基于 Localstorage 设计一个 1M 的缓存系统,需要实现缓存淘汰机制
设计思路如下:
- 存储的每个对象需要添加两个属性:分别是过期时间和存储时间。
- 利用一个属性保存系统中目前所占空间大小,每次存储都增加该属性。当该属性值大于 1M 时,需要按照时间排序系统中的数据,删除一定量的数据保证能够存储下目前需要存储的数据。
- 每次取数据时,需要判断该缓存数据是否过期,如果过期就删除。
以下是代码实现,实现了思路,但是可能会存在 Bug,但是这种设计题一般是给出设计思路和部分代码,不会需要写出一个无问题的代码
class Store {
constructor() {
let store = localStorage.getItem('cache')
if (!store) {
store = {
maxSize: 1024 * 1024,
size: 0
}
this.store = store
} else {
this.store = JSON.parse(store)
}
}
set(key, value, expire) {
this.store[key] = {
date: Date.now(),
expire,
value
}
let size = this.sizeOf(JSON.stringify(this.store[key]))
if (this.store.maxSize < size + this.store.size) {
console.log('超了-----------');
var keys = Object.keys(this.store);
// 时间排序
keys = keys.sort((a, b) => {
let item1 = this.store[a], item2 = this.store[b];
return item2.date - item1.date;
});
while (size + this.store.size > this.store.maxSize) {
let index = keys[keys.length - 1]
this.store.size -= this.sizeOf(JSON.stringify(this.store[index]))
delete this.store[index]
}
}
this.store.size += size
localStorage.setItem('cache', JSON.stringify(this.store))
}
get(key) {
let d = this.store[key]
if (!d) {
console.log('找不到该属性');
return
}
if (d.expire > Date.now) {
console.log('过期删除');
delete this.store[key]
localStorage.setItem('cache', JSON.stringify(this.store))
} else {
return d.value
}
}
sizeOf(str, charset) {
var total = 0,
charCode,
i,
len;
charset = charset ? charset.toLowerCase() : '';
if (charset === 'utf-16' || charset === 'utf16') {
for (i = 0, len = str.length; i < len; i++) {
charCode = str.charCodeAt(i);
if (charCode <= 0xffff) {
total += 2;
} else {
total += 4;
}
}
} else {
for (i = 0, len = str.length; i < len; i++) {
charCode = str.charCodeAt(i);
if (charCode <= 0x007f) {
total += 1;
} else if (charCode <= 0x07ff) {
total += 2;
} else if (charCode <= 0xffff) {
total += 3;
} else {
total += 4;
}
}
}
return total;
}
}
画一条0.5px的线
- 采用transform: scale()的方式,该方法用来定义元素的2D 缩放转换:
transform: scale(0.5,0.5);
- 采用meta viewport的方式
这样就能缩放到原来的0.5倍,如果是1px那么就会变成0.5px。viewport只针对于移动端,只在移动端上才能看到效果
介绍一下HTTPS和HTTP区别
HTTPS 要比 HTTPS 多了 secure 安全性这个概念,实际上, HTTPS 并不是一个新的应用层协议,它其实就是 HTTP + TLS/SSL 协议组合而成,而安全性的保证正是 SSL/TLS 所做的工作。
SSL
安全套接层(Secure Sockets Layer)
TLS
(传输层安全,Transport Layer Security)
现在主流的版本是 TLS/1.2, 之前的 TLS1.0、TLS1.1 都被认为是不安全的,在不久的将来会被完全淘汰。
HTTPS 就是身披了一层 SSL 的 HTTP 。
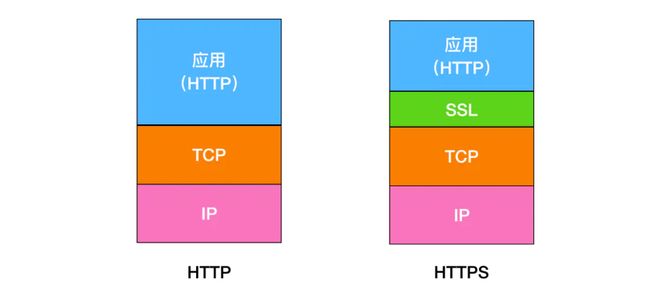
那么区别有哪些呢
- HTTP 是明文传输协议,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。
- HTTPS比HTTP更加安全,对搜索引擎更友好,利于SEO,谷歌、百度优先索引HTTPS网页。
- HTTPS标准端口443,HTTP标准端口80。
- HTTPS需要用到SSL证书,而HTTP不用。
我觉得记住以下两点HTTPS主要作用就行
- 对数据进行加密,并建立一个信息安全通道,来保证传输过程中的数据安全;
- 对网站服务器进行真实身份认证。
HTTPS的缺点
- 证书费用以及更新维护。
- HTTPS 降低一定用户访问速度(实际上优化好就不是缺点了)。
- HTTPS 消耗 CPU 资源,需要增加大量机器。
伪元素和伪类的区别和作用?
