MATLAB——微分方程建模
MATLAB——微分方程建模
- 1. 微分方程简介
- 2. 物理原理建模
-
- 一、红绿灯问题
- 二、弹簧振动问题
- 案例分析:放射性废料的处理
- 3. 人口模型
-
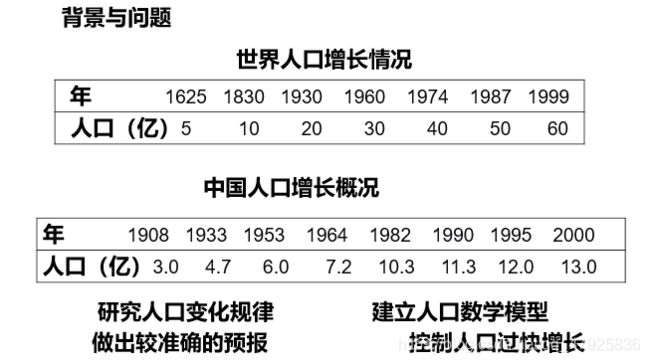
- 背景与问题
- 一、Malthus模型
- 二、Logistic模型
- 三、分龄人口模型
- 案例分析:美国人口的预报模型
- 4. 传染病模型
-
- 一、指数增长模型
- 二、SI模型
- 三、SIS模型
- 四、SIR模型
- 五、SEIR模型
- 5. 平衡点理论及建模
- 6. 差分方程模型
- 7. 微分方程的数值解
1. 微分方程简介




2. 物理原理建模
一、红绿灯问题



二、弹簧振动问题


案例分析:放射性废料的处理




问题一代码实现【M文件】
clc,clear
syms m V rho g k s(t) v(t) %定义符号常数和符变量
ds=diff(s); %定义s的一阶导数,为了初值条件赋值
s=dsolve(m*diff(s,2)-m*g+rho*g*V+k*diff(s),s(0)==0,ds(0)==0);
%使用dsolve解出s的关系式
s=subs(s,{m,V,rho,g,k},{239.46,0.2058,1035.71,9.8,0.6});
%常数赋值
s=simplify(s); %化简
s=vpa(s,6) %显示小数形式的位移函数
v=dsolve(m*diff(v)-m*g+rho*g*V+k*v,v(0)==0);
%使用dsolve解出v的关系式
v=subs(v,{m,V,rho,g,k},{239.46,0.2058,1035.71,9.8,0.6});
%常数赋值
v=simplify(v); %化简
v=vpa(v,6) %显示小数形式的速度函数
y=s-90;
tt=solve(y); tt=double(tt) %求到达海底90米处的时间
vv=subs(v,tt);vv=double(vv) %求到底海底90米处的速度
问题二的模型

计算得位移不能超过84.8439m。通过这个模型,也可以得到原来处理核废料的方法是不合理的。
clc,clear
syms m V rho g k v(t) %定义符号变量
v=dsolve(m*diff(v)-m*g+rho*g*V+k*v^2,v(0)==0);
%用dsolve函数求出v的函数式
v=subs(v,{m,V,rho,g,k},{239.46,0.2058,1035.71,9.8,0.6}); %代入数值
v=simplify(v); v=vpa(v,6) %显示小数形式的速度函数
T=solve(v-12.2); T=double(T) %求时间的临界值T
s=int(v,0,T) %求位移的临界值
结果分析
由于在实际中K与V的关系很难确定, 所以上面的模型有它的局限性,而且对不同的介质,比如在水中与在空气中K与V
的关系也不同。如果假设K为常数的话,那么水中的这个K 就比在空气中对应的V要大一些。在一般情况下,K应是 V的函数,即 K=K(V),至于是什么样的函数,这个问题至今还没有解决。
3. 人口模型
背景与问题
一、Malthus模型


1.4 模型结果分析
比较历年的人口统计资料,可发现人口增长的实际情况与Malthus模型的预报结果基本相符。世界人口大约每35年增长一倍,检查1700年至1961年的260年中世界人口的实际数量,发现两者几乎完全一致。按照该模型计算,人口数量每34.6年增长一倍,两者几乎也完全相同。此模型用于短期人口估算有较好的近似程度,但是当t→∞时,有x(t)→∞,可见它不能用于对人口的长期预报,导致这个后果的主要原因是在Malthus模型中做了如下假设:人口自然增长率g仅与人口出生率和死亡率有关。且为常数。这一假设使得模型简化,但也隐含了人口无限增长的缺陷,显然用该模型来做长期的人口预测会是不合理的,因此需要对此进行改进。
二、Logistic模型







三、分龄人口模型





案例分析:美国人口的预报模型
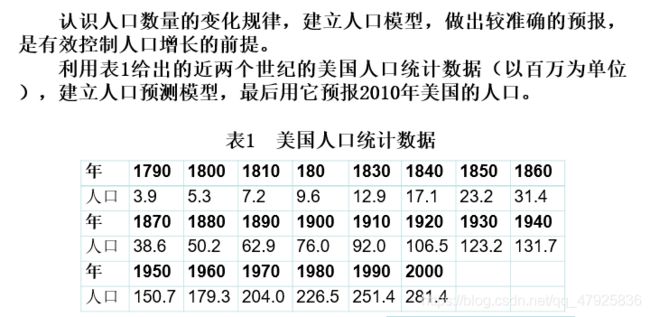

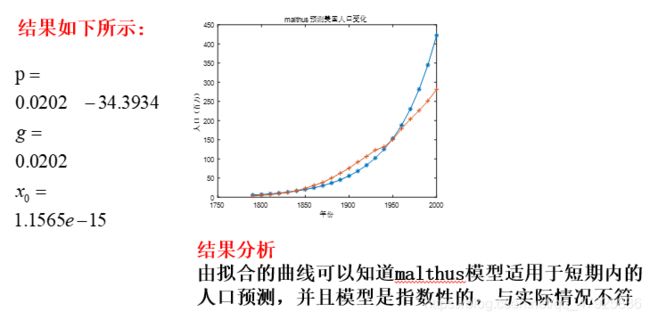
使用malthlus模型预测美国人口变化【M文件】
clc,clear
t=[1790:10:2000]';
a=xlsread('data1.xlsx');
%把原始数据保存在data1.xlsx中,读取data1里保存的数据,6*8矩阵
x=a([2:2:6],:)';
%提出人口数据,提取2,4,6行(人口)数据,并且转置
x=nonzeros(x);
x=x(~isnan(x))
y=log(x); %令y=lnx
p=polyfit(t,y,1) %拟合lnx=a*t+b
g=p(1) %p(1)代表g:人口自然增长率
x0=exp(p(2))
%因为e^(a*t)*e^b=x,而x=x0*e^g*t,所以x0=e^b
Y=polyval(p,t);
%y=polyval(p,t)为返回对应自变量t在给定系数P的多项式的值。此时值为lnx
X=exp(Y); %还原成预测的x
plot(t,X,'*-',t,x,'+-')
title('malthus预测美国人口变化')
xlabel('年份')
ylabel('人口(百万)')
数据保存在xlsx文件中,如下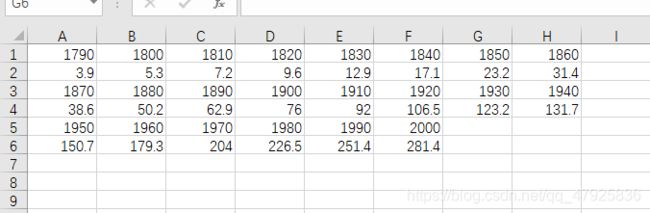
结果分析
使用logistic模型预测美国口变化【M文件】
clc, clear
a=xlsread('data1.xlsx');
%把原始数据保存在data1.xlsx中,读取data1里保存的数据,6*8矩阵
x=a([2:2:6],:)';
%提出人口数据,提取2,4,6行(人口)数据,并且转置
x=nonzeros(x); %去0
x=x(~isnan(x))
t=[1790:10:2000]';
t0=t(1); x0=x(1);
%取1970年的人口和年份作为初始数据
fun=@(cs,td)cs(1)./(1+(cs(1)/x0-1)*exp(-cs(2)*(td-t0))); %cs(1)=xm,cs(2)=r
cs=lsqcurvefit(fun,rand(2,1),t(2:end),x(2:end),zeros(2,1)) %非线性最小二乘估计得出cs
xhat=fun(cs,[t;2010]) %预测已知年代和2010年的人口
t1=[t;2010];
plot(t1,xhat,'*-',t,x,'+-')
title('logistic预测美国人口变化')
xlabel('时间t')
ylabel('人口(百万)')
结果分析
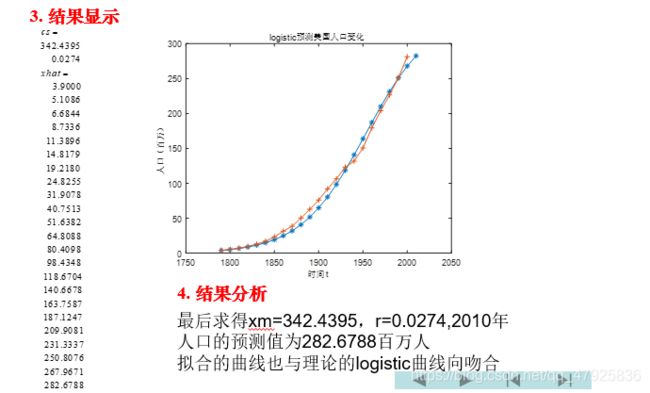

代码实现——向后差分
clc, clear
a=xlsread('data1.xlsx');
%把原始数据保存在data1.xlsx中,读取data1里保存的数据,6*8矩阵
x=a([2:2:6],:)';
%提出人口数据,提取2,4,6行(人口)数据,并且转置
x=nonzeros(x);
x=x(~isnan(x))
t=[1790:10:2000]'; %时间数据
a=[ones(21,1), -x(2:end)]; %构造a矩阵作差分方程右端
b=diff(x)./x(2:end)/10; %表示差分方程左端
cs=a\b; %其实就是a*cs=b,得出cs两个值
r=cs(1), xm=r/cs(2)
%cs(1)代表差分方程右端系数r;cs(2)代表差分方程右端s,因为s=r/xm,所以xm=r/s
4. 传染病模型

一、指数增长模型

二、SI模型
(区分病人和健康人,病人不会再被感染)


三、SIS模型
(病人可治愈成为健康人,健康人可再次被感染)

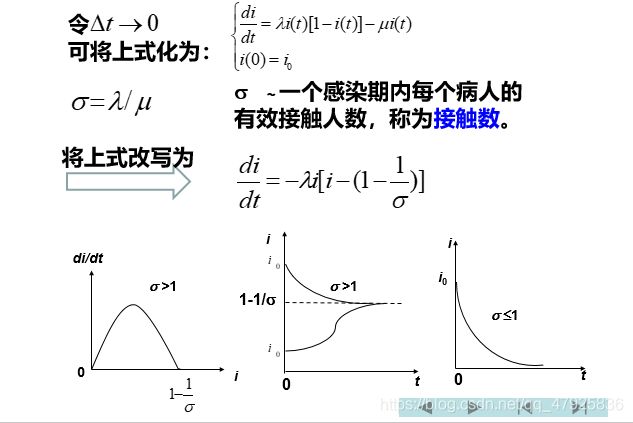

四、SIR模型
(人患病痊愈后有长期免疫力)


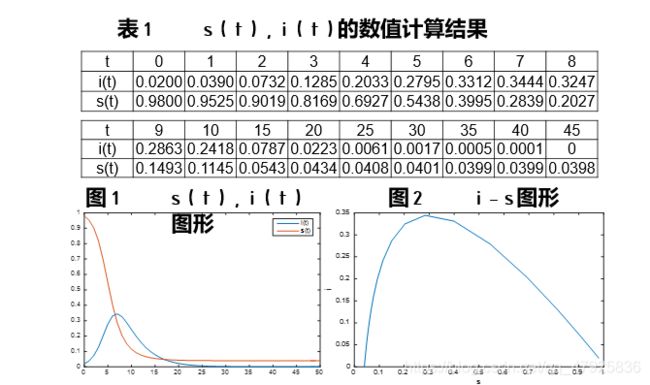

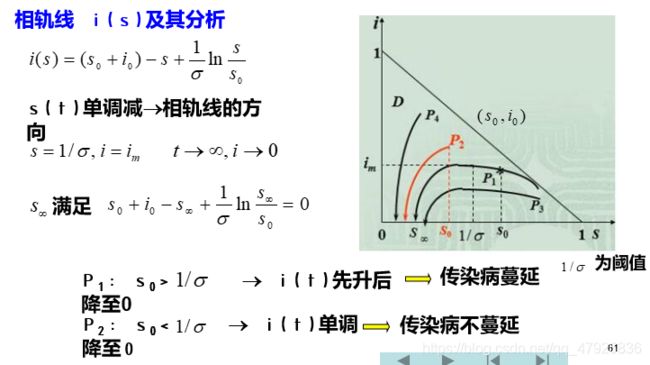

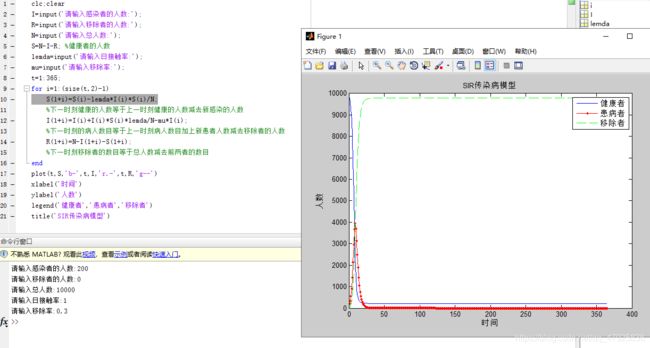
代码实现(同学编写可参考)【M文件】
clc;clear
I=input('请输入感染者的人数:');
R=input('请输入移除者的人数:');
N=input('请输入总人数:');
S=N-I-R; %健康者的人数
lemda=input('请输入日接触率:');
mu=input('请输入移除率:');
t=1:365;
for i=1:(size(t,2)-1)
S(1+i)=S(i)-lemda*I(i)*S(i)/N;
%下一时刻健康的人数等于上一时刻健康的人数减去新感染的人数
I(1+i)=I(i)+I(i)*S(i)*lemda/N-mu*I(i);
%下一时刻的病人数目等于上一时刻病人数目加上新患者人数减去移除者的人数
R(1+i)=N-I(1+i)-S(1+i);
%下一时刻移除者的数目等于总人数减去前两者的数目
end
plot(t,S,'b-',t,I,'r.-',t,R,'g--')
xlabel('时间')
ylabel('人数')
legend('健康者','患病者','移除者')
title('SIR传染病模型')
可输入如下数据测试

结果展示
五、SEIR模型
(人被感染传染病后要经历病毒潜伏期)


