多任务学习算法在推荐系统中的应用
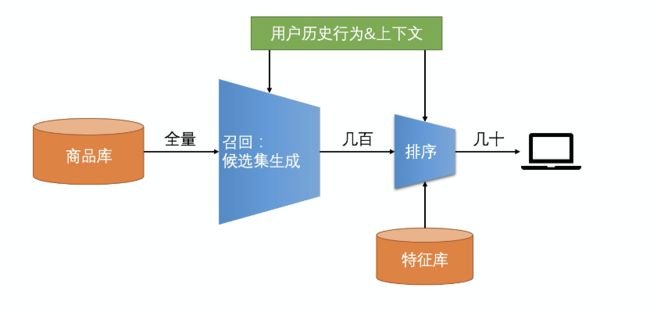
粗略来看,推荐算法可以简单地分为召回和排序两个阶段。召回模块负责从海量的物品库里挑选出用户可能感兴趣的物品子集,过滤之后通常返回几百个物品。排序模块负责对召回阶段返回的物品集个性化排序,通常返回几十个物品组成的有序列表。
总结起来,召回和排序有如下特点:
- 召回层:候选集规模大、模型和特征简单、速度快,尽量保证用户感兴趣数据多召回。
- 排序层:候选集不大,目标是保证排序的精准,一般使用复杂和模型和特征。
使用排序模块的三个原因:
- 多路召回的候选集缺乏统一的相关性度量,不同类型的召回物品不可比;
- 召回阶段通常只计算候选物品的相关性,对业务指标(如转化率、dwell time、GMV等)缺乏直接有效的度量;
- 当有多个业务关心的指标时,召回模块通常无能为力。
比如,在电商场景业务通常比较关心总成交额(GMV)这一指标,通过目标拆解:GMV = 流量 × CTR × CVR × price,我们发现流量和price通常不是算法能够控制的,那么算法需要干预的是CTR和CVR,也就是点击率和转化率。我们可以分别训练一个点击率预估模型和一个转化率预估模型,或者只训练一个多目标模型同时建模点击率预估和转化率预估。有了预估的CTR和CVR之后,我们就可以按照如下公式来对候选商品排序:
r a n k _ s c o r e = c t r ⋅ c v r ⋅ [ l o g ( p r i c e ) ] α rank\_score=ctr \cdot cvr \cdot [log(price)]^{\alpha} rank_score=ctr⋅cvr⋅[log(price)]α
这里对price项做log和指数变换的原因是通常price的值比较大,跟ctr和cvr不在一个量级上,如果不做变换会在排序公式中占据统治地位。
训练一个排序模型通常分为 模型选择、样本构建、特征工程、模型开发、训练&评估 等几个阶段。下面我们就以电商平台商品详情页的推荐场景为例,介绍一下排序模型建模的详细流程和方法。
1. 模型选择
通过前文的分析,我们确定了要在统一模型中同时建模CTR预估和CVR预估,这么做一个明显的好处是在推荐链路上只需要一个精排model,而不需要串联两个精排model。因此我们需要一个多任务学习模型。
Multi-Task Learning (MTL) is a learning paradigm in machine learning and its aim is to leverage useful information contained in multiple related tasks to help improve the generalization performance of all the tasks.
