数据采样,为了就是让我们的模型可以更好的去学习数据的特征,从而让效果更佳。但这是比较浅层的理解,更本质上,数据采样就是对随机现象的模拟,根据给定的概率分布从而模拟一个随机事件。另一说法就是用少量的样本点去近似一个总体分布,并刻画总体分布中的不确定性。因为我们在现实生活中,大多数数据都是庞大的,所以总体分布可能就包含了无数多的样本点,模型是无法对这些海量的数据进行直接建模的(至少目前而言),而且从效率上也不推荐。
因此,我们一般会从总体样本中抽取出一个子集来近似总体分布,这个子集被称为“训练集”,然后模型训练的目的就是最小化训练集上的损失函数,训练完成后,需要另一个数据集来评估模型,也被称为“测试集”。
采样的一些高级用法,比如对样本进行多次重采样,来估计统计量的偏差与方法,也可以对目标信息保留不变的情况下,不断改变样本的分布来适应模型训练与学习(经典的应用如解决样本不均衡的问题)。
AUC曲线
更多参考:特征工程之特征预处理、机器学习之类别不平衡问题 (3) —— 采样方法
降维
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1、L2惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。
PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
补充问题
1. 有哪些文本表示模型?它们各有什么优缺点?
文本表示模型
(1)词袋模型和 N-gram 模型
-
词袋模型(bag of words)
忽略词的顺序,使用 TF-IDF(词频-逆文档频率)计算权重:
tf-idf = TF * IDF = 单词 t 在文档 d 中出现的次数 / 文档 d总的单词数 * log { 文档总数 / (包含单词 t 的文档总数+1) }tf-idf
直观的解释是,如果一个单词在非常多的文章里面都出现,那么它可能是一个比较通用的词汇,对于区分某篇文章特殊语义的贡献较小,因此对权重做一定惩罚。 -
N-gram 模型
词袋模型的升级版,将连续出现的n个词(n≤N)组成的词组(N-gram)也作为一个单独的特征放到向量表示中去(若 n=3,则 gram 为 1、2 和 3 )。本质是做了一个大小为n的滑窗的操作。
(2)主题模型
(3)词嵌入与深度学习模型
能够更好地对文本进行建模,抽取出一些高层的语义特征。
-
word2vec
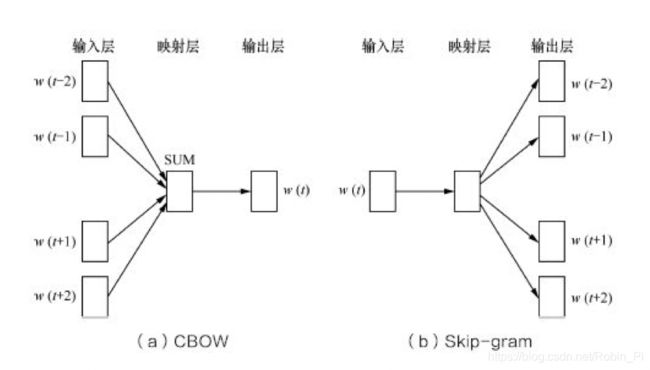 CBOW 模型:拿(一个词语的)上下文作为输入,来预测当前词的生成概率;
CBOW 模型:拿(一个词语的)上下文作为输入,来预测当前词的生成概率;Skip-gram 模型:用一个词语作为输入(使用当前词),来预测它上下文中各词的生成概率;
-
LDA 与 Word2Vec 的区别与联系?
首先,LDA是利用文档中单词的共现关系来对单词按主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。而Word2Vec其实是对“上下文-单词”矩阵进行学习,其中上下文由周围的几个单词组成,由此得到的词向量表示更多地融入了上下文共现的特征。
主题模型和词嵌入两类方法最大的不同其实在于模型本身,主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变量(即主题);而词嵌入模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,需要通过学习网络的权重以得到单词的稠密向量表示。
2. 图像数据不足时的处理方法
- 在图像分类任务中,训练数据不足会带来什么问题?如何缓解数据量不足带来的问题?
一个模型所能提供的信息一般来源于两个方面,一是训练数据中蕴含的信息;二是在模型的形成过程中(包括构造、学习、推理等),人们提供的先验信息。
造成的问题:过拟合
解决办法:
(1)基于数据:数据增强
- 旋转、平移、缩放等;
- 噪声扰动;
- 颜色变换;
- 改变亮度、清晰度等
(2)基于模型 - 简化模型;
- 添加正则项
(3)生成式对抗网络
(4)迁移学习
2. 模型评估
在计算机科学特别是机器学习领域中,对模型的评估同样至关重要。只有选择与问题相匹配的评估方法,才能快速地发现模型选择或训练过程中出现的问题,迭代地对模型进行优化。
模型评估主要分为离线评估和在线评估两个阶段。针对分类、排序、回归、序列预测等不同类型的机器学习问题,评估指标的选择也有所不同。
在离线评估中,我们经常使用的有准确率(accuracy)、精确率-召回率(precision-recall);
而在在线评估中,一般使用一些商业评价指标,如用户生命周期值(customer lifetime value)、广告点击率(click
through rate)、用户流失率(customer churn rate)等,这些指标才是模型使用者最终关心的一些指标。甚至在对模型进行训练和验证过程中使用的评价指标都不一样。
1. (离线)评估指标的局限性
-
准确率的局限性
当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
可选择用平均准确率作为评判指标 -
精确率与召回率的权衡
精确率是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。
召回率是指分类正确的正样本个数占真正的正样本个数的比例。在排序问题中,
通常没有一个确定的阈值把得到的结果直接判定为正样本或负样本,而是采用Top N返回结果的Precision值和Recall值来衡量排序模型的性能,即认为模型返回的Top N的结果就是模型判定的正样本,然后计算前N个位置上的准确率Precision@N和前N个位置上的召回率Recall@N。
解决:
- P-R 曲线
为了综合评估一个排序模型的好坏,不仅要看模型在不同Top N下的Precision@N和Recall@N,而且最好绘制出模型的P-R(Precision-Recall)曲线。