- 伪元素:在内容元素的前后插入额外的元素或样式,但是这些元素实际上并不在文档中生成。它们只在外部显示可见,但不会在文档的源代码中找到它们,因此,称为“伪”元素。例如:
p::before {content:"第一章:";}
p::after {content:"Hot!";}
p::first-line {background:red;}
p::first-letter {font-size:30px;}
- 伪类:将特殊的效果添加到特定选择器上。它是已有元素上添加类别的,不会产生新的元素。例如:
a:hover {color: #FF00FF}
p:first-child {color: red}
总结: 伪类是通过在元素选择器上加⼊伪类改变元素状态,⽽伪元素通过对元素的操作进⾏对元素的改变。
Canvas和SVG的区别
(1)SVG: SVG可缩放矢量图形(Scalable Vector Graphics)是基于可扩展标记语言XML描述的2D图形的语言,SVG基于XML就意味着SVG DOM中的每个元素都是可用的,可以为某个元素附加Javascript事件处理器。在 SVG 中,每个被绘制的图形均被视为对象。如果 SVG 对象的属性发生变化,那么浏览器能够自动重现图形。
其特点如下:
- 不依赖分辨率
- 支持事件处理器
- 最适合带有大型渲染区域的应用程序(比如谷歌地图)
- 复杂度高会减慢渲染速度(任何过度使用 DOM 的应用都不快)
- 不适合游戏应用
(2)Canvas: Canvas是画布,通过Javascript来绘制2D图形,是逐像素进行渲染的。其位置发生改变,就会重新进行绘制。
其特点如下:
- 依赖分辨率
- 不支持事件处理器
- 弱的文本渲染能力
- 能够以 .png 或 .jpg 格式保存结果图像
- 最适合图像密集型的游戏,其中的许多对象会被频繁重绘
注:矢量图,也称为面向对象的图像或绘图图像,在数学上定义为一系列由线连接的点。矢量文件中的图形元素称为对象。每个对象都是一个自成一体的实体,它具有颜色、形状、轮廓、大小和屏幕位置等属性。
单行、多行文本溢出隐藏
- 单行文本溢出
overflow: hidden; // 溢出隐藏
text-overflow: ellipsis; // 溢出用省略号显示
white-space: nowrap; // 规定段落中的文本不进行换行
- 多行文本溢出
overflow: hidden; // 溢出隐藏
text-overflow: ellipsis; // 溢出用省略号显示
display:-webkit-box; // 作为弹性伸缩盒子模型显示。
-webkit-box-orient:vertical; // 设置伸缩盒子的子元素排列方式:从上到下垂直排列
-webkit-line-clamp:3; // 显示的行数
注意:由于上面的三个属性都是 CSS3 的属性,没有浏览器可以兼容,所以要在前面加一个-webkit- 来兼容一部分浏览器。
参考 前端进阶面试题详细解答
如何判断元素是否到达可视区域
以图片显示为例:
window.innerHeight是浏览器可视区的高度;document.body.scrollTop || document.documentElement.scrollTop是浏览器滚动的过的距离;imgs.offsetTop是元素顶部距离文档顶部的高度(包括滚动条的距离);- 内容达到显示区域的:
img.offsetTop < window.innerHeight + document.body.scrollTop;
对媒体查询的理解?