在文献中,多任务学习有一些别的名字:joint learning, learning to learn, and learning with auxiliary tasks 。广义上来说,当我们在优化多个损失函数时,我们就在使用多任务学习范式。
多任务学习之所以能改善各个任务单独建模的效果,是因为以下几个原因:
- 隐式数据增强。为某任务训练模型,目标是为该任务学习一个好的特征表示,然而通常训练数据中或多或少都包含一些噪音,只学习当前任务会面临过拟合的风险,如果同时学习多个任务则可以通过平均化不同任务的噪音得到一个适用于多个任务的更好的表示。
- 注意力聚焦。如果某任务的训练数据噪音很多,或者训练数据有限,并且特征维数很高,则模型很难区分相关特征与不相关特征。MTL能够帮助模型把注意力聚焦到真正有用的特征上,因为其他学习任务可以提供额外的证据。
- 窃听。一些特征在任务A上很难被学习,而在任务B上很容易被学习。可能的原因是在任务A与该特征存在更加复杂的交互关系,或者其他特征影响了模型学习这些特征的能力。
- 表示偏置。每个机器学习模型都存在某种程度的归纳偏置,MTL的归纳偏置是偏好那些适用于多个任务的特征表示。
- 正则化。MTL相当于给各个子任务添加了正则项参数约束,可以防止过拟合。
这里介绍几个常用的多目标排序模型:NavieMultiTask,ESMM,MMoE,DBMTL,PLE。
① NavieMultiTask
在深度学习领域,MTL通常通过共享隐层的参数来实现,具体有两种共享参数的方法:hard parameter sharing 和 soft parameter sharing。
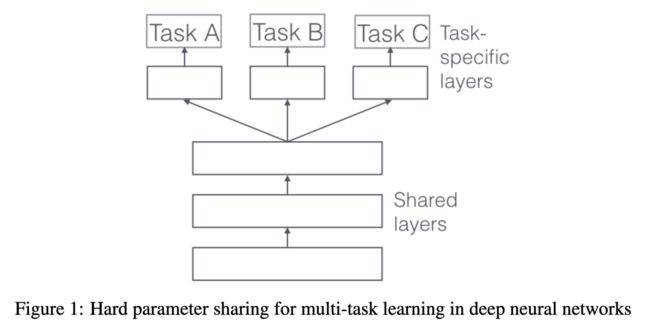
在soft parameter sharing模式中,每个任务有自己的模型和参数,各任务模型参数的一部分通过正则化的方式使得彼此距离接近,比如通过 L2 正则化。

② ESMM
“完整空间多任务模型”(Entire Space Multi-Task Model,ESMM),下文简称为ESMM模型,创新地利用用户行为序列数据,在完整的样本数据空间同时学习点击率和转化率(post-view clickthrough&conversion rate,CTCVR),解决了传统CVR预估模型难以克服的样本选择偏差(sample selection bias)和训练数据过于稀疏(data sparsity )的问题。
以电子商务平台为例,用户在观察到系统展现的推荐商品列表后,可能会点击自己感兴趣的商品,进而产生购买行为。换句话说,用户行为遵循一定的顺序决策模式:impression → click → conversion。CVR模型旨在预估用户在观察到曝光商品进而点击到商品详情页之后购买此商品的概率,即 p C V R = p ( c o n v e r s i o n ∣ c l i c k , i m p r e s s i o n ) pCVR = p(conversion|click,impression) pCVR=p(conversion∣click,impression)。
假设训练数据集为 S = { ( x i , y i → z i ) } ∣ i = 1 N S=\{ (x_i,y_i \rightarrow z_i) \} |_{i=1}^N S={(xi,yi→zi)}∣i=1N,其中的样本 ( x , y → z ) (x, y \rightarrow z) (x,y→z)是从域 X × Y × Z X × Y × Z X×Y×Z 中按照某种分布采样得到的, X X X 是特征空间, Y Y Y 和 Z Z Z 是标签空间, N N N 为数据集中的样本总数量。在CVR预估任务中, x x x 是高维稀疏多域的特征向量, y y y 和 z z z 的取值为0或1,分别表示是否点击和是否购买。 y → z y \rightarrow z y→z 揭示了用户行为的顺序性,即点击事情一般发生在购买事件之前。CVR模型的目标是预估条件概率pCVR ,与其相关的两个概率为点击率pCTR 和点击且转换率 pCTCVR ,它们之间的关系如下:
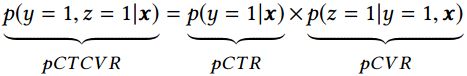
传统的CVR预估任务通常采用类似于CTR预估的技术,比如最近很流行的深度学习模型。然而,有别于CTR预估任务,CVR预估任务面临一些特有的挑战:1) 样本选择偏差;2) 训练数据稀疏;3) 延迟反馈等。
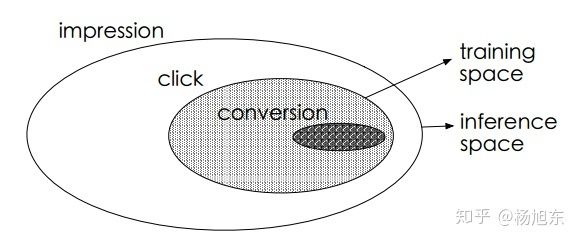
图1. 训练样本空间
延迟反馈的问题不在本文讨论的范围内,下面简单介绍一下样本选择偏差与训练数据稀疏的问题。如图1所示,最外面的大椭圆为整个样本空间 S,其中有点击事件( y=1 )的样本组成的集合为,对应图中的阴影区域,传统的CVR模型就是用此集合中的样本来训练的,同时训练好的模型又需要在整个样本空间做预测推断。由于点击事件相对于展现事件来说要少很多,因此只是样本空间 S 的一个很小的子集,从上提取的特征相对于从 S 中提取的特征而言是有偏的,甚至是很不相同。从而,按这种方法构建的训练样本集相当于是从一个与真实分布不完全一致的分布中采样得到的,这一定程度上违背了机器学习算法之所以有效的前提:训练样本与测试样本必须独立地采样自同一个分布,即独立同分布的假设。总结一下,训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。样本选择偏差会伤害学到的模型的泛化性能。
ESMM模型引入了两个辅助的学习任务,分别用来拟合pCTR和pCTCVR,从而同时消除了上文提到的两个挑战。ESMM模型能够充分利用用户行为的顺序性模式,其模型架构如图2所示。
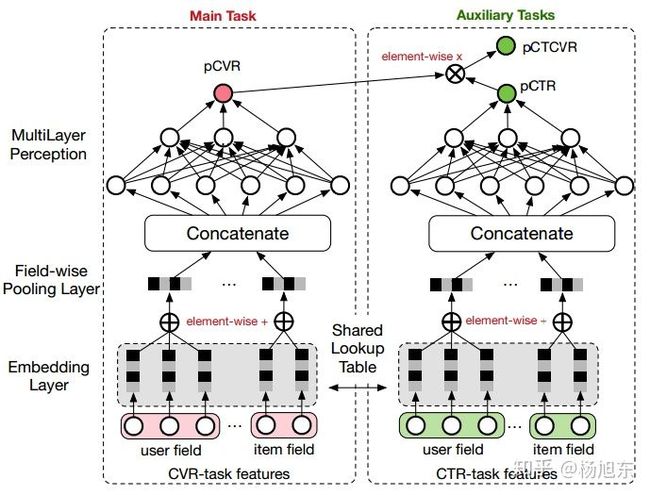
图2. ESMM模型
整体来看,对于一个给定的展现,ESMM模型能够同时输出预估的pCTR、pCVR 和pCTCVR。它主要由两个子神经网络组成,左边的子网络用来拟合pCVR ,右边的子网络用来拟合pCTR。两个子网络的结构是完全相同的,这里把子网络命名为BASE模型。两个子网络的输出结果相乘之后即得到pCTCVR,并作为整个任务的输出。
参考资料:
- CVR预估的新思路:完整空间多任务模型
- 构建分布式Tensorflow模型系列:CVR预估之ESMM
③ MMoE
MMOE模型的结构图如下:
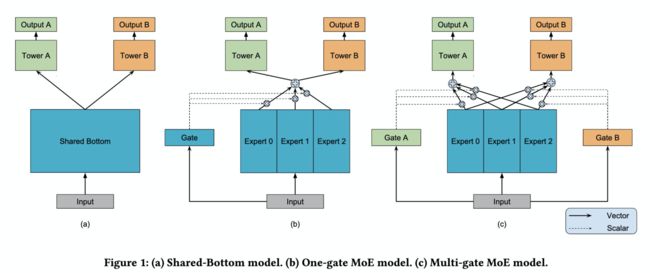
模型 (a) 最为常见,也就是上文所说的NavieMultiTask方法的架构,两个任务直接共享模型的 bottom 部分,只在最后处理时做区分,图 (a) 中使用了 Tower A 和 Tower B,然后分别接损失函数。函数表达式:
y k = h k ( f ( x ) ) y^k = h^k \left( f(x) \right) yk=hk(f(x))
模型 (b) 是常见的多任务学习模型。将 input 分别输入给三个 Expert,但三个 Expert 并不共享参数。同时将 input 输出给 Gate,Gate 输出每个 Expert 被选择的概率,然后将三个 Expert 的输出加权求和,输出给 Tower。有点 attention 的感觉。函数表达式:
y k = h k ( ∑ i = 1 n g i f i ( x ) ) y^k = h^k \left( \sum_{i=1}^n g_i f_i(x) \right) yk=hk(i=1∑ngifi(x))
