LSTM的结构、原理及其数据的输入格式介绍
文章目录
- 前言
- 一、LSTM是什么?
- 二、LSTM的网络结构及原理
-
- 1.LSTM的网络结构
- 2.LSTM的结构原理
- 3.通俗理解LSTM的三个门
- 4.LSTM神经网络的输入输出
- 参考资料
前言
LSTM由于其结构特点,能够学习长的依赖关系,被广泛应用到深度学习的各个领域,作者最近使用LSTM实现了两个小的工程应用场景,对LSTM的结构以及特点进行了学习整理,希望对大家理解这种结构有帮助。
一、LSTM是什么?
LSTM全写为Long short-term memory(长短期记忆),是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。它由 H o c h r e i t e r Hochreiter Hochreiter & S c h m i d h u b e r Schmidhuber Schmidhuber (1997)提出,并被 A l e x G r a v e s Alex Graves AlexGraves进行了改良和推广,现在在机器学习领域被广泛使用。简单来说,LSTM相比普通的RNN,能够在更长的序列中有更好的表现,它能通过门的控制保留很久之前的特征,这是它最大的特点。
二、LSTM的网络结构及原理
1.LSTM的网络结构
LSTM是一种特殊的RNN(循环神经网络),先看RNN的结构特点:

LSTM的网络结构:

可以发现,相比RNN只有一个传递状态 h t h^t ht ,LSTM有两个传输状态,一个 c t c^t ct (cell state),和一个 h t h^t ht (hidden state)。通常输出的 c t c^t ct是上一个状态传过来的加上一些数值,而 h t h^t ht则在不同节点下往往会有很大的区别。
2.LSTM的结构原理
下图是 LSTM 的计算过程,输入一共有四个: Z Z Z、输入门 Z i Z_i Zi、输出门 Z o Z_o Zo、遗忘门 Z f Z_f Zf,一个输出 a a a。

三个门各司其职,每个门通常使用 S i g m o i d Sigmoid Sigmoid 函数作为激活函数,激活后的值处在 0 0 0 和 1 1 1 之间,故方便控制 “门” 的开启和关闭,输入门决定 Z Z Z 能走多远,遗忘门决定记忆单元的值是否刷新或者重置,输出门则决定最后的能否被输出。

3.通俗理解LSTM的三个门
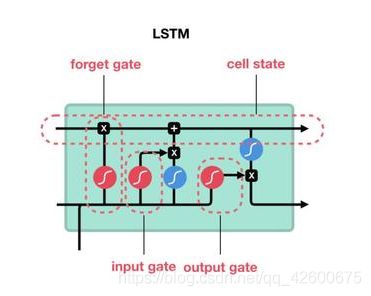
门( G a t e Gate Gate)是一种可选地让信息通过的方式,LSTM有三个门,用于保护和控制细胞的状态。
LSTM内部主要有三个阶段:
- 忘记阶段
这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。具体来说是通过计算得到的 z f z^f zf来作为忘记门控,来控制上一个状态 c t − 1 c^{t-1} ct−1的哪些需要留哪些需要忘。 - 选择记忆阶段
这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 x t x^t xt进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的表示。而选择的门控信号则是由 z i z^i zi来进行控制,将上面两步得到的结果相加,即可得到传输给下一个状态 c t c^t ct的: c t = z f ∗ c t − 1 + z i ∗ z c^t = z^f*c^{t-1}+z^i*z ct=zf∗ct−1+zi∗z。 - 输出阶段
这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 z o z^o zo来进行控制的。并且还对上一阶段得到的 c o c^o co进行了放缩(通过一个tanh激活函数进行变化),与普通RNN类似,输出 y t y^t yt往往最终也是通过 h t h^t ht变化得到。
下面我们看计算过程:
第一步,决定我们要从细胞状态中丢弃什么信息, 该决定由被称为“忘记门”的 S i g m o i d Sigmoid Sigmoid层实现。它查看 h t − 1 h_{t-1} ht−1(前一个输出)和 x t x^t xt(当前输入),并为单元格状态 c t − 1 c_{t-1} ct−1(上一个状态)中的每个数字输出 0 0 0和 1 1 1之间的数字, 1 1 1代表完全保留,而 0 0 0代表彻底删除。

第二步,决定我们要在细胞状态中存储什么信息。 首先,称为“输入门层”的 S i g m o i d Sigmoid Sigmoid层决定了我们将更新哪些值。 接下来一个 t a n h tanh tanh层创建候选向量 c t c_t ct,该向量将会被加到细胞的状态中。 在下一步中,我们将结合这两个向量来创建更新值。

第三步,更新状态值 C t C_t Ct。我们将上一个状态值乘以 f t f_t ft,以此表达期待忘记的部分。之后我们将得到的值加上 i t i_t it ∗ C ~ t C̃_t C~t。这个得到的是新的候选值, 按照我们决定更新每个状态值的多少来衡量.

最后,我们需要决定我们要输出什么。 此输出将基于我们的细胞状态,但将是一个过滤版本。 首先我们运行一个 S i g m o i d Sigmoid Sigmoid层,它决定了我们要输出的细胞状态的哪些部分, 然后我们将单元格状态通过 t a n h tanh tanh(将值规范化到 − 1 -1 −1和 1 1 1之间),并将其乘以 S i g m o i d Sigmoid Sigmoid门的输出,至此我们输出了我们决定的那些部分。

4.LSTM神经网络的输入输出
输入张量形状:(samples, timesteps, data_dim)
输出张量形状:(samples, n_labels)
下面看使用Keras完成的实例:
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# 期望输入数据尺寸: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # 返回维度为 32 的向量序列
model.add(LSTM(32, return_sequences=True)) # 返回维度为 32 的向量序列
model.add(LSTM(32)) # 返回维度为 32 的单个向量
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 生成虚拟训练数据
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# 生成虚拟验证数据
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))
注意:这里最后一层是Dense层,如果是分类,则传入的参数就是分类的类别数,如果是预测序列,这儿传入的参数就是预测的序列的长度。
(若有错误的地方还望及时告知)
参考资料
人人都能看懂的LSTM
如何简单的理解LSTM——其实没有那么复杂
如何形象的理解LSTM的三个门
LSTM神经网络输入输出究竟是怎样的?
Keras 中文文档