媒体查询由⼀个可选的媒体类型和零个或多个使⽤媒体功能的限制了样式表范围的表达式组成,例如宽度、⾼度和颜⾊。媒体查询,添加⾃CSS3,允许内容的呈现针对⼀个特定范围的输出设备⽽进⾏裁剪,⽽不必改变内容本身,适合web⽹⻚应对不同型号的设备⽽做出对应的响应适配。
媒体查询包含⼀个可选的媒体类型和满⾜CSS3规范的条件下,包含零个或多个表达式,这些表达式描述了媒体特征,最终会被解析为true或false。如果媒体查询中指定的媒体类型匹配展示⽂档所使⽤的设备类型,并且所有的表达式的值都是true,那么该媒体查询的结果为true。那么媒体查询内的样式将会⽣效。
简单来说,使用 @media 查询,可以针对不同的媒体类型定义不同的样式。@media 可以针对不同的屏幕尺寸设置不同的样式,特别是需要设置设计响应式的页面,@media 是非常有用的。当重置浏览器大小的过程中,页面也会根据浏览器的宽度和高度重新渲染页面。
浏览器是如何对 HTML5 的离线储存资源进行管理和加载?
- 在线的情况下,浏览器发现 html 头部有 manifest 属性,它会请求 manifest 文件,如果是第一次访问页面 ,那么浏览器就会根据 manifest 文件的内容下载相应的资源并且进行离线存储。如果已经访问过页面并且资源已经进行离线存储了,那么浏览器就会使用离线的资源加载页面,然后浏览器会对比新的 manifest 文件与旧的 manifest 文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,就会重新下载文件中的资源并进行离线存储。
- 离线的情况下,浏览器会直接使用离线存储的资源。
浏览器乱码的原因是什么?如何解决?
产生乱码的原因:
- 网页源代码是
gbk的编码,而内容中的中文字是utf-8编码的,这样浏览器打开即会出现html乱码,反之也会出现乱码; html网页编码是gbk,而程序从数据库中调出呈现是utf-8编码的内容也会造成编码乱码;- 浏览器不能自动检测网页编码,造成网页乱码。
解决办法:
- 使用软件编辑HTML网页内容;
- 如果网页设置编码是
gbk,而数据库储存数据编码格式是UTF-8,此时需要程序查询数据库数据显示数据前进程序转码; - 如果浏览器浏览时候出现网页乱码,在浏览器中找到转换编码的菜单进行转换。
对 CSS 工程化的理解
CSS 工程化是为了解决以下问题:
- 宏观设计:CSS 代码如何组织、如何拆分、模块结构怎样设计?
- 编码优化:怎样写出更好的 CSS?
- 构建:如何处理我的 CSS,才能让它的打包结果最优?
- 可维护性:代码写完了,如何最小化它后续的变更成本?如何确保任何一个同事都能轻松接手?
以下三个方向都是时下比较流行的、普适性非常好的 CSS 工程化实践:
- 预处理器:Less、 Sass 等;
- 重要的工程化插件: PostCss;
- Webpack loader 等 。
基于这三个方向,可以衍生出一些具有典型意义的子问题,这里我们逐个来看:
(1)预处理器:为什么要用预处理器?它的出现是为了解决什么问题?
预处理器,其实就是 CSS 世界的“轮子”。预处理器支持我们写一种类似 CSS、但实际并不是 CSS 的语言,然后把它编译成 CSS 代码: 那为什么写 CSS 代码写得好好的,偏偏要转去写“类 CSS”呢?这就和本来用 JS 也可以实现所有功能,但最后却写 React 的 jsx 或者 Vue 的模板语法一样——为了爽!要想知道有了预处理器有多爽,首先要知道的是传统 CSS 有多不爽。随着前端业务复杂度的提高,前端工程中对 CSS 提出了以下的诉求:
- 宏观设计上:我们希望能优化 CSS 文件的目录结构,对现有的 CSS 文件实现复用;
- 编码优化上:我们希望能写出结构清晰、简明易懂的 CSS,需要它具有一目了然的嵌套层级关系,而不是无差别的一铺到底写法;我们希望它具有变量特征、计算能力、循环能力等等更强的可编程性,这样我们可以少写一些无用的代码;
- 可维护性上:更强的可编程性意味着更优质的代码结构,实现复用意味着更简单的目录结构和更强的拓展能力,这两点如果能做到,自然会带来更强的可维护性。
这三点是传统 CSS 所做不到的,也正是预处理器所解决掉的问题。预处理器普遍会具备这样的特性:
- 嵌套代码的能力,通过嵌套来反映不同 css 属性之间的层级关系 ;
- 支持定义 css 变量;
- 提供计算函数;
- 允许对代码片段进行 extend 和 mixin;
- 支持循环语句的使用;
- 支持将 CSS 文件模块化,实现复用。
(2)PostCss:PostCss 是如何工作的?我们在什么场景下会使用 PostCss?