- k 表示k个任务;
- n 表示n个expert network;
模型 © 是作者新提出的方法,对于不同的任务,模型的权重选择是不同的,所以作者为每个任务都配备一个 Gate 模型。对于不同的任务,特定的 Gate k 的输出表示不同的 Expert 被选择的概率,将多个 Expert 加权求和,得到 f k ( x ) f^k(x) fk(x),并输出给特定的 Tower 模型,用于最终的输出。函数表达式:
f k ( x ) = ∑ i = 1 n g i k ( x ) f i ( x ) f^k(x) = \sum_{i=1}^n g_i^k(x) f_i(x) fk(x)=i=1∑ngik(x)fi(x)
g k ( x ) = s o f t m a x ( W g k ( x ) ) g^k(x) = softmax(W_{g^k(x)}) gk(x)=softmax(Wgk(x))
其中: g ( x ) g(x) g(x)表示 gate 门的输出,为多层感知机模型,实现时为简单的线性变换加 softmax 层。
④ PLE
PLE模型是的MMoE模型的一种优化,重新设计了网络结构来解决“跷跷板现象”。所谓的“跷跷板现象(seesaw phenomenon)”是指在对多个目标进行优化的过程中,一个任务指标的提升伴随着另外一些任务指标的下降。PLE模型提出了一种更加有效的参数共享的网络结构(分为task-specific部分和sharing部分,之后通过类似attention的方式进行加权),论文中把单层共享参数的模型网络称之为CGC网络,堆叠多层共享参数网络的模型称之为PLE模型。
1. CGC网络
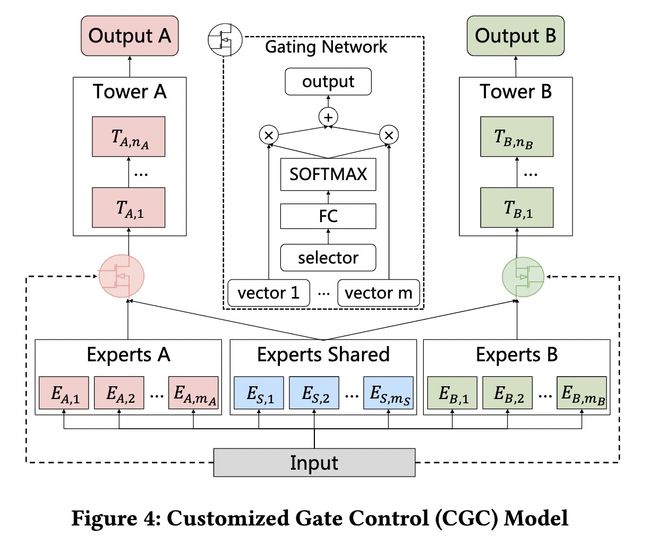
CGC网络结构
为了解决seesaw phenomenon和negative transfer效应,文章提出了PLE网络结构,而PLE结构可以看做是CGC网络结构的进一步扩展(CGC是single-level的,PLE是multi-level的)。整个CGC网络结构如上图所示。从图中的网络结构可以看出,CGC的底层网络主要包括shared experts和task-specific expert构成,每一个expert module都由多个子网络组成,子网络的个数和网络结构(维数)都是超参数;上层由多任务网络构成,每一个多任务网络(towerA和towerB)的输入都是由gating网络进行加权控制,每一个子任务的gating网络的输入包括两部分,其中一部分是本任务下的task-specific部分的experts和shared部分的experts组成(即gating network网络结构中的vector1……vector m),输入input作为gating network的selector。而gating网络的结构也是比较简单的,只是一个单层的前向FC,利用输入作为筛选器(selector)获得不同子网络所占的权重大小,进而得到不同任务下gating网络的加权和。也就是说CGC网络结构保证了,每个子任务会根据输入来对task-specific和shared两部分的expert vector进行加权求和,从而每个子任务网络得到一个embedding,再经过每个子任务的tower就得到了对应子任务的输出。
CGC网络的好处是即包含了task-specific网络独有的个性化信息,也包含了shared网络具有的更加泛化的信息,文章指出虽然MMoE模型在理论上可以得到同样的解,但是在实际训练过程中很难收敛到这种情况。
2. PLE网络