P-R曲线的横轴是召回率,纵轴是精确率。对于一个排序模型来说,其P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。
整条P-R曲线是通过将阈值从高到低移动而生成的。
- F1 score
F1 score是精准率和召回率的调和平均值。

调和平均数:数值倒数的平均数的倒数,它是加权算术平均数的变形,附属于算术平均数
调和平均的哲学意义是在一个过程中有多少条平行的路径,经过这些平行的路径后,等效的结果就是调和平均。
- ROC 曲线
看下面的 第 2 大点 :ROC 曲线的详细介绍
- 平方根误差的”意外“
使用平方根误差评估模型,可能出现的情况是无论使用哪种回归模型,得到的 RMSE 指标都非常高,而事实是在 95%的区间内的预测误差都小于 1%。
原因很可能是:在 5% 的区间出现了非常严重的离群点。
一般情况下,RMSE能够很好地反映回归模型预测值与真实值的偏离程度。但在实际问题中,如果存在个别偏离程度非常大的离群点(Outlier)时,即使离群点数量非常少,也会让RMSE指标变得很差。
相对于使用MAE计算损失,使用MSE的模型会赋予异常点更大的权重。

解决:
- 在数据预处理阶段除掉”噪声点“
- 使用功能其它更合适的指标,比如平均绝对百分比误差(Mean Absolute Percent Error,MAPE)
相比RMSE,MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响。

2. ROC曲线(受试者工作特征曲线)
-
ROC曲线的横坐标为假阳性率(False Positive Rate,FPR);
纵坐标为真阳性率(True Positive Rate,TPR)

 非常绕,但是结合实际来思考,为什么分别以负样本数(N)和正样本数来作为分母(P)其实是有一定道理的,因为不论判断的对错,我们正真需要负责的人是哪些实际上是”正“或者”负“的人。
非常绕,但是结合实际来思考,为什么分别以负样本数(N)和正样本数来作为分母(P)其实是有一定道理的,因为不论判断的对错,我们正真需要负责的人是哪些实际上是”正“或者”负“的人。 -
AUC指的是ROC曲线下的面积大小,计算AUC值只需要沿着ROC横轴做积分就可以了
-
AUC 与 P-R 曲线
ROC曲线有一个特点,当正负样本的分布发生变化时,ROC曲线的形状能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。
(相对 P-R 曲线,AUC 曲线能够更好的应对数据正负样本不均衡的问题)
3. 余弦距离的应用
在机器学习问题中,通常将特征表示为向量的形式,所以在分析两个特征向量之间的相似性时,常使用余弦相似度来表示。

两个向量的余弦相似度,即两个向量夹角的余弦。
应用场景:
- 词频或词向量特征:它们在欧式空间中的欧氏距离太大
- 文本、图像和视频等领域,特征维度往往很高,欧氏距离很容易受影响(余弦相似度依然保持:“相同时为1,正交时为0,相反时为−1”的性质)
总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
4.(在线)A/B测试的陷阱
在机器学习领域中,A/B 测试是验证模型最终效果的主要手段。
- 在线 A/B 测试的必要性
- 如何进行线上A/B测试?
进行A/B测试的主要手段是进行用户分桶,即将用户分成实验组和对照组,对实验组的用户施以新模型,对对照组的用户施以旧模型。
5. (离线)模型评估的方法
在机器学习中,我们通常把样本分为训练集和测试集,训练集用于训练模型,测试集用于评估模型。在样本划分和模型验证的过程中,存在着不同的抽样方法和验证方法。
- 模型评估中,主要的验证方法
- handout:分为训练集和验证集两个部分
在验证集上计算出来的最后评估指标与原始分组有很大关系(结果带有随机性) - 交叉验证:K-fold、留一法
- 自主法
(当样本规模比较小时)对总数为 n 的数据集进行 n 次有放回的抽样,得到大小为 n 的训练集,没有被抽到过的数据作为验证集。(保证了可训练的数据集并没有减少)
根据:

可知,当样本数很大时,大约有 1/e = 36.8% 的样本从未被选择过,可作为验证集。
6. 超参数调优
超参数搜索算法一般包括的几个要素:
- 目标函数,即算法需要最大化/最小化的目标
- 搜索范围,一般通过上限和下限来确定
- 算法的其他参数,如搜索步长
- 超参数有哪些调优方法?
- 网格搜索(类似‘穷尽法’)
- 随机搜索(在搜索范围中随机选取样本点)
- 贝叶斯优化
7. 模型过拟合与欠拟合
- 在模型评估过程中,过拟合和欠拟合具体是指什么现象?
过拟合是指模型对于训练数据拟合呈过当的情况,反映到评估指标上,就是模型在训练集上的表现很好,但在测试集和新数据上的表现较差。欠拟合指的是模型在训练和预测时表现都不好的情况。 - 几种降低过拟合和欠拟合风险的方法
(1)降低过拟合- 获取更多的数据集,或者使用数据增强
- 降低模型复杂度(如,减少神经网络层数、神经元数等)
- 正则化方法
- 利用集成学习的方法
把多个模型集成在一起,来降低单一模型的过拟合风险,如Bagging方法。
(2)降低欠拟合
- 添加新特征
- 增加模型复杂度
- 减少正则化系数
3. 经典算法
问题:
-
常用loss、正则、sgd、l-bfgs、auc公式及优缺点、数据不平衡时的调参…
-
booting:gbdt的loss、分裂节点依据、防过拟合;
-
xgb的loss选择、泰勒展开、正则(gbdt能加么)、并行、vs lightGBM;
-
lambdaMart的loss–如何直接优化metric(如NDCG)–学习/train过程;
-
svm的优化目标、软间隔、调参;
-
lr;rf;
3.1 支持向量机
(1)先简单总结一下 SVM:
基本的 SVM 是一种线性模型,可以用于解决二分类问题;SVM 的一个特点:寻求间隔最大的的分类超平面;这种 SVM 叫做线性可分支持向量机,也被称为硬间隔支持向量机。
当数据近似线性可分时,可以通过软间隔最大化,训练一个线性支持向量机。
当数据线性不可分时,我们通过核技巧和软间隔最大化训练出非线性支持向量机。
(2)简单阐述 SVM 和 LR 的区别与联系
相同点:
- 都是有监督的学习方法,;
- (不考虑核函数)都是分类模型(SVM 也可作回归);
- 都是线性模型;
- 都是判别模型;
不同点:
-
损失函数不同
SVM 为合页(hinge)损失,LR 为 log 损失 -
对非线性问题的处理方式不同
LR主要靠特征构造,必须组合交叉特征,特征离散化。
SVM也可以这样,还可以通过kernel(因为只有支持向量参与核计算,计算复杂度不高)
(由于可以利用核函数,。SVM则可以通过对偶求解高效处理。LR则在特征空间维度很高时,表现较差。) -
SVM的损失函数就自带正则!SVM是结构风险最小化算法,而LR必须另外在损失函数上添加正则项!!
参考:点击 -
理论
基础理论:机器学习算法/模型——支持向量机
这篇文章讲得特别好:【ML】支持向量机(SVM)从入门到放弃再到掌握 -
面试考点:数据挖掘(机器学习)面试–SVM面试常考问题
(3)其它问题(来自《百面》):
- SVM的原理是什么?
- SVM为什么采用间隔最大化?
- 为什么要将求解SVM的原始问题转换为其对偶问题?
- 为什么SVM要引入核函数?
- 为什么SVM对缺失数据敏感?
- SVM如何处理多分类问题?
3.2 逻辑回归
逻辑回归(Logistic Regression)可以说是机器学习领域最基础也是最常用的模型,逻辑回归的原理推导以及扩展应用几乎是算法工程师的必备技能。
(1)逻辑回归相比于线性回归,有何异同?
不同点:
- 分别处理机器学习中的两块任务:分类和回归
- 线性回归的因变量是连续的,而逻辑回归的因变量是离散的
相同点: - 都使用极大似然估计对训练样本进行建模
- 在参数求解的过程中都使用梯度下降的方法(这也是监督学习的一个常见相似之处)
(2)当使用逻辑回归处理多标签的分类问题时,有哪些常见做法,分别应用于哪些场景,它们之间又有怎样的关系? - 如果一个样本只对应一个标签:直接修改目标函数(假设函数)
使用 softmax 函数(多项式逻辑回归)构造模型,其输出的值对应样本属于各个类别的概率,最后预测的类型为概率值最高的那个类别。 - 如果一个样本可能属于多个标签:“一对其余”(One VS Rest)
训练时依次将某类划为一类,将其他所有类别划分为另外一类,共需要训练 k 个二分类的逻辑回归模型(k 为类别模型数量)。训练时具有最大分类函数值的类别是未知样本的类别。
理论参考:机器学习中的线性函数
3.3 决策树
决策树
3.4 降维
降维:使用一个低维度的向量来表示原始高纬度的特征。
(1)PCA(主成分分析)
PCA 是一种线性、无监督、全局的降维算法。
- PCA 思想:向重构误差最小(方差最大)的方向做线性投影

