使用gym创建一个自定义环境
1. 环境说明
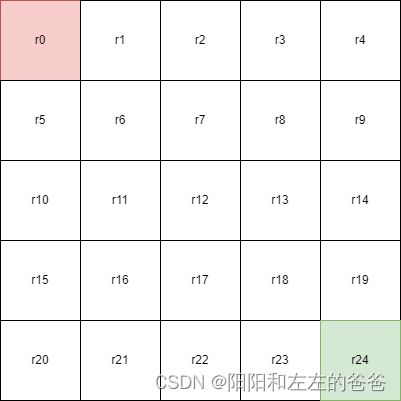
如上图,红色为起点,绿色为终点,在5*5的表格中每到达一个表格就会获得该表格对应的分数rn,agent的目标就是 找到一条路来使分数最少:)。
2. 创建环境
标准的gym环境可以分为以下几个部分,这里借鉴了gym的cliff_walking环境:
class my_env(Env):
def __int__(self):
pass
def step(self.action):
pass
def render(self):
pass
def reset(self):
pass
其中__init()用来创建动作空间,观察空间等等:
def __init__(self):
self.rows = 5 #行
self.cols = 5 #列
self.start = [0, 0] #起点
self.goal = [3, 4] #目标点
self.current_state = None #当前状态
self.action_space = spaces.Discrete(3) #动作空间,离散的三个动作0,1,2
self.observation_space = spaces.Box(low=np.array([0, 0]), high=np.array([4, 4]))#观察空间,这里为agent的坐标step(self.action)用来定义智能体的动作:
def step(self, action):
new_state = deepcopy(self.current_state)
if action == 0 : #上
new_state[0] = max(new_state[0] - 1, 0)
elif action == 1: #前
new_state[1] = min(new_state[1] + 1, self.cols - 1)
elif action == 2: #下
new_state[0] = min(new_state[0] + 1, self.rows - 1)
else:
raise Exception("Invalid action")
self.current_state = new_state
if (self.current_state[1]-self.goal[1]) ** 2 + (self.current_state[0]- self.goal[0]) ** 2 == 0:#到达终点则游戏结束
done = True
reward = EachReward(current_state=self.current_state, rows=self.rows, cols=self.cols)
else:
done = False
reward = EachReward(current_state=self.current_state, rows=self.rows, cols=self.cols)
info = {}
return self.current_state, reward, done, info其中EachReward函数为自己定义的函数,具体为根据当前坐标获取分数:
import numpy as np
p = np.random.uniform(0, 1, size=(5, 5))
def EachReward(current_state,rows,cols):
current_reward = p[current_state[0], current_state[1]]
return current_rewardrender()为是否可视化,这里不作改动,
reset()为重置:
def reset(self):
self.current_state = self.start
return self.current_state3. 完整代码
import gym
from gym import Env
from gym import spaces
import numpy as np
import random
from copy import deepcopy
from envs.build_problems import *
class PathPlanning(Env):
def __init__(self):
self.rows = 5
self.cols = 5
self.start = [0, 0]
self.goal = [3, 4]
self.current_state = None
self.action_space = spaces.Discrete(3)
self.observation_space = spaces.Box(low=np.array([0, 0]), high=np.array([4, 4]))
def step(self, action):
new_state = deepcopy(self.current_state)
if action == 0 : #up
new_state[0] = max(new_state[0] - 1, 0)
elif action == 1: #forward
new_state[1] = min(new_state[1] + 1, self.cols - 1)
elif action == 2: #down
new_state[0] = min(new_state[0] + 1, self.rows - 1)
else:
raise Exception("Invalid action")
self.current_state = new_state
if (self.current_state[1]-self.goal[1]) ** 2 + (self.current_state[0]- self.goal[0]) ** 2 == 0:
done = True
reward = 10.0
else:
done = False
reward = EachReward(current_state=self.current_state, rows=self.rows, cols=self.cols)
#print("the reward of the current state %a is %s" % (self.current_state, reward))
info = {}
return self.current_state, reward, done, info
def render(self):
pass
def reset(self):
self.current_state = self.start
return self.current_state