SQL语言的基础知识
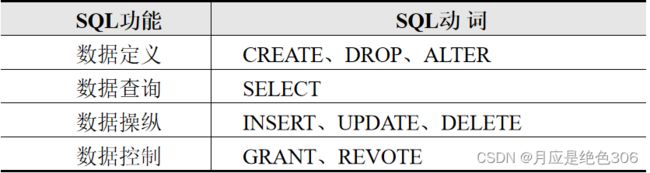
SQL (Structured Query Language) 是具有数据操纵和数据定义等多种功能的数据库语言是通用的、功能极强的关系DB语言。
SQL不仅具有丰富的查询功能还具有数据定义和数据控制功能,是集数据定义语言(DDL)、数据查询语言(DQL)、数据操纵语言(DML)、数据控制语言(DCL)于一体的关系数据语言。
需要了解的一些知识(在此不做拓展,仅提示):
1.oracle支持的数据类型
2.where<条件表达式内容>(查询条件和谓词)
3.嵌套查询子查询中的运算符
4.oracle常用函数
1.数据定义
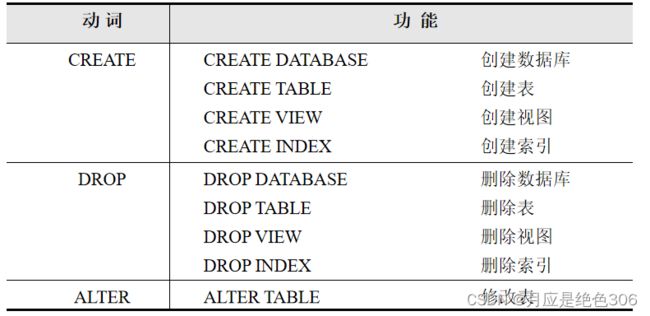
通过SQL语言的数据定义功能,可以完成数据库、基本表、视图以及索引的创建和修改。通过CREATE、DROP、ALTER3个核心动词完成数据定义功能。
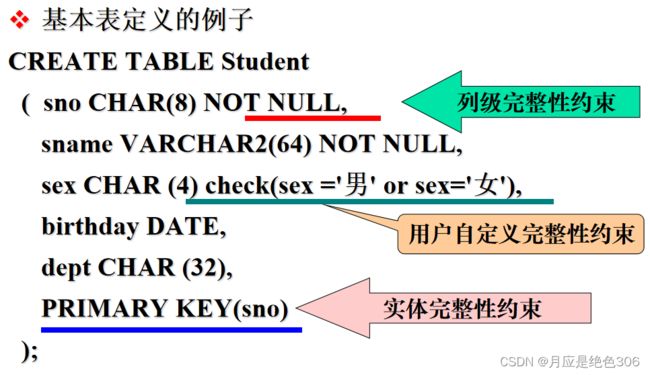
基本表的定义及其例子:
--基本表的定义
CREATE TABLE <表名>(
<字段名1> <字段数据类型> [列完整性约束],
<字段名2> <字段数据类型> [列完整性约束],
……
[表级完整性约束]
);
--基本表定义的例子
--建立学生信息表student
CREATE TABLE student(
sno NUMBER(8) NOT NULL,
sname VARCHAR2(64) NOT NULL,
sex CHAR(4) DEFAULT '男',
birthday DATE, --Orcal中DATE类型是DD-MON-YY;DATE在其他数据库中可能是YYYY-MM-DD
address VARCHAR2(256)
);
--创建表格学生表,有两个属性XH,MM。要求XH以2022开始共10位数字;MM为长10位的字符(包括字母和数字);
CREATE TABLE Student(
XH CHAR(10) CHECK (regexp_like(XH, '^[2][0][2][2][0-9]{6}+$')),
MM VARCHAR(10) CHECK (regexp_like(MM, '^[A-Za-z0-9]{10}+$'))
);
解析基本表定义的例子:

基本表的修改:
--基本表修改的定义
ALTER TABLE <基本表名>
[ADD <新列名> <列数据类型> [列完整性约束]]
[DROP COLUMN <列名>]
[MODIFY <列名> <新的数据类型>]
[ADD CONSTRAINT <表级完整性约束>]
[DROP CONSTRAINT <表级完整性约束>]
--基本表修改的例子
--例 在student表中增加一个age列(年龄)。
ALTER TABLE student
ADD age NUMBER(4) NULL;
--例 修改student表中dept列为CHAR(16)。
ALTER TABLE student
MODIFY dept CHAR(16);
--例 删除student表中新增的age列。
ALTER TABLE student
DROP COLUMN age;
--基本表的删除
--例 删除student表
DROP TABLE student;
2.数据查询
SQL数据查询是SQL语言中最重要、最丰富也是最灵活的内容。
--SELECT语句的语法
SELECT [ALL|DISTINCT] <列名或表达式> [别名1],<列名或表达式> [别名2]…
FROM <表名或视图名> [表别名1],[<表名或视图名> [表别名2]]…
[WHERE <条件表达式>]
[GROUP BY <列名>,<列名>…[HAVING<条件表达式>]]
[ORDER BY <列名> [ASC|DESC] ,<列名> [ASC|DESC]…
--简化
SELECT 目标列
FROM 基本表(或视图)
[WHERE 条件表达式]
[GROUP BY 列名1[HAVING 内部函数表达式]] --分组查询,所有的集函数都将是对每一个组进行运算
[ORDER BY 列名2 [ASC、DESC] --排序查询,按顺序排列
查询列中含有聚合函数
COUNT(*) 统计查询结果中的元组个数
