SwapNet 和 VITON-GAN
目录
-
-
- SwapNet: Garment transfer in single view images(ECCV 2018)又名 SwapNet: Image Based Garment Transfer
- VITON-GAN: Virtual Try-on Image Generator Trained with Adversarial Loss(Eurographics 2019)
- 总结
-
SwapNet: Garment transfer in single view images(ECCV 2018)又名 SwapNet: Image Based Garment Transfer
SwapNet: 基于单视图图像的换装(ECCV 2018)
(Github项目地址)
作者提出了Swapnet,一个框架,可在具有任意身体姿势,形状和衣服的人的图像之间转移服装。服装转移是一项具有挑战性的任务,需要(i)使服装的特征与身体的姿势和形状脱钩,以及(ii)在新的身体上逼真的服装质地合成。作者提出了一种神经网络架构,可通过两个特定于任务的子网来解决这些子问题。由于获取在不同身体上显示相同服装的图像对很困难,因此作者提出了一种新颖的弱监督方法,该方法通过数据增强从单个图像生成训练对。作者提出了在不受约束的图像中进行服装转移的第一种全自动方法,而无需解决困难的3D重建问题。
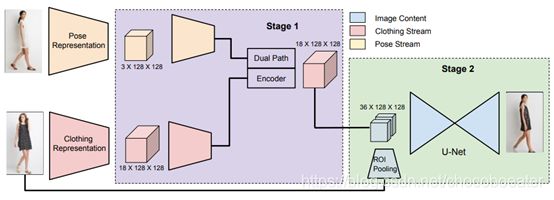
图1. 流水线由两个阶段组成:(1)变形阶段,它生成与所需姿势一致的服装分割;(2)纹理阶段,它使用所需服装图像中的服装信息合成与前一阶段服装分割一致的详细服装纹理。
给定一个包含穿着期望服装的人的图像A和一个以目标体型和姿势描绘另一个人的图像B,生成一个由与A中穿着期望服装的人相同的人组成的图像B′。A和B可以描绘穿着任意服装的不同体型和姿势的人。
条件生成模型使用编码器-解码器类型的网络架构,以转换输入图像以直接生成输出像素变得越来越流行。最近的工作,如pix2pix在图像翻译任务中显示了高质量的结果,其中输出的结构和形状与输入的偏差不大。然而,本文的服装转移任务提出了独特的挑战。成功的转换需要对输入图像进行显著的结构更改。如前面的工作(做你自己的普拉达:结构连贯的时尚合成)所示,将所需衣服的形状和纹理细节直接转移到目标身体上会给网络带来太多的负担,从而导致转换的质量不佳。(分开处理形状与纹理的必要性同样在FiNet论文中提及,生成同时进行,通常会因为二者的耦合而无法处理好衣服的形状和边界)
作者提出了一个两级流水线(图1)来分别处理形状和纹理合成。具体地说,作者认为服装和身体分割提供了一个所需服装和目标身体的简洁和必要的表示。因此,作者首先对这些分割进行操作以执行所需的形状变化,即在目标身体形状和姿势为B但衣服在A中的情况下生成衣服分割。假设图像A的衣服分割和图像B的身体分割是给定的或由先前的工作计算的(通过人类解析器)。在第二阶段,作者提出了一个纹理化网络,该网络以合成的服装分割和所需服装的图像作为输入,生成最终的传输结果。

