Gym入门&自定义环境操作
文章目录
- 一、Gym是什么?
- 二、使用步骤
-
- 1.成分简介
-
- (1)环境生成
- (2)环境初始化
- (3)进行迭代循环
- (4)最后关闭环境
- 2.构建环境
-
- (1)进行初始化
- (2)定义reset函数
- (3)定义step函数
- (4)定义render函数
- (5)写个策略
一、Gym是什么?
gym 是进行强化学习的一个python应用包。其中包括很多包括游戏、方格等可以以马尔可夫决策过程表示的各种事件集合。并且提供了更新、状态标识、显示等一系列方便的接口,并可以自主设计各类环境。具体库参考可见Gym。
二、使用步骤
1.成分简介
代码如下(示例):
import gym
env=gym.make(id="GridWorld",render_mode="human")
observation,info=env.reset(seed=10)
for i in range(50):
action=greedy_policy(observation)
observation,reward,terminated,truncated,info=env.step(action)
if terminated or truncated:
observation,info=env.reset()
time.sleep(0.5)
env.close()
(1)环境生成
在引入gym包之后,需要通过
env=gym.make()
函数来生成相应的环境。其中参数id代表着使用者所需的环境,可以通过
print(gym.env.register.all())
来查看。
(2)环境初始化
通过
env.reset()
来初始化所生成的环境。如果没有初始化,那么当前环境的状态可能为空,从而不能进行下一步的行动。
(3)进行迭代循环
我们知道,除了直接求解贝尔曼方程,其他方式求解马尔可夫决策过程(MDP)都是需要进行迭代求解的。因此,无论采用什么样的策略,我们都是需要一个最基本的循环。循环中包括状态生成动作,以及动作生成状态,还有到达终止状态时需要采取的操作。
for i in range(50):
action=greedy_policy(observation)
observation,reward,terminated,truncated,info=env.step(action) #Observation等同于强化学习中的state,
if terminated or truncated:
observation,info=env.reset()
time.sleep(0.5)
(4)最后关闭环境
env.close()
2.构建环境
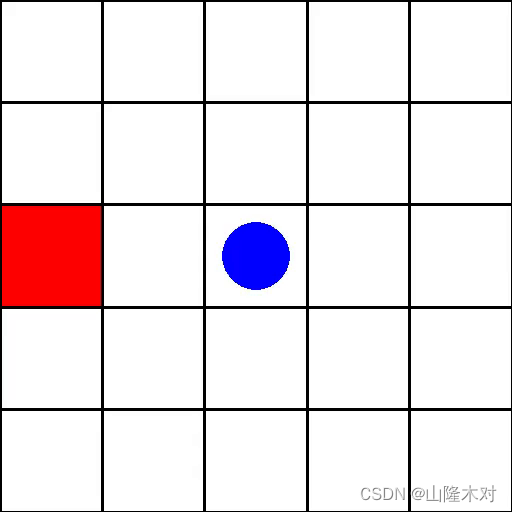
构建自己的环境需要继承gym.Env类,本文所展示的是gym官网中的案例,其使用了pygame来勾画了一个在方格中追逐目标的动态过程。如下图
class GridWorldEnv(gym.Env):
(1)进行初始化
之后,在初始化函数中初始化所需要的各种变量,其中self.observation_space和self.action_space量个变量是必须进行赋值的。
class GridWorldEnv(gym.Env):
metadata = {"render_modes":["human","rgb_array"],"render_fps":4} #这个metadata用于保存render(启动画面,下文会提到)的参数
def __init__(self,render_mode=None,size=5):
self.size=size #The size of the square grid
self.window_size=512 #The size of the PyGame window
#Obervations are dictionaries with the agent's and the target's loaction
#Each location is encoded as an element of {0,...,'size'}^2,i.e. MultiDiscrete([size,size])
self.observation_space=spaces.Dict(
{
"agent":spaces.Box(0,size-1,shape=(2,),dtype=int),
"target": spaces.Box(0, size - 1, shape=(2,), dtype=int)
}
)
#We have 4 actions,corresponding to "right,left,up,down"
self.action_space=spaces.Discrete(4)
self._action_to_direction={
0:np.array([1,0]),
1:np.array([0,1]),
2:np.array([-1,0]),
3:np.array([0,-1])
}
assert render_mode is None or render_mode in self.metadata['render_modes']
self.render_mode=render_mode
"""
If human-rendering is used, `self.window` will be a reference
to the window that we draw to. `self.clock` will be a clock that is used
to ensure that the environment is rendered at the correct framerate in
human-mode. They will remain `None` until human-mode is used for the
first time.
