TransE
知识图谱基础
三元组(h,r,t)
知识表示
即将实体和关系向量化,embedding
算法描述
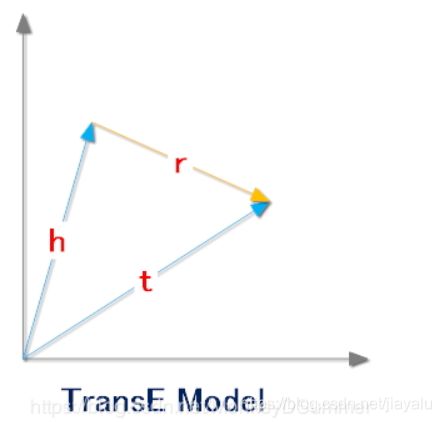
思想 :一个正确的三元组的embedding会满足:h+r=t
定义距离d表示向量之间的距离,一般取L1 或者L2 ,期望正确的三元组的距离越小越好,而错误的三元组的距离越大越好。为此给出目标函数为:
梯度求解 :
代码分析
参数:
目标函数的常数——margin
学习率——learningRate
向量维度——dim
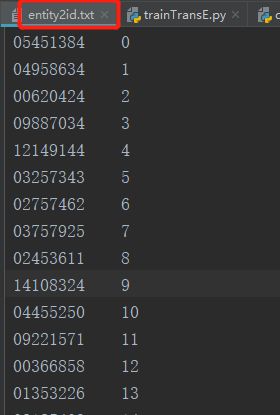
实体列表——entityList(读取文本文件,实体+id)
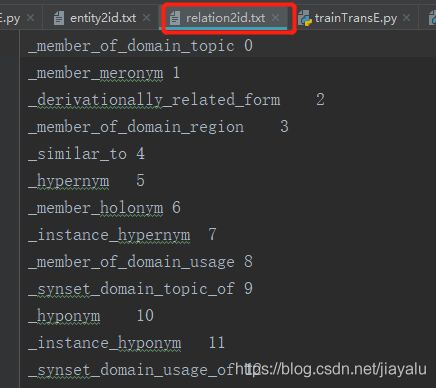
关系列表——relationList(读取文本文件,关系 + id)
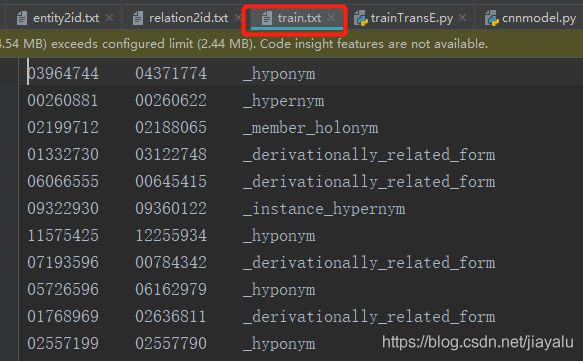
三元关系列表——tripleList(读取文本文件,实体 + 实体 + 关系)
损失值——loss
距离公式——L1
规定初始化维度和取值范围(TransE算法原理中的取值范围)
init:随机生成值
norm:归一化
getSample——随机选取部分三元关系,Sbatch
getCorruptedTriplet(sbatch)——随机替换三元组的实体,h、t中任意一个被替换,但不同时替换。
update——更新
L2更新向量的推导过程:
python 函数
"" "
@version : 3.7
@author : jiayalu
@file : trainTransE. py
@time : 22 / 08 / 2019 10 : 56
@description : 用于对知识图谱中的实体、关系基于TransE算法训练获取向量
数据:三元关系
实体id 和关系id
结果为:两个文本文件,即entityVector. txt和relationVector. txt 实体 [ array向量]
“”"from random import uniform, samplefrom numpy import * from copy import deepcopy
class TransE : def init ( self, entityList, relationList, tripleList, margin = 1 , learingRate = 0.00001 , dim = 10 , L1 = True ) : . margin = margin. learingRate = learingRate. dim = dim. entityList = entityList. relationList = relationList. tripleList = tripleList. loss = 0 . L1 = L1
def initialize ( self) :
'''
初始化向量
'''
entityVectorList = { }
relationVectorList = { }
for entity in self. entityList:
n = 0
entityVector = [ ]
while n < self. dim:
ram = init( self. dim)
entityVector. append( ram)
n += 1
entityVector = norm( entityVector)
entityVectorList[ entity] = entityVector
print ( "entityVector初始化完成,数量是%d" % len ( entityVectorList) )
for relation in self. relationList:
n = 0
relationVector = [ ]
while n < self. dim:
ram = init( self. dim)
relationVector. append( ram)
n += 1
relationVector = norm( relationVector)
relationVectorList[ relation] = relationVector
print ( "relationVectorList初始化完成,数量是%d" % len ( relationVectorList) )
self. entityList = entityVectorList
self. relationList = relationVectorList
def transE ( self, cI = 20 ) :
print ( "训练开始" )
for cycleIndex in range ( cI) :
Sbatch = self. getSample( 3 )
Tbatch = [ ]
for sbatch in Sbatch:
tripletWithCorruptedTriplet = ( sbatch, self. getCorruptedTriplet( sbatch) )
if ( tripletWithCorruptedTriplet not in Tbatch) :
Tbatch. append( tripletWithCorruptedTriplet)
self. update( Tbatch)
if cycleIndex % 100 == 0 :
print ( "第%d次循环" % cycleIndex)
print ( self. loss)
self. writeRelationVector( "E:\pythoncode\knownlageGraph\\transE-master\\relationVector.txt" )
self. writeEntilyVector( "E:\pythoncode\knownlageGraph\\transE-master\\entityVector.txt" )
self. loss = 0
def getSample ( self, size) :
return sample( self. tripleList, size)
def getCorruptedTriplet ( self, triplet) :
'''
training triplets with either the head or tail replaced by a random entity (but not both at the same time)
