HighD数据集Python处理(超车变道邻近车辆数据筛选)
由德国亚琛工业大学汽车工程研究所发布的HighD数据集,是德国高速公路的大型自然车辆轨迹数据,搜集自德国科隆附近的六个不同地点, 位置因车道数量和速度限制而异,记录的数据中包括轿车和卡车。数据集包括来自六个地点的11.5小时测量值和110 000车辆,所测量的车辆总行驶里程为45 000 km,还包括了5600条完整的变道记录。通过使用最先进的计算机视觉算法,定位误差通常小于十厘米。适用于驾驶员模型参数化、自动驾驶、交通模式分析等任务。HighD的数据格式和后续推出的InD,RounD有细微的不同,它的坐标系原点起始于左上方,标注车辆位置用的也是包围盒左上方端点而非中心点。如需数据集可点击链接HighD大型自然车辆轨迹数据集-数据集文档类资源-CSDN文库进行下载。
本文基于该数据集实现车辆执行超车变道时(如示例车道ID变化为:5——4——5),左车道前后车距离本车的距离。超车变道时指第一次车道ID变化时刻,即示例中车道5——4时刻。
-
数据读取及初步处理
原始数据容易出现空行,需删除空行,而后根据相邻帧车道编号差,获取产生变道行为的车辆数据。
origin_data=pd.read_csv('D:\BaiduNetdiskDownload\highD数据\\'+str(str(i).rjust(2, '0'))+'_tracks.csv')
'''删除多于的空行'''
data = origin_data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
finally_data=pd.DataFrame()
for ID in set(list(data['id'])):
index=[]
data_c=data[data.id==ID]
lst_Lane_id=list(data_c['laneId'])
lst_leftPrecedingId=list(data_c['leftPrecedingId'])
lst_leftFollowingId=list(data_c['leftFollowingId'])
lst_frame=list(data_c['frame'])
diff_lst_Lane_id=np.diff(lst_Lane_id)
'''获取超车变道数据'''
if -1 in diff_lst_Lane_id and 1 in diff_lst_Lane_id:
for diff in enumerate(diff_lst_Lane_id):
if diff[1]!=0:
index.append(diff[0])-
超车变道索引及数据提取
index储存两次变道的索引,需获取第一次变道索引,而后根据索引进行本车和左车道前后车数据的读取。 若左前车或左后车ID为0,则用#号替代改成由于本车的距离,距离使用绝对值。
'''获取第一次变道时刻索引'''
new_index=min(index)
'''主车变道时数据'''
new_data_c=data_c[data_c.frame==lst_frame[new_index]].copy()
new_data_c['O_P_Distance']=np.nan
new_data_c['O_F_Distance']=np.nan
'''目标车ID'''
leftPrecedingId=lst_leftPrecedingId[new_index]
leftFollowingId=lst_leftFollowingId[new_index]
data_1=data[data.frame==lst_frame[new_index]]
'''同时刻两车数据获取'''
print(ID,leftPrecedingId,leftFollowingId)
if leftPrecedingId==0:
new_data_c.iloc[0,25]='#'
else:
data_leftPrecedingId=data_1[data_1.id==leftPrecedingId]
new_data_c.iloc[0,25]=abs(new_data_c.iloc[0,2]-data_leftPrecedingId.iloc[0,2])
if leftFollowingId==0:
new_data_c.iloc[0,26]='#'
else:
data_leftFollowingId=data_1[data_1.id==leftFollowingId]
new_data_c.iloc[0,26]=abs(new_data_c.iloc[0,2]-data_leftFollowingId.iloc[0,2])-
数据导出及格式说明
构建命名为finally_data的空dataframe,用于保存最后结果,循环添加new_data_c,导出目录如下:
finally_data.to_csv(filepath+'\\'+str(str(i).rjust(2, '0'))+'.csv')
格式说明:
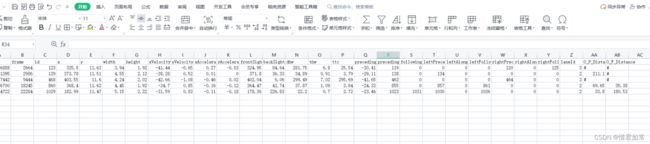
输出文件的命名和输入文件的命名相同,输出文件中最后两行:O_P_Distance表示本车与左前方车辆的距离,O_F_Distance表示本车与左后方车辆的距离。
完整代码如下:
import pandas as pd
import numpy as np
filepath=input('请输入保存文件路径:')
for i in range(1,61):
origin_data=pd.read_csv('D:\BaiduNetdiskDownload\highD数据\\'+str(str(i).rjust(2, '0'))+'_tracks.csv')
'''删除多于的空行'''
data = origin_data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
finally_data=pd.DataFrame()
for ID in set(list(data['id'])):
index=[]
data_c=data[data.id==ID]
lst_Lane_id=list(data_c['laneId'])
lst_leftPrecedingId=list(data_c['leftPrecedingId'])
lst_leftFollowingId=list(data_c['leftFollowingId'])
lst_frame=list(data_c['frame'])
diff_lst_Lane_id=np.diff(lst_Lane_id)
'''获取超车变道数据'''
if -1 in diff_lst_Lane_id and 1 in diff_lst_Lane_id:
for diff in enumerate(diff_lst_Lane_id):
if diff[1]!=0:
index.append(diff[0])
'''获取第一次变道时刻索引'''
new_index=min(index)
'''主车变道时数据'''
new_data_c=data_c[data_c.frame==lst_frame[new_index]].copy()
new_data_c['O_P_Distance']=np.nan
new_data_c['O_F_Distance']=np.nan
'''目标车ID'''
leftPrecedingId=lst_leftPrecedingId[new_index]
leftFollowingId=lst_leftFollowingId[new_index]
data_1=data[data.frame==lst_frame[new_index]]
'''同时刻两车数据获取'''
print(ID,leftPrecedingId,leftFollowingId)
if leftPrecedingId==0:
new_data_c.iloc[0,25]='#'
else:
data_leftPrecedingId=data_1[data_1.id==leftPrecedingId]
new_data_c.iloc[0,25]=abs(new_data_c.iloc[0,2]-data_leftPrecedingId.iloc[0,2])
if leftFollowingId==0:
new_data_c.iloc[0,26]='#'
else:
data_leftFollowingId=data_1[data_1.id==leftFollowingId]
new_data_c.iloc[0,26]=abs(new_data_c.iloc[0,2]-data_leftFollowingId.iloc[0,2])
finally_data=finally_data.append(new_data_c)
index.clear()
print(finally_data)
print(str(str(i).rjust(2, '0'))+'已处理完毕!')
finally_data.to_csv(filepath+'\\'+str(str(i).rjust(2, '0'))+'.csv')若有疑问,需完整代码或有交通数据处理需求欢迎VX探讨:A2528945820