(2)(Fisher) LDA (线性判别法)
- 如何处理具有类别标签的数据(LDA思想):最大化类间间距、最小化类内间距
3.5 非监督学习
3.5.1 K-means
机器学习算法/模型——有监督到无监督(聚类):由 KNN 到 K-menas
(1)(基本思想:通过迭代的方式,找到使得各个样本距离所属簇中心点的误差平方和最小(损失函数)的 K 个簇。
(2)优缺点
缺点:
- 无法事先合理地确定 K 值
- 效果受初始值影响
- 易受到噪点的影响
- 结果通常不是全局最优而是局部最优解
- 无法很好地解决数据簇分布差别比较大的情况(比如一类是另一类样本数量的100倍)
优点:
- 对于大数据集,K均值聚类算法相对是可伸缩和高效的,它的计算复杂度是O(NKt)接近于线性
- 尽管算法经常以局部最优结束,但一般情况下达到的局部最优已经可以满足聚类的需求。
(3)改进点
- 数据归一化和离群点处理
不进行归一化无法进行距离度量和比较。 - 合理地选择 K值:手肘法
选取不同的 K 值作为横轴,对应的损失函数作为纵轴,形成一个折线图,选择图像的拐点即是最佳 K值。 - 采用核函数
主要思想是通过一个非线性映射,将输入空间中的数据点映射到高位的特征空间中,并在新的特征空间中进行聚类。
(4)改进算法 - K-means++算法
针对初始值的选取进行改进:原始 K-menas 完全随机选择 K 个初始值,而 K-means++在选择选下一个聚类中心时,会有更高的概率选择离之前所选聚类中心点距离更远的点。 - ISODATA算法
针对无法确认 K值进行改进:
当属于某个类别的样本数过少时,把该类别去除;当属于某个类别的样本数过多、分散程度较大时,把该类别分为两个子类别。
3.5.2 高斯混合模型(GMM)
高斯混合模型假设每个簇的数据都是符合高斯分布(又叫正态分布)的,当前数据呈现的分布就是各个簇的高斯分布叠加在一起的结果
3.5.3 自组织映射神经网络(SOM)
3.5.4 聚类算法的评估
3.6 概率图模型(这块是空白)
概率图模型 = 图模型
主要包括两大类:
- 有向图:贝叶斯网络——单向依赖——因果关系
- 无向图:马尔科夫网络——互相依赖——依赖或者相关关系
这块是空白,先补几个大洞:
(1)朴素贝叶斯模型、最大熵模型
(2) 生成模型与判别模型
(3)马尔科夫模型
(4)主题模型
4.优化算法
4.1 常见损失函数
参见
4.2 优化问题
(1)什么是机器学习里的优化?
(2)机器学习中那些是凸优化问题,哪些是非凸优化问题?举例说明。
4.3 经典优化算法
无约束优化问题的约束方法有哪些?

1.直接法(公式法):梯度为 0 的方程组直接求解
条件:①目标函数L(θ)为凸函数 ② 在θ*处梯度为0 闭式有解
所以比较局限,同时满足的经典例子是岭回归,其目标函数为:

推导后可得到最优解:

2.迭代法(数值优化):近似求解
在很多实际问题中,会采用迭代法。迭代法就是迭代地修正对最优解的估计。
- 一阶迭代
- 二阶迭代(牛顿法)
这部分也可参考之前的笔记:模型框架:假设函数、目标函数和优化算法
4.4 随机梯度下降及改进
(1)当训练数据量特别大时,经典的梯度下降法存在什么问题,需要做如何改进?
回答上述问题的思路:
梯度下降
|
随机梯度下降
|
小批量梯度下降
经典的梯度下降法采用所有训练数据的平均损失来近似目标函数。因此,经典的梯度下降法在每次对模型参数进行更新时,需要遍历所有的训练数据。
为了解决该问题,随机梯度下降法(Stochastic Gradient Descent,SGD)用单个训练样本的损失来近似平均损失。
因此,随机梯度下降法用单个训练数据即可对模型参数进行一次更新,大大加快了收敛速率。该方法也非常适用于数据源源不断到来的在线更新场景。
为了降低随机梯度的方差,从而使得迭代算法更加稳定,也为了充分利用高度优化的矩阵运算操作,在实际应用中我们会同时处理若干训练数据,该方法被称为小批量梯度下降法(Mini-Batch Gradient Descent)。
对于小批量梯度下降法的使用,有以下三点需要注意的地方:
- 如何选取参数batch大小 m?
为了矩阵运算的效率一般m取值为2的幂次,比如32、64、128和256等 - 如何挑选m个训练数据?
在每次遍历数据之前,对所有的数据进行随机排序 - 如何选择学习率?
进行学习率衰减策略:一开始使用较大的学习率,当误差进入平台期后,减小学习率做更精细的调整。
(2)随机梯度下降法在优化过程中表现不好或者失效的原因?
深度学习中最常用的优化方法是随机梯度下降法,但是随机梯度下降法偶尔也会失效,无法给出满意的训练结果,这是为什么?
随机梯度下降(SGD)法失效的原因 —— 摸着石头下山
随机梯度下降(SGD):蒙上双眼下山
批量梯度下降(BGD):正常下山
深度学习的优化本身就很难,有太多局部最优点的陷进。但随机梯度下降法最怕不是局部最优点的问题,而是山谷和鞍点两类地形:
- 山谷中(两边峭壁,中间狭长小道)
在山谷中,本来应该沿着山道向下走,但稍有偏离就会在山壁间来回反弹震荡,导致收敛不稳定和收敛速度慢 - 鞍点处(一个方向两头翘,另一个方向两头垂再加上中间是块平地)
在鞍点处,本来应该继续前行,却会走入在这平坦之地(plateau)。会有三种可能:① 坡度明显,那基本可以走出下山的大致反向 ② 坡度不明显,则会走错方向 ③ 若几乎没有坡度,梯度几乎为零,则会陷入停滞。
(3)为了改进随机梯度下降法,研究者都做了哪些改动?提出了哪些变种方法?它们各有哪些特点?
解决之道——惯性保持和环境感知
随机梯度下降法的更新公式为:
参数等于上一步的参数加上一个前进步伐,即负梯度乘上一个控制步幅的学习率,即:

-
动量(Momentum)方法
动量方法的参数更新方式与普通的迭代法一样 :参数等上一步的参数加上一个前进步伐,只不过这个前进步伐由两部分组成,一是带学习率的负梯度,二是带衰减的前一次步伐。类比中学物理知识,当前梯度就好比当前时刻受力产生的加速度,前一次步伐好比前一时刻的速度,当前步伐好比当前时刻的速度
与随机梯度下降法相比,动量方法的收敛速度更快,收敛曲线也更稳定。
-
AdaGrad方法
具有环境感知能力,能够自适应地确定参数的学习率。梯度下降法依赖于人工设定的学习率,如果设置过小,收敛太慢,而如果设置太大,可能导致算法那不收敛,为这个学习率设置一个合适的值非常困难。
在应用中,我们希望更新频率低的参数可以拥有较大的更新步幅,而更新频率高的参数的步幅可以减小。AdaGrad方法采用“历史梯度平方和”来衡量不同参数的梯度的稀疏性(取值越小表明越稀疏),从而动态地动态调整学习率。
-
Adam方法
Adam方法将惯性保持和环境感知这两个优点集于一身(整合了自适应学习率与动量项)。
一方面,Adam记录梯度的一阶矩(first moment),即过往梯度与当前梯度的平均,这体现了惯性保持;另一方面,Adam还记录梯度的二阶矩(second moment),即过往梯度平方与当前梯度平方的平均,这类似AdaGrad方法,体现了环境感知能力,为不同参数产生自适应的学习速率。


