CPU/内存/缓存
1、CPU 和各级缓存、内存、硬盘之间的关系
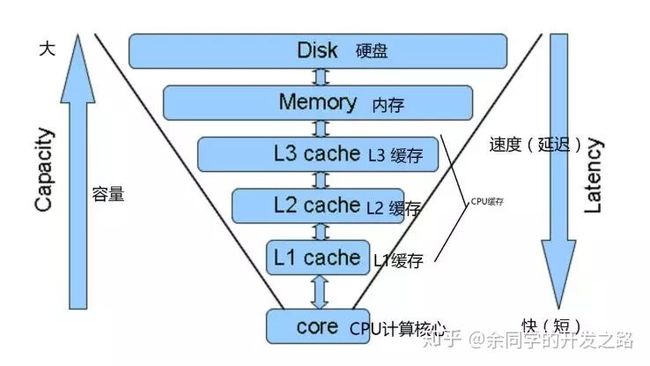
为什么会出现多级缓存呢?
说的简单一点因为 CPU 的频率太快了,而若是没有缓存,直接读取内存中的数据又太慢了,我们不想让 CPU 停下来等待,所以加入了一层读取速度大于内存但小于 CPU 的这么一层东西,这就是缓存。
加入缓存之后,CPU 需要数据就问缓存要,缓存没有就从主存中读取,并保留一份在缓存中。下次读取就从缓存中读取,加快速度。
为什么需要高速缓存
CPU 和内存访问性能的差距非常大。如今,一次内存的访问,大约需要 120 个 CPU Cycle。这也意味着,在今天,CPU 和内存的访问速度已经有了 120 倍的差距。
- CPU:按照摩尔定律,CPU 的访问速度每 18 个月便会翻一番,相当于每年增长 60%。比如我的笔记本是 Intel Core-i5-8250U 1.6GHz,也就是每秒可以访问 16 亿(= 1.6G)次。
- 内存:每年只增长 7% 左右。内存响应时间大概是 100us,也就是极限情况下,大概每秒可以访问 1000 万(= 1s / 100ns)次。
- HDD:磁盘寻道时间约 10ms,大概每秒可以访问 100 次。
图1:随着时间变迁,CPU 和内存之间的性能差距越来越大

为了弥补两者之间的性能差异,充分利用 CPU,现代 CPU 中引入了高速缓存(CPU Cache)。高速缓存分为 L1/L2/L3 Cache,不是一个单纯的、概念上的缓存(比如使用内存作为硬盘的缓存),而是指特定的由 SRAM 组成的物理芯片。
缓存行(Cache Line)
程序运行的时间主要花在将对应的数据从内存中读取出来,加载到 CPU Cache 里。CPU 从内存中读取数据到 CPU Cache 的过程中,是一小块一小块来读取数据的。这样一小块一小块的数据,在 CPU Cache 里面,我们把它叫作缓存行(Cache Line)。在我们日常使用的 Intel 服务器或者 PC 里,Cache Line 的大小通常是 64 字节。
现在总结一下,为了平衡 CPU 和内存的性能差异,现在 CPU 引入高速缓存:
- 高速缓存(CPU Cache):用于平衡 CPU 和内存的性能差异,分为 L1/L2/L3 Cache。其中 L1/L2 是 CPU 私有,L3 是所有 CPU 共享。
- 缓存行(Cache Line):高速缓存的最小单元,一次从内存中读取的数据大小。常用的 Intel 服务器 Cache Line 的大小通常是 64 字节。
高速缓存读操作
CPU Cache 和 Redis 缓存访问类似,都是先访问缓存,如果数据不存在再访问内存。在各类基准测试(Benchmark) 和实际应用场景中,CPU Cache 的命中率通常能达到 95% 以上。
CPU Cache 和 Redis 缓存架构类似


磁盘缓存
提到磁盘缓存,应该有不少人会想到CPU缓存,CPU缓存主要是为了解决速度匹配问题,因为CPU快内存慢,为了缩小速度差距带来的问题引入了缓存,这里的快慢主要针对的是对于数据的读取。
那啥是磁盘缓存呢?