它和预处理器的不同就在于,预处理器处理的是 类CSS,而 PostCss 处理的就是 CSS 本身。Babel 可以将高版本的 JS 代码转换为低版本的 JS 代码。PostCss 做的是类似的事情:它可以编译尚未被浏览器广泛支持的先进的 CSS 语法,还可以自动为一些需要额外兼容的语法增加前缀。更强的是,由于 PostCss 有着强大的插件机制,支持各种各样的扩展,极大地强化了 CSS 的能力。
PostCss 在业务中的使用场景非常多:
- 提高 CSS 代码的可读性:PostCss 其实可以做类似预处理器能做的工作;
- 当我们的 CSS 代码需要适配低版本浏览器时,PostCss 的 Autoprefixer 插件可以帮助我们自动增加浏览器前缀;
- 允许我们编写面向未来的 CSS:PostCss 能够帮助我们编译 CSS next 代码;
(3)Webpack 能处理 CSS 吗?如何实现? Webpack 能处理 CSS 吗:
- Webpack 在裸奔的状态下,是不能处理 CSS 的,Webpack 本身是一个面向 JavaScript 且只能处理 JavaScript 代码的模块化打包工具;
- Webpack 在 loader 的辅助下,是可以处理 CSS 的。
如何用 Webpack 实现对 CSS 的处理:
- Webpack 中操作 CSS 需要使用的两个关键的 loader:css-loader 和 style-loader
注意,答出“用什么”有时候可能还不够,面试官会怀疑你是不是在背答案,所以你还需要了解每个 loader 都做了什么事情:
- css-loader:导入 CSS 模块,对 CSS 代码进行编译处理;
- style-loader:创建style标签,把 CSS 内容写入标签。
在实际使用中,css-loader 的执行顺序一定要安排在 style-loader 的前面。因为只有完成了编译过程,才可以对 css 代码进行插入;若提前插入了未编译的代码,那么 webpack 是无法理解这坨东西的,它会无情报错。
title与h1的区别、b与strong的区别、i与em的区别?
- strong标签有语义,是起到加重语气的效果,而b标签是没有的,b标签只是一个简单加粗标签。b标签之间的字符都设为粗体,strong标签加强字符的语气都是通过粗体来实现的,而搜索引擎更侧重strong标签。
- title属性没有明确意义只表示是个标题,H1则表示层次明确的标题,对页面信息的抓取有很大的影响
- i内容展示为斜体,em表示强调的文本
CSS3中有哪些新特性
- 新增各种CSS选择器 (: not(.input):所有 class 不是“input”的节点)
- 圆角 (border-radius:8px)
- 多列布局 (multi-column layout)
- 阴影和反射 (Shadoweflect)
- 文字特效 (text-shadow)
- 文字渲染 (Text-decoration)
- 线性渐变 (gradient)
- 旋转 (transform)
- 增加了旋转,缩放,定位,倾斜,动画,多背景
替换元素的概念及计算规则
通过修改某个属性值呈现的内容就可以被替换的元素就称为“替换元素”。
替换元素除了内容可替换这一特性以外,还有以下特性:
- 内容的外观不受页面上的CSS的影响:用专业的话讲就是在样式表现在CSS作用域之外。如何更改替换元素本身的外观需要类似appearance属性,或者浏览器自身暴露的一些样式接口。
- 有自己的尺寸:在Web中,很多替换元素在没有明确尺寸设定的情况下,其默认的尺寸(不包括边框)是300像素×150像素,如
- 在很多CSS属性上有自己的一套表现规则:比较具有代表性的就是vertical-align属性,对于替换元素和非替换元素,vertical-align属性值的解释是不一样的。比方说vertical-align的默认值的baseline,很简单的属性值,基线之意,被定义为字符x的下边缘,而替换元素的基线却被硬生生定义成了元素的下边缘。
