基于kyuubi+spark3 加速hive批计算任务
0x00背景
我司报表平台大量ETL任务原来采用hive on tez引擎执行批计算任务,存在资源不足执行慢等问题急需解决。
经调研及测试,我们发现spark 3.0引擎在sql兼容性及执行速度等方面有巨大优化,平均执行速度是hive的2-10倍,因此我们计划通过spark3.0进行离线加速工作。
0x01架构
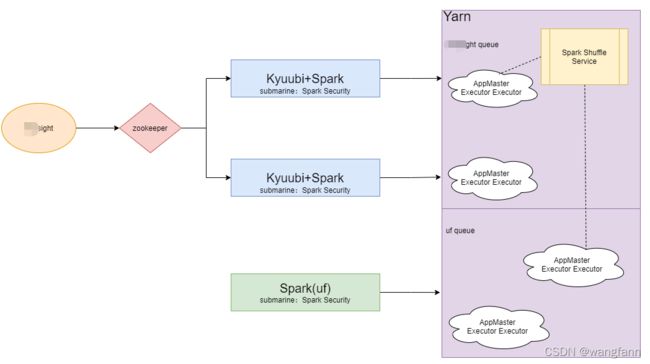
- kyuubi 1.3.0
- spark 3.1.2 Scala 2.12
- Submarine:Spark Sercurity 0.6.0 对接ranger进行库表权限
- 基于kyuubi 1.3.0 开发自定义账号验证器
- python 3.6.0 above
- jdk 1.8
- zookeeper 2.4.3
以上为我司报表平台Spark引擎的架构简图,从图中可以看出我们采用网易开源的Kyuubi替换spark官方sts用于session的管理与转发。
在新架构研发中我们遇到了几个小难点需要解决:
- spark shuffle service的部署
- kyuubi 登陆验证开发及基于ranger库表权限控制
- kyuubi+spark 任务调优
- 报表平台任务迁移方案及sql兼容处理等
0x02 spark shuffle service的部署
我司计算调度主要采用yarn平台,该平台上跑了多种计算引擎的任务,spark shuffle service当前属于nodemanager的一个辅助服务,因此需要修改配置文件并重启nodemanager。
Spark系统在运行含shuffle过程的应用时,Executor进程除了运行task,还要负责写shuffle 数据,给其他Executor提供shuffle数据。
当Executor进程任务过重,导致GC而不能为其他Executor提供shuffle数据时,会影响任务运行。
这里实际上是利用External Shuffle Service 来提升性能,External shuffle Service是长期存在于NodeManager进程中的一个辅助服务。
通过该服务 来抓取shuffle数据,减少了Executor的压力,在Executor GC的时候也不会影响其他 Executor的任务运行。
启用方法:
1. 在NodeManager中启动External shuffle Service。
a. 在“yarn-site.xml”中添加如下配置项:
yarn.nodemanager.aux-services
spark_shuffle
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
spark.shuffle.service.port
7337
配置参数描述
yarn.nodemanager.aux-services:NodeManager中一个长期运行的辅助服务,用于提升Shuffle 计算性能。
yarn.nodemanager.auxservices. spark_shuffle.class : NodeManager中辅助服务对应的类。
spark.shuffle.service.port :Shuffle服务监听数据获取请求的端口。可选配置,默认值为“7337”。
b. 添加依赖的jar包
拷贝“${SPARK_HOME}/yarn/spark-*-yarn-shuffle.jar”到“$ {HADOOP_HOME}/share/hadoop/yarn/lib/”目录下。
c. 重启NodeManager进程,也就启动了External shuffle Service。
2. Spark应用使用External shuffle Service。
在“spark-defaults.conf”中必须添加如下配置项:
spark.shuffle.service.enabled true
spark.shuffle.service.port 7337说明 :
1.如果1.如果“yarn.nodemanager.aux-services”配置项已存在,则在value中添加 “spark_shuffle”,且用逗号和其他值分开。
2.“spark.shuffle.service.port”的值需要和上面“yarn-site.xml”中的值一样。 配置参数描述: spark.shuffle.service.enabled:NodeManager中一个长期运行的辅助服务,用于提升Shuffle 计算性能。默认为false,表示不启用该功能。 spark.shuffle.service.port : Shuffle服务监听数据获取请求的端口。可选配置,默认值 为“7337”。
0x03 kyuubi登陆验证开发及基于ranger库表权限控制
kyuubi提供了多种认证开发方式,我们采用通用的方式自定义自己的认证逻辑。kyuubi的权限控制采用的kyuubi研发团队提供的Submarine Spark Security Plugin插件完成。
以上开发都比较简单在这里我简单列一下部署步骤。
一. kyuubi登录验证开发
kyuubi 连接验证采用类似hiveserver2方式。

kyuubi 配置文件需要配置:
kyuubi.authentication=CUSTOM #自定义