会不会有人觉得磁盘缓存在磁盘里?其实不是,磁盘缓存不是在磁盘中,而是在内存中。
对了,我觉得这里非常有必要说下,我们这里说的磁盘,一般就是指的咱们电脑上的硬盘,Windows电脑中的什么C盘,D盘这些,我们的大部分数据信息也都是保存在这上面的。
其实磁盘缓存和CPU缓存的机制差不多。
磁盘缓存是把从磁盘中读取到的数据保存到内存中,下次读取该数据的饿时候不会再从磁盘中去读取,而是直接从内存中读取
缓存概念的扩充
所以啊,对于现在的缓存,不仅CPU和内存之间有CPU缓存,在内存和磁盘之间也存在我们这次说的磁盘缓存,甚至在硬盘和网络之间也存在缓存,比如网络内容缓存。
这里举个例子吧,比如我们上网浏览一张图片,第一次浏览加载该图片的时候其实是比较慢得,但是我们下次再次打开该网的这个图片,速度就会快很多,那是因为这张图片数据保存在了我们的硬盘上,再次读取是直接从我们的硬盘上读取,而不是从服务器上拉取了。
所以啊,看了那么多,其实缓存这玩意就是把低速设备的数据保存在高速设备上,需要的时候直接从高速设备上将其读取。
不读入内存就无法运行?
这是咋回事,相信看了我之前几篇分析CPU和内存的文章就知道我这里说的什么意思了,CPU被设计成只能从内存中读取数据来运行相关程序,而内存中的数据是哪里来的呢?
我们平常写的程序啥的都是保存在本地硬盘中,好吧,是磁盘,我们上面说的磁盘,但是你得知道磁盘和硬盘他们之间啥关系啊。
要想这个程序被运行,那么首先需要把这段程序数据加载进内存,只有进了内存才能被CPU读取运行啊,也就是这么个图:

虚拟内存
虚拟机内存是把磁盘的一部分作为假想的内存来使用
听起来有点魔幻,不是那么好理解,不直观,首先虚拟内存肯定不是真的内存,虽然不是真的是虚拟的,但是人家也叫内存,所以,虚拟内存能够起到内存的一些作用,啥意思嘞?
我们知道,程序需要加载进内存供CPU读取运行,如果内存空间不够,如何运行大内存程序呢?
比如说现在内存空间仅剩10M,但是现在有个大小20M的程序需要运行,在没有虚拟内存的情况下,这个程序是无法被运行的,但是有了虚拟内存就可以,虚拟内存通过特定技术把磁盘中的一部分容量作为内存来使用,也就是说会把这个20M大小的程序的部分数据存放在磁盘中的这块虚拟内存中,然后在真正的内存中也存放部分这个程序的数据,在运行这个程序的时候,如果所需要的数据没有在内存中,而是在磁盘中的虚拟内存中,那么就会发生数据交换,把虚拟内存中需要现在用到的数据与内存中这段程序暂时不用的数据进行交换,以此来保证程序的正常运行。
这,就是虚拟内存了。
2、SRAM和DRAM
SRAM和DRAM都是RAM
中文名叫随机存储器,随机是什么意思呢? 意思是, 给定一个地址, 可以立即访问到数据(访问时间和位置无关), 而不像咱们熟悉的磁带, 知道最后一首歌在最后的位置, 却没法直接一下子跳到磁带的最后部门, 所以磁带不是随机存储器, 而是顺序存储器。
来看看SRAM的电路:

上面是能保存SRAM的一个bit,你看看, 这东东, 保存一个bit需要6个晶体管, 所以贵, 造价高啊。 SRAM一般只有几个MB而已, 再多了就不划算, 因为贵! 从电路图可以看出, 基本都是一些晶体管运算, 速度很快, 所以SRAM一般用来做高速缓存存储器, 既可以放在cpu芯片上, 也可以放在片下。 SRAM中的S是static的意思。
看看DRAM电路图:
