Explicit Knowledge Incorporation for Visual Reasoning
Abstract
现有的可解释的和显式的视觉推理方法只执行基于视觉证据的推理,而不考虑视觉场景之外的知识。为了解决视觉推理方法和真实世界图像的语义复杂性之间的知识差距,我们提出了第一个显式视觉推理方法,该方法结合了外部知识,并对高阶关系注意进行建模,以提高泛化能力和可解释性。具体来说,我们提出了一个知识合并网络,它为来自外部知识库的实体和谓词显式地创建和包含新的图节点,以丰富用于显式推理的场景图的语义。然后,我们创建一个新的图形关联模块,对丰富的场景图进行高阶关系关注。通过明确引入结构化的外部知识和高阶关系注意,我们的方法在GQA和VQAv2数据集上展示了显著的可推广性和可解释性。
Introduction
视觉问答旨在回答关于视觉场景的自然语言问题。这是一项漫长的任务,需要深入理解视觉和语言输入,以及回答开放式问题的知识。虽然深度神经网络(DNN)非常强大,但大多数基于DNN的VQA方法都是由问题和答案之间的表面相关性驱动的黑匣子[2]。因此,这些模型在作出推论或概括方面是有限的。他们也不能解释他们的决策过程,特别是复杂的问题,需要多个推理步骤才能回答。DNN模型缺乏通用性或可解释性,降低了其在医疗保健、安全和金融等多个领域的应用速度。
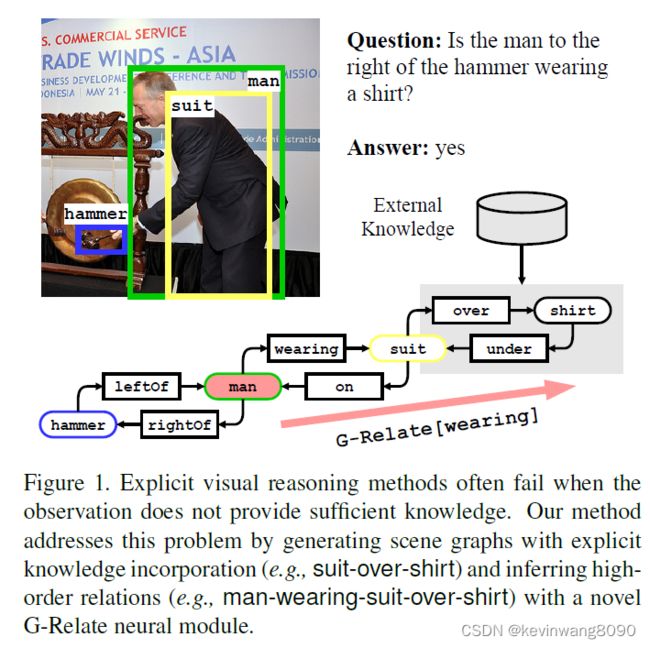
最近的研究旨在通过将视觉信息表示为结构化场景图[24]或将问题转换为可执行神经模块的程序[11,12]来解决这些问题。这些可解释的显式推理模型在合成场景和问题上取得了显著的性能[14]。然而,由于真实世界图像和问题的复杂性,当在更一般的VQA数据集上测试时,它们仍然远远不能令人满意[5,13]。这些数据驱动的方法依赖于检测对象及其关系的准确性和完整性,并且不了解常识或视觉观察之外的其他有用知识。例如,如图1所示,回答“锤子右边的那个人穿衬衫了吗?”视觉推理模型需要检测衬衫,并注意它是否存在。这个例子中的推理任务具有挑战性,因为衬衫在场景中是无法检测到的。另一方面,人类可以很容易地整合“男人穿西装”的观察和“西装通常穿在衬衫上”的常识知识,来推断男人和衬衫之间的高阶关系。为了实现视觉推理的可概括性和可解释性,我们提出了一种基于知识整合和高阶关系注意的可解释的显式视觉推理方法。它描述了与现有方法相比的两个主要优势:
首先,现有的视觉推理研究要么隐含地将外部知识作为语言特征嵌入[12,24],要么将信息从外部知识图传播到具有静态拓扑的场景图中[32],这不能解决视觉场景中未检测到的对象或缺失的概念。不同的是,在这项工作中,我们通过添加实体和谓词作为新节点,将外部知识图中的常识知识显式地合并到场景图中。如图1所示,使用我们提出的方法,可以将外部关系衬衫-西装下和西装-外衫添加到场景图中,以丰富场景图。这种丰富的场景图提供了更丰富的语义,支持可概括和可解释的推理。