COUNT(<列名>) 统计查询结果中一个列上值的个数
MAX(<列名>) 计算查询结果中一个列上的最大值
MIN(<列名>) 计算查询结果中一个列上的最小值
SUM(<列名>) 计算查询结果中一个数值列上的总和
AVG(<列名>) 算查询结果中一个数值列上的平均值
① 除COUNT(*)外,其他集函数都会先去掉空值再计算。
② 在<列名>前加入DISTINCT保留字,会将查询结果中重复的行去掉后再计算。
SELECT COUNT(*) FROM dept
集合运算查询:UNION,INTERSECT,MINUS
实例:
--查询工资在1000到2000之间的员工
SELECT ename FROM emp WHERE sal>=1000 AND sal<=2000;
--查询工资在1000到2000之间的员工,使用BETWEEN…AND:
SELECT ename FROM emp WHERE sal BETWEEN 1000 AND 2000;
--查询其姓名在指定集合之中的员工:
SELECT ename FROM emp WHERE ename IN ('SMITH','FORD','HELLO');
--将学生按照总学分进行分组,查询至少包含两个年龄大于20岁的同学的分组总学分信息
select zxf
from xsb
where age>20
--若题目没直接给年龄,给了出生日期
--WHERE (extract(YEAR FROM sysdate) - extract(YEAR from cjrq) ) >20
group by zxf
having count(*)>1;
--要对公司各部门的工资统计情况进行排序,要求是按照工资总和从大到小排序,
--如果工资总和相同,再按照部门号从小到大排序。
SELECT deptno AS 部门号, AVG(sal) AS 平均工资, MIN(sal) AS 最低工资, MAX(sal) AS 最高工资, SUM(sal) AS 工资总和
FROM emp
GROUP BY deptno
ORDER BY SUM(sal) DESC, deptno ASC
--多表查询
--查询选修了‘数据库’课程的学生学号和姓名
select x.xh,x.xm
from xsb x,kcb k,cjb c
where x.xh=c.xh and k.kch=c.kch and k.kcm='数据库';
--自连接
--查询至少选修两门课程的学生学号
SELECT C1.xh
FROM CJB C1, CJB C2
WHERE C1.xh = C2.xh AND C1.kch !=C2.kch
--法二
SELECT xh
FROM CJB
GROUP BY xh
HAVING count(*)>1
--嵌套查询
--查询选修了101101课程的学生学号和姓名
--1.非关联嵌套查询
SELECT X.xh, X.xmFROM XSB X
WHERE X.xh IN
(SELECT C.xh
FROM CJB C
WHERE C.kch=101101)
--2.关联嵌套查询
SELECT X.xh, X.xm
FROM XSB X
WHERE EXISTS
(SELECT *
FROM CJB C
WHERE C.kch=101101
AND X.xh=C.xh)
注意:
1.自然连接(natural join)是一种特殊的等值连接,他要求两个关系表中进行连接的必须是相同的属性列(名字相同),无须添加连接条件,并且在结果中消除重复的属性列。
2.嵌套查询是指嵌套在另一个SELECT语句中的查询。在SELECT语句中,WHERE子句或者HAVING子句中的条件往往不能用一个确定的表达式来确定,而要依赖于另一个查询,这个被嵌套使用的查询称为子查询,它在形式上是被一对圆括号限定的SELECT语句。在子查询中还可以再嵌套子查询。 嵌套查询是由里向外处理的,这样外层查询可以利用内层查询的结果。
3.同样地,FROM和HAVING中也可以嵌套子查询
3.数据操作
SQL语言的数据操纵功能主要包括插入(INSERT)、删除(DELETE)和更新(UPDATE)3个方面。借助相应的数据操纵语句,可以对基本表中的数据进行更新,包括向基本表中插入数据、修改基本表中原有数据、删除基本表的某些数据。