kyuubi.authentication.custom.class=com.xxx.bigdata.auth.CustomPasswdAuthenticationProvider #需要自己实现密码验证kyuubi 需要新增编译的jar包,部署到kyuubi/jars/目录下
spring-security-core-4.2.3.RELEASE.jar
mysql-connector-java-5.1.39-bin.jar
kyuubi-authentication-1.0-SNAPSHOT.jar连接测试方式:
~/spark-3.1.2-bin-hadoop2.7/bin/beeline -u jdbc:hive2://dw-data-group-test.ksord.com:10001 -n test -p ****
二. kyuubi库表权限开发
1. 项目下载
下载地址:https://github.com/apache/submarine
2. 编译
mvn clean package -Dmaven.javadoc.skip=true -DskipTests -pl :submarine-spark-security -Pspark-3.0 -Pranger-2.1
建议在linux机器上编译,将编译好的jar放到 $SPARK_HOME/jars 下,改名 submarine-spark-security-.jar
3. Ranger配置
3.1 新建 $SPARK_HOME/conf/ranger-spark-security.xml , 添加配置
ranger.plugin.spark.policy.rest.url
http://ksyun-bj6c-epc-bd-hadoop-tmp-2.ksord.com:6080
URL to Ranger Admin
ranger.plugin.spark.service.name
hivedev
Name of the Ranger service containing policies for this YARN instance
ranger.plugin.spark.policy.cache.dir
./hivedew/policycache
ranger.plugin.spark.policy.pollIntervalMs
5000
ranger.plugin.spark.policy.source.impl
org.apache.ranger.admin.client.RangerAdminRESTClient
3.2 新建 $SPARK_HOME/conf/ranger-spark-audit.xml , 添加配置
xasecure.audit.is.enabled
true
xasecure.audit.destination.db
false
xasecure.audit.destination.db.jdbc.url
jdbc:mysql://localhost:3306/ranger_audit
xasecure.audit.destination.db.user
rangerlogger
xasecure.audit.destination.db.password
none
xasecure.audit.destination.db.jdbc.driver
com.mysql.jdbc.Driver
4. Spark配置
$SPARK_HOME/conf/spark-defaults.conf 添加配置
spark.sql.extensions=org.apache.submarine.spark.security.api.RangerSparkAuthzExtension5. 测试
1. 启动Kyuubi服务
$KYUUBI_HOME/bin/kyuubi start
2. Spark Beeline 链接
-u url为kyuubi的访问链接 -n 用户名称 $SPARK_HOME/bin/beeline -u jdbc:hive2://ksyun-bj6c-epc-dw-data-group-test.ksord.com:10009 -n XXX
3. 验证SQL
执行SQL,查看SQL是否执行成功或者未有权限的库表是否能查看到
6. 注意
1. hive-site.xml 配置
hive-site.xml 里不要开启hive.security.authorization.enabled 相关配置
2. Spark-authorizer
Spark-authorizer当前版本验证失败,如果服务器之前部署过Spark-authorizer,需要把Spark-authorizer相关配置及依赖清理干净
3. Submarine Spark Security Plugin 插件编译
建议在服务器上编译,在本地编译问题会比较多。 这块已咨询Kyuubi社区,预计在之后版本会将此插件集成到Kyuubi项目中
0x04 kyuubi+spark 任务调优
先贴一下kyuubi-defaults.conf的配置信息
## Kyuubi Configurations
# kyuubi.authentication NONE
kyuubi.frontend.bind.host bd-spark-01.ksord.com
kyuubi.frontend.bind.port 10009
# kyuubi ha
kyuubi.ha.enabled=true
kyuubi.ha.zookeeper.acl.enabled=false
