DensetNet原理简述以及pytorch在cifar-10上的训练
1. DensetNet背景介绍
1.卷积神经网络CNN在计算机视觉物体识别上优势显著,典型的模型有:LeNet5, VGG, Highway Network, Residual Network.
2.CNN越深则效果越好,但是,会面临梯度弥散的问题,经过层数越多,则前面的信息就会渐渐减弱和消散。
3.目前已有很多措施去解决以上困境:
(1)Highway Network,Residual Network通过前后两层的残差链接使信息尽量不丢失
(2)Stochastic depth通过随机drop掉Resnet的一些层来缩短模型
(3)FractalNets通过重复组合一些平行的层序列来保证深度的同时减轻这个问题。
但这些措施都有一个共性:都是在前一层和后一层中都建立一个短连接,如下图:
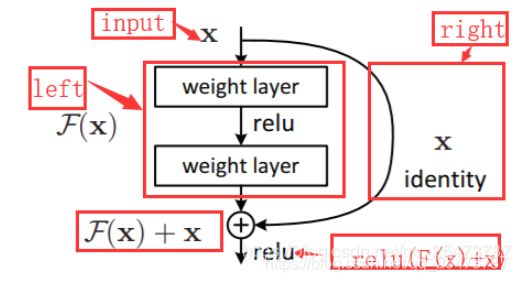
2.DensetNet基本原理

如上图所示,是一个5层的dense block,里面含有5层基本的卷积层,每一个卷积层都包含一个基本的BN,Relu和Conv,代码如下:
# 首先定义一个卷积块,其顺序是bn->relu->conv
def conv_block(in_channel, out_channel):
layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True),
nn.Conv2d(in_channel, out_channel, 3, padding=1, bias=False)
)
return layer
如上代码所示,dense block中的每一层都是包含着BN,Relu和Conv操作。加入BN和Relu操作,是处理上面一层传来的特征图,进行BN操作,然后在经过Relu操作,将梯度限定在一个特定的范围之内,BN和Relu都是减缓梯度问题的有效的手段(不了解Batch Normlization和Relu操作的,可以自行阅读相关的论文)。
实现完dense block中基本的层之后,接下来开始实现dense block,如上图所示,有一个变量叫做k,这个k代表的是,dense block里面的layer输出的ouput channel的个数,比方说,dense block的输入的input channel是32,k=5
那么如下图所示:

各层详细的channel个数如下:
input_channel=32 k=5
layer1_input=32 layer1_output=5
layer2_input=32+51 layer2_output=5
layer3_input=32+52 layer3_output=5
layer4_input=32+53 lyaer4_output=5
layer5_input=32+54 lyaer5_output=5
ouput_channel=32+5*5
代码实现dense block
class dense_block(nn.Module):
def __init__(self, in_channel, growth_rate, num_layers):
super(dense_block, self).__init__()
block = []
channel = in_channel
for i in range(num_layers):
block.append(conv_block(channel, growth_rate))//这里的grow_rate就是k
channel += growth_rate
self.net = nn.Sequential(*block)
def forward(self, x):
for layer in self.net:
out = layer(x)
x = torch.cat((out, x), dim=1)
return x
除了 dense block,DenseNet 中还有一个模块叫过渡层(transition block),因为 DenseNet
会不断地对维度进行拼接, 所以当层数很高的时候,输出的通道数就会越来越大,参数和计算量也会越来越大,
为了避免这个问题,需要引入过渡层将输出通道降低下来,同时也将输入的长宽减半,这个过渡层可以使用
1 x 1 的卷积
def transition(in_channel, out_channel):
trans_layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True),
nn.Conv2d(in_channel, out_channel, 1),
nn.AvgPool2d(2, 2)
)
return trans_layer
完整的denset net实现
class densenet(nn.Module):
def __init__(self, in_channel, num_classes, growth_rate=32, block_layers=[6, 12, 24, 16]):
super(densenet, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channel, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(3, 2, padding=1)
)
channels = 64
block = []
for i, layers in enumerate(block_layers):
block.append(dense_block(channels, growth_rate, layers))
channels += layers * growth_rate
if i != len(block_layers) - 1:
block.append(transition(channels, channels // 2)) # 通过transition 层将大小减半,通道数减半
channels = channels // 2
self.block2 = nn.Sequential(*block)
self.block2.add_module('bn', nn.BatchNorm2d(channels))
self.block2.add_module('relu', nn.ReLU(True))
self.block2.add_module('avg_pool', nn.AvgPool2d(3))
self.classifier = nn.Linear(channels, num_classes)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x
训练
def data_tf(x):
x = x.resize((96, 96), 2) # 将图片放大到 96 x 96
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.transpose((2, 0, 1)) # 将 channel 放到第一维,只是 pytorch 要求的输入方式
x = torch.from_numpy(x)
return x
train_set = CIFAR10('./data', train=True,download=True,transform=data_tf)
train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
test_set = CIFAR10('./data', train=False, download=True,transform=data_tf)
test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)
net = densenet(3, 10)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
def get_acc(output, label):
total = output.shape[0]
_, pred_label = output.max(1)
num_correct = (pred_label == label).sum().item()
return num_correct / total
def train(net, train_data, valid_data, num_epochs, optimizer, criterion):
if torch.cuda.is_available():
net = net.cuda()
prev_time = datetime.now()
for epoch in range(num_epochs):
train_loss = 0
train_acc = 0
net = net.train()
for im, label in train_data:
if torch.cuda.is_available():
im = Variable(im.cuda())
label = Variable(label.cuda())
else:
im = Variable(im)
label = Variable(label)
# forward
output = net(im)
loss = criterion(output, label)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += get_acc(output, label)
cur_time = datetime.now()
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = "Time %02d:%02d:%02d" % (h, m, s)
if valid_data is not None:
valid_loss = 0
valid_acc = 0
net = net.eval()
for im, label in valid_data:
if torch.cuda.is_available():
im = Variable(im.cuda(), volatile=True)
label = Variable(label.cuda(), volatile=True)
else:
im = Variable(im, volatile=True)
label = Variable(label, volatile=True)
output = net(im)
loss = criterion(output, label)
valid_loss += loss.item()
valid_acc += get_acc(output, label)
epoch_str = (
"Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, "
% (epoch, train_loss / len(train_data),
train_acc / len(train_data), valid_loss / len(valid_data),
valid_acc / len(valid_data)))
else:
epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " %
(epoch, train_loss / len(train_data),
train_acc / len(train_data)))
prev_time = cur_time
print(epoch_str + time_str)
train(net, train_data, test_data, 20, optimizer, criterion)