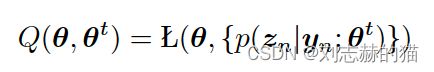机器学习中的优化问题
参考书:MLAPP
机器学习中,从监督学习到非监督学习、从线性回归到聚类降维,最终都转化成求解一个优化问题。本文从数学角度记录机器学习中的优化问题,内容包括优化问题类型、求解算法、应用,这其实对应着:
- 定义问题—>模型
- 解决问题—>算法
- 应用
内容概要
- 1.目标函数的类型
- 2.求解算法
-
- 2.1 一阶方法
-
- 梯度下降
- 2.2 二阶方法
-
- 牛顿法
- 拟牛顿法(BFGS)
- 信任域方法
- 2.3 随机方法
-
- 随机梯度下降
- preconditioned SGD
- 2.4 求解有约束优化
- 2.5 bound optimization
- 2.6 blackbox和derivative-free
- 2.7 贝叶斯优化
1.目标函数的类型
机器学习常用最小化损失函数的思想求解参数,其优化问题对应:
min θ ∈ Θ L ( θ ) \min_{\theta\in\Theta}L(\theta) θ∈ΘminL(θ)
不同的 L L L和变量空间 Θ \Theta Θ确定了不同的优化模型,而模型的特征和性质决定了解的存在性、判断最优解和求解的方法。
- 无约束优化VS有约束优化
假设 Θ \Theta Θ是整个 R D \mathbb{R}^D RD,那么相当于可以在整个D维空间上搜索解,无需考虑范围限制,这时对应的是无约束优化。
假设 Θ ⊂ R D \Theta\subset\mathbb{R}^D Θ⊂RD,那么需要考虑目标变量的搜索范围,这时对应的是约束优化。