"""
self.window=None
self.clock=None
(2)定义reset函数
上边提到,reset函数用于整个环境状态的初始化,如果没有reset的函数,环境将处于无状态的情况,也没法进行下一步的step。
def reset(self,seed=None,options= None,) :
#We need to following line to seed self.np_random
super(GridWorldEnv, self).reset(seed=seed)
#Choose the agent's location uniformly at random
self._agent_location=self.np_random.integers(0,self.size,size=2,dtype=int)
#We will sample the target's location randomly until it does not coincide with the agents's location
self._target_location=self._agent_location
while np.array_equal(self._agent_location,self._target_location):
self._target_location=self.np_random.integers(0,self.size,size=2,dtype=int)
observation=self._get_obs()
info=self._get_info()
if self.render_mode=="human":
self._render_frame()
return observation,info
(3)定义step函数
step函数是action→observation之间的一个映射函数,通过做出动作action,将获得一个怎样的observation以及相应的reward,并判断是否到达终点状态(terminated),并将相应的信息返回。
def step(self, action):
#Map the action to the direction we walk in
direction=self._action_to_direction[action]
#We use np.clip to make sure we don't leave the grid
self._agent_location=np.clip(self._agent_location+direction,0,self.size-1)
terminated=np.array_equal(self._agent_location,self._target_location)
reward=1 if terminated else 0
observation=self._get_obs()
info=self._get_info()
if self.render_mode=="human":
self._render_frame()
return observation,reward,terminated,False,info
(4)定义render函数
render函数是一个用来展示效果画面的一个函数,如果你不需要相应的动画或者图像演示,那么可以不去定义它,而直接打印step函数的返回值来判断相应的状态变化。本案例是利用pygame中的接口来生成一个5*5的方格,并定义一个圆球去追方块,追到了就获得奖励1。
def render(self):
if self.render_mode=="rgb_array":
return self._render_frame()
def _render_frame(self):
if self.window is None and self.render_mode=="human":
pygame.init()
pygame.display.init()
self.window=pygame.display.set_mode((self.window_size,self.window_size))
if self.clock is None and self.render_mode=="human":
self.clock=pygame.time.Clock()
canvas=pygame.Surface((self.window_size,self.window_size))
canvas.fill((255,255,255))
pix_square_size=(self.window_size/self.size) #Size of single grid square in pixels
#First we draw the target
pygame.draw.rect(canvas,(255,0,0),pygame.Rect(pix_square_size*self._target_location,(pix_square_size,pix_square_size)))
#Then draw the agent
pygame.draw.circle(canvas,(0,0,255),(self._agent_location+0.5)*pix_square_size,pix_square_size/3)
#Finally,add some gridlines
for x in range(self.size+1):
pygame.draw.line(
canvas,0,(0,pix_square_size*x),(self.window_size,pix_square_size*x),width=3
)
pygame.draw.line(
canvas,
0,(pix_square_size*x,0),(pix_square_size*x,self.window_size),width=3
)
if self.render_mode=="human":
#The following line copies our drawing from 'canvas' to the visible window
self.window.blit(canvas,canvas.get_rect())
pygame.event.pump()
pygame.display.update()
#We need to ensure that human-rendering occurs at the predefined framerate.
#The following line will automatically add a delay to keep the framerate stable
self.clock.tick(self.metadata["render_fps"])
else:#rgb_array
return np.transpose(
np.array(pygame.surfarray.pixels3d(canvas)),axes=(1,0,2)
)
(5)写个策略
策略即是根据observation和reward来决策选取什么样的action。由于好像在环境中写的策略没法通过gym.make生成的环境调用出来,所以我直接在主程序里写了一个贪心算法的策略。即:选取动作体(红色圆)和目标(蓝色方块)之间x和y差距最大的一个轴进行移动。如果目标坐标-动作体坐标<0,那么移动-1个距离,或者目标-动作体坐标>0,移动1个距离。
def greedy_policy(observation):
action = 0
agent_location = observation["agent"]
target_loaction = observation["target"]
x_distance = target_loaction[0] - agent_location[0]
y_distance = target_loaction[1] - agent_location[1]
if abs(x_distance) > abs(y_distance):
if x_distance > 0:
action = 0
elif x_distance < 0:
action = 2
else:
if y_distance > 0:
action = 1
elif y_distance < 0:
action = 3
return action