其中β1,β2为衰减系数,mt是一阶矩,vt是二阶矩。
…
4.5 L1正则化与稀疏性
(1)首先,要弄搞明白为什么需要模型参数具有稀疏性。
稀疏性,说白了就是模型的很多参数是0。这相当于对模型进行了一次特征选择,只留下一些比较重要的特征,提高模型的泛化能力,降低过拟合的可能。
(2)L1正则化使得模型参数具有稀疏性的原理是什么?
参考《百面》有三个角度可以解释:
- 解空间形状
- 函数叠加
- 贝叶斯先验
5. 采样
这一块和图模型一样,基本也是个空白,先看最常见的问题吧。(其实,关于采样,在特种工程的补充部分也有提到过。)
5.1 采样的作用
举例说明采样在机器学习中的应用。
采样本质上是对随机现象的模拟,根据给定的概率分布,来模拟产生一个对应的随机事件。采样可以让人们对随机事件及其产生过程有更直观的认识。
例如,通过对二项分布的采样,可以模拟“抛硬币出现正面还是反面”这个随机事件,进而模拟产生一个多次抛硬币出现的结果序列,或者计算多次抛硬币后出现正面的频率
另一方面,采样得到的样本集也可以看作是一种非参数模型,即用较少量的样本点(经验分布)来近似总体分布,并刻画总体分布中的不确定性。从这个角度来说,采样其实也是一种信息降维,可以起到简化问题的作用。
例如,在训练机器学习模型时,一般想要优化的是模型在总体分布上的期望损失(期望风险),但总体分布可能包含无穷多个样本点,要在训练时全部用上几乎是不可能的,采集和存储样本的代价也非常大。因此,一般采用总体分布的一个样本集来作为总体分布的近似,称之为训练集,训练模型的时候是最小化模型在训练集上损失函数(经验风险)。同理,在评估模型时,也是看模型在另外一个样本集(测试集)上的效果。这种信息降维的特性,使得采样在数据可视化方面也有很多应用,它可以帮助人们快速、直观地了解总体分布中数据的结构和特性。
对当前的数据集进行重采样,可以充分利用已有数据集,挖掘更多信息,
如自助法和刀切法(Jack knife),通过对样本多次重采样来估计统计量的偏差、方差等。
另外,利用重采样技术,可以在保持特定的信息下(目标信息不丢失),有意识地改变样本的分布,以更适应后续的模型训练和学习,
例如利用重采样来处理分类模型的训练样本不均衡问题。
此外,很多模型由于结构复杂、含有隐变量等原因,导致对应的求解公式比较复杂,没有显式解析解,难以进行精确求解或推理。在这种情况下,可以利用采样方法进行随机模拟,从而对这些复杂模型进行近似求解或推理。这一般会转化为某些函数在特定分布下的积分或期望,或者是求某些随机变量或参数在给定数据下的后验分布等。
例如,在隐狄利克雷模型和深度玻尔兹曼机(Deep Boltzmann Machines,DBM)的求解过程中,由于含有隐变量,直接计算比较困难,此时可以用吉布斯采样对隐变量的分布进行采样。如果对于贝叶斯模型,还可以将隐变量和参数变量放在一起,对它们的联合分布进行采样。注意,不同于一些确定性的近似求解方法(如变分贝叶斯方法、期望传播等),基于采样的随机模拟方法是数值型的近似求解方法。
5.2 常见的采样方法
…
5.7 样本不均衡问题
对于二分类问题,当训练集中正负样本非常不均衡时,如何处理数据以更好地训练分类模型?
两个角度来解决:
-
基于数据的方法
对数据进行重采样,使原本不均衡的样本变得均衡:
1.直接随机采样:对少数类的样本进行随机过采样,对多数类的样本进行随机欠采样。最简单的处理不均衡样本集的方法是随机采样。采样一般分为过采样(Over-sampling)和欠采样(Under-sampling)。
随机过采样是从少数类样本集Smin中随机重复抽取样本(有放回)以得到更多样本;随机欠采样则相反,从多数类样本集Smaj中随机选取较少的样本(有放回或无放回)。
随机采样的问题:
直接的随机采样虽然可以使样本集变得均衡,但会带来一些问题,比如,过采样对少数类样本进行了多次复制,扩大了数据规模,增加了模型训练的复杂度,同时也容易造成过拟合;欠采样会丢弃一些样本,可能会损失部分有用信息,造成模型只学到了整体模式的一部分。2.1 过采样时采取措施生成新的样本,如SMOTE算法
SMOTE算法对少数类样本集Smin中每个样本x,从它在Smin中的K近邻中随机选一个样本y,然后在x,y连线上随机选取一点作为新合成的样本(根据需要的过采样倍率重复上述过程若干次)
2.2 对于欠采样,可以采用Informed Undersampling来解决由于随机欠采样带来的数据丢失问题
-
基于算法的方法
在样本不均衡时,也可以通过改变模型训练时的目标函数(如代价敏感学习中不同类别有不同的权重)来矫正这种不平衡性;
当样本数目极其不均衡时,也可以将问题转化为单类学习(one-class learning)、异常检测(anomaly detection)
深度学习
6. 前向神经网络
6.1 多层感知机与布尔函数
(1)多层感知机表示异或逻辑时最少需要几个隐含层(仅考虑二元输入)?
包含一个隐含层的多层感知机就可以确切地计算异或函数。

