【MediaPipe】(3) AI视觉,人脸识别,附python完整代码
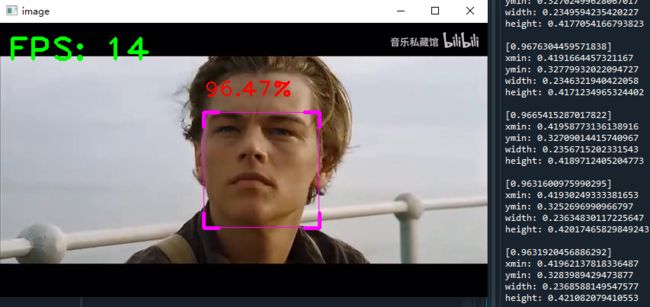
各位同学好,今天和大家分享一下如何使用MediaPipe完成人脸实时跟踪检测,先放张图看效果,FPS值为14,右侧的输出为:每帧图像是人脸的概率,检测框的左上角坐标及框的宽高。
有需要的可以使用 cv2.VideoCapture(0) 捕获电脑摄像头。本节就用视频进行人脸识别。
1. 导入工具包
# 安装opencv
pip install opencv-contrib-python
# 安装mediapipe
pip install mediapipe
# pip install mediapipe --user #有user报错的话试试这个
# 安装之后导入各个包
import cv2 #opencv
import mediapipe as mp
import time人脸检测的相关说明见官方文档:Face Detection - mediapipe
MediaPipe 人脸检测是一种识别速度超快的方法,具有 6 个特征点和多面支持。它基于BlazeFcae一个轻量级且性能良好的面部检测器,专为移动GPU推理量身定制。该探测器的超实时性能使其能够应用于任何需要精确感兴趣面部区域作为其他任务特定模型输入的实时取景器体验,例如3D面部关键点或几何估计(例如 MediaPipe Face Mesh)面部特征或表情分类以及面部区域分割。
2. 相关函数说明
从mediapipe中导入检测方法,今天我们使用人脸检测 mediapipe.solutions.face_detection。
mediapipe.solutions.hands # 手部关键点检测
mediapipe.solutions.pose # 人体姿态检测
mediapipe.solutions.face_mesh # 人脸网状检测
mediapipe.solutions.face_detection # 人脸识别
....................(1)mediapipe.solutions.face_detection.FaceDetection() 人脸检测函数
参数:
min_detection_confidence: 默认为 0.5。人脸检测模型的最小置信值 (0-1之间),高于该置信度则将检测视为成功。
返回值:
detections:检测到的人脸的集合,其中每个人脸都表示为一个检测原始消息,其中包含 人脸的概率、1 个边界框、6 个关键点(右眼、左眼、鼻尖、嘴巴中心、右耳、左耳)。边界框由 xmin 和 width (由图像宽度归一化为 [0, 1])以及 ymin 和 height (由图像高度归一化为 [0, 1])组成。每个关键点由 x 和 y 组成,分别通过图像宽度和高度归一化为 [0, 1]。
返回值.score: 获取图像是人脸的概率
返回值.location_data: 获取识别框的 x, y, w, h 和 6个关键点的 x, y
返回值.location_data.relative_bounding_box: 获取识别框的 x, y, w, h
返回值.location_data.relative_keypoints: 6个关键点的 x, y 组成的列表
(2)mediapipe.solutions.drawing_utils.draw_landmarks() 绘制手部关键点的连线
参数:
image: 需要画图的原始图片
landmark_list: 检测到的手部关键点坐标
connections: 连接线,需要把那些坐标连接起来
landmark_drawing_spec: 坐标的颜色,粗细
connection_drawing_spec: 连接线的粗细,颜色等
3. 只绘制识别框和关键点
使用 cv2.VideoCapture() 读取视频文件时,文件路径最好不要出现中文,防止报错。
变量.read() 每次执行就从视频中提取一帧图片,需要循环来不断提取。用success来接收是否能打开,返回True表示可以打开。img保存返回的的每一帧图像。
由于读入视频图像通道一般为RGB,而opencv中图像通道的格式为BGR,因此需要 cv2.cvtColor() 函数将opencv读入的视频图像转为RGB格式 cv2.COLOR_BGR2RGB。
import cv2
import mediapipe as mp
import time
# 导入人脸识别模块
mpFace = mp.solutions.face_detection
# 导入绘图模块
mpDraw = mp.solutions.drawing_utils
# 自定义人脸识别方法,最小的人脸检测置信度0.5
faceDetection = mpFace.FaceDetection(min_detection_confidence=0.5)
#(1)导入视频
filepath = 'C:\\GameDownload\\Deep Learning\\face.mp4'
cap = cv2.VideoCapture(filepath)
pTime = 0 # 记录每帧图像处理的起始时间
#(2)处理每一帧图像
while True:
# 每次取出一帧图像,返回是否读取成功(True/False),以及读取的图像数据
success, img = cap.read()
# 将opencv导入的BGR图像转为RGB图像
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将每一帧图像传给人脸识别模块
results = faceDetection.process(imgRGB)
# 如果检测不到人脸那就返回None
if results.detections:
# 返回人脸关键点索引index,和关键点的坐标信息
for index, detection in enumerate(results.detections):
# 遍历每一帧图像并打印结果
print(index, detection)
# 每帧图像返回一次是人脸的几率,以及识别框的xywh,后续返回关键点的xy坐标
# print(detection.score) # 是人脸的的可能性
# print(detection.location_data.relative_bounding_box) # 识别框的xywh
# 绘制关键点信息及边界框
mpDraw.draw_detection(img, detection)
# 记录每帧图像处理所花的时间
cTime = time.time()
fps = 1/(cTime-pTime) #计算fps值
pTime = cTime # 更新每张图像处理的初始时间
# 把fps值显示在图像上,img画板;fps变成字符串;显示的位置;设置字体;字体大小;字体颜色;线条粗细
cv2.putText(img, f'FPS: {str(int(fps))}', (10,50), cv2.FONT_HERSHEY_PLAIN, 3, (0,255,0), 3)
# 显示图像,输入窗口名及图像数据
cv2.imshow('image', img)
if cv2.waitKey(50) & 0xFF==27: #每帧滞留50毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()结果如下图所示,准确找到了人脸位置,并绘制识别框。右侧打印识别框和关键点信息。
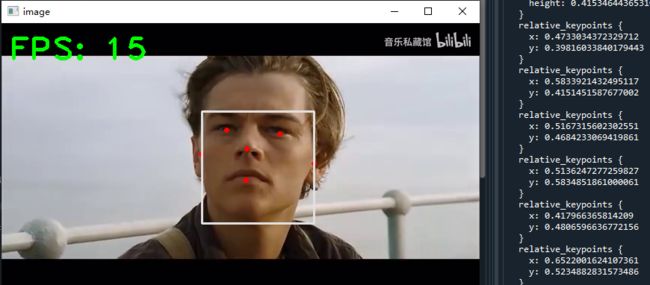
4. 编辑识别框,保存人脸位置信息
在这里我更加关注识别框的位置位置,不太关心关键点的坐标信息,因此接下来我们单独绘制识别框,并把每一帧图像的人脸概率显示出来。如果有同学更关注人脸关键点,可以使用mediapipe的人脸网状检测,能得到的关键点非常多,这个我在后续章节也会写。
因此,接下来我们在上面代码的基础上继续补充。detection.location_data.relative_bounding_box 获取检测框的左上角坐标和检测框的宽高,保保存在bbox中。如下我们可以看到识别框的信息都是归一化之后的,需要将其转换为像素坐标。
IN[21]: detection.location_data.relative_bounding_box
Out[21]:
xmin: 0.6636191606521606
ymin: 0.16451001167297363
width: 0.1620280146598816
height: 0.28804928064346313转换方法也很简单,只需要将比例长度x和w乘以实际图像宽度即可得到像素长度下的x和w,同理y和h。注意,像素长度一定是整数,如[200,200],比例长度是小数,如[0.5, 0.5]
使用自定义矩形绘制函数cv2.rectangle(),现在有了像素坐标下的左上坐标xy,框的宽w和高h。就可以在原图像img上把框绘制出来。
detection.score 获取检测框的人脸概率值,返回只有一个元素的列表。detection.score[0] 提取这个元素,返回浮点型数值。
# 导入人脸识别模块
mpFace = mp.solutions.face_detection
# 导入绘图模块
mpDraw = mp.solutions.drawing_utils
# 自定义人脸识别方法,最小的人脸检测置信度0.5
faceDetection = mpFace.FaceDetection(min_detection_confidence=0.5)
#(1)导入视频
filepath = 'C:\\GameDownload\\Deep Learning\\face.mp4'
cap = cv2.VideoCapture(filepath)
pTime = 0 # 记录每帧图像处理的起始时间
boxlist = [] # 保存每帧图像每个框的信息
#(2)处理每一帧图像
while True:
# 每次取出一帧图像,返回是否读取成功(True/False),以及读取的图像数据
success, img = cap.read()
# 将opencv导入的BGR图像转为RGB图像
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将每一帧图像传给人脸识别模块
results = faceDetection.process(imgRGB)
# 如果检测不到人脸那就返回None
if results.detections:
# 返回人脸索引index(第几张脸),和关键点的坐标信息
for index, detection in enumerate(results.detections):
# 遍历每一帧图像并打印结果
# print(index, detection)
# 每帧图像返回一次是人脸的几率,以及识别框的xywh,后续返回关键点的xy坐标
print(detection.score) # 是人脸的的可能性
print(detection.location_data.relative_bounding_box) # 识别框的xywh
# 设置一个边界框,接收所有的框的xywh及关键点信息
bboxC = detection.location_data.relative_bounding_box
# 接收每一帧图像的宽、高、通道数
ih, iw, ic = img.shape
# 将边界框的坐标点从比例坐标转换成像素坐标
# 将边界框的宽和高从比例长度转换为像素长度
bbox = (int(bboxC.xmin * iw), int(bboxC.ymin * ih),
int(bboxC.width * iw), int(bboxC.height * ih))
# 有了识别框的xywh就可以在每一帧图像上把框画出来
cv2.rectangle(img, bbox, (255,0,0), 5) # 自定义绘制函数,不适用官方的mpDraw.draw_detection
# 把人脸的概率显示在检测框上,img画板,概率值*100保留两位小数变成百分数,再变成字符串
cv2.putText(img, f'{str(round(detection.score[0] * 100, 2))}%',
(bbox[0], bbox[1]-20), # 文本显示的位置,-20是为了不和框重合
cv2.FONT_HERSHEY_PLAIN, # 文本字体类型
2, (0,0,255), 2) # 字体大小; 字体颜色; 线条粗细
# 保存索引,人脸概率,识别框的x/y/w/h
boxlist.append([index, detection.score, bbox])
# 记录每帧图像处理所花的时间
cTime = time.time()
fps = 1/(cTime-pTime) #计算fps值
pTime = cTime # 更新每张图像处理的初始时间
# 把fps值显示在图像上,img画板;fps变成字符串;显示的位置;设置字体;字体大小;字体颜色;线条粗细
cv2.putText(img, f'FPS: {str(int(fps))}', (10,50), cv2.FONT_HERSHEY_PLAIN, 3, (0,255,0), 3)
# 显示图像,输入窗口名及图像数据
cv2.imshow('image', img)
if cv2.waitKey(50) & 0xFF==27: #每帧滞留50毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()结果如下图所示,右侧输出每帧图像的每个识别框的概率和框坐标
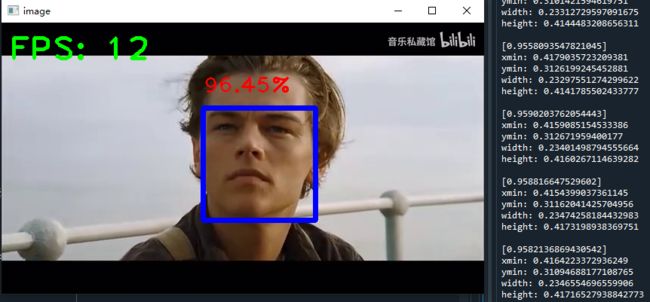
5. 优化识别框
接下来把识别框做的好看一些,只需要修改矩形框样式即可,我们接着上面的代码编辑。把识别框宽度调细一些,在四个角上添加粗线段。
# 导入人脸识别模块
mpFace = mp.solutions.face_detection
# 导入绘图模块
mpDraw = mp.solutions.drawing_utils
# 自定义人脸识别方法,最小的人脸检测置信度0.5
faceDetection = mpFace.FaceDetection(min_detection_confidence=0.5)
#(1)导入视频
filepath = 'C:\\GameDownload\\Deep Learning\\face.mp4'
cap = cv2.VideoCapture(filepath)
pTime = 0 # 记录每帧图像处理的起始时间
boxlist = [] # 保存每帧图像每个框的信息
#(2)处理每一帧图像
while True:
# 每次取出一帧图像,返回是否读取成功(True/False),以及读取的图像数据
success, img = cap.read()
# 将opencv导入的BGR图像转为RGB图像
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将每一帧图像传给人脸识别模块
results = faceDetection.process(imgRGB)
# 如果检测不到人脸那就返回None
if results.detections:
# 返回人脸索引index(第几张脸),和关键点的坐标信息
for index, detection in enumerate(results.detections):
# 遍历每一帧图像并打印结果
# print(index, detection)
# 每帧图像返回一次是人脸的几率,以及识别框的xywh,后续返回关键点的xy坐标
print(detection.score) # 是人脸的的可能性
print(detection.location_data.relative_bounding_box) # 识别框的xywh
# 设置一个边界框,接收所有的框的xywh及关键点信息
bboxC = detection.location_data.relative_bounding_box
# 接收每一帧图像的宽、高、通道数
ih, iw, ic = img.shape