上面看到了CGC网络是一种single-level的网络结构,一个比较直观的思路就是叠加多层CGC网络(获得更加丰富的表征能力),而PLE网络结构就是将CGC拓展到了multi-level下。具体网络结构如下图所示。

PLE网络结构
与CGC网络(PLE里的Extraction Network)不同的是:
- 在底层的Extraction网络中,除了各个子任务的gating network外,还包含有一个share部分的gating network,这部分gating network的输入包含了所有input,而各个子任务的gating network的输入是task-specific和share两部分;
- 在上层Extraction Network中input不再是原始的input向量,而是底层Extraction Network网络各个gating network输出结果的fusion result。
3. 损失函数的设计
论文指出在设计损失函数时,主要是解决两个问题,一个是多任务模型不同人物之间的样本空间不同;另一个是不同任务之间的权重设定。
针对第一个问题,文章的解决思路是训练样本空间为全部任务的样本空间的并集,而针对每个任务计算loss时,只考虑这个任务的样本空间
L k ( θ k , θ s ) = 1 ∑ i δ k i ∑ i δ k i l o s s k ( y ^ k i ( θ k , θ s ) , y k i ) L_k(\theta_k,\theta_s)=\frac{1}{\sum_i \delta_k^i} \sum_i \delta_k^i loss_k \left( \hat{y}_k^i (\theta_k,\theta_s), y_k^i \right) Lk(θk,θs)=∑iδki1i∑δkilossk(y^ki(θk,θs),yki)
针对第二个问题,传统方法是人工设定一个固定的权重比例,这个需要人工来进行调整,文章给出的思路就是一种自适应动态调节的方案,在训练过程中调整不同任务之间的权重 w k t = w k , 0 × γ k t w_k^t=w_{k,0} \times \gamma_k^t wkt=wk,0×γkt,最终的loss如下
L ( θ 1 , ⋯ , θ K , θ s ) = ∑ k = 1 K w k L k ( θ k , θ s ) L(\theta_1,\cdots,\theta_K,\theta_s)=\sum_{k=1}^K w_k L_k(\theta_k, \theta_s) L(θ1,⋯,θK,θs)=k=1∑KwkLk(θk,θs)
⑤ DBMTL
推荐系统的多个目标之间可能是高度相关 或者 互相抑制关系,DBMTL模型可用于建模目标之间可能存在的因果关系,如下图:
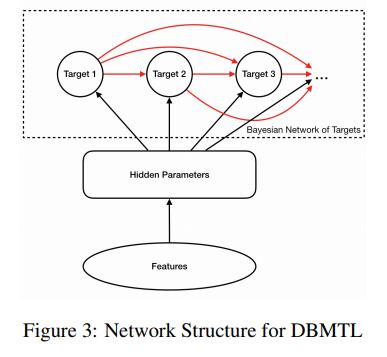
公式为:
P ( l , m ∣ x , H ) = P ( l ∣ x , H ) P ( m ∣ l , x , H ) (1) P(l,m|x,H)=P(l|x,H)P(m|l,x,H) \tag 1 P(l,m∣x,H)=P(l∣x,H)P(m∣l,x,H)(1)
P ( l , m ∣ x , H ) = P ( m ∣ x , H ) P ( l ∣ m , x , H ) (2) P(l,m|x,H)=P(m|x,H)P(l|m,x,H) \tag 2 P(l,m∣x,H)=P(m∣x,H)P(l∣m,x,H)(2)
公式(1)和 (2)从概率的角度讲都是对的, 该如何选择呢?
这其实就是判断目标 与目标 哪个为因哪个为果。
在没有明显的因果关系时如何选择?需要声明的是,两种计算方法,论文中的原话是
it’s a matter of which one is more “learnable” from data.
