离线数仓分析
离线数仓分析
第一步、获取数据源
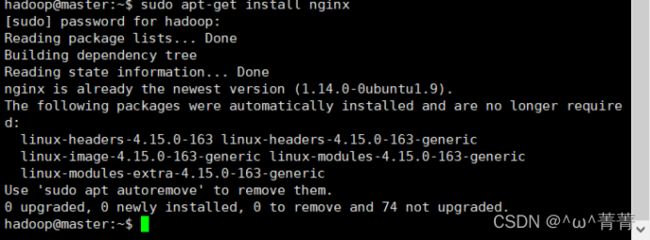
(1)安装nginx
(2)上传shop.html文件到/var/www/html目录

(3)在浏览器通过192.168.1.11(自己的id)/shop.html访问网页产生日志


(4)监控nginx生成的访问日志:sudo tail -F /var/log/nginx/access.log

第二步、Flume采集日志到HDFS
准备工作:
1、开启三台虚拟机

2、开启三个节点的zookeeper的服务

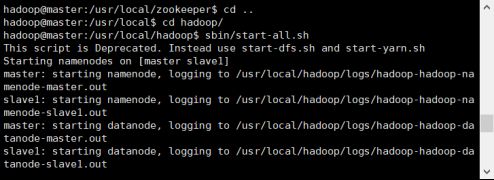
3、在master开启hadoop和yarn

(1)创建/home/hadoop/web_log目录

(2)进入/home/hadoop/web_log目录
![]()
(3)创建nginx_memory_hdfs.properties文件并填写

(4)使用nginx_memory_hdfs.properties文件启动Flume

(5)去HDFS检查日志数据是否采集到/web/log目录

第三步、ETL清洗数据(脏数据)
(1)在eclipse连接hadoop,通过xshell进行连接,并进行可视化

(2)在eclipse创建ETL mapreduce项目,创建一个hive包,写项目

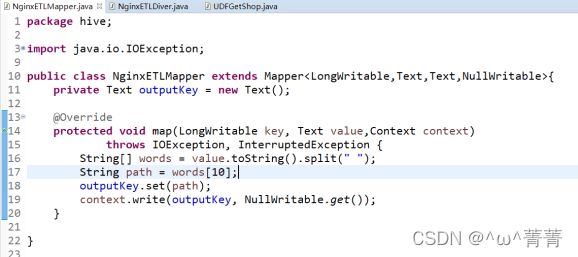
(3)在eclipse编写NginxETLMapper和NginxETLDriver这两个类

(4)打包上传文件到/home/hadoop/web_log目录下(这个时候要注意打包方式,不然会报main的错)

(5)执行jar包:hadoop -jar/home/hadoop/web_log/NginxETL.jar 22-02-22 12(年-月-日 时间)(这个时间是你HDFS上的日志文件数据)

(6)在hdfs上查看,路径是自己eclipse上Driver(测试类上的路径)(/web/log/etl)

(7)创建脚本web_log_etc.sh并执行

第四步、搭建数据到仓库(离线数仓)处理数据的时效性可以分为(离线和实时)
数仓分层,分为四层:
Ods:储存清洗后的日志数据
Dwd:从ods种提取出待分析时间段的数据
Dws:从dwd中提取出商品名称的数据
Ads:基于dws的分析结果
为什么要数仓分层?
1.把复杂的问题简单化
2.数据结构清晰
3.提高数据的复用性
4.隔离原始数据
(1)创建web_log_import.sh脚本并填写

(2)创建web_log_analysis.sh脚本并填写

(3)编写udf函数

(4)把udf函数打成jar包进行上传到/home/hadoop/web_log

(5)执行两个脚本文件(web_log_import.sh和web_log_analysis.sh)

**注意在执行第二个脚本的时候,hdfs上的数据不能多于7条,否则报错
当master namenode宕机时,在slave1杀死namenode节点再重启namenode
Kill -9 **(节点前的数字)
Hadoop-daemon.sh start namenode
第五步、保存分析结果
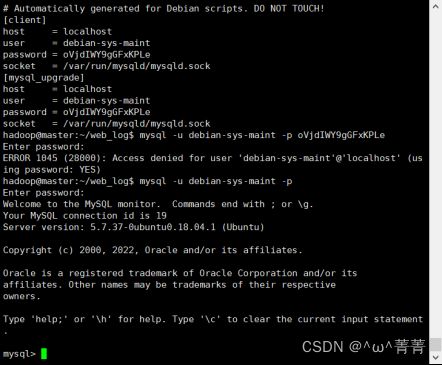
(1)查看mysql数据库账号密码:sudo cat /etc/mysql/debian.cnf

(2)进入mysql:mysql -u debian-sys-maint -p密码
(3)创建web_log用户,并设置密码为123456
![]()
(4)授予web_log用户操纵web_log数据库的权限并刷新

(5)退出MySQL使用web_log用户登录,并使用数据库

(6)创建shop_count_rank表,存储hive导出的数据(增量导入)增量导入的基础是全量导入

增加导入hive数据到MySQL

导入后查看表中数据

(7)创建脚本web_log_export.sh(全量导入)

第六步、定时任务
使用crontab-e命令来添加定时任务(选择第三个vim编译器)
为脚本添加上要使用的环境变量