第二,现有方法依赖于检测到的二元关系,但是缺乏推断场景图中远处节点之间的高阶关系的机制。例如,如图1所示,现有的神经模块网络不能用一阶关联模块进行正确推理,因为在人和衬衫之间没有检测到直接关系,或者问题没有指定两者(例如,穿着和过度)的关系。我们通过设计一个新颖的图形相关模块来解决这个挑战,该模块支持高阶关系推理。尽管人和衬衫之间没有直接的关系,但G-Relate可以根据人穿西装和西装外套这两种直接关系来推断人穿衬衫的概率。这使得我们的模型能够有效地将注意力转移到不相邻的图节点,并正确回答问题。
我们将这项工作的贡献总结如下:
1 .我们提出了第一个显式视觉推理模型,该模型利用外部知识和神经模块来实现可推广性和可解释性。
2.我们设计了一个知识整合网络(KINet),它将外部知识作为额外的节点和边明确地整合到场景图中,为推理提供丰富的语义。
3.我们设计了一个基于场景图拓扑和语义实现高阶关系关注的图相关模块。
4.在GQA [13]和VQAv2 [5]数据集上,我们的方法优于最先进的显式推理方法,表明其优越的泛化能力和可解释性。
Related Work
场景图。
场景图已经广泛应用于各种视觉任务中,例如图像字幕[8,30,31]和VQA [7,24,26]。高质量的场景图可以准确可靠地描述图像的视觉内容,不完整或不正确的场景图会降低感兴趣任务的性能。为了生成更精确的场景图,一些研究通过将知识表示为语言特征[28,29,33]或主谓宾三元组[1]来隐含地包含外部知识。吴等[29]直接将外部知识嵌入到语言特征中,并将其与视觉特征相结合。顾等人[9]通过将检测到的对象与概念网[19]中的类进行匹配来查询类间的关系。Zareian等人[32]应用图卷积网络[17]在场景图和外部知识图之间传播信息。这些方法只细化图节点的特征,而不细化图拓扑,不能解决未检测到的对象或外部概念的问题。不同的是,通过为外部实体和谓词显式添加图节点,我们的方法扩展了场景图以包含更丰富的语义,直到所需数量的外部知识被合并。更重要的是,它允许在这些额外的图节点上直接执行神经模块,从而弥补了用知识进行可解释的视觉推理的研究空白。
可解释和明确的视觉推理。
我们的方法与一系列可解释和明确的推理方法有关[4,10,11,12,15,20,24]。由于深度神经网络卓越的学习能力,端到端VQA模型可以毫无理由地轻松学习数据集偏差[14]。为了解决这个问题,最近的研究开发了复合推理模型,通过设计和执行基于图像特征[4,10,15,20]或场景图[12,24]的神经模块。最近,史等人[24]提出了可解释和显式神经模块(XNMs),不仅在CLEVR [14]数据集上实现了100%的准确性,而且允许在推理过程中显式跟踪场景图中的注意力转移。类似地,神经状态机(NSM) [12]预测一个概率图,并用更一般的模块对该图进行顺序推理。我们的方法通过引入外部知识和高阶关系注意来区别于这些相关研究。我们提出的图相关模块将注意力传播到场景图中不相邻的节点,从而能够有效地引用高阶关系。
Approach
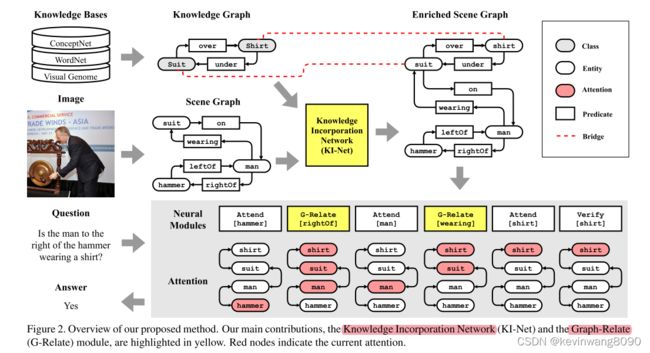
第一次,我们通过利用场景图、外部知识边缘和神经模块来进行可解释和明确的视觉推理。我们的方法首先通过明确地结合外部知识来创建丰富的场景图,然后执行由问题生成的神经模块程序。图2突出显示了我们的方法的两个示例,包括一个知识合并网络(KI-Net),它将实体和谓词从外部知识图显式地合并到场景图中,以及一个Graph-Relate (G-Relate)模块,它基于丰富的场景图来推断高阶关系。