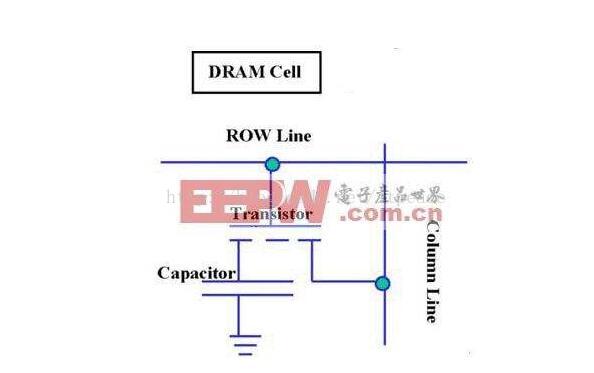
可以看到, 存储一个bit的DRAM只需要一个电容和一个晶体管。 DRAM的数据实际上是存在于电容里面的, 电容会有电的泄露, 损失状态, 故需要对电容状态进行保持和刷新处理, 以维持持久状态, 而这是需要时间的, 所以就慢了。 这个刷新加动态刷新, 而DRAM中的D就是dynamic的意思。
DRAM和SRAM区别
DRAM比SRAM要慢, 但造价更低, 容量也比SRAM大得多, 在计算机中主要用来做内存, 物尽其用。
SRAM 是英文 Static RAM 的缩写,它是一种具有静志存取功能的存储器,不需要刷新电路即能保存它内部存储的数据。不像 DRAM 内存那样需要刷新电路,每隔一段时间,固定要对 DRAM 刷新充电一次,否则内部的数据即会消失,因此 SRAM 具有较高的性能,但是 SRAM 也有它的缺点,即它的集成度较低,相同容量的 DRAM 内存可以设计为较小的体积,但是 SRAM 却需要很大的体积,这也是目前不能将缓存容量做得太大的重要原因。这中间也解释了为什么内存中的数据一断电就没有了。
RAM工作原理
这里涉及地址总线:传输地址信号和数据总线:传输数据。
RAM(随机读写存储器)的工作原理大致是当 CPU 读取主存时,将地址信号放到地址总线上传给主存,主存读到地址信号后,解析信号并定位到指定存储单元,然后将此存储单元数据放到数据总线上返回给 CPU。
我们为了提高 CPU 的利用率,添加了多级缓存,但是呢,数据的读取和保存都要在主存上进行
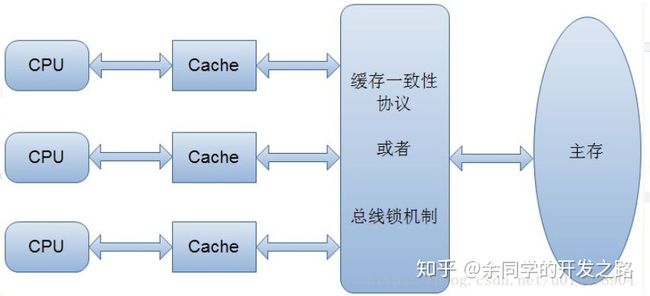
解决缓存一致性的方案
总线锁机制 或 MESI
MESI
在多线程的情况下就会出现问题,因为每个线程都有自己的缓存,假如线程 1 从主存中读取到 x,并对其加 1 ,此时还没有写回主存,线程 2 也从主存中读取 x ,并加 1 ,它们是不知道对方的,也不可以读取对方的缓存。这时都将 x 写回主存,那此时 x 的值就少了 1 。
这也就是多线程情况下带有缓存的问题,数据出现问题了,怎么办呢?不能把缓存去掉吧,这时就需要一种协议,来保证不同的线程在读写主存数据时遵守某种规则以保证不会出现数据不一致的问题。这种协议有很多,其中用的比较多的是 MESI 协议,主要用来保证缓存的一致性。
MESI 为了保证多个缓存中共享数据的一致性,定义了 cache line 的四种状态,而线程对 cache line 的四种操作可能会产生不一致的状态,因此缓存控制器监听到本地操作和远程操作的时候,需要对地址一致的 cache line 状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。
(M: modified E: Exclusive S: shared I: invalid)
CPU 中每个缓存行(caceh line)使用 4 种状态进行标记(使用额外的两位(bit)表示)。
M: 被修改(Modified):读取并修改
该缓存行只被缓存在该 CPU 的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它 CPU 读取主存中相应内容之前)写回主存。当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