:param triplet:
:return corruptedTriplet:
'''
i = uniform( - 1 , 1 )
if i < 0 :
while True :
entityTemp = sample( self. entityList. keys( ) , 1 ) [ 0 ]
if entityTemp != triplet[ 0 ] :
break
corruptedTriplet = ( entityTemp, triplet[ 1 ] , triplet[ 2 ] )
else :
while True :
entityTemp = sample( self. entityList. keys( ) , 1 ) [ 0 ]
if entityTemp != triplet[ 1 ] :
break
corruptedTriplet = ( triplet[ 0 ] , entityTemp, triplet[ 2 ] )
return corruptedTriplet
def update ( self, Tbatch) :
copyEntityList = deepcopy( self. entityList)
copyRelationList = deepcopy( self. relationList)
for tripletWithCorruptedTriplet in Tbatch:
headEntityVector = copyEntityList[
tripletWithCorruptedTriplet[ 0 ] [ 0 ] ]
tailEntityVector = copyEntityList[ tripletWithCorruptedTriplet[ 0 ] [ 1 ] ]
relationVector = copyRelationList[ tripletWithCorruptedTriplet[ 0 ] [ 2 ] ]
headEntityVectorWithCorruptedTriplet = copyEntityList[ tripletWithCorruptedTriplet[ 1 ] [ 0 ] ]
tailEntityVectorWithCorruptedTriplet = copyEntityList[ tripletWithCorruptedTriplet[ 1 ] [ 1 ] ]
headEntityVectorBeforeBatch = self. entityList[
tripletWithCorruptedTriplet[ 0 ] [ 0 ] ]
tailEntityVectorBeforeBatch = self. entityList[ tripletWithCorruptedTriplet[ 0 ] [ 1 ] ]
relationVectorBeforeBatch = self. relationList[ tripletWithCorruptedTriplet[ 0 ] [ 2 ] ]
headEntityVectorWithCorruptedTripletBeforeBatch = self. entityList[ tripletWithCorruptedTriplet[ 1 ] [ 0 ] ]
tailEntityVectorWithCorruptedTripletBeforeBatch = self. entityList[ tripletWithCorruptedTriplet[ 1 ] [ 1 ] ]
if self. L1:
distTriplet = distanceL1( headEntityVectorBeforeBatch, tailEntityVectorBeforeBatch,
relationVectorBeforeBatch)
distCorruptedTriplet = distanceL1( headEntityVectorWithCorruptedTripletBeforeBatch,
tailEntityVectorWithCorruptedTripletBeforeBatch,
relationVectorBeforeBatch)
else :
distTriplet = distanceL2( headEntityVectorBeforeBatch, tailEntityVectorBeforeBatch,
relationVectorBeforeBatch)
distCorruptedTriplet = distanceL2( headEntityVectorWithCorruptedTripletBeforeBatch,
tailEntityVectorWithCorruptedTripletBeforeBatch,
relationVectorBeforeBatch)
eg = self. margin + distTriplet - distCorruptedTriplet
if eg > 0 :
self. loss += eg
if self. L1:
tempPositive = 2 * self. learingRate * (
tailEntityVectorBeforeBatch - headEntityVectorBeforeBatch - relationVectorBeforeBatch)
tempNegtative = 2 * self. learingRate * (
tailEntityVectorWithCorruptedTripletBeforeBatch - headEntityVectorWithCorruptedTripletBeforeBatch - relationVectorBeforeBatch)
tempPositiveL1 = [ ]
tempNegtativeL1 = [ ]
for i in range ( self. dim) :
if tempPositive[ i] >= 0 :
tempPositiveL1. append( 1 )
else :
tempPositiveL1. append( - 1 )
if tempNegtative[ i] >= 0 :
tempNegtativeL1. append( 1 )
else :
tempNegtativeL1. append( - 1 )