图2. 阶段1模块的架构。变形模块由一个双路径U-net组成,该U-net对人体分割有较强的依赖,对服装分割有较弱的依赖。
变形模块
流水线的第一个阶段变形模块,根据A的服装分割 A cs A_{\text{cs}} Acs和B身体分割 B b s B_{bs} Bbs进行生成,得到B的服装分割 B ′ cs {B'}_{\text{cs}} B′cs,该分割与A的服装分割形状和标签具有一致性,同时严格遵循图2中B的身体形状和姿势。作者把这个问题看作是一个条件生成过程,在这个过程中,衣服应该受到 A cs A_{\text{cs}} Acs的制约,而身体则受到 B bs B_{\text{bs}} Bbs的制约。
作者使用双路径U-net网络来解决双调节问题。双路径网络由两个编码器流组成,一个用于身体,一个用于衣服,还有一个解码器,该解码器将两个编码的隐藏表示组合起来生成最终输出。用一个18通道分割mask来代表服装,不包括皮带或眼镜等小配件。给出这个18通道分割图,其中每个通道包含一个服装类别的概率图,服装编码器生成512×16×16大小的特征图(512大小的16×16特征)。给定一个彩色编码的3通道身体分割,身体编码器同样生成一个512×16×16大小的特征映射来表示目标身体。这些编码的特征映射被连接起来并通过4个residual blocks传递。然后对得到的特征映射进行上采样,以生成所需的18通道服装分割。

图3. 第一阶段分割可视化。(a) A的服装分割;(b)B的人体分割;(c)通过变形模块生成B的服装分割;(d)B的原始服装分割。
生成的图像强烈地依赖于人体分割,而微弱地依赖于服装分割。这是通过将服装分割编码为2×2×1024的窄表示,然后将其上采样到所需大小的特征映射来实现的。这种紧凑的表示鼓励网络从服装流中提取高层次信息,例如服装项目的类型(顶部、底部、鞋子、皮肤等)和每个项目的一般形状,同时限制生成的分割以紧密跟随嵌入在身体分割中的目标姿势和体形。
为了监督训练,理想情况下我们需要像姿势指导图像生成中的Ground Truth三元组( A cs A_{\text{cs}} Acs+ B bs B_{\text{bs}} Bbs~ B ′ cs {B'}_{\text{cs}} B′cs)。然而,这样一个数据集很难获得,而且对于服装的更大变化通常是不可扩展的。相反,作者使用自监督方法生成所需的三元组。具体地说,在给定一幅图像B的情况下,考虑了可以直接监督的三元组( B cs B_{\text{cs}} Bcs+ B bs B_{\text{bs}} Bbs~ B ′ cs {B'}_{\text{cs}} B′cs)。但是,使用此设置时,由于 B cs B_{\text{cs}} Bcs= B ′ cs {B'}_{\text{cs}} B′cs,网络学习标识映射有危险。为了避免这种情况,作者使用 B cs B_{\text{cs}} Bcs的增强。执行随机仿射变换(包括随机裁剪和翻转)。这鼓励该网络丢弃 B cs B_{\text{cs}} Bcs的位置提示,只提取与服装部分的类型和结构相关的高级提示。(这里的数据集只包含无关联的试穿图像,输入中直接包含了Ground Truth,所以直接学习会有危险。对于CP-VTON中用到的产品图像-试穿图像的图像对,或者是M2C-TON训练用的同一件衣服和模特的不同姿势试穿,这一部分的数据处理应该就不必要了?或者也会对结果产生积极的影响?)
作者选择将服装分割表示为18通道概率图,而不是3通道彩色编码分割图像,以允许模型更灵活地分别对每个单独片段进行扭曲(对于单样服装转换的工程就不需要分别扭曲了)。在训练过程中,分割图像的每个通道都会经历不同的仿射变换,因此网络应该学习每个通道与相应身体段之间更高层次的关系推理。相比之下,作者使用3通道彩色编码图像表示身体分割,类似于着装中人的生成模型中观察到的,身体分割的更细粒度编码并不能提供更多的信息。彩色编码的身体分割图像还提供了关于每个服装段应该在哪里对齐的指导,这总体上提供了关于身体形状和姿势的更强提示。此外,由于衣服片段跨越多个身体片段,因此保持整个身体图像的结构比将身体片段分割为单个通道更为有利。
变形模块是由交叉熵损失和GAN损失结合起来训练的。具体地说,变形模块 z cs = f 1 ( A cs , B bs ) z_{\text{cs}} = f1(A_{\text{cs}},B_{\text{bs}}) zcs=f1(Acs,Bbs)具有以下学习目标:

其中, λ adv L adv \lambda_{\text{adv}}L_{\text{adv}} λadvLadv表示损耗的对抗性分量, f 1 enc f1_{\text{enc}} f1enc和 f 1 dec f1_{\text{dec}} f1dec是变形模块的编码器和解码器分量。调整每个分量的权重,使得每个损失的梯度贡献约为相同数量级。在实验中,作者观察到添加一个小的对抗权重有助于产生更好的收敛性和生成的分割形状保持。

图4. 第2阶段模块的体系结构。纹理模块以自我监督的方式进行训练。通过服装分割获得输入到编码器的形状信息,利用ROI池获得纹理信息。
纹理模块
第二阶段网络纹理模块,是一个U-Net架构,它训练生成纹理细节。给出了在所需的身体形状和姿势, B cs ′ B_{\text{cs}}^{'} Bcs′下的衣服分割,以及在图像a中所示的所需衣服的嵌入。作者通过在6个身体部位(主体,左臂,右臂,左臂)中的每一个部位ROI Pooling来获得该嵌入并生成3×16×16的特征图,然后将其上采样到原始图像大小。将这些特征图与 B cs ′ B_{\text{cs}}^{'} Bcs′叠加,然后将它们输入U-Net。其思想是利用服装分割来控制高层的结构和形状,利用服装的嵌入来引导底层色彩和细节的幻觉(hallucination)。
与第一阶段类似,作者以弱监督的方式训练纹理模块。具体地说,给定一个输入图像B,将输入视为( B cs B_{\text{cs}} Bcs+将衣服嵌入B中~B)。为了避免学习身份映射(identity mapping),作者通过执行随机翻转和裁剪,从B的扩充计算期望衣服的嵌入。作者使用L1重建损失、特征损失(VGG-19)和带有DRAGAN梯度惩罚的GAN损失(来自GAN的收敛性和稳定性(解读))来提高结果的清晰度并稳定GAN的训练。第二级纹理模块f2的学习目标如下:
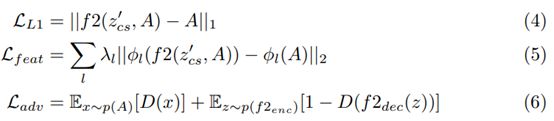
其中, ∅ l \varnothing_{l} ∅l表示预先训练的VGG-19网络的某一层激活的损失。这个阶段的鉴别器有以下目标:
![]()
在测试过程中,作者使用前一阶段生成的服装分割。需要注意的是,作者通过跨通道执行argmax操作来展平18通道分段映射。这样做主要是为了防止由于阶段1的输出在一个特定的像素位置,在一个以上的通道中有非零值,而产生的伪影。此步骤是不可微的,因此不允许端到端培训。但是可以通过跳过argmax步骤并使用softmax来对这些预训练网络执行端到端微调。作者指出,这个框架对输入服装和人体分割中的噪声是鲁棒的。第二阶段对第一阶段产生的噪声服装分割进行操作,在填充纹理和颜色时学习忽略噪声。
该网络的主要优势在于,与着装中人的生成模型不同的是,服装分割和身体分割不需要非常干净,框架才能有效。该分割是通过最先进的人体分析和身体分析模型获得的,但是这些模型的预测仍然是有噪声的,并且经常有漏洞。然而,该网络可以学习补偿这些中间表示中的噪声。有噪声的衣服和身体分割提供了一个非常丰富和结构化的信号,而不是姿势关键点,同时没有像输入到pix2pix和Scribbler一样的限制,后者需要精确的草图或分割作为输入来产生合理的结果。
此外,作者对第一阶段的输出执行一些后处理,以在将目标个体送入第二阶段之前保留其身份。特别地,在生成的服装分割 B cs ′ B_{\text{cs}}^{'} Bcs′中,将原始服装分割 B cs B_{\text{cs}} Bcs中的“脸”和“头发”部分替换为相应的部分。类似地,在第二阶段结束时,将人脸和头发像素从B复制到结果中。如果没有这些步骤,整个框架就变得类似于寄托同一个人,而不是将衣服重新定位到另一个人身上。