# 将边界框的坐标点从比例坐标转换成像素坐标
# 将边界框的宽和高从比例长度转换为像素长度
bbox = (int(bboxC.xmin * iw), int(bboxC.ymin * ih),
int(bboxC.width * iw), int(bboxC.height * ih))
# 有了识别框的xywh就可以在每一帧图像上把框画出来
# cv2.rectangle(img, bbox, (255,0,0), 5) # 自定义绘制函数,不适用官方的mpDraw.draw_detection
# 把人脸的概率显示在检测框上,img画板,概率值*100保留两位小数变成百分数,再变成字符串
cv2.putText(img, f'{str(round(detection.score[0] * 100, 2))}%',
(bbox[0], bbox[1]-20), # 文本显示的位置,-20是为了不和框重合
cv2.FONT_HERSHEY_PLAIN, # 文本字体类型
2, (0,0,255), 2) # 字体大小; 字体颜色; 线条粗细
# 保存索引,人脸概率,识别框的x/y/w/h
boxlist.append([index, detection.score, bbox])
#(3)修改识别框样式
x, y, w, h = bbox # 获取识别框的信息,xy为左上角坐标点
x1, y1 = x+w, y+h # 右下角坐标点
# 绘制比矩形框粗的线段,img画板,线段起始点坐标,线段颜色,线宽为8
cv2.line(img, (x,y), (x+20,y), (255,0,255), 4)
cv2.line(img, (x,y), (x,y+20), (255,0,255), 4)
cv2.line(img, (x1,y1), (x1-20,y1), (255,0,255), 4)
cv2.line(img, (x1,y1), (x1,y1-20), (255,0,255), 4)
cv2.line(img, (x1,y), (x1-20,y), (255,0,255), 4)
cv2.line(img, (x1, y), (x1, y+20), (255, 0, 255), 4)
cv2.line(img, (x,y1), (x+20,y1), (255,0,255), 4)
cv2.line(img, (x,y1), (x,y1-20), (255,0,255), 4)
# 在每一帧图像上绘制矩形框
cv2.rectangle(img, bbox, (255,0,255), 1) # 自定义绘制函数
# 记录每帧图像处理所花的时间
cTime = time.time()
fps = 1/(cTime-pTime) #计算fps值
pTime = cTime # 更新每张图像处理的初始时间
# 把fps值显示在图像上,img画板;fps变成字符串;显示的位置;设置字体;字体大小;字体颜色;线条粗细
cv2.putText(img, f'FPS: {str(int(fps))}', (10,50), cv2.FONT_HERSHEY_PLAIN, 3, (0,255,0), 3)
# 显示图像,输入窗口名及图像数据
cv2.imshow('image', img)
if cv2.waitKey(50) & 0xFF==27: #每帧滞留50毫秒后消失,ESC键退出
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()
修改后的检测框效果如下
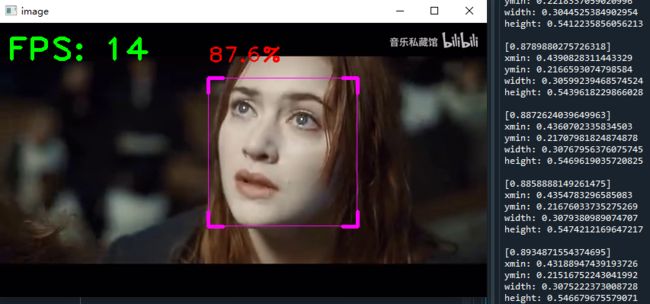
我们将坐标信息存放在了boxlist中,boxlist.append([index, detection.score, bbox]) 存放人脸索引、评分、检测框信息,把它打印出来看一下,比如某帧图像所在的视频有3张脸,每一帧都会输出0、1、2三个识别框的概率,左上角坐标xy,框的宽高wh
。。。。。。。。。。。。。。。。。。。。。。。。。
[0, [0.9619430303573608], (98, 100, 96, 96)],
[1, [0.9173532128334045], (457, 65, 118, 118)],
[2, [0.8985080122947693], (268, 52, 123, 123)],
[0, [0.9615015983581543], (98, 100, 97, 97)],
[1, [0.9164762496948242], (457, 65, 118, 118)],
[2, [0.9118367433547974], (269, 53, 123, 123)],
[0, [0.9616674780845642], (97, 100, 97, 97)],
[1, [0.9218802452087402], (272, 53, 122, 122)],
[2, [0.9176990389823914], (456, 65, 118, 118)],
[0, [0.9638006091117859], (97, 101, 97, 97)],
[1, [0.9180505275726318], (276, 56, 119, 119)],
[2, [0.9177079796791077], (456, 64, 118, 118)],
。。。。。。。。。。。。。。。。。。。。。。。。。。