Knowledge Incorporation Network
KI-Net,神经模块网络通常在包含一组特定语义的数据集上进行训练[13,14],这使得它们很难推广和扩展到更广泛的知识范围。提出的知识网络旨在支持语义更丰富的显式推理,并允许神经模块跟踪视觉观察之外的推理过程。它被设计为显式地将外部知识合并为场景图节点(见图3):基于外部知识图的拓扑,它首先执行拓扑扩展,以将外部关系合并到场景图中(例如,图3中的穿衬衫的人和戴头盔的人,通过向场景图中显式地添加新的候选实体衬衫和头盔)。然后,考虑到视觉和语义特征,它执行语义细化以选择性地丢弃与视觉观察具有低相关性的候选实体(例如,图3中的衬衫)。知网产生了一个丰富的场景图,允许神经模块对合并的语义进行显式推理。它由使用交叉熵损失的地面真实场景图注释来监督。
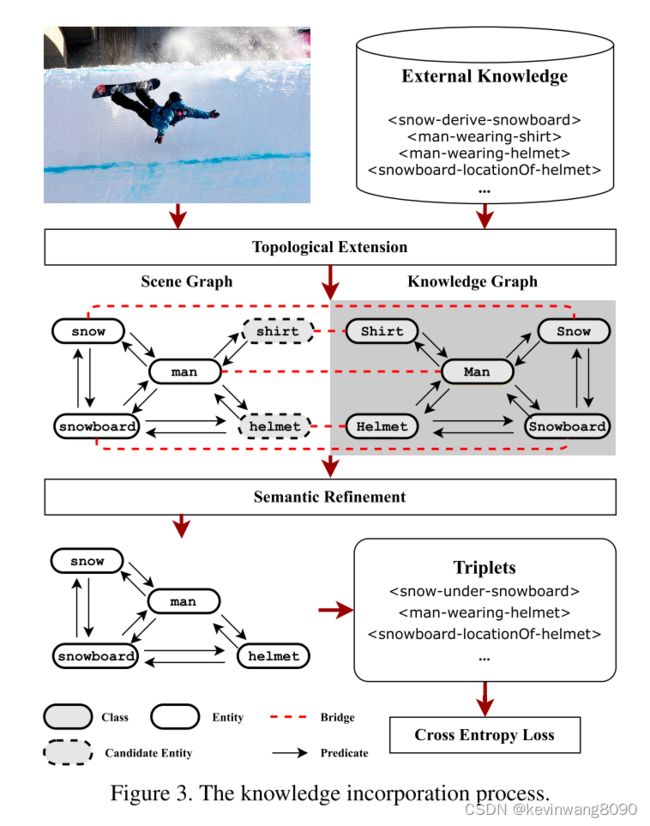
拓扑扩展。
基于场景实体和外部类之间的语义匹配和图拓扑,我们提出候选实体添加到场景图中。首先,场景图中的每个现有实体e ∈ VS与具有相同语义含义(即,高于阈值ǫcls).的最高特征相似性)的类节点g(e) ∈ VK桥接桥接在场景图和知识图之间形成消息传递路径。接下来,我们创建候选实体节点,以便将关于未观察到但直接相关的概念的知识添加到场景图中。让d(,)表示一对输入实体之间谓词的最小数量。如果∃ e ∈ VS,d(g(e′),g(e)) = 1,我们添加一个候选实体e′及其连接到实体e的相邻谓词p。
![]()
最后,e′和p′的特征直接从知识图中相应的节点复制,实体节点e′与其类节点g(e′)桥接,因为它们共享相同的特征。该拓扑扩展确保候选实体(例如,图3的场景图中的衬衫和头盔)与视觉观察(例如,图3中的人)直接相关,并且在语义上与对应的类(例如,图3的知识图中的衬衫和头盔)一致。它在场景图和知识图之间建立了丰富的联系,从而可以联合考虑它们的特征来计算新实体和观察到的场景上下文之间的相关性。
语义细化。
候选实体已经基于知识图拓扑被添加到场景图中,但是它们与观察到的场景上下文的语义相关性是未知的。因此,我们执行语义细化以保持紧凑的场景图,同时包含最相关的外部知识。为了实现这个目标,通过消息传递,我们计算一个相关性矩阵M来度量不同实体之间的特征相关性。矩阵M中的相关权重由视觉特征和来自外部知识的语义共同决定。
给定两个相邻节点vi,vj ∈ VS∪PS∪VK∪PK及其特征hi,hj,消息传递被实现为图关注网络[27]: mij = MLP(hi,hj),φij = softmaxN(vi)(mij),h′I = Xφijhj,N(vi) (2) (3) (4),
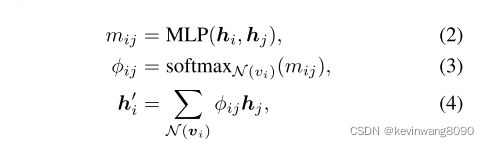
其中N(vi)表示vi的相邻节点集。消息传递导致每个节点vi的更新特征h’I,并且相关性矩阵M包含所有成对的相关性分数mij。我们通过KGAT多次重复此消息,以彻底传播这些特性。利用所计算的相关性矩阵,当e′与其相邻节点之间的top-Kp相关性得分之和小于阈值ǫp.时,候选实体e′被丢弃,所有其相邻谓词节点也被丢弃。最后,我们移除所有的桥,从外部知识图中获得一个只有相关节点的丰富场景图。拓扑扩展和语义细化可以根据所需的知识量进行迭代。