E: 独享的(Exclusive):写回
该缓存行只被缓存在该 CPU 的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它 CPU 读取该内存时变成共享状态(shared)。同样地,当 CPU 修改该缓存行中内容时,该状态可以变成 Modified 状态。
S: 共享的(Shared):其他cpu读取
该状态意味着该缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个 CPU 修改该缓存行中,其它 CPU 中该缓存行可以被作废(变成无效状态)。
I: 无效的(Invalid):其他cpu修改
该缓存是无效的(可能有其它 CPU 修改了该缓存行)。
cache line 不同的状态之间可以相互转化,这也就是 MESI 协议的具体内容,比方说一个处于 M 状态的缓存行必须时刻监听所有试图读该缓存行相对应主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成 S 状态之前被延迟执行。
CPU 中的乱序执行优化
处理器为提高运算速度而做出违背代码原有顺序的优化。虽然顺序变了,但是执行的结果是不会变的。
举个例子,我要去买杯饮料喝,正常逻辑是这样的,去店里->点单->付钱->喝饮料。那其实我还可以在去店里的路上同时就把【点单付钱】一起搞定,又或者我先【点单】再去店里付钱拿饮料。
类比到 CPU 中也是这样,求 x + y = ? 我计算 x 的值,再计算 y 的值,其实可以一起执行,或是先计算 y 的值,当然为了提高运算速度,它会同时计算 x 和 y 的值,一个 CPU 中又不是只有一个逻辑计算的单元。
乱序优化就是这样,为了提高效率 CPU 做出的优化,这在单核的时候是不会有问题的,但是在多核时代又会出现问题。
再举个例子,线程 1 需要借组一个 flag 变量执行一段逻辑,你能用 C线程 2 来乱序优化一下,先执行逻辑而不看 flag 变量的值?这是肯定不行的。
行还是不行肯定有一套规则,这套规则也就是内存屏障
4、系统调用
进程在系统上运行分为两个级别
用户态(user mode):在用户态运行的进程可以直接读取用户程序的数据。
系统态(kernel model):在系统态运行的程序可以访问计算机的任何资源不受限制。
平常我们运行的程序都是用户态的,想要将进程运行在系统态则需要利用系统调用。
系统调用
在我们运行的用户程序中,凡是与系统级别有关的操作(例如文件管理、内存管理、进程控制)都必须通过系统调用方式向OS提出服务请求,并由OS代为完成。平常我门的进程几乎都是用户态,读取用户数据,当涉及到系统操作,计算机资源的时候就要用到系统调用了
系统调用功能
- 设备管理:完成设备的请求/释放以及设备的启动
- 文件管理:完成文件的读写、删除、创建等功能
- 进程控制:完成进程的创建、撤销、阻塞以及唤醒等功能
- 内存管理:完成内存的分配、回收以及获取作业占用内存区大小和地址等功能
引用:https://zhuanlan.zhihu.com/p/55429568
https://zhuanlan.zhihu.com/p/106297543
https://blog.csdn.net/qq_31877171/article/details/100983891