上图可知,有无约束对于解的存在性和求解方法非常重要。
-
凸优化VS非凸优化
假设目标函数 L L L是凸函数,并且参数空间 Θ \Theta Θ是凸集,那么模型就是凸优化模型,否则即为非凸模型。
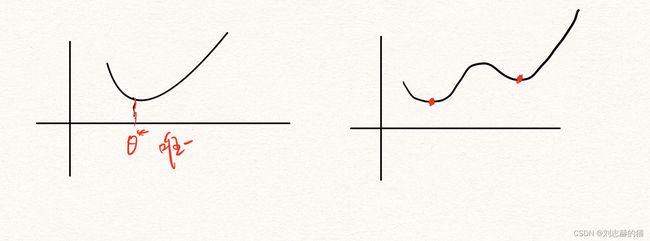
凸优化是一类性质非常好的模型,理论十分完善。由于凸优化的局部最优就是全局最优,所以求解凸优化时只需要找到局部最优解即可。
而非凸优化不仅不能保证局部解就是全局解,还存在一类非常特殊的鞍点,使得梯度下降陷入局部解无法继续下降。 -
光滑优化VS非光滑优化
假设目标函数 L L L满足一定的光滑条件,比如拉普拉斯光滑条件 ∣ L ( x ) − L ( y ) ∣ ≤ a ∣ x − y ∣ |L(x)-L(y)|\leq a|x-y| ∣L(x)−L(y)∣≤a∣x−y∣就称为一阶光滑。
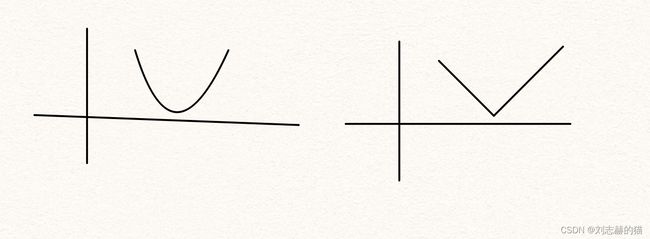
优化问题常用梯度下降,对于非光滑的目标函数,无法求得梯度,因此需要用到别的方法求解,比如下一节提到的次梯度下降等。
2.求解算法
2.1 一阶方法
一阶方法是指在求解过程中用到了目标函数的一阶梯度(次梯度)信息。
梯度下降
迭代格式:
θ t + 1 = θ t + η t d t \theta_{t+1}=\theta_t+\eta_td_t θt+1=θt+ηtdt
- 下降方向:使得目标函数减少的 d t d_t dt,即 L ( θ t + 1 ) < L ( θ t ) L(\theta_{t+1})
- 步长:每次走的步长 η t \eta_t ηt,步长的选取十分关键,选的太小导致迭代次数过多收敛太慢,选的太大容易错过最优点,它的选择叫learning rate schedule,内容可以单独写出一章,常用的选择方法:
- 常数
- 线性搜索
- 收敛性:衡量算法是否适用就是看它是否收敛以及收敛速度是多少,梯度下降一般能到线性收敛
- 加速方法:
- momentum
指数平均的思想,将之前的信息汇总,都反映到这次的下降方向中,越靠前的信息影响越小
m t = β m t − 1 + g t − 1 θ t = θ t − 1 − η t m t m_t=\beta m_{t-1}+g_{t-1}\\ \theta_t=\theta_{t-1}-\eta_tm_t mt=βmt−1+gt−1θt=θt−1−ηtmt - nesterov momentum
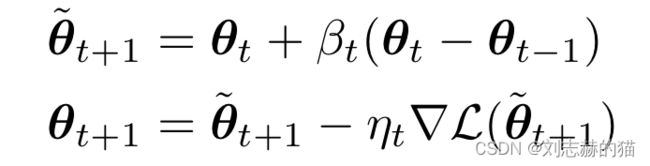
- momentum
2.2 二阶方法
二阶方法指用到了目标函数的二阶导数信息。
牛顿法
迭代格式:
θ t + 1 = θ t − η t H t − 1 g t \theta_{t+1}=\theta_t-\eta_tH_t^{-1}g_t θt+1=θt−ηtHt−1gt
其中 H t H_t Ht是二阶hessian矩阵
拟牛顿法(BFGS)
实践中,求解二阶hessian矩阵十分耗时,一般会对二阶hessian矩阵进行近似,按照不同的规则,有不同的近似方法,常用的是BFGS:
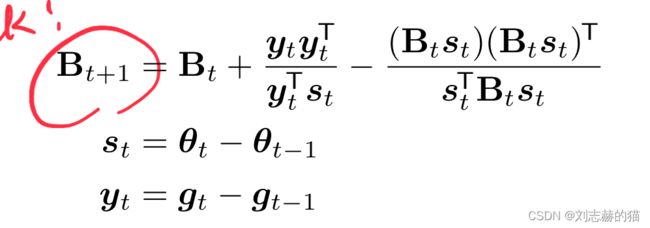
信任域方法
2.3 随机方法
之前的目标函数都是确定性的,无随机变量,但在实际机器学习中目标函数中会有随机变量:
L ( θ ) = E q ( z ) [ L ( θ , z ) ] L(\theta)=\mathbb E _{q(z)}[L(\theta,z)] L(θ)=Eq(z)[L(θ,z)]
随机梯度下降
每步迭代格式:
θ t + 1 = θ t − η t g t \theta_{t+1}=\theta_t-\eta_tg_t θt+1=θt−ηtgt
其中 g t = ∇ θ L ( θ t , z t ) , z t ∼ q ( z ) g_t=\nabla_{\theta} L(\theta_t,z_t),z_t\sim q(z) gt=∇θL(θt,zt),zt∼q(z)
例如在样本数N,损失函数 l ( y , f ( x ) ) l(y,f(x)) l(y,f(x))的损失最小化优化模型中:
L ( θ t ) = 1 N ∑ n = 1 N l ( y n , f ( x ( i ) , θ t ) ) L(\theta_t)=\frac{1}{N}\sum_{n=1}^N l(y_n,f(x^{(i)},\theta_t)) L(θt)=N1n=1∑Nl(yn,f(x(i),θt))
- 方向 g t g_t gt
如果每次用到N个样本去更新参数,就是批量梯度下降
如果每次只用一个样本更新参数,就是SGD - 步长
为保证收敛,一般要求Robbins-Monro conditions