图5. 测试结果。其中SwapNet-Feat(无特征损失训练)和SwapNet-Gan(无GAN损失训练)
然而,这个框架很难处理源图像和目标图像之间的大姿态变化。如果其中一个图像包含一个部分的身体,而另一个包含一个完整的身体,模型就无法为缺失的下肢产生适当的幻觉细节。此外,这个框架对诸如帽子和太阳镜之类的类的遮挡非常敏感,并且可能生成混合伪影。并且网络有时无法处理部分自我遮挡。
SwapNet是根据2维模特的图像之间转移服装这一领域的较早成果,因此论文表示没有找到比较好的参照。现今已有据说在保持衣服特点上表现更好的M2E-TON,还有更进一步的I-VTON(Inpainting-Based Virtual Try-on Network for Selective Garment Transfer)等等,不过这些论文还没有现有的代码,所以这次还是针对SwapNet作一些了解。
VITON-GAN: Virtual Try-on Image Generator Trained with Adversarial Loss(Eurographics 2019)
VITON-GAN: 对抗性损失训练的虚拟衣图像生成器
(Github项目地址)
作者提出了一个虚拟试穿生成对抗网络(VITON-GAN),它是对CP-VTON的一种改进。该网络使用店内服装和模特儿的图像生成虚拟试穿图像。通过在训练流水线中添加对抗机制,当模型人的图像中存在遮挡时(例如,在衣服前面交叉的双臂),该方法可以提高生成图像的质量。
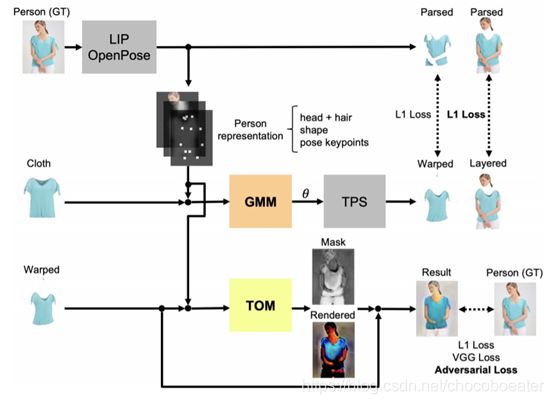
图1. VITON-GAN的结构

图2. CP-VTON的GMM的损失函数是生成的扭曲服装和真实图片的衣服图层之间的L1损失
VITON-GAN相对于CP-VTON有三个主要更新。
(1)对TOM进行对抗训练,以判别器为基础,使用TOM结果图像,店内服装图像和人像作为输入,并判断结果是real还是fake。
(2)GMM的损失函数包括生成图像和真实图像的衣服+身体图层之间的L1距离。(CP-VTON的GMM损失函数见图2)
(3)随机水平翻转用于数据增强。(根据博客看来数据增强能够训练的数据量以提高模型的泛化能力,或是增加噪声数据以提升模型的鲁棒性,链接中提到了更多数据增强的可能性)

图3. 成功例子

图4. 失败例子
根据作者得到的实验结果,在遮挡例子中,VITON-GAN产生的手和手臂比CP-VTON更清楚。但是,当模型的原始衣服为半袖且试穿的衣服为长袖时,手臂产生失败(参见图4:上排)。这是因为TPS转换无法处理在长袖衬衫被遮盖的情况下经常发生的拓扑变化。同样,尽管在大多数情况下,VITON-GAN生成的图像与CP-VTON一样好(请参见图3),但偶尔也会生成模糊的图像,如图4的下一行所示。
(更多的对比结果由于我还没跑完模型,之后才能看到)
总结
对近年的两篇虚拟试衣相关的论文进行了了解,它们都是在Github上已有复现的论文。其中VITON-GAN的项目结构与CP-VTON的基本一致。
上周师姐给我分享了一些相关经验,例如可以专注于某一模块的优化,以减少工作量。将原先的部分结构替换为新型的网络结构有时能产生意想不到的效果,这和VITON-GAN做的工作很类似。
最近除了看论文和代码相关外,也在看网上一些dalao的实验笔记,尤其是一些记录了实验的过程与改进优化思路的,也许能找到可借鉴的地方。
相关博客
相关实验笔记