Reasoning with Neural Modules
神经模块网络是一类推理方法,通过在图像特征[4,10,15,20]或场景图[12,24]上组成和执行一组手工神经模块来实现可解释的推理。最近的神经模块网络[24]在合成视觉推理数据集[14]上取得了完美的精度,但是它们对语义丰富的真实世界图像的泛化仍然是一个未解决的问题。我们的KI-Net生成了一个语义范围更广的丰富场景图,允许可解释的推理方法扩展到训练数据之外。在这一节中,我们重点介绍了新的G-Relate模块,它可以通过将注意力转移到不相邻的图节点来推断高阶关系。
为了对丰富的场景图进行显式推理,我们设计了三类神经模块:注意力、逻辑和输出。这些神经模块基于四种元类型的原子模块,可以代表VQA数据集的所有问题类型[5]。注意力模块计算推理过程中不同图像内容(例如图像特征或场景图节点)的相对重要性,这对于许多问题的回答是必不可少的。出席根据实体的特征计算实体的注意力权重,G-Relate通过查询谓词将注意力转移到其他相关实体。除了两个注意力模块,逻辑模块(即And、Or和Not)根据注意力权重执行逻辑运算,输出模块(即比较、计数、存在、选择、描述和验证)根据不同的问题类型计算输出特征。选项卡。1总结了具体的神经模块及其实现。这三类神经模块组成一个程序,对丰富的场景图进行推理。考虑到图的拓扑结构和丰富的语义,神经程序可以在推理过程中显式地跟踪注意力以推断答案。
图形相关模块。
在神经模块研究中,考虑到与谓词查询的相关性,关系推理通常通过重新分配注意力来实现[12]。
现有的方法[24]要么仅在相邻场景图节点之间转移注意力,要么学习转移矩阵以在所有节点之间传播注意力,而不管图拓扑如何。在复杂场景图中,随着实体和谓词数量的增加,高阶注意成为现有神经模块无法处理的关键需求。
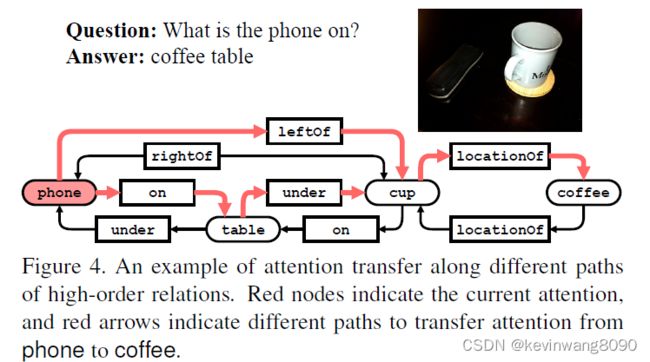
例如,回答“电话在打什么?”,注意力应该从电话转移到相邻实体表和非相邻实体咖啡(见图4)。咖啡的特点提供了关于桌子类型的额外信息。使用一阶相关模块,将注意力转移到咖啡是相当困难的,因为不能从输入中提取电话和咖啡之间的直接关系。为了应对这一挑战,我们设计了一个Graph-Relate模块来推断丰富场景图中的高阶关系,这样注意力就可以沿着关系路径转移到远处的实体。
给定由神经程序中的先前模块计算的注意力a,G-Relate模块计算转移矩阵Wh以在场景图上传播注意力。有了这个转移矩阵,图表的关注点可以更新为:
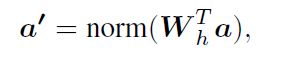
其中norm()使用softmax函数将实体节点的所有注意力权重转换为[0,1]。
传递矩阵Wh可以用各种方法计算。例如,在XNM [24]中,编码的查询q和边缘特征hij用MLP处理以计算转移矩阵。边缘特征来自一阶基本事实关系或两个相邻实体特征的连接。不同的是,我们的GRelate模块考虑场景图中的高阶复合关系:我们提取连接ei和ej(在最大长度L内)的所有可能的关系路径Uij = {U1,U2,,,UN}。例如(见图4),我们提取了描述咖啡和电话之间复合关系的两条路径:咖啡-位置-杯子-电话右侧和咖啡-位置-杯子-桌子-电话下方。两个路径都由一组一阶关系组成,并有助于两个实体之间的高阶关系。基于实体ei和ej之间的拓扑距离lij = d(ei,ej)(即沿着路径的谓词的数量),通过考虑不同的情况来计算转移矩阵。