还有其他的learning rate schedule
preconditioned SGD
迭代格式:
θ t + 1 = θ t − η t M t − 1 g t \theta_{t+1}=\theta_t-\eta_tM_t^{-1}g_t θt+1=θt−ηtMt−1gt
其中 M t − 1 M_t^{-1} Mt−1就是preconditioned矩阵,它不一定涉及二阶导数信息
- AdaGrad ( M t = d i a g ( s t + ϵ ) 1 / 2 M_t=diag(s_t+\epsilon)^{1/2} Mt=diag(st+ϵ)1/2)
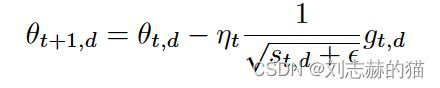
其中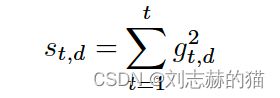
由此可算出每步迭代的变化量:

- RMSProp \ AdaDelta
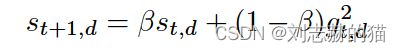
每步更新量:

更简单的Adadelta
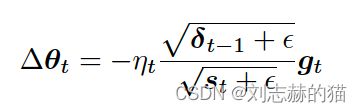
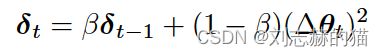
- Adam
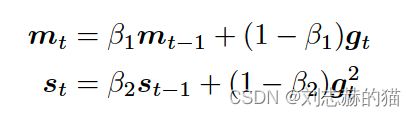
每步更新量:

- M t M_t Mt非对角
2.4 求解有约束优化
- 拉格朗日乘子法
- proximal gradient descent
思想:将约束通过惩罚函数写成成目标函数
对于非光滑的目标函数,如果能把目标函数写成复合函数:
L ( θ ) = L s ( θ ) + L r ( θ ) L(\theta)=L_s(\theta)+L_r(\theta) L(θ)=Ls(θ)+Lr(θ)
其中 L s L_s Ls光滑, L r L_r Lr非光滑,则可用PGD算法更新参数:
 )
)
其中
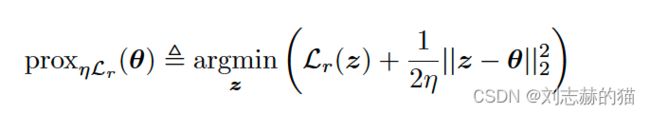
2.5 bound optimization
有时候求解原目标函数比较困难,退一步求解一个它的下界,这个下界要满足几个条件:
- 它的最优解好求
- 它和原目标函数相差不大,最好能衡量两者的差距
这样的函数称为surrogate function,满足
Q ( θ , θ t ) ≤ L ( θ ) , Q ( θ t , θ t ) = L ( θ t ) Q(\theta,\theta_t)\leq L(\theta),Q(\theta_t,\theta_t)=L(\theta_t) Q(θ,θt)≤L(θ),Q(θt,θt)=L(θt)
每步转而求解
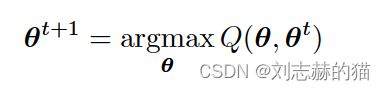
- EM
目标函数:

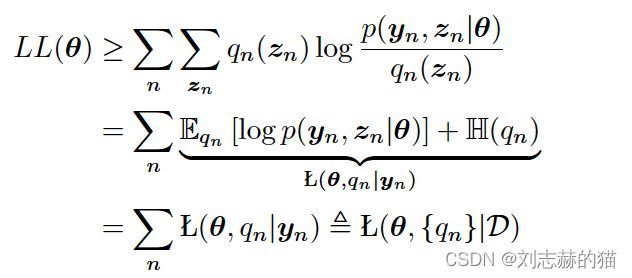
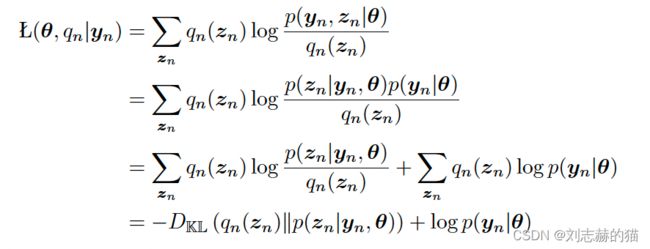
定义: