【笔记】scatter_函数:用法如 torch.zeros(target.size(0), 2).scatter_(1,target,1).to(self.device)
target内容:
tensor([0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0,
0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0,
0, 1, 1, 0])
类型:
target.shapetorch.Size([100])
target.size()
torch.Size([100])
程序1:error
要知道错误的原因
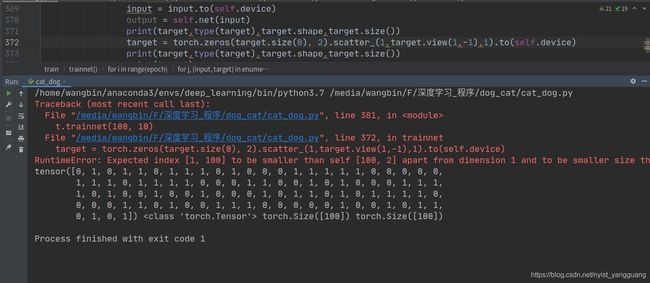
RuntimeError: Expected index [1, 100] to be smaller than self [100, 2] apart from dimension 1 and to be smaller size than src [100, 2]
程序2: true
import torch
from PIL import Image
import numpy as np
import torch.nn as nn
import os
from torch.utils.data import Dataset, DataLoader
class mydataset(Dataset):
def __init__(self, path):
self.path = path
self.dataset = os.listdir(self.path)
self.mean = [0.4878, 0.4545, 0.4168]
self.std = [0.2623, 0.2555, 0.2577]
def __getitem__(self, index):
name = self.dataset[index]
name_list = name.split(".")
target = int(name_list[0])
target = torch.tensor(target)
img = Image.open(os.path.join(self.path, name))
img = np.array(img) / 255
# 去均值
img = (img - self.mean) / self.std
# img 是 float64
data = torch.tensor(img, dtype=torch.float32).permute(2, 0, 1)
return data, target
def __len__(self):
return len(self.dataset)
class mynetwork(nn.Module):
def __init__(self):
super(mynetwork, self).__init__()
# 有序容器
self.line1 = nn.Sequential(
nn.Linear(3 * 100 * 100, 5120),
nn.ReLU(),
nn.Linear(5120, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 2560),
nn.ReLU(),
nn.Linear(2560, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 2),
)
# parse vt. 解析;从语法上分析
def forward(self, parse):
data = torch.reshape(parse, shape=(-1, 3 * 100 * 100))
return self.line1(data)
class train(object):
def __init__(self, path):
self.path = path
self.test_dataset = mydataset(self.path)
self.train_dataset = mydataset(self.path)
self.criterion = torch.nn.MSELoss()
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.net = mynetwork().to(self.device)
self.optimize = torch.optim.Adam(self.net.parameters())
def dataloader(self, batch):
train_data_loader = DataLoader(dataset=self.train_dataset, batch_size=batch, shuffle=True)
test_data_loader = DataLoader(dataset=self.test_dataset, batch_size=batch, shuffle=True)
return train_data_loader, test_data_loader
def trainnet(self, batch, epoch):
train_data_loader, test_data_loader = self.dataloader(batch)
losses = []
accuracy = []
for i in range(epoch):
for j, (input, target) in enumerate(train_data_loader):
input = input.to(self.device)
output = self.net(input)
print(target,type(target),target.shape,target.size())
target = torch.zeros(target.size(0), 2).scatter_(1,target.view(1,-1),1).to(self.device)
print(target,type(target),target.shape,target.size())
print(target)
input()
if __name__ == "__main__":
path = r"./cat_dog/img"
t = train(path)
t.trainnet(100, 10)
输出:
/home/wangbin/anaconda3/envs/deep_learning/bin/python3.7 /media/wangbin/F/深度学习_程序/dog_cat/cat_dog.py
tensor([0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0,
0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0,
0, 1, 1, 0]) torch.Size([100]) torch.Size([100])
tensor([[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.]], device='cuda:0') torch.Size([100, 2]) torch.Size([100, 2])
tensor([[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.],
[0., 1.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[1., 0.]], device='cuda:0') 附:

函数资料:
torch._C._TensorBase._TensorBase def scatter_(self,
dim: int,
index: Any,
src: Any,
reduce: str = None) -> None
scatter_(dim, index, src, reduce=None) -> Tensor
Writes all values from the tensor src into self at the indices specified in the index tensor. For each value in src, its output index is specified by its index in src for dimension != dim and by the corresponding value in index for dimension = dim.
For a 3-D tensor, self is updated as:
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2
This is the reverse operation of the manner described in ~Tensor.gather.
self, index and src (if it is a Tensor) should have same number of dimensions. It is also required that index.size(d) <= src.size(d) for all dimensions d, and that index.size(d) <= self.size(d) for all dimensions d != dim.
Moreover, as for ~Tensor.gather, the values of index must be between 0 and self.size(dim) - 1 inclusive, and all values in a row along the specified dimension dim must be unique.
Additionally accepts an optional reduce argument that allows specification of an optional reduction operation, which is applied to all values in the tensor src into self at the indicies specified in the index. For each value in src, the reduction operation is applied to an index in self which is specified by its index in src for dimension != dim and by the corresponding value in index for dimension = dim.
Given a 3-D tensor and reduction using the multiplication operation, self is updated as:
self[index[i][j][k]][j][k] *= src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] *= src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] *= src[i][j][k] # if dim == 2
Reducing with the addition operation is the same as using ~torch.Tensor.scatter_add_.
Note
Reduction is not yet implemented for the CUDA backend.
Example:
>>> x = torch.rand(2, 5)
>>> x
tensor([[ 0.3992, 0.2908, 0.9044, 0.4850, 0.6004],
[ 0.5735, 0.9006, 0.6797, 0.4152, 0.1732]])
>>> torch.zeros(3, 5).scatter_(0, torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]]), x)
tensor([[ 0.3992, 0.9006, 0.6797, 0.4850, 0.6004],
[ 0.0000, 0.2908, 0.0000, 0.4152, 0.0000],
[ 0.5735, 0.0000, 0.9044, 0.0000, 0.1732]])
>>> z = torch.zeros(2, 4).scatter_(1, torch.tensor([[2], [3]]), 1.23)
>>> z
tensor([[ 0.0000, 0.0000, 1.2300, 0.0000],
[ 0.0000, 0.0000, 0.0000, 1.2300]])
>>> z = torch.ones(2, 4).scatter_(1, torch.tensor([[2], [3]]), 1.23, reduce='multiply')
>>> z
tensor([[1.0000, 1.0000, 1.2300, 1.0000],
[1.0000, 1.0000, 1.0000, 1.2300]])
Params:
dim – the axis along which to index
index – the indices of elements to scatter, can be either empty or the same size of src. When empty, the operation returns identity
src – the source element(s) to scatter, incase `value` is not specified
reduce – reduction operation to apply, can be either 'add' or 'multiply'.
< Python 3.7 (deep_learning) >