通用近似定理告诉我们,一个前馈神经网络如果具有线性输出层和至少一层具有任何一种“挤压”性质的激活函数的隐藏层,当给予网络足够数量的隐藏单元时,可以以任意精度近似任何从一个有限维空间到另一个有限维空间的波莱尔可测函数。
可以简单认为我们常用的激活函数和目标函数是通用近似定理适用的一个子集,因此多层感知机的表达能力是非常强的,关键在于我们是否能够学习到对应此表达的模型参数。
(2)如果只使用一个隐层,需要多少隐节点能够实现包含n元输入的任意布尔函数?
(3)…
6.2 神经网络的激活函数
(1)写出常用激活函数及其导数。
-
sigmiod

如何记忆?
目的:想将函数值控制在 0 和 1 之间——>取倒数并让分子为1 ;想让函数取到(0, 0.5)且单调递增——>分母取1 + e-x

因此,在函数值取到 0 和 1 的时候,倒数接近0(出现梯度消失) -
tanh

如何记忆?
目的:想将函数值固限制在(-1, 1)之间,即x趋近正无穷时y取1,x趋近负无穷时,y取-1;想爱让函数经过原点(0, 0)——>恰好简单的指数函数有这种极端的性质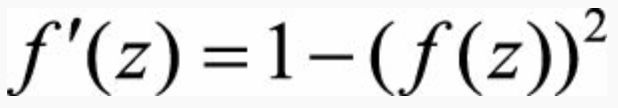
通过求导后的式子得出,在tanh函数取值为1的时候,导数为0,即和Sigmoid函数一样,存在梯度消失的问题。 -
ReLU


(2)为什么Sigmoid和Tanh激活函数会导致梯度消失的现象?
-
Sigmoid激活函数将输入z映射到区间(0,1),当z很大时,f(z)趋近于1;当z很小时,f(z)趋近于0。其导数在z很大或很小时都会趋近于0,造成梯度消失的现象。
-
对于Tanh激活函数,当z很大时,f(z)趋近于1;当z很小时,f(z)趋近于−1。其导数在z很大或很小时都会趋近于0,同样会出现“梯度消失”。
实际上,Tanh激活函数相当于Sigmoid的平移:tanh(x)=2sigmoid(2x)−1 .
(3)ReLU系列的激活函数相对于Sigmoid和Tanh激活函数的优点是什么?它们有什么局限性以及如何改进?
- ReLU 激活函数的优点:
- 从计算的角度,Sigmoid和Tanh 均需要计算指数,复杂度高,而ReLu只需要一个阈值即可得到激活函数
- ReLU的非饱和性可以有效地解决梯度消失的问题,提供相对宽的激活边界。
在 > 0 时导数为 1(不会变为0),在一定程度上缓解了神经网络的梯度消失问题。 - ReLU的单侧抑制提供了网络的稀疏表达能力。
负梯度在经过该ReLU单元时被置为0
-
ReLU 激活函数的局限性
ReLU的局限性在于其训练过程中会导致神经元死亡的问题。这是由于函数导致负梯度在经过该ReLU单元时被置为0,且在之后也不被任何数据激活,即流经该神经元的梯度永远为0,不对任何数据产生响应。
在实际训练中,如果学习率(Learning Rate)设置较大,会导致超过一定比例的神经元不可逆死亡,进而参数梯度无法更新,整个训练过程失败。 -
变种和改进
Leaky ReLU(LReLU),其形式表示为:

 …
…
6.3 多层感知机的反向传播算法(这块是薄弱)
(1)写出多层感知机的平方误差和交叉熵损失函数。
(2)根据问题1中定义的损失函数,推导各层参数更新的梯度计算公式。
(3)平方误差损失函数和交叉熵损失函数分别适合什么场景?
一般来说,平方损失函数更适合输出为连续,并且最后一层不含Sigmoid或Softmax激活函数的神经网络;交叉熵损失则更适合二分类或多分类的场景。
6.4 神经网络训练技巧
在大规模神经网络的训练过程中,我们常常会面临“过拟合”的问题,即当参数数目过于庞大而相应的训练数据短缺时,模型在训练集上损失值很小,但在测试集上损失较大,泛化能力很差。解决“过拟合”的方法有很多,包括数据集增强(Data Augmentation)、参数范数惩罚/正则化(Regularization)、模型集成(Model Ensemble)等;其中Dropout是模型集成方法中最高效与常用的技巧。同时,深度神经网络的训练中涉及诸多手调参数,如学习率、权重衰减系数、Dropout比例等,这些参数的选择会显著影响模型最终的训练效果。批量归一化(Batch Normalization,BN)方法有效规避了这些复杂参数对网络训练产生的影响,在加速训练收敛的同时也提升了网络的泛化能力。
(1)神经网络训练时是否可以将全部参数初始化为0?
问题:突然发现并不知道神经网络初始化的意义?
原来初始化参数对神经网络来说极端重要,甚至有人专门研究不依赖训练而只靠初始参数的模型:点击1、点击2
考虑全连接的深度神经网络,同一层中的任意神经元都是同构的,它们拥有相同的输入和输出,如果再将参数全部初始化为同样的值,那么无论前向传播还是反向传播的取值都是完全相同的。学习过程将永远无法打破这种对称性,最终同一网络层中的各个参数仍然是相同的。
因此,我们需要随机地初始化神经网络参数的值,以打破这种对称性。简单来说,我们可以初始化参数为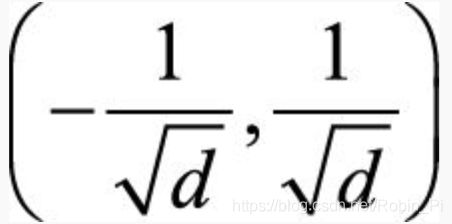 取值范围的均匀分布,其中d是一个神经元接受的输入维度。偏置可以被简单地设为0,并不会导致参数对称的问题。
取值范围的均匀分布,其中d是一个神经元接受的输入维度。偏置可以被简单地设为0,并不会导致参数对称的问题。
(2)为什么Dropout可以抑制过拟合?它的工作原理和实现?
Dropout是指在深度网络的训练中,以一定的概率随机地 “临时丢弃”一部分神经元节点
dropout 作用:
- 类似集成算法:对于包含N个神经元节点的网络,在Dropout的作用下可看作为2N个模型的集成
- 对于任意神经元,每次训练中都与一组随机挑选的不同的神经元集合共同进行优化,这个过程会减弱全体神经元之间的联合适应性,减少过拟合的风险,增强泛化能力。
dropout 如何训练:
(3)批量归一化的基本动机与原理是什么?在卷积神经网络中如何使用?
神经网络训练过程的本质是学习数据分布,如果训练数据与测试数据的分布不同将大大降低网络的泛化能力,因此我们需要在训练开始前对所有输入数据进行归一化处理。
然而随着网络训练的进行,每个隐层的参数变化使得后一层的输入发生变化,从而每一批训练数据的分布也随之改变,致使网络在每次迭代中都需要拟合不同的数据分布,增大训练的复杂度以及过拟合的风险。
批量归一化在卷积神经网络中应用时,需要注意卷积神经网络的参数共享机制。每一个卷积核的参数在不同位置的神经元当中是共享的,因此也应该被一起归一化。
6.5 深度卷积网络
可以参考之前的文章:卷积基础和常用卷积模型
(1)卷积操作的本质特性包括稀疏交互和参数共享,具体解释这两种特性及其作用。
-
稀疏交互(局部感受野):每一个神经元仅与前一层特定区域内的神经元存在权重连接
其意义是大大减少了参数量 -
参数共享:同层的神经元共用相同的卷积核(权值参数)
其意义是使得卷积层具有平移等变性
(2)常用的池化操作有哪些?池化的作用是什么? -
最大池化:取滑动窗口内的最大值
-
平均池化:取滑动窗口内的均值
池化的作用
- 显著降低参数量
- 保持对平移、伸缩、旋转操作的不变性
(3)卷积神经网络如何用于文本分类任务?
这块倒没研究过!
6.6 深度残差网络
(1)ResNet的提出背景和核心理论是什么?
ResNet的提出背景是解决或缓解深层的神经网络训练中的梯度消失问题。
反向传播时,梯度将涉及两层参数的交叉相乘,可能会在离输入近的网络层中产生梯度消失的现象。ResNet把网络结构调整为,既然离输入近的神经网络层较难训练,那么我们可以将它短接到更靠近输出的层。

对于一般的两层卷积网络, 输入 x 会经历两轮加权求和激活输出的过程,但是在得到输出 F(x) 之前,残差块还引入了一个从输入 x 直接到达网络第二层激活输出的一个额外过程, 如图所示, 这就实现了网络的跳层连接。其结果是在进行最后的激活之前, 得到了输出 F(x) + x, 而不是卷积网络的输出 F(x)。
循环神经网络
强化学习
集成学习
机器学习之集成学习
NLP
CV
Coding
数学
参考
其它总结博客
- 机器学习常见算法个人总结(面试用)
知识点参考
- 数据预处理之数据无量纲化(标准化/归一化)
- 机器学习中常见的几种归一化方法以及原因
- LabelEncoder(标签编码)与One—Hot(独热编码)
- 特征工程之特征表达
- 特征的标准化和归一化
- 特征工程之特征选择
- 特征工程之特征预处理
- 机器学习之类别不平衡问题 (3) —— 采样方法
- 机器学习中的特征——特征选择的方法以及注意点
- An Introduction to Feature Selection
- 集成学习之Boosting —— Gradient Boosting原理
总结
特征工程

数据预处理(特征工程的核心)