tempPositive = array( tempPositiveL1)
tempNegtative = array( tempNegtativeL1)
else :
tempPositive = 2 * self. learingRate * (
tailEntityVectorBeforeBatch - headEntityVectorBeforeBatch - relationVectorBeforeBatch)
tempNegtative = 2 * self. learingRate * (
tailEntityVectorWithCorruptedTripletBeforeBatch - headEntityVectorWithCorruptedTripletBeforeBatch - relationVectorBeforeBatch)
headEntityVector = headEntityVector + tempPositive
tailEntityVector = tailEntityVector - tempPositive
relationVector = relationVector + tempPositive - tempNegtative
headEntityVectorWithCorruptedTriplet = headEntityVectorWithCorruptedTriplet - tempNegtative
tailEntityVectorWithCorruptedTriplet = tailEntityVectorWithCorruptedTriplet + tempNegtative
copyEntityList[ tripletWithCorruptedTriplet[ 0 ] [ 0 ] ] = norm( headEntityVector)
copyEntityList[ tripletWithCorruptedTriplet[ 0 ] [ 1 ] ] = norm( tailEntityVector)
copyRelationList[ tripletWithCorruptedTriplet[ 0 ] [ 2 ] ] = norm( relationVector)
copyEntityList[ tripletWithCorruptedTriplet[ 1 ] [ 0 ] ] = norm( headEntityVectorWithCorruptedTriplet)
copyEntityList[ tripletWithCorruptedTriplet[ 1 ] [ 1 ] ] = norm( tailEntityVectorWithCorruptedTriplet)
self. entityList = copyEntityList
self. relationList = copyRelationList
def writeEntilyVector ( self, dir ) :
print ( "写入实体" )
entityVectorFile = open ( dir , 'w' , encoding= "utf-8" )
for entity in self. entityList. keys( ) :
entityVectorFile. write( entity + " " )
entityVectorFile. write( str ( self. entityList[ entity] . tolist( ) ) )
entityVectorFile. write( "\n" )
entityVectorFile. close( )
def writeRelationVector ( self, dir ) :
print ( "写入关系" )
relationVectorFile = open ( dir , 'w' , encoding= "utf-8" )
for relation in self. relationList. keys( ) :
relationVectorFile. write( relation + " " )
relationVectorFile. write( str ( self. relationList[ relation] . tolist( ) ) )
relationVectorFile. write( "\n" )
relationVectorFile. close( )
def init ( dim) : return uniform( - 6 / ( dim0.5 ) , 6 / ( dim0.5 ) )
def norm ( list ) : ‘’’ = linalg. norm( list ) = 0 while i < len ( list ) : list [ i] = list [ i] / var+= 1 return array( list )
def distanceL1 ( h, t , r) : = h + r - tsum = fabs( s) . sum ( ) return sum
def distanceL2 ( h, t, r) : = h + r - tsum = ( s* s) . sum ( ) return sum
def openDetailsAndId ( dir , sp= " " ) : = 0 list = [ ] with open ( dir , “r” , encoding= “utf-8” ) as file : = file . readlines( ) for line in lines: = line. strip( ) . split( sp) list . append( DetailsAndId[ 0 ] ) += 1 return idNum, list
def openTrain ( dir , sp= " " ) : = 0 list = [ ] with open ( dir , “r” , encoding= “utf-8” ) as file : = file . readlines( ) for line in lines: = line. strip( ) . split( sp) if ( len ( triple) < 3 ) : continue list . append( tuple ( triple) ) += 1 return num, list