kyuubi.ha.zookeeper.namespace=kyuubi
kyuubi.ha.zookeeper.quorum=xx.xx,xx.xx,xx.xx
kyuubi.ha.zookeeper.client.port=2181
kyuubi.ha.zookeeper.session.timeout=600000
# kyuubi pool
#kyuubi.operation.scheduler.pool=FAIR
kyuubi.backend.engine.exec.pool.size=30
kyuubi.backend.engine.exec.pool.wait.queue.size=100
# spark
spark.driver.memory=2g
spark.executor.memory=6g
spark.driver.cores=1
spark.executor.cores=3
# Overhead
spark.driver.memoryOverhead=1g
spark.executor.memoryOverhead=6g
spark.driver.maxResultSize=1g
# classpath
#spark.driver.extraClassPath=/home/hadoop/hadoop/share/hadoop/hdfs/lib/hadoop-ks3-0.1.jar
spark.driver.extraLibraryPath=/home/hadoop/hadoop/lib/native:/home/hadoop/hadoop/lib/native/Linux-amd64-64
#spark.executor.extraClassPath=/home/hadoop/hadoop/share/hadoop/hdfs/lib/hadoop-ks3-0.1.jar
spark.executor.extraLibraryPath=/home/hadoop/hadoop/lib/native:/home/hadoop/hadoop/lib/native/Linux-amd64-64
# history
spark.history.fs.cleaner.enabled=true
spark.history.fs.logDirectory=hdfs:///spark-history/
spark.history.provider=org.apache.spark.deploy.history.FsHistoryProvider
spark.history.ui.port=18081
spark.historyServer.address=ksyun-bj6c-epc-bd-hadoop-01.ksord.com:18081
spark.history.fs.cleaner.maxAge=7d
spark.history.fs.cleaner.maxNum=Int.MaxValue
spark.history.fs.cleaner.interval=1d
spark.eventLog.dir=hdfs://bjCluster/spark-history/
spark.eventLog.enabled=true
# dynamicAllocation
spark.dynamicAllocation.enabled=true
spark.shuffle.service.enabled=true
spark.shuffle.service.port=7337
# minExecutors<= initialExecutors< maxExecutors
spark.dynamicAllocation.initialExecutors=0
spark.dynamicAllocation.minExecutors=0
spark.dynamicAllocation.maxExecutors=25
spark.dynamicAllocation.executorAllocationRatio=0.5
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
spark.dynamicAllocation.executorIdleTimeout=60s
spark.dynamicAllocation.cachedExecutorIdleTimeout=30min
# true if perfer shuffle tracking than ESS
spark.dynamicAllocation.shuffleTracking.enabled=false
spark.dynamicAllocation.shuffleTracking.timeout=30min
spark.dynamicAllocation.schedulerBacklogTimeout=1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=1s
spark.cleaner.periodicGC.interval=5min
# For a user named bob
# ___bob___.spark.dynamicAllocation.maxExecutors=600
spark.master=yarn
spark.submit.deployMode=cluster
kyuubi.authentication=CUSTOM