- 在目标个数较少时,当然可以都试一试。
- 建议选择发生概率大的为因,概率小的为果。
损失函数为:
L ( x , H ) = − [ w 1 ⋅ l o g ( p ( t 1 ∣ x , H ) ) + w 2 ⋅ l o g ( p ( t 2 ∣ t 1 , x , H ) ) + w 3 ⋅ l o g ( p ( t 3 ∣ t 1 , t 2 , x , H ) ) ] L(x,H)=-\left[ w_1 \cdot log(p(t_1|x,H)) + w_2 \cdot log(p(t_2|t_1,x,H)) + w_3 \cdot log(p(t_3|t_1,t_2,x,H)) \right] L(x,H)=−[w1⋅log(p(t1∣x,H))+w2⋅log(p(t2∣t1,x,H))+w3⋅log(p(t3∣t1,t2,x,H))]
完整的DBMTL模型图是:
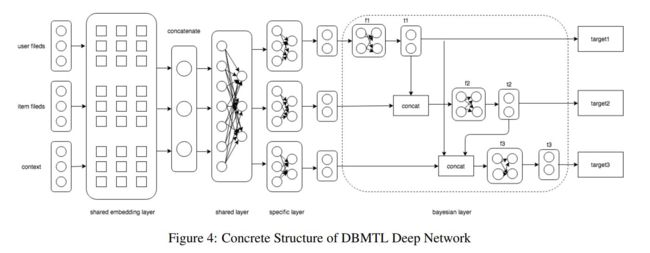
2. 样本构建
下面以电商平台的商品详情页个性化推荐场景为例,介绍一下如果构建训练样本。
商品详情页通常有一个用户正在查看的主商品在页面上方,页面下方还会有一个或多个推荐商品列表,如下图所示,我们现在讨论的就是这些商品列表的个性化排序模型的样本如何构建。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VBRcWlHb-1662197239875)(https://cdn.jsdelivr.net/gh/yangxudong/blogimg@master/rec/item_detail_page.png)]
一般的个性化推荐排序模型,我们从用户和商品两个实体维度来构建样本,比如在ctr预估模型,用户点击了某商品,这这一对
商品详情页的个性化推荐列表一般情况下需要和主商品具有一定的相似或者搭配的关系,因此,我们需要从
最终,我们构建的样本格式为:
3. 特征工程
通常排序模型的特征由三部分构成:
- 用户侧特征:包括用户画像信息、用户粒度统计信息(过于一段时间窗口内用户各种行为的统计值)、用户偏好信息(用户-物品或用户-物品属性粒度的交叉统计信息)
- 物品侧特征:物品基础内容信息、物品粒度的统计信息、物品偏好信息(物品-用户画像、物品-人群画像粒度的统计信息)
- 上下文特征:地理位置、访问设备、天气、时间、是否节假日等
在商品详情页这样的场景下,我们还需要加入主商品维度的特征,具体如下:
- Trigger侧特征:trigger-item 交叉统计特征; trigger的属性与item的属性交叉统计特征;
上文提到了很多统计特征,这里详细说明下具体是如何统计的,得到一个统计量一般需要考虑如下几个维度:
- 统计对象:包括user、item、
、 等; - 统计窗口:最近1天、3天、7天、14天、30天等;
- 行为类型:曝光、点击、收藏、加购、购买等
- 统计量:绝对值、排名、比率(点击率、加购率等)、加权和等
一般从上面几个维度组合来考虑如何生成统计特征不容易有遗漏。
对应数值型的特征,我们一般还需要做离散化或者标准化。离散化包括:等频分箱、等宽分箱、自适应分箱(类似决策树寻找特征分裂点的做法)。标准化方法包括:z-score、min-max等。
4. 模型开发
模型开发部分没什么好说的,按照论文内容基于某种深度学习框架,比如tensorflow、pytorch等,开发出模型即可。当然,与其自己开发,不如先找找有没有开源的模型可用,这里推荐阿里云机器学习PAI团队开源的推荐算法训练框架 EasyRec。
简单介绍一下EasyRec推荐算法框架。基于EasyRec框架用户可直接用自己的数据训练内置的算法模型,也可以自定义新的算法模型。目前,已经内置了多个排序模型,如 DeepFM / MultiTower / Deep Interest Network / DSSM / DCN / WDL 等,以及 DBMTL / MMoE / ESMM / PLE 等多目标模型。另外,EasyRec兼容odps/oss/hdfs等多种输入,支持多种类型的特征,损失函数,优化器及评估指标,支持大规模并行训练。使用EasyRec,只需要配置config文件,通过命令调用的方式就可以实现训练、评估、导出、推理等功能,无需进行代码开发,帮您快速搭建推广搜算法。

相比NLP和CV领域的模型,推荐模型的特定是输入的field特别多,可能有几百个,并且各个field的类型和语义也各不相同,需要不同的处理,比如,有的field当成原始特征值使用,有的field需要转embedding之后再接入model,因此,对输入数据的处理通常是开发推荐模型时需要很多重复劳动、易出错、又没有多少技术含量的部分,这让算法工程师头疼不已。EasyRec工具对输入特征的处理进行了自动化,只需要简单的配置即可省去很多重复性劳动。
总结
本文概要讲述了多任务学习的定义、动机和一般方法,概要介绍了目前主流的几种多目标排序模型。并结合电商平台商品详情页的业务场景具体介绍了如何构建样本,如何做特征工程。并且推荐基于开源的面向工业界的EasyRec推荐算法训练框架来构建做算法的训练和评估。至于模型服务的部署,每家公司的平台各不相同,就不详细介绍了。