if name == ‘main ’ : = “E:\pythoncode\ZXknownlageGraph\TransEgetvector\entity2id.txt” , entityList = openDetailsAndId( dirEntity) = “E:\pythoncode\ZXknownlageGraph\TransEgetvector\relation2id.txt” , relationList = openDetailsAndId( dirRelation) = “E:\pythoncode\ZXknownlageGraph\TransEgetvector\train.txt” , tripleList = openTrain( dirTrain) print ( “打开TransE” ) = TransE( entityList, relationList, tripleList, margin= 1 , dim = 128 ) print ( “TranE初始化” ) . initialize( ) . transE( 1500 ) . writeRelationVector( “E:\pythoncode\ZXknownlageGraph\TransEgetvector\relationVector.txt” ) . writeEntilyVector( “E:\pythoncode\ZXknownlageGraph\TransEgetvector\entityVector.txt” )
数据
结果向量
这是我自己的代码,主要用来存储,若能帮到其他人,我也很愿意。
相关推荐
TransE 算法 (Translating Embedding)
u011274209的专栏
03-27
介绍 TransE 算法 (Translating Embedding)
知识表示学习 TransE 代码逻辑梳理 超详细解析
南波兔不写bug
09-02
知识表示学习 网络上已经存在了大量知识库(KBs),比如OpenCyc,WordNet,Freebase,Dbpedia等等。
这些知识库是为了各种各样的目的建立的,因此很难用到其他系统上面。为了发挥知识库的图(graph)性,也为了得到统计学习(包括机器学习和深度学习)的优势,我们需要将知识库嵌入(embedding)到一个低维空间里(比如10、20、50维)。我们都知道,获得了向量后,就可以运用各种数学工具进行分析。它为许多知识获取任务和下游应用铺平了道路。
TransE 如何进行向量更新?
暗焰之珩的博客
04-27
算法 伪代码
SGD中的向量更新
代码实现
关于TransE ,博客上各种博文漫天飞,对于原理 我就不做重复性劳动,只多说一句,TransE 是知识表示算法 翻译算法 系列中的最基础算法 ,此处还有TransH、TransD等等;个人觉得翻译算法 的叫法是不太合适的,translating,叫做平移或者变换算法 可能更加符合作者的原本意图,利用向量的平移不变性去做链路预测。了解原理 个人觉得以下两篇足够…
TransE 代码实践(很详细)
得克特
09-27
TranE是一篇Bordes等人2013年发表在NIPS上的文章提出的 算法 。它的提出,是为了解决多关系数据(multi-relational data)的处理问题。 TransE 的直观含义,就是 TransE 基于实体和关系的分布式向量表示,将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译,通过不断调整h、r和t(head、relat...
transE (Translating Embedding)详解+简单python实现
yuanyue
05-15
表示学习旨在学习一系列低维稠密向量来表征语义信息,而知识表示学习是面向知识库中实体和关系的表示学习。当今大规模知识库(或称知识图谱)的构建为许多NLP任务提供了底层支持,但由于其规模庞大且不完备,如何高效存储和补全知识库成为了一项非常重要的任务,这就依托于知识表示学习。 transE 算法 就是一个非常经典的知识表示学习,用分布式表示(distributed representation)来描述知识库...
TransE 算法 详解
MonkeyDSummer的博客
12-25
TransE 算法 详解 @(机器学习)[知识图谱|知识表示| TransE ]
文章目录TransE 算法 详解算法 背景知识图谱是什么知识表示是什么基本思想算法 描述梯度参考文献算法 背景
TransE 算法 解析
perfectzxiny的博客
12-04
transE (Translating Embedding)详解+简单python实现 概念 transE 算法 是一个非常经典的知识表示学习,用分布式表示(distributed representation)来描述知识库中的三元组。 原理 transE 算法 利用了word2vec的平移不变性, TransE 的直观含义,就是 TransE 基于实体和关系的分布式向量表示,将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译(其实就是向量相加),通过不断调
【论文笔记】 知识图谱 之 TransE 算法 (Translating Embedding)
justlpf的专栏
10-31
原文地址:https://blog.csdn.net/elaine_bao/article/details/52012537
TransE 算法
dxk_093812的博客
04-11
TransE 算法 中存在一个设定,它将关系看作是实体间的平移向量,也就是说对于一个三元组(h,r,t)对应的向量lh,lr,lt,希望 lh+lr =lt 这源于Mikolov等人在2013年提出的word2vec词表示学习模型,他们发现词向量空间存在着平移不变现象,如 C(king)−C(queen)≈C(man...
TransE 算法 详解【代码学习系列】【知识图谱】【表示学习】
weixin_44023339的博客
08-27
1 代码来源 本代码来源于github项目地址,项目实现了 TransE 算法 。下面结合项目代码,对 TransE 算法 原理 及实现进行详细说明。 2基本思想 TransE 是一篇Bordes等人2013年发表在NIPS上的文章提出的 算法 。它的提出,是为了解决多关系数据(multi-relational data)的处理问题。我们现在有很多很多的知识库数据knowledge bases (KBs),比如Fre...
