Multi-Level Knowledge Injecting for Visual Commonsense Reasoning
摘要——当浏览一幅图像时,人类可以推断出隐藏在图像中的东西,而不是视觉上明显的东西,例如物体的功能、人的意图和精神状态。然而,这种视觉推理范式对计算机来说非常困难,需要了解世界是如何工作的。为了解决这个问题,我们提出了基于常识知识的推理模型(CKRM)来获取外部知识,以支持视觉常识推理(VCR)任务,其中计算机被期望回答具有挑战性的视觉问题。我们的核心思想是:(1)通过多层次知识转移网络注入外部常识知识,实现细胞级、层级和注意力级的联合信息转移,从而弥合识别级和认知级图像理解之间的鸿沟。它可以有效地从不同的角度捕捉知识,提前感知人类的常识。(2)为了进一步促进认知水平上的图像理解,我们提出了一种基于知识的推理方法,该方法可以将转移的知识与视觉内容相关联,并组成推理线索来获得最终答案。在具有挑战性的视觉常识推理数据集VCR上进行的实验验证了我们提出的CKRM方法的有效性,该方法可以显著提高推理性能并达到最先进的精度。
INTRODUCTION
通过对场景的一瞥,人们不仅可以知道场景中明显的东西(例如物体、物体的位置、物体的状态和动作),而且可以推断出许多不明显的事情(例如物体的功能、人的心理状态和即将发生的事情)。目前,计算机算法在图像分类[1]、[2]、目标检测[3]-[5]、动作识别[6]、[7]、场景解析[8]、[9]等识别任务上取得了很大进展。然而,在处理涉及推理的任务,特别是常识性推理时,计算机还有很长的路要走。
推理作为人类的一种重要能力,在人工智能领域受到了广泛关注。在文本理解领域,一个具有代表性的任务是自然语言推理[10](也称为文本蕴涵识别),它需要计算机来判断假设是否可以从前提中推断出来。然而,这种语言蕴涵主要侧重于对句子对之间的关系进行建模,而不是认知层面的推理。许多视觉和语言任务被认为是令人信服的“人工智能完备”任务[11],这些任务除了需要单一通道外,还需要多通道推理。最具代表性的任务之一是视觉问答(VQA)[12]、[13],它旨在自动推断视觉问题的文本答案。由于深度神经网络在计算机视觉和自然语言处理方面具有很强的学习能力,这方面的研究已经取得了很大的进展。计算机在回答与图像内容直接相关的问题方面取得了长足的进步,如物体的类别、编号和颜色[14]-[16]。然而,当面对明确的信息不够、需要更多常识的问题时,性能仍然远远不能令人满意[17]。因此,如何有效地获取和结合人类常识是更好地处理VQA任务的有效途径。
作为推理的一个分支,常识推理在从自然语言处理到计算机视觉的许多人工智能领域都具有非常重要的意义。本文主要研究视觉常识推理(VCR),它模拟了人类对日常遇到的常见情况进行推理的能力。与传统的VQA任务不同,VCR对认知水平的视觉理解提出了更高的要求。例如,我们不是把注意力集中在一个低层次的动作上:“一个男孩单膝跪向一个女孩”,而是希望联系常识,推断出:“男孩可能想向女孩求婚。”
图1显示了可视化常识推理的一个示例。对于给定的图像,会问一个问题:“为什么每个人都低着头坐着?”当人们面对这个问题时,我们可以首先识别物体(食物、盘子、餐桌等),然后进一步推断这种情况很可能发生在吃东西的时候。此外,餐桌上还有未吃的食物,每个人都闭上了眼睛。他们中的大多数人还把手放在前面,低着头。然后,我们讲述了一个常识,即“信教的人通常在吃饭前手牵手,低下头,闭上眼睛,祈祷感谢”。根据认知和常识的联合信息,我们可以推断出整个情况:人们在吃饭前祈祷。
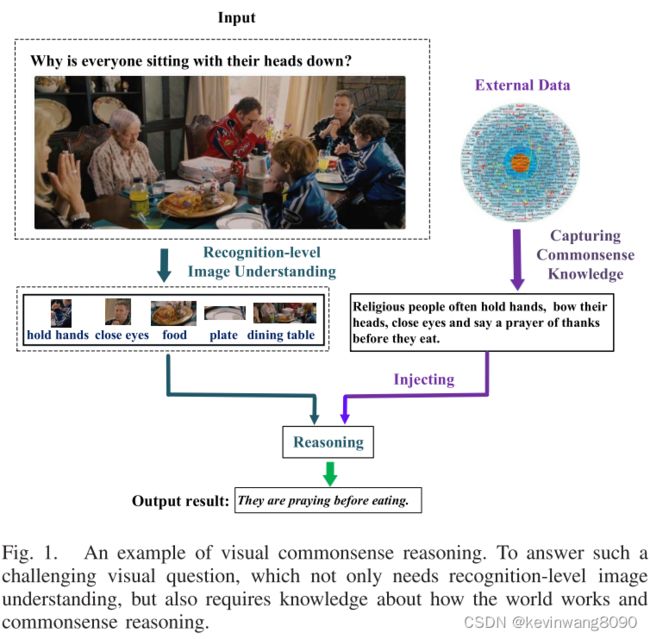
这种视觉常识推理范式广泛存在于人们的日常生活中。比如说看电影的时候,我们通常会对人物的意图、故事的结局等做出很多推断。更重要的是,在社会互动的过程中,我们还必须推断人们的行为、目标和心理状态。这对人类来说似乎不费吹灰之力,但对计算机来说却极其困难,因为:(1)人类常识推理往往伴随着经验知识的积累,而计算机缺乏这种知识。(2)除了识别级的视觉理解之外,计算机还需要对图像所引起的隐含上下文进行更深层次的推理
针对上述问题,我们提出了基于常识的推理模型CKRM(Common-Sense Knowledge Based Reason Model)来获取外部知识,并利用这些知识来支持可视化常识推理任务。主要贡献可以概括为:
多层次的知识转移网络:
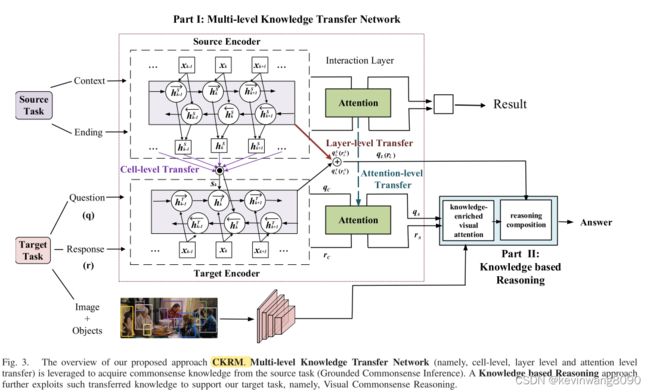
为了弥合识别级和认知级图像理解之间的差距,我们通过迁移学习注入从现有数据中获取的外部知识,实现了细胞级、层级和注意力级的联合信息传递。它可以从不同的角度传递知识,并提供互补的提示,激活计算机提前知道一些常识。
基于知识的推理:
为了进一步向认知级图像理解迈进,充分利用转移的知识,我们提出了一种基于知识的推理方法。它由两个主要组成部分组成:
- 丰富知识的视觉注意,它将传递的知识与视觉内容联系起来,实现推理线索的细粒度对齐
- 推理合成,合成推理线索,得出最终答案
多级知识传递网络和基于知识的推理方法形成了端到端的体系结构。因此,它们可以共同优化,以相互促进迁移学习和推理,从而提高视觉常识推理任务的绩效。为了验证我们提出的方法的有效性,我们在VCR数据集上进行了大量的实验,并取得了最新的结果。
CONCLUSION
本文提出了CKRM来获取外部常识,并注入这些常识来支持可视化常识推理任务。我们首先提出了一个多层次的知识转移网络,从不同的角度获取知识,即从源任务中获取细胞级、层级和注意力级的信息。其次,我们进一步提出了一种基于知识的推理方法,该方法可以充分利用传递的知识来推导推理结果。作为一种端到端的体系结构,我们的方法可以共同优化,以相互促进迁移学习和推理。为了验证该方法的有效性,我们在VCR上进行了实验。在未来的工作中,我们将加入更多的知识类型来辅助视觉常识推理任务。将深度学习与传统人工智能方法相结合是一个很有前途的方向,我们将探索如何更好地将经典的基于知识的方法与深度学习相结合。
提出的问题:
计算机不能像人类一样推断出隐藏在图像中的东西,需要了解外部是怎样运作的。
人类常识推断往往伴随着经验知识的积累,而计算机缺乏这种知识,计算机还需要对图像所引起的隐含上下文进行更深层次的推理。
解决方案:
通过迁移学习的思想,从多个层级进行知识嵌入的学习,利用事实常识推理的任务获取常识知识,使用到视觉常识推理。
讨论:
本文的主要思想就是使用一个迁移学习的方法,从一个源任务的训练中获取不同层级常识知识,然后用于视觉推理任务,并提出了一个推理模块。
这种迁移学习的方式,将常识知识隐式提取与应用。两种任务的学习方式,带来大量的计算。