形式上,我们基于谓词特征和图拓扑计算实体ei和ej之间的转移权重wij:
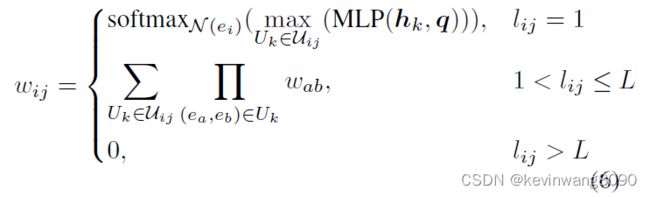
其中hk代表实体ei和ej之间的第k个谓词的特征,wab是相邻实体ea和eb之间的权重。基于谓词特征和查询之间的相关性,直接计算一阶关系(即lij = 1)的转移权重。高转移权重表示谓词特征与查询密切相关,反之亦然。与XNM不同,我们的图结构允许两个实体之间连接多个谓词,这里我们采用它们的最大权重。为了测量高阶关系(1 < lij ≤ L)的转移权重,我们计算沿着每条路径的一阶转移权重的乘积,并在多条路径上线性组合它们。我们将计算出的转移权重存储到关系矩阵Wh中,并通过在整个图中传播这些权重来更新每个实体节点处的关注。这个过程被集成到神经模块的端到端训练中。
场景图和知识图。
KI-Net在初始场景图GS = (VS,PS,es)和外部知识图GK = (VK,PK,EK)上运行。场景图由从图像中检测到的实体节点(即,对象实例,记为VS)和谓词节点(即,实体之间的关系或交互,记为PS)组成。知识图由从外部知识库获得的类节点(即一般概念,表示为VK)和谓词(即概念之间的关系,表示为主键)组成。这两个图都可以用多个谓词连接实体或类。它们将实体或类之间的关系组织成一组主谓宾三元组,其中es和EK包含从主语到谓语或从谓语到宾语的有向边链接。每个节点都与一个dh维特征向量相关联。场景图的节点特征用被检测对象的区域特征初始化[3],而知识图的节点特征用单词元素初始化[22]。视觉和外部节点特征与遵循GB-Net的消息传递相融合[32]。
讨论:
作者认为目前的模型缺乏通用性及可解释性,目前可解释性的工作,以及知识引入的工作,已经有很多人在做了,包括基于结构化的场景图或者可执行神经模块,这些都是可解释的显式推理模型,但缺乏常识。还需要引入常识等数据集集之外的有用知识,作者认为当前方法存在两个问题:
- 现有外部知识嵌入要么是隐含的作为语言特征嵌入(比如 XNM, NSM), ,要么将信息从外部知识图传播到具有静态拓扑的场景图中,不能解决视觉场景中未检测到的对象或缺失的概念。
- 现有方法依赖于检测到的二元关系,但是缺乏推断场景图中远处节点之间的高阶关系的机制
作者提出将外部知识图中的常识显式的合并到场景图中,这种合并操作太复杂,并且对于场景图中的objects所缺失的常识大多是attribute/relation, 主要是属性相关信息的缺失,因此只需要对这部分内容进行补充即可,甚至最合适的方式是在构建场景图的过程中就包含这些外部常识,而不是在构建好场景图后再显式的拓扑合并,这种操作明显增加了复杂性。
而对于图中的高阶关系推理,即多跳推理,作者设计了一个G-Relate来关注高阶(不相邻)的图节点,使模型能够关注不相邻的图节点,这种方式是否有必要?在图卷积网络执行多层迭代时,不相邻节点的信息一样可以传导。
可惜的是本文代码没放出来。