Svm算法 原理 及实现
d__760的博客
05-21
Svm(support Vector Mac)又称为支持向量机,是一种二分类的模型。当然如果进行修改之后也是可以用于多类别问题的分类。支持向量机可以分为线性核非线性两大类。其主要思想为找到空间中的一个更够将所有数据样本划开的超平面,并且使得本本集中所有数据到这个超平面的距离最短。一、基于最大间隔分隔数据1.1支持向量与超平面 在了解svm 算法 之前,我们首先需要了解一下线性分类器这...
TransE 的理解
机器学习 数据挖掘 搜索引擎 推荐系统
02-26
先看下train2id.txt,大概是这样子:
253 3643 35
就只有head tail relatio…
TransE
weixin_43751558的博客
11-20
转自:http://blog.csdn.net/u011274209/article/details/50991385 一、引言 网络上已经存在了大量知识库(KBs),比如OpenCyc,WordNet,Freebase,Dbpedia等等。这些知识库是为了各种各样的目的建立的,因此很难用到其他系统上面。为了发挥知识库的图(graph)性,也为了得到统计学习(包括机器学习和深度学习)的优势,我们需要将知识库嵌入(embedding)到一个低维空间里(比如10、20、50维)。我们都知道,获得了向量后,就可以
CSDN开发者助手,常用网站自动整合,多种工具一键调用
CSDN开发者助手由CSDN官方开发,集成一键呼出搜索、万能快捷工具、个性化新标签页和官方免广告四大功能。帮助您提升10倍开发效率!
TransE 模型:知识图谱的经典表示学习方法
ChihkAnchor的博客
10-24
传统的知识图谱表示方法是采用OWL、RDF等本体语言进行描述;随着深度学习的发展与应用,我们期望采用一种更为简单的方式表示,那就是【向量】,采用向量形式可以方便我们进行之后的各种工作,比如:推理,所以,我们现在的目标就是把每条简单的三元组< subject, relation, object > 编码为一个低维分布式向量。(有关【分布式表示】的概念请大家自行百度)
paper:Tra…
学习笔记(2)——TransE 算法 (Translating Embedding)
strivequeen的博客
08-26
前言 目前网络上存在大量知识库(KBs):如OpenCyc、WordNet、Freebase、Dbpedia等等,它们因不同目的建成,因此很难用到其他系统上。为发挥知识库的图(graph)性,也为得到统计学习(包括机器学习和深度学习)的优势,需要将知识库嵌入(embedding)到一个低维空间里(比如10、20、50维)。获得向量后,就可以运用各种数学工具进行分析。 表示学习 :学习一系列低维稠密向量来表征语义信息,知识表示学习是面向知识库中实体和关系的表示学习。大规模知识库(知识图谱)的构建为许多NLP任
transE
qq_27374315的博客
10-31
我们为什么要关注表示学习这个问题呢?我们可以看关于机器学习的一个重要公式,这个公式有三个部分组成,第一部分是关于数据或者问题的表示,在表示的基础上我们要去设计或者构建一个目标,也就是说我们要实现一个什么样的目标。在设定了目标之后,开始看怎么实现这个目标,这就是优化的过程。对于机器学习来讲,表示是这三个环节中最基础的部分,也是我们为什么会关注它的重要原因。对于自然语言处理和多媒体处理而言,所处理的数...
©️2020 CSDN 皮肤主题: 游动-白 设计师:白松林 返回首页
jiayalu CSDN认证博客专家 CSDN认证企业博客
10
原创
7万+
周排名
22万+
总排名
2万+
访问
等级
411
积分
18
粉丝
38
获赞
26
评论
197
收藏
热门文章
知识图谱与推荐系统 12495
主题模型 5345
TransE算法原理与案例 4593
AMBERT(李航)---- 多粒度预训练模型 918
HanLP环境搭建 755
分类专栏
环境搭建 1篇
算法模型 10篇
最新文章
白板推导SVM--个人手推笔记
AMBERT(李航)---- 多粒度预训练模型
FM模型--推荐系统
分类专栏
环境搭建 1篇
算法模型 10篇







![[外链图片转存失败(img-ecjLQyc0-1567589870034)(en-resource://database/2941:0)]](http://img.e-com-net.com/image/info8/29ecebc8923a4a03827c6949bfc56a14.jpg)














 4万+
4万+ 