插入数据:
1.插入单个元组:
INSERT INTO <基本表名> [(<字段名1>, <字段名2>,…, <字段名n>)]
VALUES(<表达式1>,<表达式2>,…,< 表达式n>)
--VALUES后则一一对应要添加字段的输入值。
--要往dept表中插入一条新记录,部门号为50,部门名称为NETWORK,部门地址为BEIJING,相应的INSERT语句为:
INSERT INTO dept(deptno,dname,loc) VALUES(50, 'NETWORK', 'BEIJING');
INSERT INTO dept VALUES(50, 'NETWORK', 'BEIJING');
2.插入多个元组
INSERT INTO <基本表名> [(<字段名1>,<字段名2>,…,< 字段名n>)] <子查询>
--假设有一个表emp1,它的结构与emp相同,现在希望从表emp中将部门10和部门20的员工数据复制到表emp1中
INSERT INTO emp1(empno,ename,deptno,sal,hiredate)
SELECT empno,ename,deptno,sal,hiredate FROM emp WHERE deptno=10 or deptno=20;
修改数据:
UPDATE <基本表名>
SET <字段名1> = <表达式1> [,<字段名2> = <表达式2>][,…n]
[WHERE <条件>]
--将 “王林”同学在001课程的成绩修改为75
UPDATE CJB
SET cj = 75
WHERE kch = ‘001’ AND xh =
(SELECT xh
FROM XSB
WHERE xm = ‘王林’)删除数据:
DELETE FROM <表名>[WHERE <条件>]
DELETE FROM XSB WHERE xh=100111
4.数据控制
SQL授权语句的一般格式为:
GRANT 权限,[权限] ···
[ON 对象类型 对象名]
TO 用户[,用户]···;
[WITH GRANT OPTION];
把查询、插入、更新、删除 XSB表的权力授给(剥夺)王平
GRANT select, insert, update, delete on XSB to Wangping
REVOKE select , insert, update, delete on XSB from Wangping
5.数据查询问题
--查询总学分高于’王林’ 的学生学号和姓名(考虑同名情况)
select x1.xh,x1.xm
from xsb x1
where zxf>any(
select x2.zxf
from xsb x2
where x2.xm='王林');
--查询总学分最高的学生学号和姓名
select x1.xh,x1.xm
from xsb
where zxf>all(
select x2.zxf
from xsb x2)
--查询选修了所有课程的学生学号和姓名
select x1.xh,x1.xm
from xsb x1
where not exists(
(select k.kch
from kcb k)
minus
(select c.kch
from cjb c
where c.xh = x1.xh));
--将学生按照总学分进行分组,查找那些至少有两位同学的分组中大于18岁的最年轻的同学的年龄
SELECT X.zxf, MIN (X.age) FROM XSB X
WHERE X.age > 18
GROUP BY X.zxf
HAVING (SELECT COUNT(*)
FROM XSB X1
WHERE X1.zxf = X.zxf) >1
--将学生按照总学分进行分组,查询至少包含两个年龄大于18岁的同学的分组信息
SELECT zxf
FROM XSB
WHERE age > 18
GROUP BY zxf
HAVING COUNT(*) > 1
--GROUP BY分组查询,SELECT子句后的字段必须包含GROUP BY后的分组字段
--GROUP BY子句通常与集合函数一起使用
SELECT X.xh, X.xm, AVG (C.cj)
FROM XSB X, CJB C
WHERE X.xh = C.xh
GROUP BY X.xh, X.xm