- 所有的替换元素都是内联水平元素:也就是替换元素和替换元素、替换元素和文字都是可以在一行显示的。但是,替换元素默认的display值却是不一样的,有的是inline,有的是inline-block。
替换元素的尺寸从内而外分为三类:
- 固有尺寸: 指的是替换内容原本的尺寸。例如,图片、视频作为一个独立文件存在的时候,都是有着自己的宽度和高度的。
- HTML尺寸: 只能通过HTML原生属性改变,这些HTML原生属性包括的width和height属性、的size属性。
- CSS尺寸: 特指可以通过CSS的width和height或者max-width/min-width和max-height/min-height设置的尺寸,对应盒尺寸中的content box。
这三层结构的计算规则具体如下:
(1)如果没有CSS尺寸和HTML尺寸,则使用固有尺寸作为最终的宽高。
(2)如果没有CSS尺寸,则使用HTML尺寸作为最终的宽高。
(3)如果有CSS尺寸,则最终尺寸由CSS属性决定。
(4)如果“固有尺寸”含有固有的宽高比例,同时仅设置了宽度或仅设置了高度,则元素依然按照固有的宽高比例显示。
(5)如果上面的条件都不符合,则最终宽度表现为300像素,高度为150像素。
(6)内联替换元素和块级替换元素使用上面同一套尺寸计算规则。
CSS中可继承与不可继承属性有哪些
一、无继承性的属性
- display:规定元素应该生成的框的类型
- 文本属性:
- vertical-align:垂直文本对齐
- text-decoration:规定添加到文本的装饰
- text-shadow:文本阴影效果
- white-space:空白符的处理
- unicode-bidi:设置文本的方向
- 盒子模型的属性:width、height、margin、border、padding
- 背景属性:background、background-color、background-image、background-repeat、background-position、background-attachment
- 定位属性:float、clear、position、top、right、bottom、left、min-width、min-height、max-width、max-height、overflow、clip、z-index
- 生成内容属性:content、counter-reset、counter-increment
- 轮廓样式属性:outline-style、outline-width、outline-color、outline
- 页面样式属性:size、page-break-before、page-break-after
- 声音样式属性:pause-before、pause-after、pause、cue-before、cue-after、cue、play-during
二、有继承性的属性
- 字体系列属性
- font-family:字体系列
- font-weight:字体的粗细
- font-size:字体的大小
- font-style:字体的风格
- 文本系列属性
- text-indent:文本缩进
- text-align:文本水平对齐
- line-height:行高
- word-spacing:单词之间的间距
- letter-spacing:中文或者字母之间的间距
- text-transform:控制文本大小写(就是uppercase、lowercase、capitalize这三个)
- color:文本颜色
- 元素可见性
- visibility:控制元素显示隐藏
- 列表布局属性
- list-style:列表风格,包括list-style-type、list-style-image等
- 光标属性
- cursor:光标显示为何种形态
li 与 li 之间有看不见的空白间隔是什么原因引起的?如何解决?
