Pandas数据分析
大数据作业要用到Pandas,参照这个教程,做个记录。
1.Pandas读取数据

2.Pandas数据结构DataFrame和Series
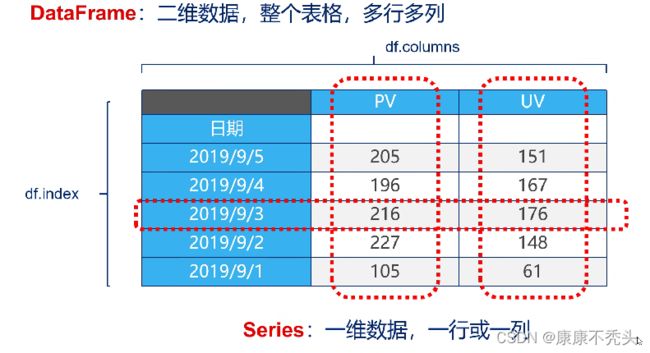
Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引组成)
2.1仅有数据列表即可产生最简单的Series
s1 = pd.Series[1,'a',5.2,7]索引默认从0开始
2.2创建一个具有标签索引的Series
s2 = pd.Series[1,'a',5.2,7],index=['d','b','a','c']2.3根据标签索引查询数据
s2['a']
s2['b','a']2.4使用Python字典创建Series
sdata = {'O':527,'T':786,'A':342,'U':590}2.5根据多个字典序列创建dataframe
data={
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
df = pd.DataFrame(data)2.5查询列、查询行
df['year']
df.loc[1]3.Pandas数据查询
3.1使用数值区间进行查询

# 行index按区间
df.loc['2018-01-03':'2018-01-05', 'bWendu']注意:区间既包含开始,也包含结束
3.2使用条件表达式或函数进行查询
df.loc[df["yWendu"]<-10, :]
## 查询最高温度小于30度,并且最低温度大于15度,并且是晴天,并且天气为优的数据
df.loc[(df["bWendu"]<=30) & (df["yWendu"]>=15) & (df["tianqi"]=='晴') & (df["aqiLevel"]==1), :]
# 直接写lambda表达式,返回行Series
df.loc[lambda df : (df["bWendu"]<=30) & (df["yWendu"]>=15), :]
# 编写自己的函数,查询9月份,空气质量好的数据
def query_my_data(df):
return df.index.str.startswith("2018-09") & (df["aqiLevel"]==1)
df.loc[query_my_data, :]4.Pandas新增数据列
4.1直接赋值的方法
实例:清除温度列,变成数字类型
# 替换掉温度的后缀℃
df.loc[:, "bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')
df.loc[:, "yWendu"] = df["yWendu"].str.replace("℃", "").astype('int32')实例:计算温差
# 注意,df["bWendu"]其实是一个Series,后面的减法返回的是Series
df.loc[:, "wencha"] = df["bWendu"] - df["yWendu"]4.2 df.apply方法
将一个Series转换成行或列(根据axis判断)
实例:添加一列温度类型:
1. 如果最高温度大于33度就是高温
2. 低于-10度是低温
3. 否则是常温
def get_wendu_type(x):
if x["bWendu"] > 33:
return '高温'
if x["yWendu"] < -10:
return '低温'
return '常温'
# 注意需要设置axis==1,这是series的index是columns
df.loc[:, "wendu_type"] = df.apply(get_wendu_type, axis=1)
# 查看温度类型的计数
df["wendu_type"].value_counts()
4.3 df.assign方法
将新的列添加到DataFrame中
实例:将温度从摄氏度变成华氏度
# 可以同时添加多个新的列
df.assign(
yWendu_huashi = lambda x : x["yWendu"] * 9 / 5 + 32,
# 摄氏度转华氏度
bWendu_huashi = lambda x : x["bWendu"] * 9 / 5 + 32
)4.4 按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:高低温差大于10度,则认为温差大
# 先创建空列(这是第一种创建新列的方法)
df['wencha_type'] = ''
df.loc[df["bWendu"]-df["yWendu"]>10, "wencha_type"] = "温差大"
df.loc[df["bWendu"]-df["yWendu"]<=10, "wencha_type"] = "温差正常"5.Pandas的数据统计函数
5.1汇总类统计
# 一下子提取所有数字列统计结果(总数、最大值、最小值、平均值、方差、分位数)
df.describe()5.2唯一去重和按值计数
枚举、分类列的所有取值以及各个取值出现的次数
df["fengxiang"].unique()
df["fengxiang"].value_counts()5.3相关系数和协方差
来自知乎,对于两个变量X、Y:
1. 协方差:***衡量同向反向程度***,如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高。
2. 相关系数:***衡量相似度程度***,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大
# 协方差矩阵:
df.cov()
# 相关系数矩阵
df.corr()
# 单独查看空气质量和最高温度的相关系数
df["aqi"].corr(df["bWendu"])