kyuubi.authentication.custom.class=com.xxx.bigdata.auth.CustomPasswdAuthenticationProvider
# AQE
spark.sql.adaptive.enabled=true
#kyuubi.engine.event.loggers=JSON
#kyuubi.engine.event.json.log.path=file:///home/hadoop/events
# scheduler 策略
spark.scheduler.mode=FAIR
#spark.scheduler.allocation.file=/home/hadoop/kyuubi-1.3.0/conf/fairscheduler.xml
# 广播
spark.sql.autoBroadcastJoinThreshold=10M
# 资源释放时间
kyuubi.operation.query.timeout=3600000
kyuubi.session.engine.idle.timeout=PT9M
kyuubi.session.idle.timeout=PT4M
# 针对3.0之后时间解析问题
spark.sql.legacy.timeParserPolicy=LEGACY
# kyuubi metrics
kyuubi.metrics.enabled=true
kyuubi.metrics.prometheus.path=/metrics
kyuubi.metrics.prometheus.port=10019
kyuubi.metrics.reporters=PROMETHEUS
kyuubi.ha.zookeeper.session.timeout=600000
# level
# kyuubi.engine.share.level=CONNECTION
___report\_config\_dev___.kyuubi.engine.share.level=CONNECTION
# gc
#spark.driver.extraJavaOptions=-XX:+UseG1GC -javaagent:/home/hadoop/kyuubi-1.3.0/jmx_prometheus_javaagent-0.16.1.jar=3010:/home/hadoop/kyuubi-1.3.0/conf/config.yaml
spark.driver.extraJavaOptions=-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1ReservePercent=15 -XX:+DisableExplicitGC -Duser.timezone=Asia/Shanghai
spark.executor.extraJavaOptions=-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1ReservePercent=15 -XX:+DisableExplicitGC -Duser.timezone=Asia/Shanghai
#spark.yarn.am.extraJavaOptions=-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1ReservePercent=15 -XX:+DisableExplicitGC -Duser.timezone=Asia/Shanghai
# 任务优先级
#spark.yarn.priority=1这里有几点说明:
- kyuubi和spark的配置参数非常多,这里只是贴了一部分线上的信息,仅供大家参考
- kyuubi有多种连接模式,我们大部分即席场景采用session模式,批处理场景采用的connection模式,模式的选择是非常重要的,具体差异可以查询官方说明
- spark的参数调优是一个比较复杂的过程,这里我们花了很多时间,我们的原则就是闲置的时候尽量少浪费资源,繁忙的时候充分利用集群能力,提高系统吞吐量
0x05 报表平台任务迁移方案及sql兼容处理等
1.报表迁移方案
我们的方案分两步走:
1.对原有的hive SQL 统一通过spark引擎进行explain验证,把验证通过的sql后台统一转为spark引擎执行,在下一次任务执行的时候就会采用新的执行引擎运行了。
2.对于explain失败的SQL任务,我们把主动权交给用户,由用户自己去修改语法进行引擎的转换。
2.sql 兼容处理
我们做了几个方面的sql兼容工作,当需要采用spark引擎去执行任务的时候会先做sql的转换。主要有以下几个方面:
- hive SQL中的隐式注释中特殊符号比如--在spark中无法正常运行,我们会自动去除掉,在日志打印中保留
- hive SQL 中的飘号`在spark中是不支持的,需要给去掉或者替换成双引号
- 其他一些格式问题
采用上面方案我们整个迁移方案基本上对用户是无感知的,用户并不清楚他们报表的引擎已经由hive替换为了spark。
0x06 结果
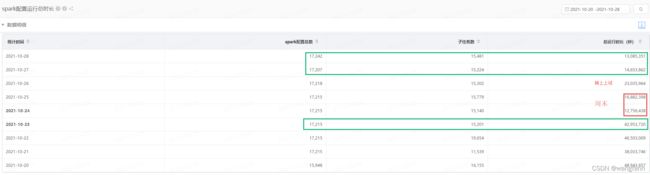
完成报表平台 3/4 hive任务的迁移,已切任务执行时间整体缩短两倍,同时集群资源预计在不影响任务执行性能的情况下可缩减1/4到1/3。
可以拿2021-10-23日的数据和10-27和20-28号的数据进行个纵向对比。
大家可以采用类似方案完成hive到spark的任务迁移。 Good Luck !!!