浏览器会把inline内联元素间的空白字符(空格、换行、Tab等)渲染成一个空格。为了美观,通常是一个
解决办法:
(1)为
(2)将所有
(3)将
- 内的字符尺寸直接设为0,即font-size:0。不足:
内的字符间隔,因此需要将- 内的字符间隔设为默认letter-spacing:normal。
渐进增强和优雅降级之间的区别
(1)渐进增强(progressive enhancement):主要是针对低版本的浏览器进行页面重构,保证基本的功能情况下,再针对高级浏览器进行效果、交互等方面的改进和追加功能,以达到更好的用户体验。 (2)优雅降级 graceful degradation: 一开始就构建完整的功能,然后再针对低版本的浏览器进行兼容。
两者区别:
- 优雅降级是从复杂的现状开始的,并试图减少用户体验的供给;而渐进增强是从一个非常基础的,能够起作用的版本开始的,并在此基础上不断扩充,以适应未来环境的需要;
- 降级(功能衰竭)意味着往回看,而渐进增强则意味着往前看,同时保证其根基处于安全地带。
“优雅降级”观点认为应该针对那些最高级、最完善的浏览器来设计网站。而将那些被认为“过时”或有功能缺失的浏览器下的测试工作安排在开发周期的最后阶段,并把测试对象限定为主流浏览器(如 IE、Mozilla 等)的前一个版本。 在这种设计范例下,旧版的浏览器被认为仅能提供“简陋却无妨 (poor, but passable)” 的浏览体验。可以做一些小的调整来适应某个特定的浏览器。但由于它们并非我们所关注的焦点,因此除了修复较大的错误之外,其它的差异将被直接忽略。
“渐进增强”观点则认为应关注于内容本身。内容是建立网站的诱因,有的网站展示它,有的则收集它,有的寻求,有的操作,还有的网站甚至会包含以上的种种,但相同点是它们全都涉及到内容。这使得“渐进增强”成为一种更为合理的设计范例。这也是它立即被 Yahoo 所采纳并用以构建其“分级式浏览器支持 (Graded Browser Support)”策略的原因所在。
什么是物理像素,逻辑像素和像素密度,为什么在移动端开发时需要用到@3x, @2x这种图片?
以 iPhone XS 为例,当写 CSS 代码时,针对于单位 px,其宽度为 414px & 896px,也就是说当赋予一个 DIV元素宽度为 414px,这个 DIV 就会填满手机的宽度;
而如果有一把尺子来实际测量这部手机的物理像素,实际为 1242*2688 物理像素;经过计算可知,1242/414=3,也就是说,在单边上,一个逻辑像素=3个物理像素,就说这个屏幕的像素密度为 3,也就是常说的 3 倍屏。
对于图片来说,为了保证其不失真,1 个图片像素至少要对应一个物理像素,假如原始图片是 500300 像素,那么在 3 倍屏上就要放一个 1500900 像素的图片才能保证 1 个物理像素至少对应一个图片像素,才能不失真。 当然,也可以针对所有屏幕,都只提供最高清图片。虽然低密度屏幕用不到那么多图片像素,而且会因为下载多余的像素造成带宽浪费和下载延迟,但从结果上说能保证图片在所有屏幕上都不会失真。
还可以使用 CSS 媒体查询来判断不同的像素密度,从而选择不同的图片:
my-image { background: (low.png); } @media only screen and (min-device-pixel-ratio: 1.5) { #my-image { background: (high.png); } }display:inline-block 什么时候会显示间隙?
- 有空格时会有间隙,可以删除空格解决;
margin正值时,可以让margin使用负值解决;- 使用
font-size时,可通过设置font-size:0、letter-spacing、word-spacing解决;
解释性语言和编译型语言的区别
(1)解释型语言
使用专门的解释器对源程序逐行解释成特定平台的机器码并立即执行。是代码在执行时才被解释器一行行动态翻译和执行,而不是在执行之前就完成翻译。解释型语言不需要事先编译,其直接将源代码解释成机器码并立即执行,所以只要某一平台提供了相应的解释器即可运行该程序。其特点总结如下- 解释型语言每次运行都需要将源代码解释称机器码并执行,效率较低;
- 只要平台提供相应的解释器,就可以运行源代码,所以可以方便源程序移植;
- JavaScript、Python等属于解释型语言。
(2)编译型语言
使用专门的编译器,针对特定的平台,将高级语言源代码一次性的编译成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式。在编译型语言写的程序执行之前,需要一个专门的编译过程,把源代码编译成机器语言的文件,如exe格式的文件,以后要再运行时,直接使用编译结果即可,如直接运行exe文件。因为只需编译一次,以后运行时不需要编译,所以编译型语言执行效率高。其特点总结如下:- 一次性的编译成平台相关的机器语言文件,运行时脱离开发环境,运行效率高;
- 与特定平台相关,一般无法移植到其他平台;
- C、C++等属于编译型语言。
两者主要区别在于: 前者源程序编译后即可在该平台运行,后者是在运行期间才编译。所以前者运行速度快,后者跨平台性好。
(4)消除
- 的字符间隔letter-spacing:-8px,不足:这也设置了